こんにちは、本田です。
AIアプリケーション開発プラットフォームとして注目を集めるDifyは、RAG(Retrieval-Augmented Generation)システム構築を容易にする強力な機能を備えています。
特に、ナレッジの「チャンキング」設定はRAGの精度を左右する重要な要素です。
本記事では、Difyが提供するチャンキング手法の中でも、特に「親子チャンク」機能に着目し、その仕組みと有効なユースケース、具体的な活用例について解説します。
Difyの親子チャンク:検索精度とコンテキスト理解の「良いとこどり」
親子チャンクは、概念的には「Small-to-Big Retrieval」や「階層チャンク」と呼ばれる高度なRAG手法と同様のアプローチです。
その仕組みはシンプルで、
- 初期検索: より詳細で具体的な情報を含む小さなチャンク(子チャンク)を対象に検索を実行する。
- コンテキスト拡張: 検索でヒットした子チャンクが含まれる、より広範な情報を持つ大きなチャンク(親チャンク)を取得し、LLMへの入力(コンテキスト)として提供する。
これにより、細かい情報粒度での検索精度と、文脈を理解するために必要な広範なコンテキストの両方を確保し、「良いとこどり」を狙うことができます。
なぜ親子チャンクが有効なのか?:汎用チャンキングとの比較
通常のチャンキング(例えば、テキストを一定の文字数で区切るなど)では、以下のような課題が生じることがあります。
- 情報の分断: 重要な情報が複数のチャンクに分割され、検索クエリとの関連性が見つけにくくなる。
- コンテキスト不足: 検索でヒットしたチャンクだけでは、LLMが質問に正確に答えるための文脈が不足する。
- ノイズの混入: 検索クエリと部分的に一致するものの、本質的には無関係なチャンクを拾ってしまう。
特に、特定の識別子(キー)とそれに関連する情報がセットになった構造化データ(例: 表形式データ)を扱う場合、この問題は顕著になります。汎用的なチャンキングでは、キーと値の関係性が失われやすく、類似した構造を持つ他のデータと混同しやすいためです。
親子チャンクは、この課題に対する有効な解決策になります。
あらかじめデータ構造に合わせて親子関係を定義しておくことで、キー(子チャンク)で正確に情報を特定し、関連する情報全体(親チャンク)を漏れなくコンテキストとして渡すことができるからです。
簡単なデモ↓
親子チャンクが特に威力を発揮するユースケースの一つが、CSVのような表形式データの時です。
ここでは、製品情報をまとめたCSVデータを例に、その有効性を見ていきましょう。
データ例: 以下のような製品在庫の表データ
製品ID,製品名,カテゴリ,価格,在庫状況,
P001,高性能ノートPC,PC,150000,在庫あり,
P002,ワイヤレスイヤホン,オーディオ,12000,在庫あり,
P003,スマートウォッチ,ウェアラブル,25000,在庫わずか,
P004,4Kモニター,PC周辺機器,40000,在庫あり,
...
P020,メカニカルキーボード,PC周辺機器,18000,入荷待ち,
手順:
-
データをCSVファイルとして保存する(※UTF-8 コンマ区切り)
-
Difyにログイン>ナレッジ>テキストファイルからインポート
-
チャンク設定で「親子チャンク」を、区切り文字として「段落」(CSVの場合は改行に対応)を選択
(デフォルトではまだ期待するチャンキングになっていない…子チャンクをセル単位で分けたい)
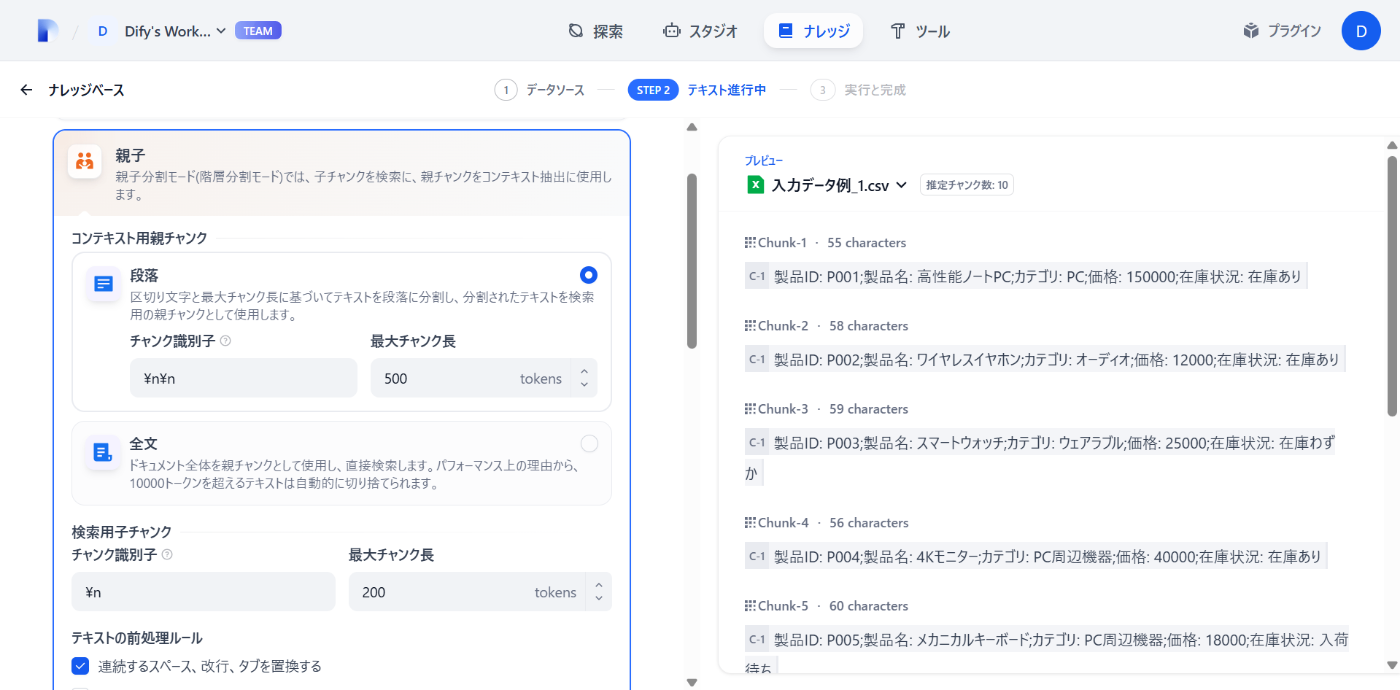
-
親チャンクに注目すると、セルの値がヘッダーとセットで表示され、セル間が「;」で区切られていることに気づく
製品ID: P001;製品名: 高性能ノートPC;カテゴリ: PC;価格: 150000;在庫状況: 在庫あり -
子チャンクの識別子を「;」で設定するとセル単位に分割成功🙌

↓
以下のような親子関係が設定されます。
P001,高性能ノートPC,PC,150000,在庫あり
|子||_____子_____||子||__子__||__子__|
|-----------------親-----------------|
-
親チャンク:
CSVの各行全体(例:
製品ID:P001,製品名:高性能ノートPC,カテゴリ:PC,価格:150000,在庫状況:在庫あり) -
子チャンク:
各列の値(例:
製品ID:P001,製品名:高性能ノートPC,カテゴリ:PC,価格:150000,在庫状況:在庫あり)
✅ 要するにデータベース検索的な事ができることに気づいた
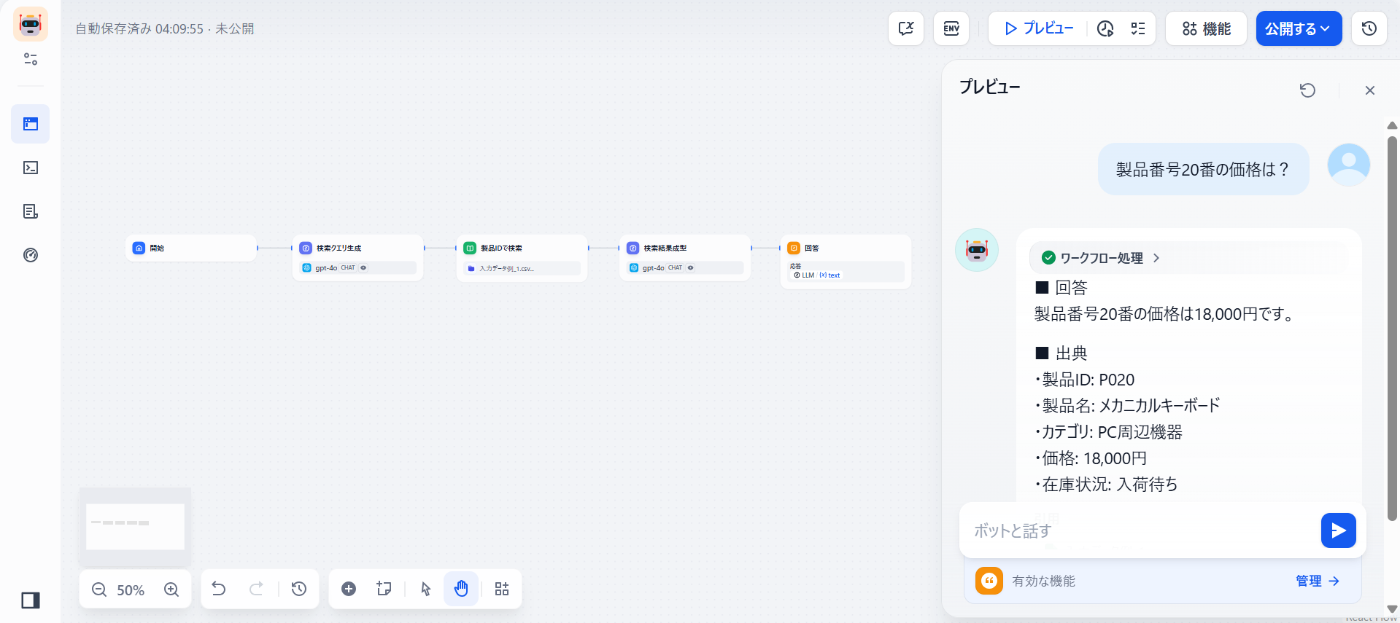
この設定で、例えば「製品番号20番の価格は?」といった質問が来た場合、
-
検索クエリ「P020」に最も関連性の高い子チャンク
製品ID:P020がヒットする。※検索設定は、前処理で「
製品ID: Xxx」の形式に成形するならキーワード1.0でもヒットする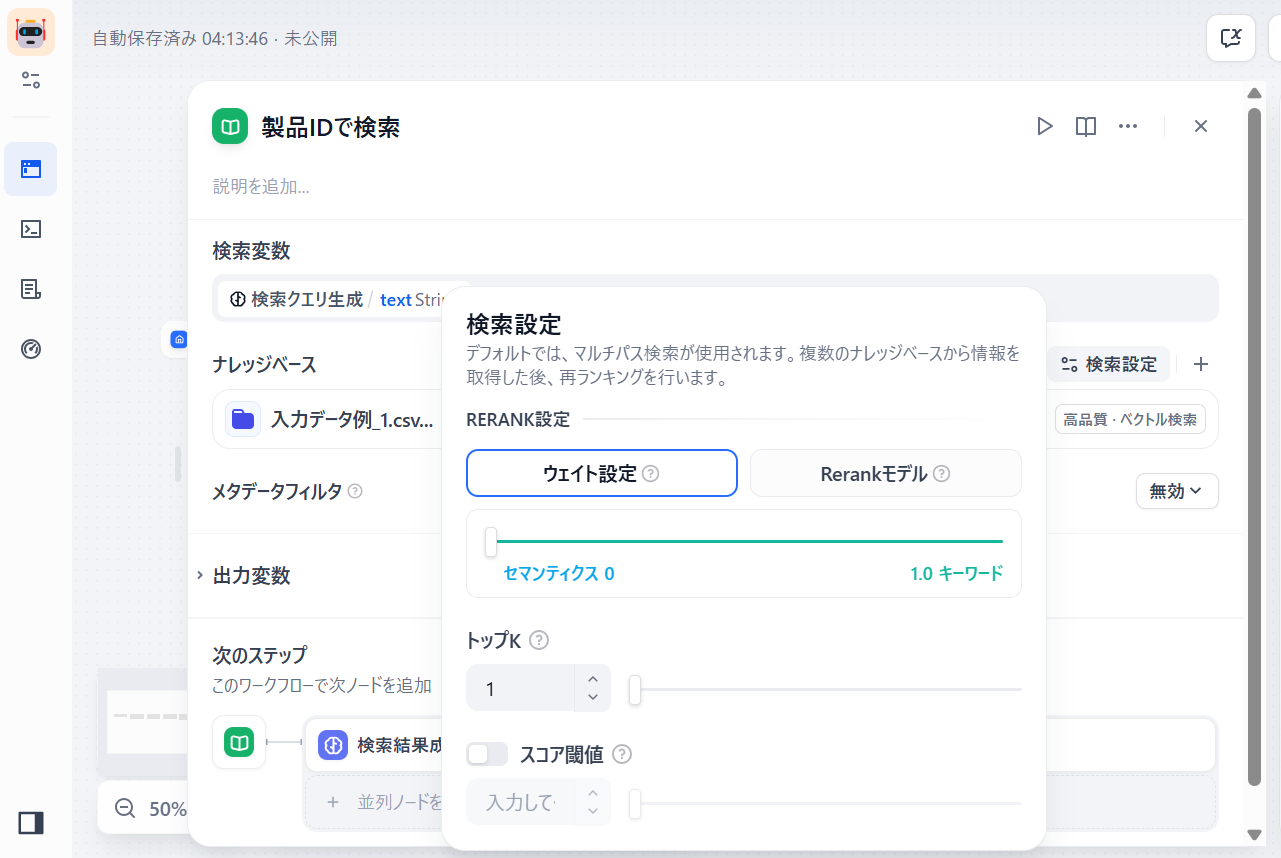
-
この子チャンクが含まれる親チャンク
製品ID: P020;製品名: メカニカルキーボード;カテゴリ: PC周辺機器;価格: 18000;在庫状況: 入荷待ち全体が取得される。<知識習得ノードの入力>
{ "query": "# 出力\n製品ID: 020" }<知識習得ノードの出力>
{ "result": [ { "metadata": { "_source": "knowledge", "dataset_id": "a7ac4d33-8f59-44ca-b66d-734a40ba58ce", "dataset_name": "入力データ例_1.csv...", "document_id": "2690ff32-8eb3-4e67-9307-c180f35aad28", "document_name": "入力データ例_1.csv", "document_data_source_type": "upload_file", "segment_id": "b6b98da2-d9b6-4035-a61d-d5c75d65b357", "retriever_from": "workflow", "score": 0.8077725, "segment_hit_count": 2, "segment_word_count": 60, "segment_position": 20, "segment_index_node_hash": "8f84bb97ae267e6ce3f7ffc407a5ad595f036fd77a4805f8e6d75f0516ad0aed", "doc_metadata": null, "position": 1 }, "title": "入力データ例_1.csv", "content": "製品ID: P020;製品名: メカニカルキーボード;カテゴリ: PC周辺機器;価格: 18000;在庫状況: 入荷待ち" } ] } -
LLMはこの親チャンク情報(製品ID P020の製品情報全体)を基に、「製品番号20番の価格は18,000円です。」と正確に回答できる。
■ 回答 製品番号20番の価格は18,000円です。 ■ 出典 ・製品ID: P020 ・製品名: メカニカルキーボード ・カテゴリ: PC周辺機器 ・価格: 18,000円 ・在庫状況: 入荷待ち
もし親子チャンクを使用しない場合、「P020」というキーワードだけでは類似度の高い他の製品情報(この場合だと「P021」など近い番号の製品IDのチャンクなど)も拾ってしまい、RAGの精度が著しく低下する可能性があります。
実際に、親子チャンクを使わなければ本要件を満たすことは(私の検証範囲では)できませんでした。
まとめ:親子チャンクの可能性
Difyの親子チャンク機能は、特に**検索キーとなる識別子を持つ構造化データ(CSVなど)**をナレッジとして扱う際に、RAGシステムの検索精度と回答品質を大幅に向上させる強力な選択肢となるようです。
今回はCSVデータを例に解説しましたが、テキスト主体のドキュメント(例: 条-項に構造化されている社内規定のPDFをMarkdownに変換したもの)などでも、条-項の構造を親子関係に見立てて適用できる可能性があります。
ただし、データの構造や内容に合わせて最適な設定を見つけるためには、検証が必要となるだろう。
Difyを活用して高精度なRAGアプリケーションを構築する上で、親子チャンクは間違いなく試してみる価値のある機能といえます。
参考

株式会社アップグレードは、エンタープライズ企業の生成AI活用における戦略立案から実装までを一貫して支援する専門企業です。本ブログでは、AI Workflow設計、AI Agent開発、RAGシステム構築、各種LLMの実践的活用手法など、技術的知見を共有します。| Dify公式パートナー
Discussion