人物抽出のためのコード比較その④: DBSCAN, SSD
はじめに
人物抽出は、画像や動画から特定の人物を背景から分離する技術です。
AR(拡張現実)やVR(仮想現実)のようなアプリケーションでよく使用されます。
今回は前回の記事に引き続き、人物抽出の技術を紹介します。
関連記事
今回のキーワードはDBSCANとSSDです。
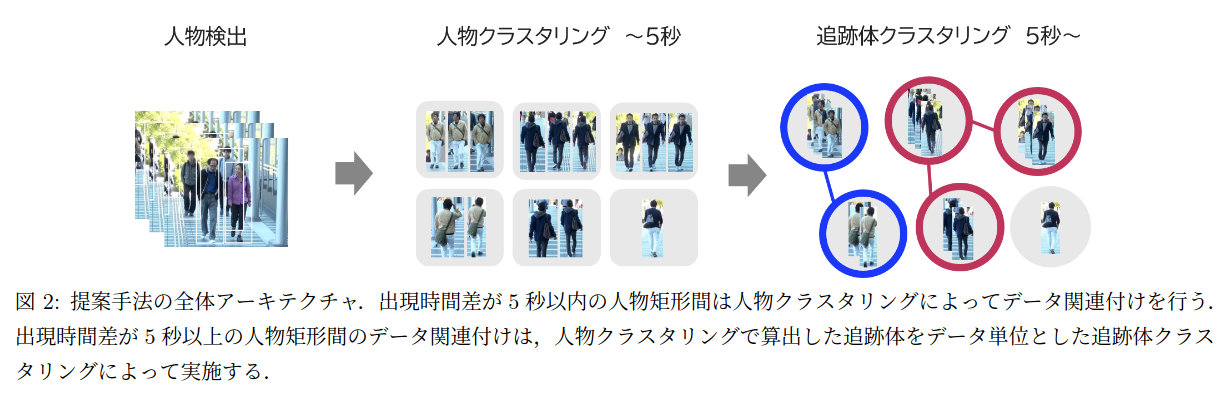
前回の最後にご紹介した「人物再同定に基づく段階的クラスタリングを用いた複数人物追跡」の調査として、論文内で採用されているDBSCANを実装し、その使用感を確かめます。また、YOLOに対して代替となる候補としてSSDを使用してみます。
環境
Python 3.8.10
(FACE01)
$ inxi -SCGxx --filter
System: Kernel: 5.15.0-46-generic x86_64 bits: 64 compiler: N/A Desktop: Unity wm: gnome-shell dm: GDM3
Distro: Ubuntu 20.04.4 LTS (Focal Fossa)
CPU: Topology: Quad Core model: AMD Ryzen 5 1400 bits: 64 type: MT MCP arch: Zen rev: 1 L2 cache: 2048 KiB
Graphics: Device-1: NVIDIA TU116 [GeForce GTX 1660 Ti] vendor: Micro-Star MSI driver: nvidia v: 515.65.01 bus ID: 08:00.0
方法
元動画

DBSCANで人物の領域を抽出
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)は、密度ベースのクラスタリングアルゴリズムの1つで、学習を必要としません。
外観容姿の類似性に基づくDBSCANは、形状や外観の特徴を捉えてクラスタリングを行う強力な手法です。とくに画像分析やパターン認識の分野でよく使用されます。パラメーターεとMinPtsの選択は、クラスタリングの結果に大きく影響します。
1. DBSCANの基本
DBSCANは、データポイントの密度に基づいてクラスターを形成します。以下は、基本的な手順です。
-
距離と密度の定義: あるデータポイントから指定された半径ε以内にあるデータポイントの数が、指定された最小値MinPts以上であれば、そのデータポイントはコアポイントとされます。
-
クラスターの形成: コアポイントを中心に、隣接するデータポイントをクラスターに追加します。隣接するデータポイントがコアポイントであれば、その隣接ポイントもクラスターに追加します。
-
ノイズの識別: コアポイントでなく、クラスターにも属さないデータポイントはノイズとされます。
具体的には…
以下は、これらのステップを図示したものです。
A B C D E
● ● ● ● ●
- ポイントAから半径ε以内に3つのポイントがあるため、ポイントAはコアポイントです。
- ポイントBとCも半径ε以内に3つ以上のポイントがあるため、コアポイントです。
- ポイントDとEは半径ε以内にMinPts未満のポイントしかないため、コアポイントではありません。
Cluster 1 Noise
●●● ●●
ABC DE
- ポイントA、B、Cは互いに隣接しているため、クラスター1を形成します。
- ポイントDとEはコアポイントではなく、他のクラスターにも属していないため、ノイズとされます。
このように、DBSCANはデータポイント間の密度に基づいてクラスターを形成し、孤立したポイントをノイズとして識別します。
2. sklearn.clusterのDBSCANクラス
sklearn.clusterのDBSCANクラスは、PythonでDBSCANクラスタリングを実装するためのもので、上記の外観容姿の類似性に基づくDBSCANのプロセスを以下のように実行します。
1. 特徴抽出
この部分は、OpenCVの以下の関数を使用して実装します。
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
2. 類似性の計算
DBSCANクラスでは、epsパラメーターで指定された距離内のデータポイントを隣接点として扱います。デフォルトの距離計算はユークリッド距離ですが、metricパラメーターを使用して他の距離計算方法を指定することもできます。
3. DBSCANの適用
以下は、DBSCANクラスを使用してクラスタリングを行う基本的なコードの構造です。
from sklearn.cluster import DBSCAN
# データの準備(Xには特徴ベクトルが格納される)
X = ...
# DBSCANのインスタンスを作成
dbscan = DBSCAN(eps=0.5, min_samples=5)
# クラスタリングの実行
dbscan.fit(X)
# クラスタラベルの取得
labels = dbscan.labels_
-
eps: このパラメーターは、あるデータポイントからの半径εで、この範囲内にあるデータポイントが隣接点として扱われます。 -
min_samples: このパラメーターは、コアポイントと見なすために必要な隣接点の最小数です。
fitメソッドを呼び出すと、DBSCANアルゴリズムがデータに適用され、クラスタラベルが計算されます。クラスタラベルは、labels_属性から取得できます。ノイズ点はラベル-1としてマークされます。
このように、sklearnのDBSCANクラスを使用すると、DBSCANクラスタリングを簡単に適用でき、外観容姿の類似性に基づくクラスタリングなどのタスクに利用できます。
実装コード
import cv2
import numpy as np
import PySimpleGUI as sg
from sklearn.cluster import DBSCAN
# 人物検出のための準備
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
# ビデオの読み込み
video_path = 'assets/input_video_4.mp4'
cap = cv2.VideoCapture(video_path)
# PySimpleGUIのウィンドウ設定
layout = [[sg.Image(filename='', key='-IMAGE-')],
[sg.Button('Exit', size=(10, 1))]]
window = sg.Window('DBSCAN People Detection', layout, location=(800, 400))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 人物検出
boxes, _ = hog.detectMultiScale(frame, winStride=(8, 8))
# DBSCANの適用
if len(boxes) > 0:
dbscan = DBSCAN(eps=50, min_samples=1)
clusters = dbscan.fit_predict(boxes)
# クラスタごとに短形で囲む
for cluster_id in np.unique(clusters):
cluster_boxes = boxes[clusters == cluster_id]
x_min = cluster_boxes[:, 0].min()
y_min = cluster_boxes[:, 1].min()
x_max = cluster_boxes[:, 0].max() + cluster_boxes[:, 2].max()
y_max = cluster_boxes[:, 1].max() + cluster_boxes[:, 3].max()
cv2.rectangle(frame, (x_min, y_min), (x_max, y_max), (0, 255, 0), 2)
# PySimpleGUIでの表示
imgbytes = cv2.imencode('.png', frame)[1].tobytes()
window['-IMAGE-'].update(data=imgbytes)
event, values = window.read(timeout=20)
if event == sg.WIN_CLOSED or event == 'Exit':
break
cap.release()
window.close()
実行結果

SSDで人物の領域を抽出
SSD(Single Shot Multibox Detector)は、物体検出のための深層学習モデルの1つです。一度の推論で物体のクラスと位置を同時に検出するため、高速なアルゴリズムとして知られています。
SSDの特徴
- 高速: SSDは名前の「Single Shot」からもわかるように、一度の推論で物体の位置とクラスを同時に特定します。これにより、リアルタイムでの物体検出が可能です。
- 精度と速度のバランス: SSDは高速でありながら、精度も比較的高いため、多くの応用シーンで使用されます。
- 畳み込み層の使用: SSDは畳み込み層を使用して特徴を抽出し、さまざまなスケールとアスペクト比で物体を検出します。
SSDの動作
- 基本ネットワーク: 画像の特徴を抽出するための基本ネットワーク(例:VGG、ResNetなど)を使用します。
- マルチスケール特徴マップ: 基本ネットワークの畳み込み層から、さまざまな解像度の特徴マップを抽出します。これにより、大小さまざまな物体を検出できます。
- デフォルトボックス: 各特徴マップ上のセルに対して、あらかじめ定義された形状とサイズの「デフォルトボックス」を割り当てます。
- クラスと位置の予測: 各デフォルトボックスに対して、物体のクラスとバウンディングボックスの位置を予測します。
- 非最大抑制: 重複するバウンディングボックスを除去し、最終的な検出結果を得ます。
モデルのダウンロード
TensorFlow 2 Detection Model Zoo
今回は軽量モデルであるSSD MobileNet v2 320x320をダウンロードして使用しました。
ssd_mobilenet_v2_320x320_coco17_tpu-8 $ tree
.
├── checkpoint
│ ├── checkpoint
│ ├── ckpt-0.data-00000-of-00001
│ └── ckpt-0.index
├── pipeline.config
└── saved_model
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
3 directories, 7 files
実装コード
import cv2
import PySimpleGUI as sg
import tensorflow as tf
# モデルのパス
model_path = 'ssd_mobilenet_v2_320x320_coco17_tpu-8/saved_model'
# モデルの読み込み
model = tf.saved_model.load(model_path)
# 推論関数の取得
infer = model.signatures["serving_default"]
# ウィンドウの設定
layout = [[sg.Image(filename='', key='image')]]
window = sg.Window('SSD People Detection', layout, location=(800, 400))
# ビデオの読み込み
video_path = 'assets/input_video_4.mp4'
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 推論の実行
# 推論の実行
input_tensor = tf.convert_to_tensor([frame], dtype=tf.uint8) # dtypeを追加
detections = infer(input_tensor)
# 検出結果の処理
boxes = detections['detection_boxes'].numpy()[0]
scores = detections['detection_scores'].numpy()[0]
for i, box in enumerate(boxes):
if scores[i] > 0.5: # 信頼度スコアが0.5以上の場合
y1, x1, y2, x2 = map(int, box * [frame.shape[0], frame.shape[1], frame.shape[0], frame.shape[1]])
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 結果の表示(PySimpleGUI)
imgbytes = cv2.imencode('.png', frame)[1].tobytes()
window['image'].update(data=imgbytes)
event, values = window.read(timeout=20)
if event == sg.WINDOW_CLOSED or event == 'Exit':
break
cap.release()
cv2.destroyAllWindows()
window.close()
実行結果

考察
今回は、DBSCANとSSDを使用して人物抽出を行いました。
YOLOを使用したときと比べ、実行速度・精度ともに劣る結果となりました。
DBSCANに関しては、YOLOより遅いとは考えづらいため、tkに表示する段階で遅くなっているかもしれません。この点に関しては深追いしていません。
SSDに関しては、モデルの選択が悪かったのかもしれません。今回は軽量モデルを使用しましたが、重いモデルを使用すれば精度は上がるかもしれません。(EfficientDetとか)
DBSCANはHOGによって抽出された領域をクラスタリングするため、HOGの精度に依存します。HOGとCNNを比較するとやはり見劣りしてしまう点は否めません。ただ、コード中の半径εなどパラメーターを調整することで、HOGの精度を上げることができるかもしれません。この点も深追いしていません。
以上です。ありがとうございました。
Discussion