1. はじめに👋
Difyを使えば、PDFやテキストファイルをアップロードするだけで、誰でも簡単にRAG(検索拡張生成)環境を構築することができます。しかし、いざ使ってみると、以下のような課題に直面することはありませんか?
- ナレッジに回答が存在するにも関わらず、「分かりません」と回答される (回答拒否)
- 無関係な情報を参照し、もっともらしい誤情報を生成する (ハルシネーション)
これは、DifyやLLMの性能不足ではなく、「データの前処理」と「検索設定の最適化」が適切にされていないことが原因です。
この記事では、RAGの仕組みを噛み砕いて解説し、各設定の意味やおすすめ設定、検索精度を高めるためのテクニックなどをご紹介します。
2. RAGとは?📚
まず前提として、RAG(Retrieval-Augmented Generation)について簡単に整理しておきましょう。
RAGとは、ChatGPTやGeminiなどのLLM(大規模言語モデル)に対し、外部の知識を検索・参照させたうえで回答を生成させる技術です。
LLMは一般的な知識は豊富ですが、「社内の就業規則」や「今朝発表されたばかりのニュース」までは学習していません。そこで、LLMが本来知り得ない独自データや最新情報を後から補い、それに基づいて回答させる仕組みがRAGです。これを活用することで、特定の外部情報(ナレッジ)に基づいた問い合わせ対応チャットボットなどが作成可能になります。
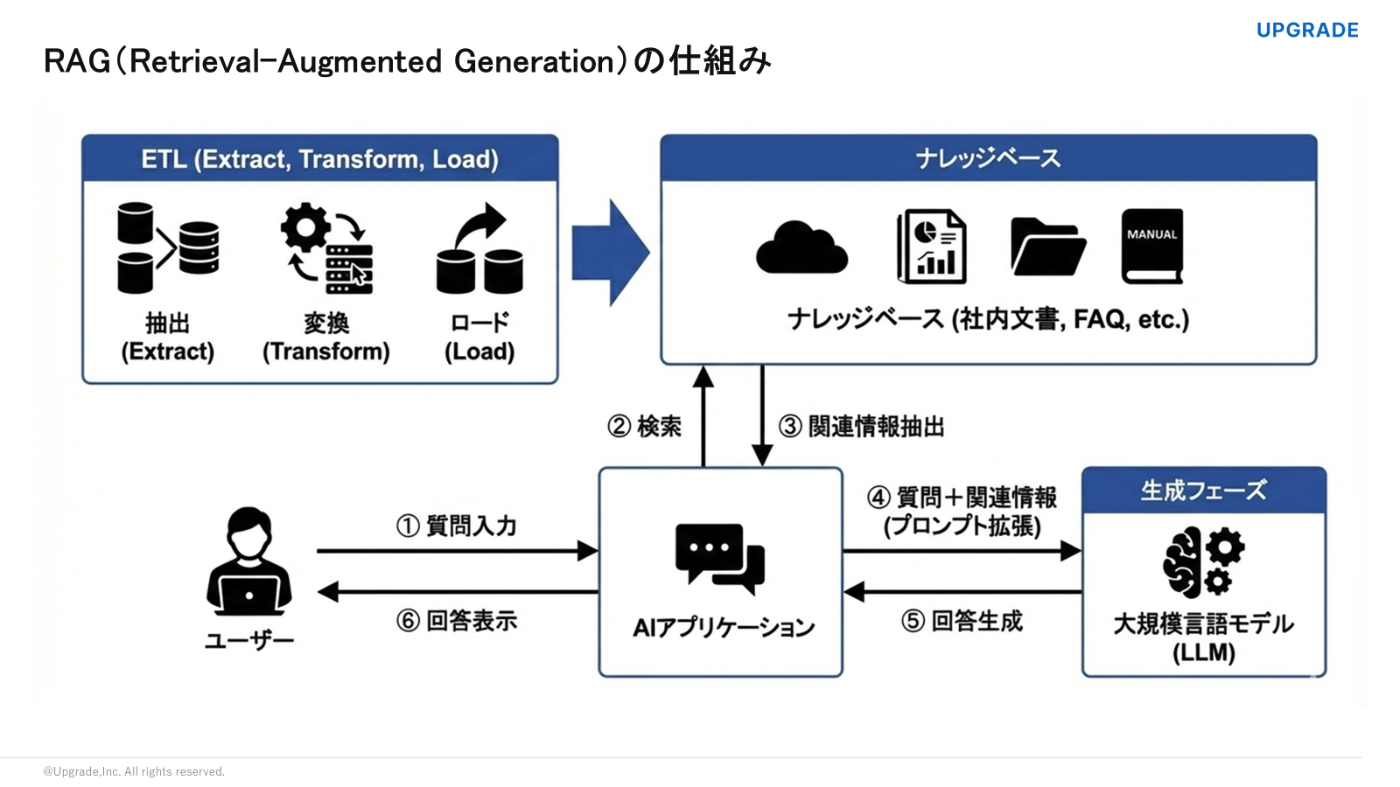
そして、RAGの回答精度を高めるためには、大きく分けて次の2つのアプローチが必要です。
- 登録するナレッジデータを適切に整理する
- ナレッジの検索設定を最適化する
ここからは、Difyを使ってこれらをどう実現していくか、順を追って詳しく見ていきましょう。
【用語解説】RAGとナレッジの違い
-
RAG(ラグ):システム全体のこと
- 外部データを検索して回答を作成する「仕組み」や「プロセス全体」を指します。
- 料理でのイメージ👨🍳: カレーを作る「工程(食材を切る・煮込む・盛り付ける)」
-
ナレッジ(Knowledge):データそのもののこと
- Difyに登録した「ドキュメント(PDF、テキストなど)の集合体」を指します。
- 料理でのイメージ🍳: 冷蔵庫の中にある「食材(肉・野菜・スパイス)」
3. 精度を左右する『ナレッジ』の登録プロセス🗃️
なぜナレッジの「質」が重要なのか
データサイエンスの世界には以下の原則があります。
「Garbage In, Garbage Out(質の悪いデータを入れれば、質の悪い結果しか出ない)」
これは生成AIにおいても言えることで、どれだけ高性能なLLMを使用しても、参照するデータ(ナレッジ)が整理されていなければ、適切な回答は期待できません。
そこで、ここではDifyが裏側で行っているETLプロセスに沿って、最適なナレッジ登録の手順を解説します。
ETLプロセスとは?
データ統合の基本プロセスで、【Extract(抽出)→ Transform(加工)→ Load(保存)】の頭文字を取ったものです。Difyでもナレッジを作成する際、裏側ではこの3ステップが実行されています。
STEP1:📥Extract(抽出)
まずは、Difyにデータを読み込ませるフェーズです。

Difyはテキストファイル(PDF, Word, Markdown等)だけでなく、Notionやウェブサイトのデータを同期させることができます。
Notion同期の留意点
- リアルタイム同期ではない: Notion側を更新しても、Dify側で「同期ボタン」を押さない限り反映されません。
- 画像や埋め込みコンテンツは取得不可: テキスト情報は取得できますが、ページ内に貼られた画像やYouTubeリンクの中身までは読み取れません。
ウェブサイト同期の留意点
- APIキーが必要: FirecrawlやJinaなどの外部スクレイピングサービスのAPIキー設定が必要です。
また、ドキュメント内に画像が含まれている場合、それらをナレッジとして取り込む(URL化する)には、主に以下の2つのアプローチがあります。
-
Wordファイルの場合
従来のナレッジ登録フローで対応可能です。文書内の画像は自動的に認識され、ナレッジベース内にURLとして保存されます。 -
PowerPointの場合
ナレッジパイプラインの「Dify Extractor」を活用すると、PowerPoint内の画像を抽出し、URL化して保存することが可能になります。
【用語解説】ナレッジパイプラインとは?
「ナレッジパイプライン」とは、ver.1.9.0以降で利用可能になった、ナレッジ作成におけるデータ処理を自動化・効率化するための機能です。
ナレッジパイプラインを用いた画像データの管理・抽出方法については、弊社のナレッジパイプライン解説記事(こちら)をご覧ください。
STEP2:✂️ Transform(加工)
次は、取り込んだデータをAIが理解・検索しやすい形に加工します。
① テキストの前処理(クリーニング)
まずはデータに含まれるノイズを除去します。
推奨:PDFのヘッダー・フッター、ページ番号、無意味な特殊文字、連続する改行などは削除することをお勧めします。これらが残っていると、検索ノイズ(異物混入)となり、AIが文脈を見失う原因になります。
② 適切なサイズへの分割(チャンキング)
長い文章をすべてLLMに読み込ませるのではなく、クエリに関連する部分だけを抽出してコンテキストとして渡せるよう、検索しやすいサイズに切り分けます。Difyでは、データの特性に合わせてモードを使い分けることが重要です。
今回は、以下のような就業規則ダミーデータを使用して、それぞれのモードで実際にどのように分割されるかを見ていきましょう。

Word形式の就業規則ダミーデータ
1. 汎用モード(General)
最も標準的な設定です。「改行」や「句読点」などの識別子を目印に、機械的に文章を区切ります。
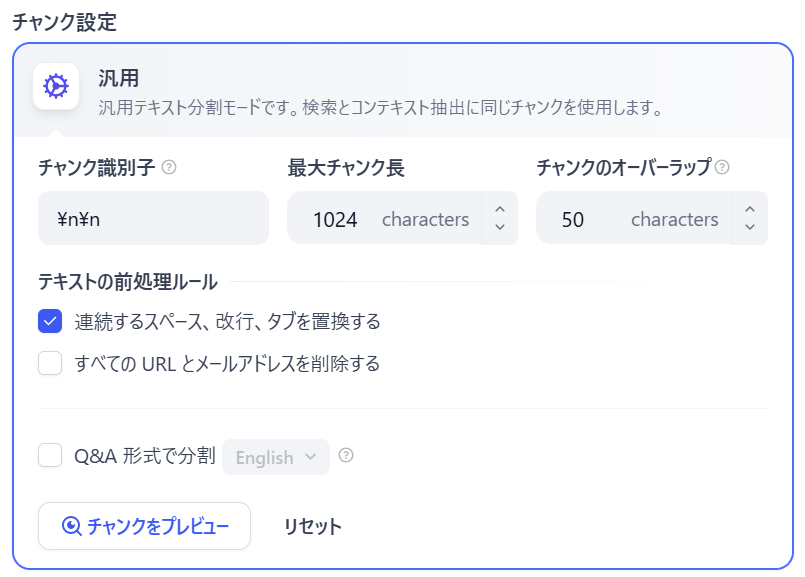
-
チャンク識別子: どこで分割するかを指定します。
- 一般的には「
\n\n(改行)」や「;」などが使われます
- 一般的には「
-
最大チャンク長: 1つの塊の文字数(トークン数)です。
- 最大4000文字まで設定可能です
- 長すぎると「検索で見つけにくい」、短すぎると「文脈が切れる」ためバランスが重要になります
-
チャンクのオーバーラップ: 前後のチャンクを「あえて重複させる」設定です。
- 重要な情報がちょうど「切れ目」に来てしまった場合でも、前後の重複部分でカバーすることで情報の欠落を防ぎます
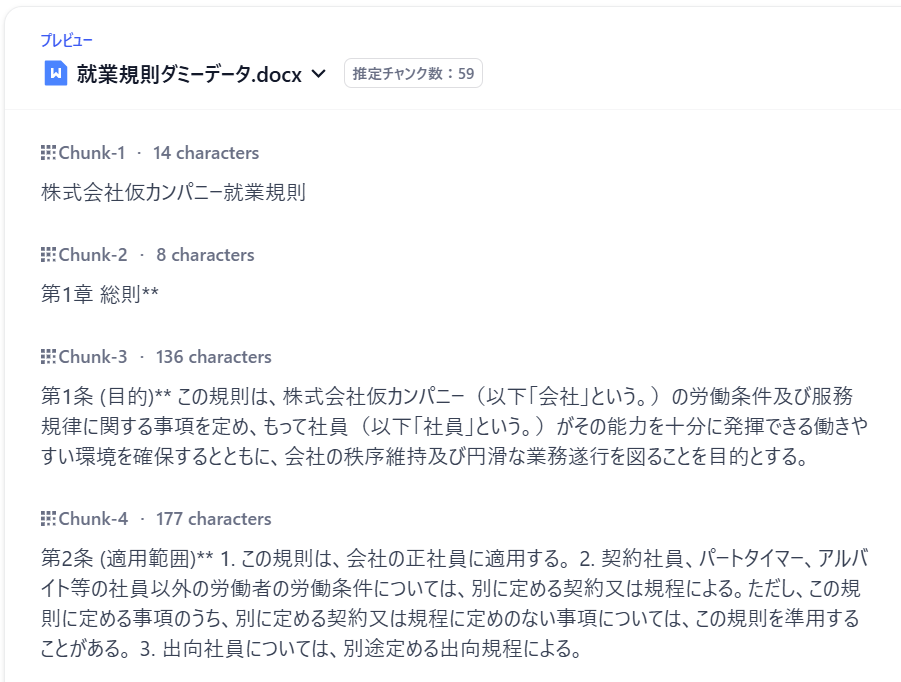
汎用モードで分割した就業規則ダミーデータ
💡 設定値のベストプラクティス
「数値の設定に迷う」という方は、まずは以下の値を基準にしてください。
マイクロソフト社の技術検証[1]において、ハイブリッド検索環境では以下の設定が高いパフォーマンスを示すと報告されています。
- チャンクサイズ:512 トークン
- オーバーラップ:25% 前後
※これはあくまで目安です。最適な設定はドキュメントの構成によって異なるため、Difyのプレビュー機能で実際の分割結果を確認しながら、微調整することをお勧めします。
2. 親子チャンクモード(Parent-Child)
検索用には「具体的な情報を含む小さなチャンク(子)」を使い、LLMには回答生成用のコンテキストとして「広範な情報を持つ大きなチャンク(親)」を渡す高度な仕組みです。
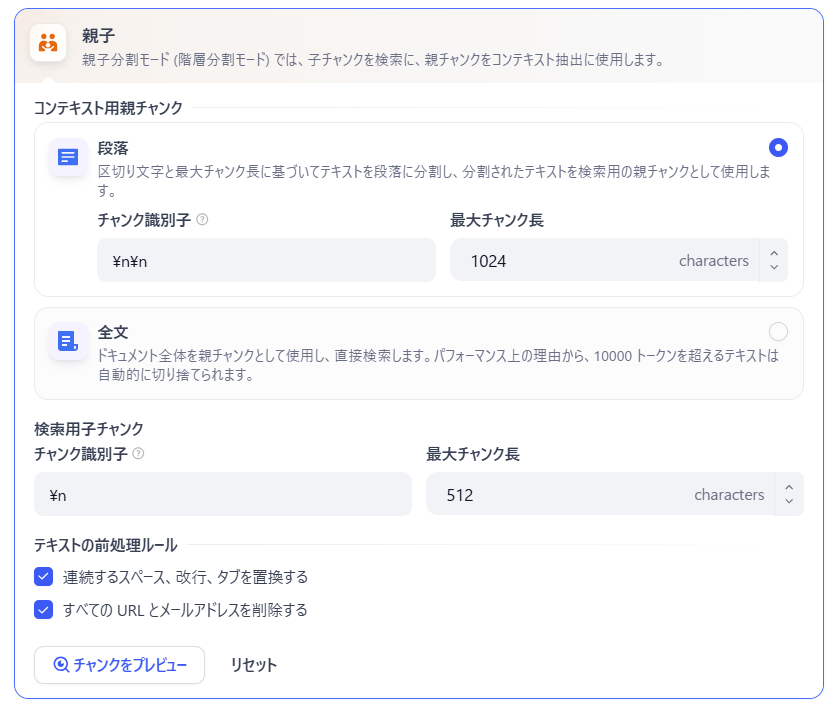
親子チャンクモードでは、細かい情報にも正確にアクセスしつつ、文脈を理解するための広いコンテキストも保持することができるため、以下のようなシーンで活躍します。
- 契約書・就業規則(文脈補完): 特定の規則(項)を検索したいが、その規則が適用されるための「前提条件」や「定義」が、条文全体(親)の方に記載されている場合。
- マニュアル・製品仕様書(ID検索): 「エラーコード E-01」や「型番 S-100」といったIDでピンポイントに検索し、回答にはそのIDが含まれる「スペック表全体」や「トラブルシューティングの全手順」を含めたい場合。
具体的な動作イメージ
親子チャンクが活躍する2つのパターンを紹介します。
ケース①:就業規則(文脈の補完)
「パートの規定は?」と質問するシーンを想像してください。
- 検索(子チャンク): 「パートタイマー...については、別に定める...」という特定の文言(子)がキーワードでヒットします。
- 生成(親チャンク): LLMには、その一文だけでなく、「この規則は、会社の正社員に適用する」という大前提が書かれた第2条全体(親) が渡されます。
- 結果: LLMは単に「別規定による」と答えるだけでなく、「原則としてこの規則は正社員用であり、パートタイマーには別途規定がある」という、条文全体の構造を理解した正確な回答が可能になります。
ケース②:製品カタログ(IDからの仕様抽出)
「型番 X-2000のスペックを知りたい」と質問するシーンを想像してください。
- 検索(子チャンク): 表の中に書かれた「X-2000」という型番(子)をピンポイントで見つけ出します。
- 生成(親チャンク): LLMには型番単体ではなく、その型番が記載されている 「製品仕様一覧表」の全体(親) が渡されます。
- 結果:「X-2000の重量は500g、バッテリー持続時間は12時間です」といった表構造を崩さない完全な回答が可能になります。
詳しくは、弊社の親子チャンク解説記事(こちら)をご覧ください。
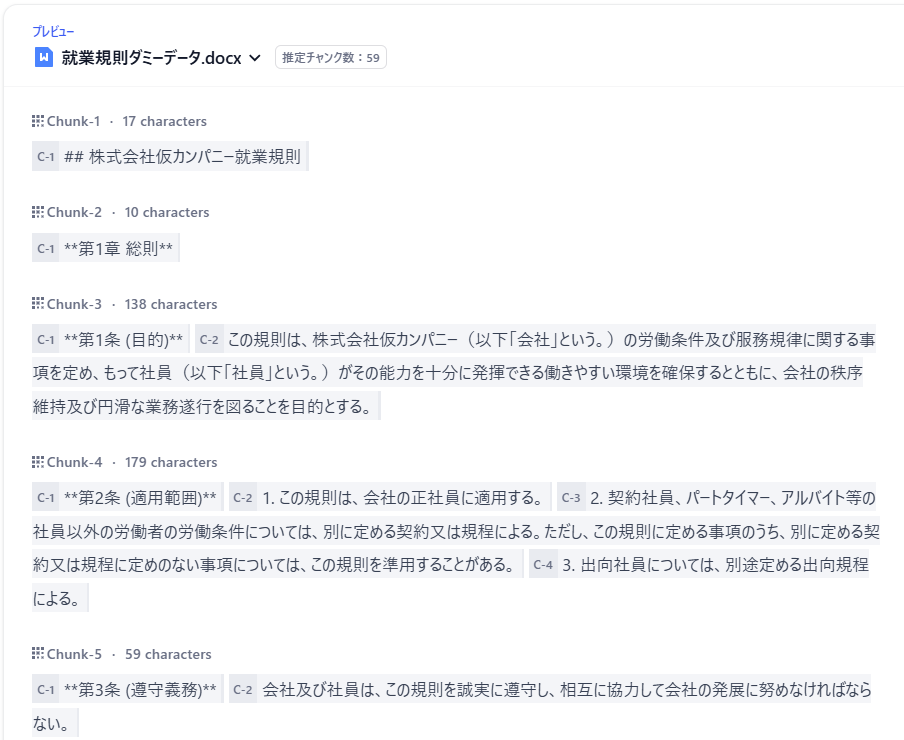
親子チャンクモードで分割した就業規則ダミーデータ
📊 モード比較表
| 設定名 | 処理メカニズム | メリット | デメリット |
|---|---|---|---|
|
汎用モード (標準) |
【切断】 文字数や記号で機械的にカットする |
・処理が高速 ・コストがかからない |
・複雑な文脈の維持が苦手 |
|
Q&A形式 (応用) |
【生成】 AIが内容を理解し、質問集を作る |
・検索ヒット率が高い ・口語体の質問に強い |
・APIコストが発生する |
|
親子チャンク (階層化) |
【構造化】 検索用(小)と回答用(大)を分ける |
・検索精度と文脈理解を両立 | ・ある程度綺麗にまとまったデータが必要 |
STEP3:🗄️Load(保存)
最後に、加工したデータをデータベースに保存します。ここでDify独自の重要な設定項目「インデックス方法」が登場します。
「高品質」と「経済的」の比較
設定画面には「高品質」と「経済的」がありますが、実務レベルの回答精度を求めるのであれば、「高品質」の選択をおすすめします。

| 設定 | 仕組み | メリット | デメリット | 用途 |
|---|---|---|---|---|
|
高品質 (推奨) |
ベクトル検索 テキストを、「類似度を計算できるベクトル(数値)」に変換して保存 |
言葉の揺らぎ・文脈を理解できる 例:「スマホ」で検索しても「iPhone」や「携帯」の記事がヒットする |
Embeddingモデル(OpenAIなど)の使用料がわずかに発生する | AIチャットボット全般 |
| 経済的 |
キーワード検索 チャンクから主要な10個のキーワードを自動抽出して索引化(転置インデックス) |
トークン消費がなく無料で使える | 検索ワードが一致しないとヒットしない (「スマホ」で検索しても「携帯」は出ない) |
単純な用語検索ツールなど |
【用語解説】Embedding(埋め込み)とは?
Embeddingとは、テキストを 「数値の羅列(ベクトル)」に変換する技術 のことです。
イメージ:文章の意味を多次元の「座標」に変換し、意味が近い言葉(「王様」と「皇帝」など)を座標上の近い場所に配置する
これにより、単語が違っても意味が似ていれば検索できるようになります。
「高品質」を選んだ場合、どのモデルを使って数値化するかを選びます。Difyでは text-embedding-3-largeや Cohere などが選択可能です。
⚠️注意:「高品質」を選択した後に、「経済的」に戻すことはできません。
4. 検索精度の最適化:Difyの設定テクニック🔍
ナレッジの登録(ETL)が終わったら、次はそのデータを「どう探し出すか」を決める検索設定を行います。ここがチャットボットの応答品質を決める重要なチューニングポイントになります。
検索モードの比較と使い分け
インデックス方法で「高品質」を選んだ場合、以下の3つの検索モードから選ぶことができます。
1. ベクトル検索(意味の類似性)
意味の類似性をもとに検索する、典型的なRAGの検索方法です。
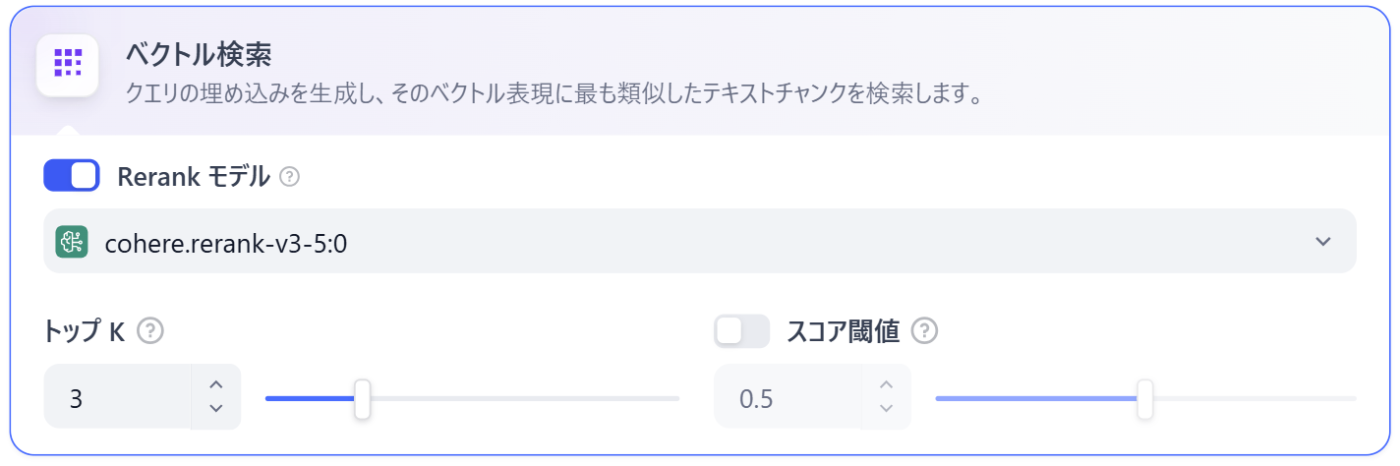
-
得意なこと: 文脈の理解
- 「テレワーク」と検索して「リモートワーク」や「在宅勤務」の規定を探し出すことができます。
-
苦手なこと: 固有名詞やIDの検索
- 「S001」「Pro-A23」といった意味的な文脈を持たない記号などは、ベクトルの距離が近づきにくく見つけられないことがあります。
2. 全文検索(キーワード一致)
字列の完全一致や頻度に基づいて検索する方法です。

-
得意なこと: 固有名詞やIDの検索
- 文字列が完全一致すれば確実に見つけ出します。
-
苦手なこと: 意味の類似性
- 「テレワーク」で検索しても、文章中に「テレワーク」という単語がなければ、「リモートワーク」の記事はヒットしません。
3. ハイブリッド検索
ベクトル検索と全文検索を同時に実行し、それぞれの結果を統合する方法です。
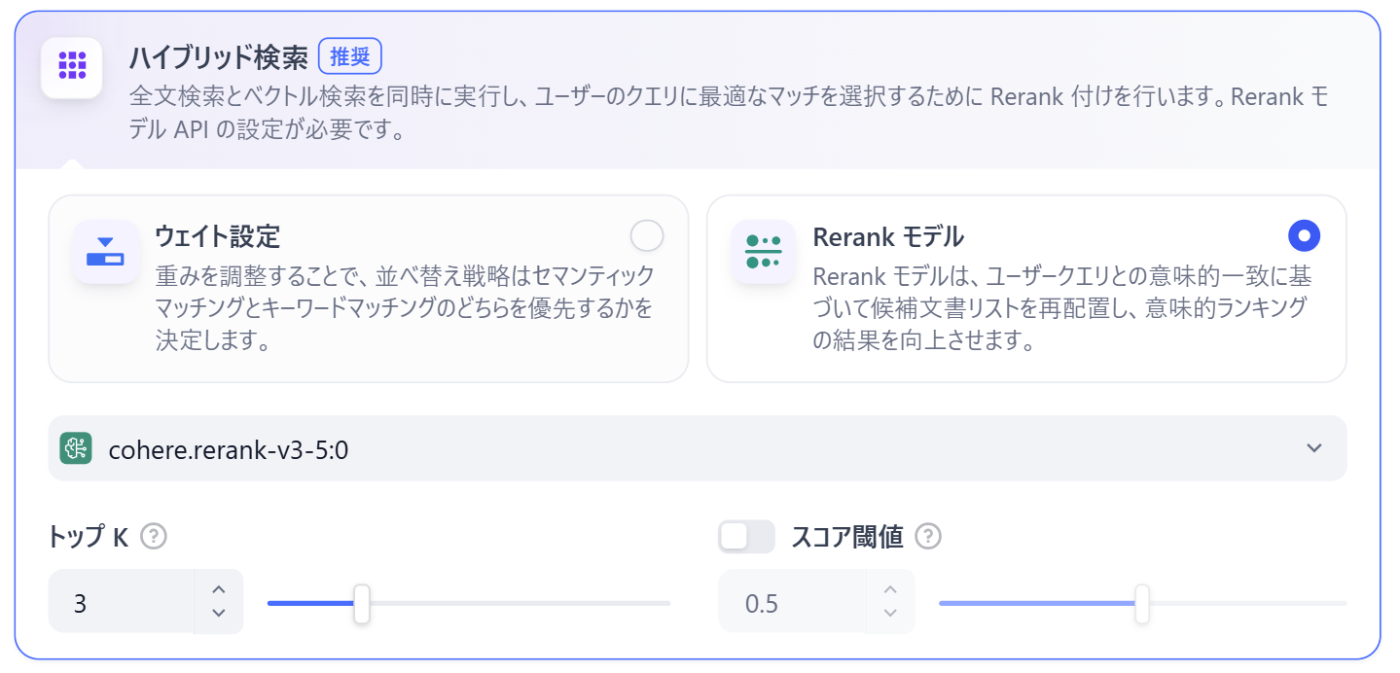
ハイブリッド検索の場合、ベクトル検索と全文検索の比重を以下の二種類の方法から選んで設定することができます。
- ウェイト設定:「ベクトル検索の結果を7割、キーワード検索の結果を3割重視する」といったように、手動で重み付けをする方法
-
Rerankモデル:クエリと検索されたドキュメントのペアを入力として受け取り、LLMが読み込んで採点し直す方法
- ベクトル検索とキーワード検索の結果を統合し、「意味の近さ」と「単語の正確さ」の両方を考慮して、最も適切な順序に並べ替えます。
Rerankモデルの例:クエリ「S001が関わった新商品の市場投入について」
- ベクトル検索: 「市場投入」の文脈を持つが、S001を含まない記事を拾ってしまう。
- 全文検索: 「S001」を含むが、市場投入とは関係ない記事を拾ってしまう。
- Rerank後: 両方の要素を詳細に評価し、「社員S001」の「新商品Xの市場投入」に関するチャンクを最上位に配置できる。
📊 検索比較表
| 検索モード | 仕組み | 推奨シーン |
|---|---|---|
| ベクトル検索 | 意味の近さで検索 | 一般的な会話、抽象的な質問 |
| 全文検索 | キーワード一致で検索 | 型番検索、専門用語の定義検索 |
|
ハイブリッド検索 (Rerank推奨) |
ベクトル + 全文 + 再評価 | 全てのシーン(特に実務利用) |
【補足】「保存時の設定」と「検索時の設定」の違い
よくある疑問として、「保存(Load)するときにもベクトルとか選んだのに、なぜ検索するときも選ぶの?」というものがあります。
-
Load(保存・インデックス化)=「本の並べ方を決める」
- 図書館を作る時に、「本を内容のジャンル順(ベクトル)で棚に並べるか」、それとも「タイトルのあいうえお順(キーワード)で並べるか」を決める作業です。
-
検索設定(Search Setting)=「本の探し方を決める」
- お客さん(ユーザー)が来た時に、「ジャンルの棚を見て探すか(ベクトル検索)」、「検索機でタイトル検索するか(キーワード検索)」を決める作業です。
TopKとスコア閾値の調整
検索モードが決まったら、次は「どれくらいの量を」「どのくらいの厳しさで」取得するかを調整します。
Top K(取得数)
検索で見つかったチャンクを 「類似スコアが高い順(=関連性が高い順)」に並べ替え、上から最大で何個までをLLMに渡すかを決める設定です。
- 設定の目安: 1~10の間で設定できますが、通常は 3~5 程度が適切です。
- 注意点: 10などに設定して、LLMに渡す情報量が多すぎると、重要な情報が埋もれて無視される 「Lost in the Middle(情報の迷子)」現象が起きたり、回答生成の遅延が増加します。
スコア閾値(Score Threshold)
「類似スコアがこの数値を下回るチャンクはすべて無視する」 という最低品質ライン(足切りライン)の設定です。
- 設定の目安: 最初は 0.5 程度にしておき、関係ない情報が混ざるなら上げて(0.6~0.7)、答えが出ないなら下げるなど、ナレッジ登録後の検索テストで実際の回答を見て、微調整することをおすすめします。
- 注意点: 閾値を高くしすぎると、表現が少し違うだけで本当に必要なチャンクまで除外してしまうリスクがあります。
その他の検索テクニック
RAGの検索精度をさらに高めるために、有効な検索テクニックを3つ紹介します。
1. クエリ書き換え (Query Rewriting)
チャットボットとやり取りをしているときに、ユーザーは会話の流れを前提にして、
- 「この〇〇は?」
- 「さっきの話の続きなんだけど」
- 「使い方は?」
といった指示語だけで質問することがあります。
しかし、文脈情報が欠落したこの状態のまま検索を実行しても、ユーザーの意図を正しくベクトル化できず、検索精度が低下します。
そこで役立つのが、LLMを使って直前の会話履歴をもとに質問文を意味の通る完全な文章へ書き換えてから検索する手法です。
- ユーザー: 「使い方は?」
- LLMによる書き換え: 「(直前に話題に出ていた製品Aの)使い方は(どうすればいいですか)?」
- → この情報が正しく補われた文章で検索を実行することで、検索精度が大幅に向上します。
クエリ書き換えについて、詳しくは弊社の解説記事(こちら)をご覧ください。
2. HyDE法 (Hypothetical Document Embeddings)
HyDE法は、LLMに仮想の回答を先に生成させてから検索を行う高度な手法です。
手順は以下の通りです:
- 質問に対してLLMが「仮の回答」を生成する
- その生成文章とナレッジ内の文書を比較し、内容が近いものを検索する
この手法では質問文との単語一致ではなく、回答内容の文脈一致で検索できるため、関連度の高い情報を取得しやすくなります。
HyDE法について、詳しくは弊社の解説記事(こちら)をご覧ください。
3. メタデータフィルタリング
単純なテキスト検索だけでは、「内容は似ているが、実は関係ない古い資料」や「別の部署の同名ファイル」などがノイズとしてヒットしてしまうことがあります。
これを防ぐために、ドキュメントに付与された属性情報(メタデータ)を使って、検索範囲を事前に絞り込む手法です。
- 仕組み: ナレッジを登録した後に、ナレッジベースから「カテゴリ」「作成日」「部署」などのタグ(メタデータ)を付与しておき、検索時にその条件でフィルタリングをかけます。
- 活用例: 「今年の〇〇の請求書は?」と聞かれた際、全データから探すのではなく、 「2025年度」かつ「経理部」 というタグが付いたデータだけに絞ってから検索を実行します。
- メリット: 探索範囲が物理的に限定されるため、関係ない情報が混ざる余地がなくなり、検索精度が向上します。
メタデータフィルタリングについて、詳しくは弊社の解説記事(こちら)をご覧ください。
5. まとめ🎯
今回の解説を通じ、実務で使えるRAGの構築には、単なるファイルアップロードではなくデータの前処理と検索のチューニングが不可欠であることが分かりました。
-
ETLプロセスの徹底: 適切な
クリーニングとチャンク設定(オーバーラップ等)を行うことは、LLMが正しく情報を拾うための土台となります。 -
検索設定の最適化: 実務においては、ベクトル検索だけでなくキーワード検索も併用する
ハイブリッド検索や、結果を再評価するRerankモデルの活用が、回答精度を確実に高めるための有効な手段です。

株式会社アップグレードは、エンタープライズ企業の生成AI活用における戦略立案から実装までを一貫して支援する専門企業です。本ブログでは、AI Workflow設計、AI Agent開発、RAGシステム構築、各種LLMの実践的活用手法など、技術的知見を共有します。| Dify公式パートナー
Discussion