はじめに
こんにちは!この記事では、LLM アプリケーション開発プラットフォームである Dify を使って、より自然な会話ができるチャットボットを構築する方法について解説します。特に、会話変数を効果的に活用し、ユーザーとの対話をよりスムーズで文脈に沿ったものにするためのテクニックに焦点を当てます。
単純に会話変数をプロンプトに含めるだけでは、期待通りの応答が得られないことがあります。この記事を通して、その課題と解決策を学び、より高度なチャットボット開発を目指しましょう。
1. 会話変数とメモリ機能の違い
Dify には会話の文脈を維持するための機能として「会話変数」と「メモリ」がありますが、これらは異なる役割を持っています。
-
メモリ機能: Difyに組み込まれている標準的な機能で、直近の会話のやり取りを自動的にLLMのコンテキストに含めて応答を生成する方法です。
【メリット】
- 設定が容易: Difyのインターフェース上でメモリ機能を有効にするだけで利用でき、特別な設定やフロー設計が不要です。
- 自然な会話の流れ: 直近の文脈を自動で考慮するため、短期的な会話の連続性を保ちやすく、自然な対話体験を提供しやすいです。
【デメリット】
- トークン消費: 会話履歴全体をコンテキストとして渡すため、特に会話が長くなるとLLMへの入力トークン数が多くなり、コスト増加やLLMのコンテキスト長上限に達する可能性があります。
- 情報の取捨選択ができない: 関連性の低い過去のやり取りもコンテキストに含まれてしまい、LLMが混乱したり、応答の精度が低下したりする可能性があります。重要な情報だけを選択的に記憶させることが困難です。
-
会話変数: Difyのフロー内で、会話の中から特定の情報(ユーザーの名前、以前の発言の要点、決定事項など)を抽出し、「変数」として保存・管理し、その変数を後続のプロンプトに組み込むことで、過去の情報を参照させる方法です。
【メリット】
- 精密な制御: どの情報を、どのタイミングで記憶させ、いつ利用するかを開発者が完全に制御できます。会話の初期に得た重要な情報を、会話の最後に至るまで確実に保持・利用することが可能です。
- 長期的な記憶: 変数として保存された情報は、会話セッションが続く限り保持されるため、LLMメモリ機能のようなターン数やトークン数の制限を受けにくいです。
- 効率的なトークン利用: 必要な情報だけを変数としてプロンプトに含めるため、会話履歴全体を送るよりもトークン数を節約でき、コスト削減やコンテキスト長制限の回避につながります。
- 構造化された情報: 情報を特定の変数名で管理するため、LLMに対して「ユーザー名」や「前回の要望」といった形で明確に情報を提示でき、より的確な応答を引き出しやすくなります。
【デメリット】
- 設計・実装の複雑さ: どの情報を変数として抽出・保存するか、そのためのロジック(例: プロンプトエンジニアリング、キーワード抽出、正規表現など)をDifyのフロー内で設計・実装する必要があります。初期の開発コストが高くなります。
- メンテナンスの手間: 会話の目的や必要な情報が変わった場合、変数の抽出ロジックや利用箇所を修正する必要があり、メンテナンスの手間がかかります。
- 予期しない情報の欠落: 設計時に想定していなかった重要な情報が会話中に出てきた場合、それが変数として保存されていなければ、後で参照することができません。柔軟性に欠ける可能性があります。
- 生成精度への不安: 会話変数を入力するだけでは、過去の会話履歴を適切に参照した応答を生成できない場合があります。
この記事で主に焦点を当てるのは、後者の会話変数です。会話変数をうまく活用することで、AI はユーザーの発言の意図をより正確に捉えるかつコスト面の調整もできるようになります。
2. 会話変数の基本的な使い方
手順
-
まず以下の一番左にある
会話変数ボタンを押します。
-
変数の追加 > 名前を設定 > タイプ(string or array[string])を設定 ※デフォルト値&説明は任意(記入を推奨)

-
LLMの回答後に
変数代入ブロックを追加

-
「+」ボタンで変数を追加 > 会話変数を設定 > 追加 > LLMの回答

-
LLMのプロンプトで設定した会話変数を用いる

この履歴情報を受け取った LLM は、次のユーザーの入力(例:「もう少し詳しく」)に対して、直前の Dify に関する応答を踏まえて回答を生成しようとします。これが基本的な会話履歴の利用方法です。
3. 会話変数の問題点
一見すると、会話変数を用いるだけで自然な会話ができそうに思えます。しかし、単純に会話変数をプロンプトに挿入するだけでは、いくつかの問題が発生する可能性があります。
問題点:LLM が過去の会話をうまく制御・参照できない
LLM は、プロンプトに含まれる大量のテキストの中から、現在の応答生成に最も関連性の高い情報を見つけ出す必要があります。しかし、会話変数が単純なテキスト羅列として挿入されるだけだと、以下のような問題が起こりえます。
- 情報の混同: 会話が長くなると、過去のどの発言が現在の質問に関連しているのかを LLM が正確に判断できなくなることがあります。例えば、複数のトピックについて話した後、「それについて教えて」と言われた場合、どの「それ」を指すのか混乱する可能性があります。
- 冗長な応答: 以前に回答した内容を繰り返してしまったり、文脈に合わない応答を生成したりすることがあります。
- 指示の不明確化: 会話変数自体が長大なテキストとなるため、本来 LLM に与えたい指示(例:「以下のユーザー入力に回答してください」)が埋もれてしまい、LLM がタスクを正確に理解できなくなることがあります。
具体例:
ユーザーが最初に「Aについて教えて」と質問し、次に「Bについて教えて」と質問したとします。その後、ユーザーが「最初の質問について、もう少し詳しく」と尋ねたとします。
単純な会話変数の挿入では、LLM はプロンプト内の「Aについて教えて」「Bについて教えて」という両方の履歴を見ることになります。「最初の質問」がどちらを指すのか正確に解釈できず、Bについて詳しく説明し始めたり、あるいは混乱して一般的な応答を返したりする可能性があるのです。
User: Aについて教えて
Assistant: Aは〇〇です。
User: Bについて教えて
Assistant: Bは△△です。
User: 最初の質問について、もう少し詳しく
Assistant: Bについてさらに詳しく説明します。Bは□□という特徴も持っています... (←本当はAについて聞かれている)
このように、単純な履歴の利用だけでは、LLM が文脈を正確に捉えきれず、自然な会話の流れを阻害してしまうことがあるのです。
4. 過去の会話を参照した自然な会話を達成する方法
では、どうすれば会話変数をより効果的に活用し、自然な会話を実現できるのでしょうか?ここでは、いくつかの具体的な方法を提案します。これらの方法を組み合わせることで、自然な会話を再現することができます。
方法1. 構造化された会話履歴の提示
LLM が会話変数を理解しやすくするために、履歴をより構造化してプロンプトに含める方法です。単純なテキスト羅列ではなく、各発言が誰によるもので、何回目のやり取りなのかを明示します。
構造例:
"turn": conversation_count, #会話回数を示す
"user": query, #ユーザーの入力
"assistant": answer #LLMの回答
このような XML や JSON ライクな形式(あるいは単純なマークダウンでも可)で履歴を整形し、会話変数に格納することで、LLM は各ターンを区別しやすくなるとともに、どのような入力に対して出力が生成されているのか理解することができます。
実際に上記の構造を生成するには、コードブロックを用いて、作成するのがいいでしょう。
コード例:
def main(query: str, answer: str, conversation: list) -> dict:
"""
会話の履歴に新しいユーザーのクエリとアシスタントの回答を追加し、
新しいエントリと更新後の会話ターン数を返す関数
Args:
query (str): ユーザーからの入力クエリ
answer (str): LLMが生成した回答
conversation (list): これまでの会話履歴のリスト
Returns:
dict: 以下のキーを持つ辞書
- result (str): 追加された新しいエントリを文字列化したもの
"""
# 現在の会話数を取得し、次のターン数を計算
conversation_count = len(conversation) + 1
# 新しい会話エントリを辞書形式で作成
new_entry = {
"turn": conversation_count, # 会話のターン番号
"user": query, # ユーザーのクエリ
"assistant": answer # アシスタントの回答
}
# new_entry を文字列に変換
new_entry_str = str(new_entry)
# 結果となる文字列と会話数を辞書で返す
return {
"result": new_entry_str,
}
方法2. 過去の会話変数を用いたユーザーの入力補完
ユーザーの入力が曖昧な場合(例:「それについてもっと教えて」)、LLM に応答させる前に、その入力をより具体的に補完するステップを挟む方法です。
プロセス:
- ユーザーが「それについて教えて」と入力。
- LLMが会話変数を参照し、「それ」が直前のトピック「たとえば:Dify の機能」を指していると判断。
- 実際の LLM への入力プロンプトでは、ユーザーのクエリを 「Dify の機能について教えて」 のように補完・具体化して渡す。
- LLM は明確化されたクエリに基づいて応答を生成する。
この補完処理は、「ユーザー入力の意図解釈」専用の軽量な LLM プロンプトを準備して実行することも考えられます。これにより、メインの応答生成 LLM は、より明確な指示に基づいて動作できるようになります。
特にRAGのようなケースでナレッジのクエリ変数を補完することで適切なチャンクを取得することができるようになります。
イメージ図:

入力統一 コード例:
def main(arg1: str, arg2: str, All_conversation_list: list) -> dict:
"""
会話履歴の有無に応じて入力文字列を知識クエリとLLMクエリに割り当て、
辞書形式で返します。
Args:
arg1 (str): ユーザーの入力
arg2 (str): 会話履歴を用いて情報を保管した入力
All_conversation_list (list): これまでの会話履歴のリスト
Returns:
dict: 以下のキーを持つ辞書
- "knowledge_query" (str): 使用する知識クエリ
- "llm_query" (str): 使用するLLMクエリ(プロンプト内で使用)
"""
# 会話履歴が存在するかどうかを判定
if All_conversation_list:
# 会話履歴ありの場合は arg2 を両方のクエリとして設定
knowledge_query = arg2
llm_query = arg2
else:
# 会話履歴なしの場合は arg1 を知識クエリ、LLMクエリは空文字列
knowledge_query = arg1
llm_query = ""
# 結果を辞書で返却
return {
"knowledge_query": knowledge_query,
"llm_query": llm_query,
}
方法3. 会話履歴の保持数を設定する
会話履歴に会話保持上限を設けることで、トークン数を下げ、コストを削減する方法です。
これは精度には直接関係ありませんが、必ず構築した方がいいフローです。実際に数十回連続で実行してしまうとトークン数が膨大になり、1回の実行で多額の請求がされてしまいます。
手順:
- 記憶保持数で分岐
- 一定数以下の場合、通常通り変数代入ブロックで追加する
- 一定数以上の場合、 コードブロックで一番過去の会話履歴を削除し、新しい生成を追加する > 変数代入ブロックで直前のコードブロックの出力を用いて会話変数を上書きする
イメージ図:
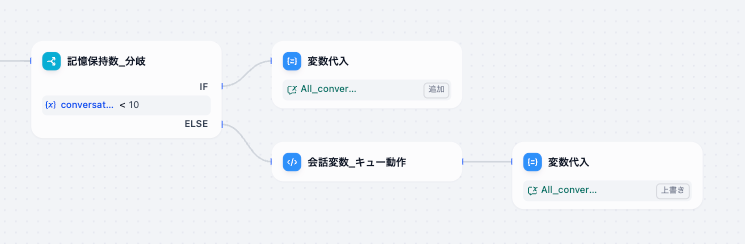
会話変数キュー動作 コード例:
def main(conv_list: list, answer: str) -> dict:
"""
会話履歴の先頭要素を削除し、最新の回答を末尾に追加して返す関数
Args:
conv_list (list): これまでの会話を保持するリスト
answer (str): 追加する最新の回答
Returns:
dict: 更新後の会話リストを 'result' キーに格納した辞書
"""
# 会話リストの最も古いエントリ(先頭)を削除
conv_list.pop(0)
# 最新の回答をリストの末尾に追加
conv_list.append(answer)
# 更新後のリストを辞書形式で返却
return {"result": conv_list}
まとめ
Dify で自然な会話を実現するチャットボットを構築するには、単に会話変数を有効にするだけでなく、その提示方法や活用方法に工夫が必要です。
今回紹介した、
- 構造化された会話変数の提示
- ユーザー入力の補完
- 会話履歴の保持数制限
といったテクニックを組み合わせることで、LLM は会話の文脈をより正確に理解し、ユーザーにとって自然で満足度の高い応答を生成できるようになります。
これらの方法を参考に、ぜひあなたの Dify アプリケーション開発に活かしてみてください!

株式会社アップグレードは、エンタープライズ企業の生成AI活用における戦略立案から実装までを一貫して支援する専門企業です。本ブログでは、AI Workflow設計、AI Agent開発、RAGシステム構築、各種LLMの実践的活用手法など、技術的知見を共有します。| Dify公式パートナー
Discussion