人物抽出のためのコード比較その③: Deep OC-SORT
はじめに
人物抽出は、画像や動画から特定の人物を背景から分離する技術です。
AR(拡張現実)やVR(仮想現実)のようなアプリケーションでよく使用されます。
今回は前回の記事に引き続き、人物抽出の技術を紹介します。
関連記事
リアルタイム性と追従性を重視します。今回のキーワードはDeep OC-SORTです。
環境
Python 3.8.10
(FACE01)
$ inxi -SCGxx --filter
System: Kernel: 5.15.0-46-generic x86_64 bits: 64 compiler: N/A Desktop: Unity wm: gnome-shell dm: GDM3
Distro: Ubuntu 20.04.4 LTS (Focal Fossa)
CPU: Topology: Quad Core model: AMD Ryzen 5 1400 bits: 64 type: MT MCP arch: Zen rev: 1 L2 cache: 2048 KiB
Graphics: Device-1: NVIDIA TU116 [GeForce GTX 1660 Ti] vendor: Micro-Star MSI driver: nvidia v: 515.65.01 bus ID: 08:00.0
方法
元動画

DEEP SORT(Deep Simple Online and Realtime Tracking)

DeepSORT(Deep Simple Online and Realtime Tracking)は、リアルタイムの物体追跡アルゴリズムで、以下の特徴を持っています。
-
特徴量抽出: 物体のバウンディングボックスの位置と大きさだけでなく、外観特徴も考慮します。特徴抽出ネットワークを用いて、物体の外観から特徴ベクトルを抽出し、物体の識別と追跡に使用します。
-
物体の一致: バウンディングボックスのIoUだけでなく、抽出された特徴ベクトルのコサイン距離も考慮に入れて物体の一致を決定します。
-
物体の消失と再出現: 物体が一時的に視界から消えても、その物体の追跡を続けることができます。物体の外観特徴を記憶しているため、物体が再び視界に入ったときにそれを再認識できます。
関連する手法とDeepSORTとの違い
-
SORT: Simple Online and Realtime Tracking(SORT)は、バウンディングボックスの位置と大きさのみを使用して追跡を行います。DeepSORTとの違いは、外観特徴を考慮しない点です。
-
BoTSORT: BoTSORTは、SORTを基にした改良版で、一部の特徴を共有しますが、特定のシナリオでの追跡性能が異なる場合があります。
-
DeepOCSORT: DeepOCSORTは、DeepSORTと同様に外観特徴を使用しますが、純粋な動作ベースの方法であるOC-SORTを基に、オブジェクトの外観を活用。既存の高性能な動作ベースの方法に外観マッチングを適応的に統合しました。MOT20で1位、MOT17で2位(63.9と64.9 HOTA)を達成しています。
-
OCSORT: OCSORTは、オプティカルフローを使用して物体の追跡を強化します。DeepSORTとの主な違いは、特徴抽出の方法と追跡の戦略です。
-
StrongSORT: StrongSORTは、DeepSORTの拡張版で、より強力な特徴抽出と一致戦略を持っています。計算コストが高い一方で、追跡性能が向上しています。
DEEP OC-SORT: MULTI-PEDESTRIAN TRACKING BY ADAPTIVE RE-IDENTIFICATION
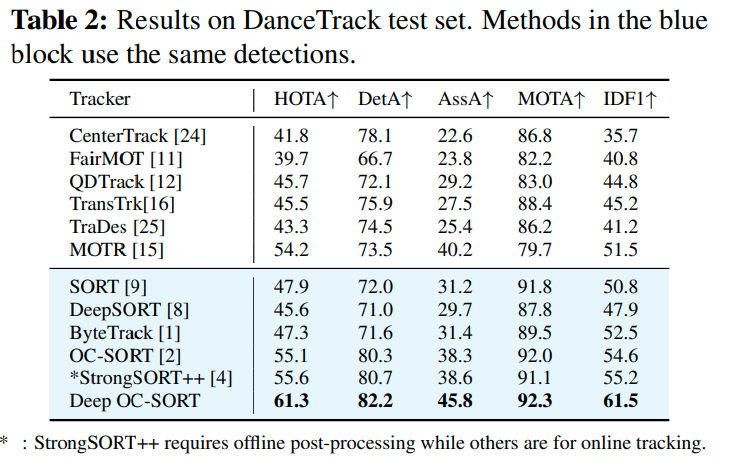
この論文から、Deep OC-SORTが優れていることが分かります。
Deep OC-SORTの実装
BoxMOT: pluggable SOTA tracking modules for object detectors. Yolov8, YoloX, YoloNAS supported. SOTA CLIP-ReID models available!!

BoxMOTは以下の特徴を有します。
-
Yolo Trackingの組み合わせ: このリポジトリは、Yolo(You Only Look Once)という物体検出アルゴリズムと、さまざまな追跡アルゴリズム(DeepSORTなど)を組み合わせて使用します。これにより、リアルタイムでの物体追跡が可能になります。
-
複数の追跡手法のサポート: DeepSORTの他にも、BoTSORT、DeepOCSORT、OCSORT、StrongSORTなどの追跡手法をサポートしてるので、さまざまなシナリオや要件に合わせて追跡手法を選択できます。
-
リアルタイム追跡: リアルタイムでの物体追跡が可能で、ウェブカメラやビデオファイルからの入力に対応しています。
-
柔軟な設定: コマンドライン引数を通じて、使用するモデル、追跡手法、閾値などの設定が可能なので、ユーザーが自分のニーズに合わせてカスタマイズできます。
-
依存関係の管理: 必要なパッケージやモデルのダウンロードを自動化しており、セットアップが超簡単です。
このリポジトリをgit cloneして、動作環境を簡単に作れます。
# Python仮想環境を作成
python3 -m venv .
. bin/activate
# git clone
git clone https://github.com/mikel-brostrom/yolo_tracking.git
# セットアップ
pip install -v -e .
YOLOv8 | YOLO-NAS | YOLOX examplesにしたがって、以下のように実行します。
python examples/track.py \
--yolo-model yolov8n \
--tracking-method deepocsort \
--source assets/input_video_3.mp4 \
--save \
--classes 0 \
--device 0 \
--vid-stride 2 \
--line-width 2
実行結果は/home/terms/ドキュメント/extract people from video/runs/track/expにavi形式で保存されます。

期待通りに動作してくれました。
それでは、track.pyを修正して、tkで表示されるようにしてみます。
track.pyの修正
@torch.no_grad()
def run(args):
# YOLOトラッキングの実行
yolo = YOLO(
args.yolo_model if 'yolov8' in str(args.yolo_model) else 'yolov8n.pt',
)
results = yolo.track(
source=args.source,
conf=args.conf,
iou=args.iou,
show=args.show,
stream=True,
device=args.device,
show_conf=args.show_conf,
show_labels=args.show_labels,
save=args.save,
verbose=args.verbose,
exist_ok=args.exist_ok,
project=args.project,
name=args.name,
classes=args.classes,
imgsz=args.imgsz
)
yolo.add_callback('on_predict_start', partial(on_predict_start, persist=True))
if 'yolov8' not in str(args.yolo_model):
# replace yolov8 model
m = get_yolo_inferer(args.yolo_model)
model = m(
model=args.yolo_model,
device=yolo.predictor.device,
args=yolo.predictor.args
)
yolo.predictor.model = model
# store custom args in predictor
yolo.predictor.custom_args = args
# PySimpleGUIのウィンドウ設定
if args.show_tk:
layout = [[sg.Image(filename='', key='-IMAGE-')]]
window = sg.Window('YOLO Tracking', layout, location=(800, 400))
for frame_idx, r in enumerate(results):
if r.boxes.data.shape[1] == 7:
if yolo.predictor.source_type.webcam or args.source.endswith(VID_FORMATS):
p = yolo.predictor.save_dir / 'mot' / (args.source + '.txt')
yolo.predictor.mot_txt_path = p
processed_img = r.orig_img.copy()
for box in r.boxes.data:
x1, y1, x2, y2, id, confidence, class_id = map(float, box)
x1, y1, x2, y2, id, class_id = map(int, [x1, y1, x2, y2, id, class_id]) # 整数型に変換
confidence = round(confidence * 100) # 小数点以下2桁までの表示にするため100倍して四捨五入
cv2.rectangle(processed_img, (x1, y1), (x2, y2), (0, 255, 0), 2)
# クラス名のマッピング(この例では0がpersonに対応)
class_names = {0: "hito"}
class_name = class_names.get(class_id, "")
# テキストの描画(クラス名、信頼度など)
text = f"id:{id} {class_name} {confidence}%"
cv2.putText(processed_img, text, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
if args.show_tk:
event, values = window.read(timeout=0)
imgbytes = cv2.imencode('.png', processed_img)[1].tobytes()
window['-IMAGE-'].update(data=imgbytes)
if event == sg.WINDOW_CLOSED:
break
def parse_opt():
# 引数の設定
class Args:
def __init__(self):
self.yolo_model = Path(WEIGHTS / 'yolov8n')
self.reid_model = Path(WEIGHTS / 'osnet_x0_25_msmt17.pt')
self.tracking_method = 'deepocsort'
self.source = 'assets/input_video_4.mp4'
self.imgsz = [640]
self.conf = 0.5
self.iou = 0.7
self.device = '0'
self.show_tk = True
self.show = False
self.save = True
self.classes = [0]
self.project = ROOT / 'runs' / 'track'
self.name = 'exp'
self.exist_ok = False
self.half = False
self.vid_stride = 4
self.show_labels = True
self.show_conf = True
self.save_txt = False
self.save_id_crops = False
self.save_mot = False
self.line_width = 1
self.per_class = False
self.verbose = True
return Args()

非常に負荷が高いですが、一応期待通りに動作しています。
それでは、背景を透明化しましょう。
コードの改変部分は、以下のようになります。
for frame_idx, r in enumerate(results):
if r.boxes.data.shape[1] == 7:
if yolo.predictor.source_type.webcam or args.source.endswith(VID_FORMATS):
p = yolo.predictor.save_dir / 'mot' / (args.source + '.txt')
yolo.predictor.mot_txt_path = p
processed_img = r.orig_img.copy()
# 透明化用のマスクを作成(全て0で初期化)
mask = np.zeros_like(processed_img[:, :, 0])
for box in r.boxes.data:
x1, y1, x2, y2, id, confidence, class_id = map(float, box)
x1, y1, x2, y2, id, class_id = map(int, [x1, y1, x2, y2, id, class_id]) # 整数型に変換
# 人物の領域をマスクに追加(人物の領域を1に設定)
mask[y1:y2, x1:x2] = 1
confidence = round(confidence * 100) # 小数点以下2桁までの表示にするため100倍して四捨五入
cv2.rectangle(processed_img, (x1, y1), (x2, y2), (0, 255, 0), 2)
# クラス名のマッピング(この例では0がpersonに対応)
class_names = {0: "hito"}
class_name = class_names.get(class_id, "")
# テキストの描画(クラス名、信頼度など)
text = f"id:{id} {class_name} {confidence}%"
cv2.putText(processed_img, text, (x1, y1 + 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 透明化処理
# マスクを4チャンネルに拡張(RGBチャンネルは全て1、アルファチャンネルはmaskに基づく)
alpha_channel = (mask * 255).astype(np.uint8)
# 元の画像にアルファチャンネルを追加
processed_img_with_alpha = np.concatenate([processed_img, alpha_channel[:, :, np.newaxis]], axis=2)
if args.show_tk:
event, values = window.read(timeout=0)
imgbytes = cv2.imencode('.png', processed_img_with_alpha)[1].tobytes()
window['-IMAGE-'].update(data=imgbytes)
if event == sg.WINDOW_CLOSED:
break

出来ました!
考察
今回はDeep OC-Sortを使用して、人物抽出を行いました。
横着してhttps://github.com/mikel-brostrom/yolo_trackingリポジトリをそのまま、あるいは加筆修正して使用しましたが、そのせいで、場当たり的で分かりにくいコードになってしまいました。
このリポジトリが想定するような使い方ではないので、仕方のないことではあります。
ライセンス的にも使いづらい印象です。Ultralytics Licensing
また、外観をもとにした追跡手法ではありましたが、それほど精度良く追跡できているとは言えませんでした。手前の人物で、後側の人物が隠れてしまうと、度々IDが入れ替わってしまいます。
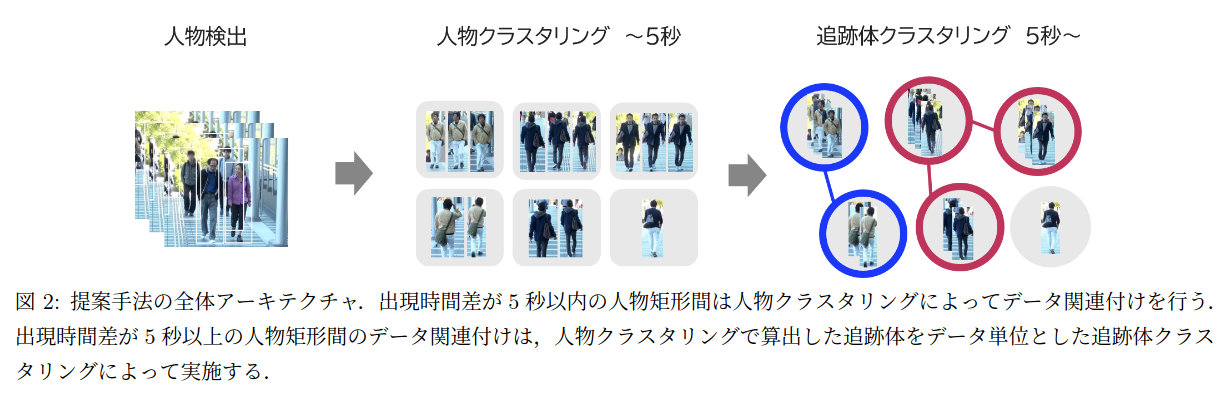
これについては「人物再同定に基づく段階的クラスタリングを用いた複数人物追跡」というNECバイオメトリクス研究所の論文が参考になりそうです。

結論
以上です。
今後は、人物のIDと得られた複数枚の画像を紐付けて、人物の再同定を行い、より精度の高い人物抽出を行いたいと思います。
Discussion