
Turing株式会社の自動運転MLチームでインターンをしている東京大学学部4年の中村です。
Turingでは完全自動運転EV実現のために、End-to-End(E2E)な自動運転モデルの開発を行っています。E2Eモデルを実現するためには、特定のタスクに特化したモデルを利用したオートラベリングを活用するなど、従来のタスク特化型モデルが必要になることがあります。
今回は、タスク特化なモデルのうち、
- 昼も夜も高い精度(IoU 0.5 確率閾値 40% で AP 96.0% AR 95.0%)
- 黄色信号や矢印信号といった比較的頻度の少ない信号機まで認識可能
- 自レーンの信号機を選択的に認識
といった特徴を持つ信号機認識モデルを作成しました。また、これに伴って自社内で総計4.4万枚に及ぶデータセットの作成も行いました。データセットの作成から、モデルの学習、評価をこの記事で紹介していこうと思います。
信号機認識の課題
自動運転において必要なドメイン特化型モデルの1つが信号機認識モデルです。Turingでは以前にも、Zennの記事や人工知能学会などで発表したように信号機認識モデルのを行ってきました。Zennの記事では、信号機認識の困難さをより一般的な観点から分析してきました。
これまでに作成してきたモデルは昼の赤信号・青信号を比較的良く検出出来ていましたが、黄色信号や、矢印信号と言った登場頻度の少ない信号機の検出においてはそもそもデータ数からして少ないという課題が残っていました。また、ただ信号機を全て認識すればいいのかというと違います。人間は、信号機を無意識のうちに選択し、自レーンに関連する信号機のみを認識することが出来ています。自動運転に用いられる信号機認識モデルはこれと同じような能力を身につけている必要があります。自分が認識すべき信号機をどれくらい認識出来ているか、という点についても議論の余地が残っていました。
Turing以外の先行事例に目を向けると、インドの信号機において、矢印を含めて認識するモデルを作成した先行研究が存在しますが、このモデルで使用されたデータセットは昼の信号機のみであり、精度は公表されていません。

論文より抜粋
どうやってモデルを作るのか
前章の議論を踏まえた上で、今回作成するモデルは
- 昼も夜も高い精度
- 黄色信号や矢印信号といった比較的頻度の少ない信号機まで認識可能
- 自レーンの信号機を選択的に認識
を目標とし、データセットから一新することにしました。
最初から完璧なデータセット及びモデルを作ることは困難です。
そこで、まず以前作成した検索システムを活用して高速道路・朝/夜のバランスをコントロールしながら、信号機の含まれる画像がより多くなるような仮のデータセットを作成し、これをアノテーションして学習した仮のモデルを作成します。
次に、仮モデルを評価した上で苦手な状況を精査し、仮のモデルや手動のアノテーション結果を使用して苦手な状況(黄色信号や矢印信号)をより多く含むデータセットを作成し、これに対してオートラベリングと手動による修正を行います。最後にこれを使用してモデルを学習させ、評価することにしました。
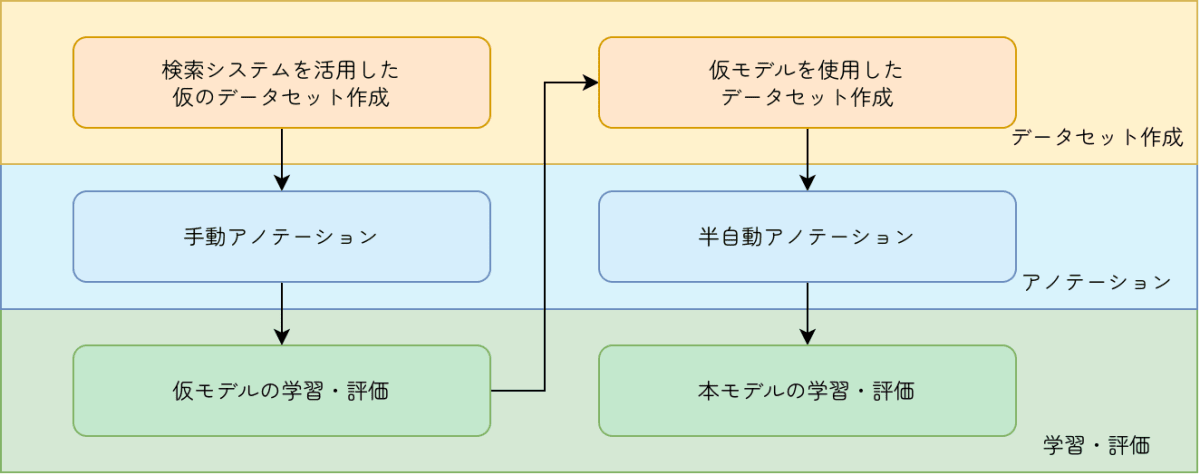
モデル開発サイクルの図
次の章からは実際の作業手順にしたがって何を行ったかを紹介していきます。
検索システムを活用した仮のデータセット作成
はじめに、過去に作成した検索システムを活用して、昼・夜・信号機有りなどのキーワードを使用して画像を取り出す動画を抽出しました。動画からは10秒おきに画像を抽出し、その画像をアノテーションに回します。
これとは別にランダムな画像も用意しこの時点で合計20000枚ほどのデータセットを作成しました。
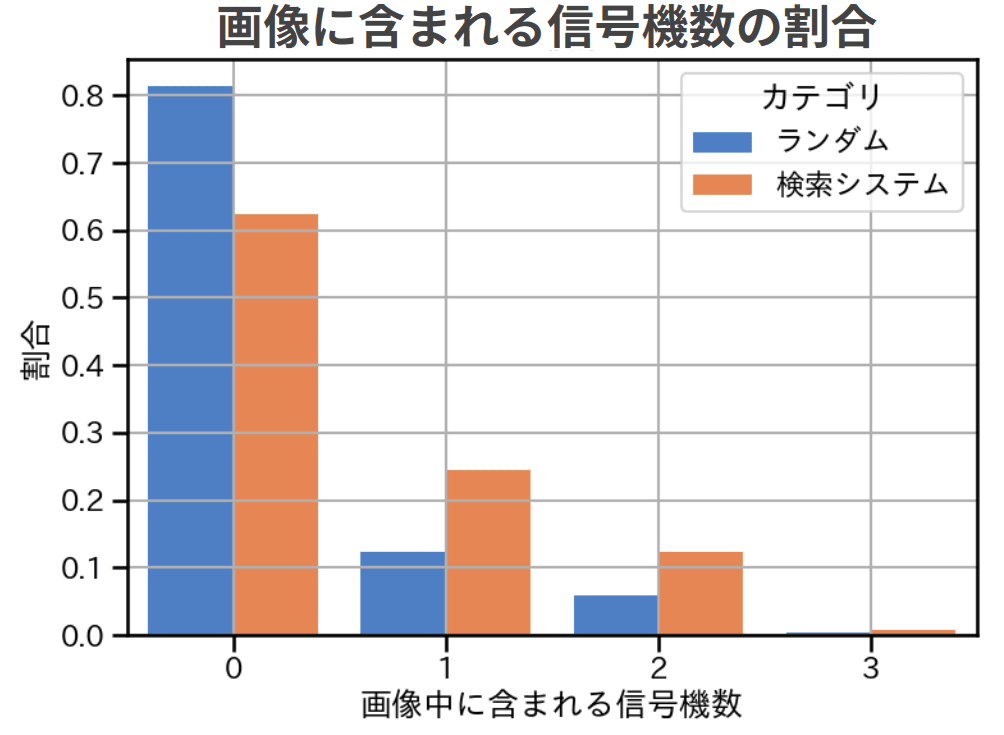
検索システムによる画像当たり信号機数の改善
検索システムでは、意図的に信号機を増やすようにした結果、1枚あたりに含まれる信号機の数が改善しました。また、データセットに含まれる夜の時間帯の画像数はおよそ1万枚と、前回データセット作成時に追加でアノテーションを行った5000枚よりもかなり多い枚数をはじめから確保することが出来ました。

信号機の昼夜割合
一方で、信号機の割合で言うと、依然として黄色信号が少なく(100枚ほど)、矢印信号も400枚ほどとあまり多くはありませんでした。
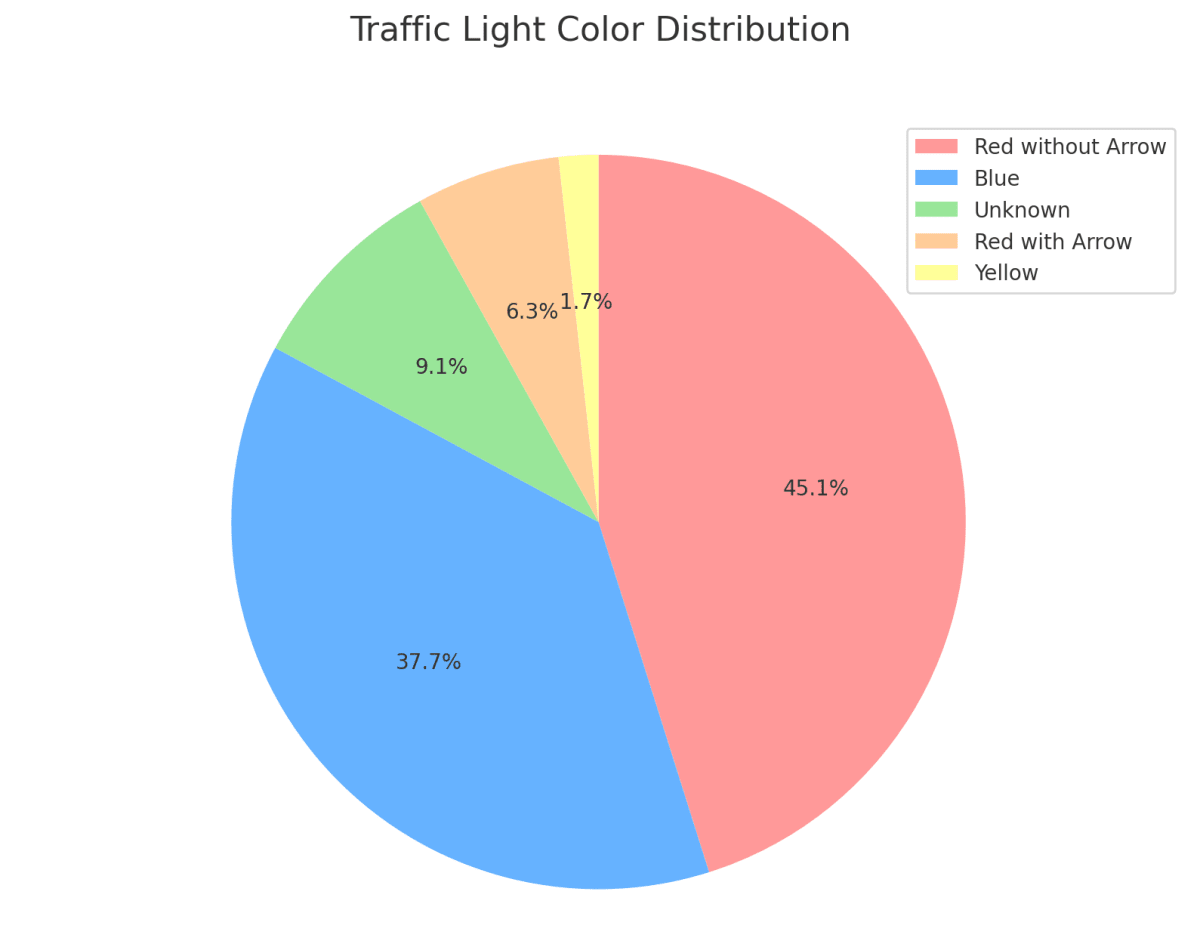
信号機の色別割合
手動アノテーション
作成したデータセットに対してアノテーションを行うことが必要です。前回の信号機認識モデルの際はCVATを使用していましたが、今回はlabel studioを使用することにしました。前回までの選定要件
-
環境構築が容易であること
- Webブラウザで操作可能である
-
機能が十分であること
- 複雑なラベルに対応出来る、オートラベリング機能など
-
継続的にメンテナンスされていること
- 開発がアクティブであり、メンテナンスが継続的であること、できればオープンソースであること
-
手が痛くならないこと
- UI/UXが悪くないこと
を踏まえた上で、今回はエンジニア以外がラベリングを行うことを想定し、ホットキー機能がより充実しており、UIが非エンジニアから見てもとっつきやすいものを選定しました。また、オートラベリング機能が簡単に使用できそうであることも決め手となりました。

label studioの作業画面 CVATに比べてスッキリとしていてモダン
今回のアノテーション全般に関しては普段走行パートナーとして、走行データを収集していただいているパートナーの方達にご協力をお願いしました。非常に助かりました。
仮モデルの学習・評価
今回作成するモデルは前回同様YOLOXをベースにしています。
仮モデルは1番モデルサイズの大きいyolox_xを使用しました。これを推論するマシンは学習用のマシンであり、基本的にハードウェアリソースに余裕があるため、一旦なるべく精度の良いモデルを目指します。学習時のパラメタは基本的には大きく変えていませんが、入力画像サイズ(メモリ上限ギリギリの640, 800)、左右反転の確率(0.5 → 0)を変更しました。これは日本の信号機の基本的な配列(青黄赤)をモデルに刷り込むためです。(🚥の絵文字の配列は会社によって異なるらしい…)
class Exp(MyExp):
def __init__(self):
super(Exp, self).__init__()
self.depth = 1.33
self.width = 1.25
self.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]
# max training epoch
self.max_epoch = 30
self.num_classes = 8
# --------------- transform config ----------------- #
self.flip_prob = 0
self.input_size = (640, 800) # (height, width)
また、この時点ではとにかくイテレーションを回すことを重視し、矢印信号への拡張は実装していませんでした。
このモデルはIoU 0.50、確率閾値1%(確率1%以上の出力を推論として受け取る)の元で、AP 0.60, AR 0.91と比較的良い数字を達成しましたが、実際に確率の閾値をある程度(25%など)設けた上で動画を見てみると黄色信号において見逃している(確率が低い)ことが多く、完成とは言えないモデルでした。

夜の走行データでのテストはまだダメ
仮モデルを使用したデータセット作成
前回のモデルを踏まえた上で、黄色信号及び矢印信号を全体として増やすことにしました。

この中から確実に黄色信号を認識しないといけないのは辛い
黄色信号は動画を2.5秒おきに画像化したデータ全てに対して推論を行い、少しでも黄色と推論された画像を含むセクションをデータセットに加えました。一方で矢印信号はこの段階で学習されたモデルがなかったため推論してデータセットに加えることが出来ません。
そこで、筆者は信号機の空間的局所性に着目することにしました。この言葉はコンピューターサイエンスにおけるキャッシュの議論においてよく出てきますが、ここにおける局所性も似たようなもので、「信号機は一度現れたらその近辺にも沢山あるはずで、これは矢印信号といった比較的レアな信号機にも当てはまる」という仮説です。考えたら当然ですが矢印信号が含まれる動画には他にも矢印信号が現れる可能性が高いです。そこで、既にアノテーションデータで矢印信号が検出されている動画からより多く画像を切り抜くことで矢印信号の枚数を確保しました。
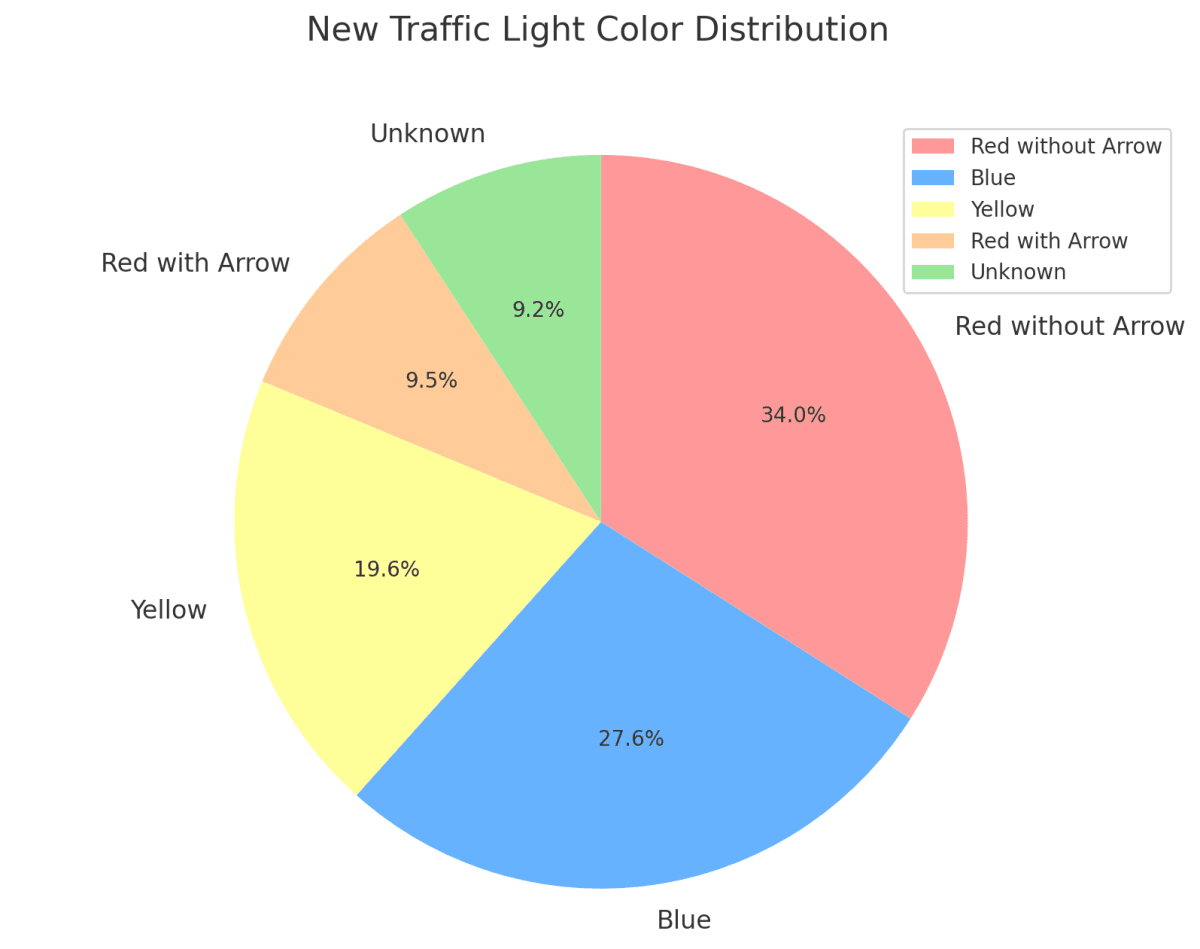
改善した信号機の色別割合
これで合計4.4万枚ほどのデータセットを作成しました。
半自動アノテーション
作成した仮モデルの力も借りながら、オートラベリングと人の目を使用したアノテーションを追加で行いました。label studioのml backendは非常に使いやすく(なんならアノテーションしながら学習もできるらしい)よかったです。
オートラベリングを活用したアノテーションは初の試みでしたが、アノテーターの皆さんからも好評でした。

画像を読み込んだ時点でモデルによる推論が表示される(画面右下box内に確率が表示される)
また、アノテーションをしてもらいながらモデルのおかしな推論を報告してもらうことで、現時点でのモデルの弱点を学ぶことが出来ました。
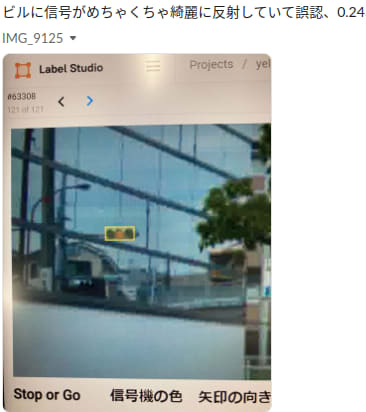
黄色信号が綺麗にビルに反射していて誤認識されている
本モデル学習・評価
本モデル学習の前に、YOLOXの拡張を行いました。今回のモデルは矢印に対応させるために、正解ラベルのone-hot表現を諦めるようにしています。YOLOXは損失関数として、Binary Cross Entropy Lossを使用しているため、実は各クラスごとの確率を出すことが出来ます。そのため [1(赤), 0(青), 0(黄), 0(不明), 1(左), 1(直進), 0(右)] のようなベクトルを学習・推論することが出来ます。これに対応するように学習コードを拡張することで矢印信号に対応させました。
その上で、本モデルは車載を想定し、yolox_sをメインとして学習しました。学習にあたっては、画像の入力サイズを(1280, 1280)にし、先ほどと変わらず、filpする確率は0にしてあります。
このモデルはIoU0.5で以下のような値を得ることが出来ました。
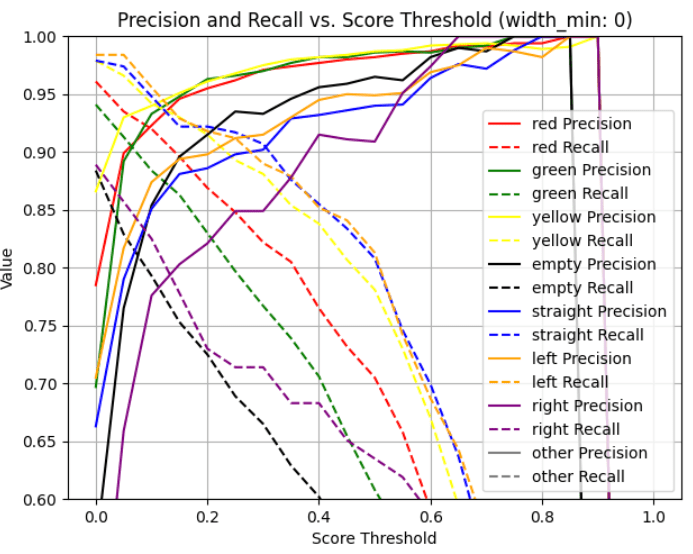
precision/recallを閾値ごとに見た図
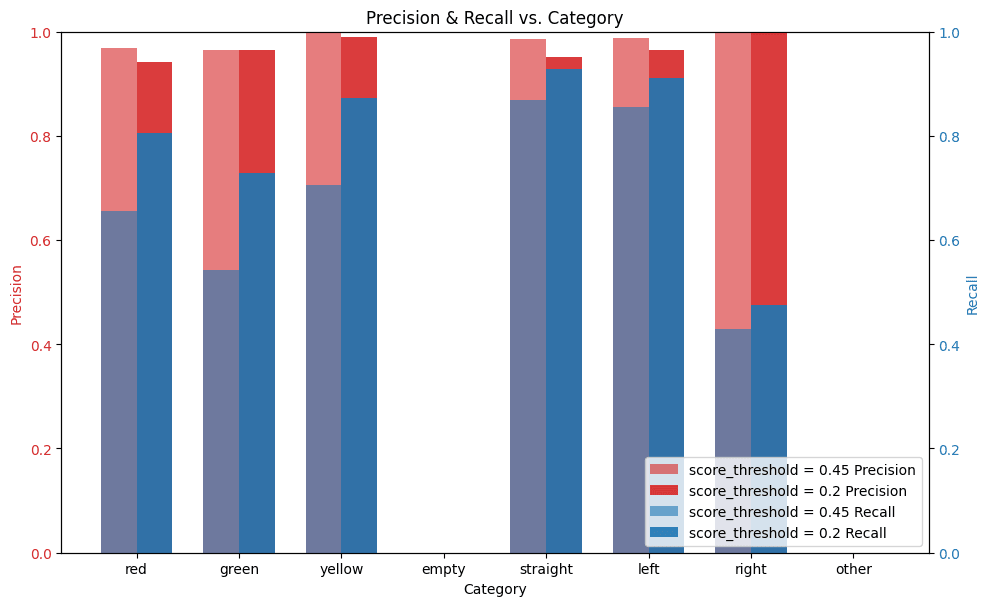
特に確率閾値を0.45に固定したときの値が以下です。
| color | precision | recall |
|---|---|---|
| 赤 | 0.980 | 0.732 |
| 青 | 0.982 | 0.655 |
| 黄 | 0.984 | 0.807 |
| 不明 | 0.959 | 0.562 |
| 直進 | 0.936 | 0.834 |
| 左折 | 0.950 | 0.841 |
| 右折 | 0.911 | 0.651 |
また、同条件におけるprecisionの混合行列を作成、致命的な推論ミスが存在しないことを確認しました。
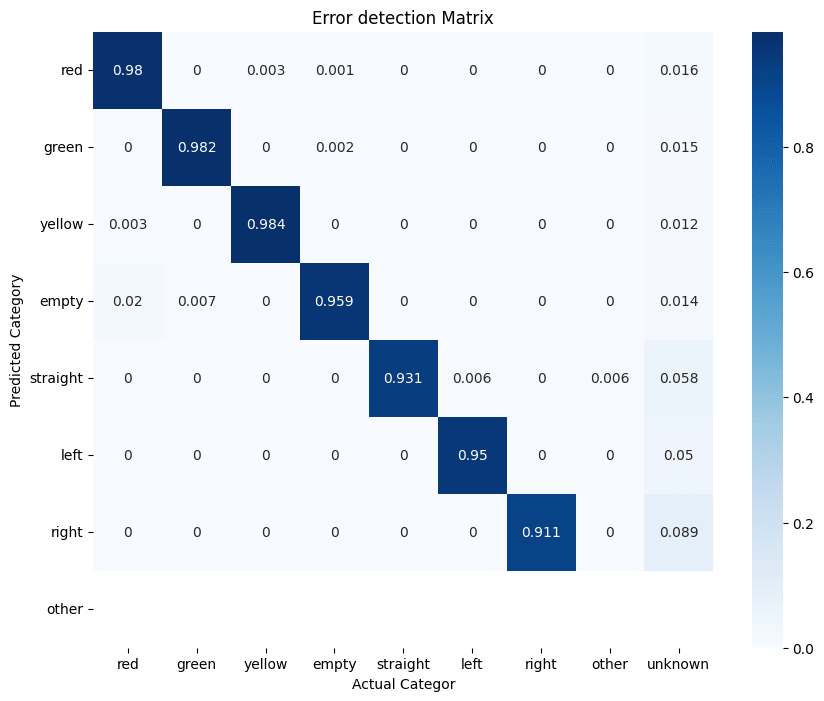
赤信号と青信号の間違いなどは見当たらない
苦手だった夜の矢印及び黄色信号も克服していることがわかります。

夜に矢印信号や黄色信号をしっかり認識している
考察
仮のデータセットで矢印を含めて学習したyolox_xと全てのデータセットで学習したyolox_sで、precision及びrecallを比較しました(IoU = 0.50)。以下のグラフを見るとわかるとおり全体的にprecision, recallが向上していることがわかり、データセットの質がモデルの出来に大きく関わっていることが改めてわかります。

precision/recallを閾値ごとに見たときの比較
自レーンの認識についても以下の画像が示すように信号機を通り過ぎたら正面の別の信号機を認識するようにしっかりと出来ていました。

信号機を通り過ぎたら別の正面の信号機を認識する
また、誤検知・未検出についても分析を行いました。その結果
- 矢印のアノテーション漏れによる誤検知認定
- 信号機のサイズミスによるIoU閾値が低かったもの
- レーンを間違えたもの
などが主であることがわかりました。特に走行レーンでない信号を認識してしまう問題は都内の複雑なレーンによりもたらされているものが多く、これからも改善が必要なことがわかります。

走行レーンと平行に近い別のレーンの信号機を認識してしまう

右側の信号は認識しなくて良い信号
また夜のみの精度を算出したところ、昼よりも大きくrecallが低下していました。そこで、スコア閾値を20%に下げたところ、precisionの大きな低下なく、recallが改善しました。このことから、夜は検出時のスコアが低いものの、誤検出しづらいことがわかりました。
夜の場合、閾値を下げてもprecisionがそれほど大きく低下せず、recallが改善する
おわりに
この記事では前回よりも高精度で高機能な信号機認識モデルを作成していきました。
精度が思ったより高かったため、リークを疑いYouTubeの動画で推論してみましたが、変わらず良い精度で推論出来ていました。

YouTubeの動画に対しても良い精度で推論出来ている
今回作成したモデルは良い精度が出ていたものの、自レーンの検出や、それを組み合わせた解釈など、まだまだ信号の認識1つとっても発展の余地があります。
また、Garbage in, garbage outという言葉で示されているように、ハードウェア側で綺麗な画像を取得出来ていることはモデル精度においてかなり重要です。Turingではハードウェア側からフリッカー対策や、CPUの負荷対策なども行ってきています。
自動運転には信号機だけでなく、様々な物体の認識や解釈が必要です。信号機だけでなく、様々なデータセットを自前で作成し、オリジナルモデルの開発を進めています。興味のある方は是非、HPをご覧ください。

Discussion