Turing株式会社の自動運転MLチームでインターンをしている東大B4の中村です。
突然ですが、web検索のように簡単に、ストレージ内に保存されている、日時以外のメタ情報のない動画が検索出来るようになったら幸せになれると思いませんか? 例えば「赤信号で車が停止している」という検索クエリに対して、実際に赤信号で停止している動画が返ってきたら、簡単にそれを信号検知+停止のモデル学習に使えるようになります。
今回私が開発した動画検索システムはこれをAIの力を借りて実現しました。これにより、格段に動画検索の利便性が増し、より多様な動画を簡単に使用できるようになりました。今回はそのシステムについて紹介します。
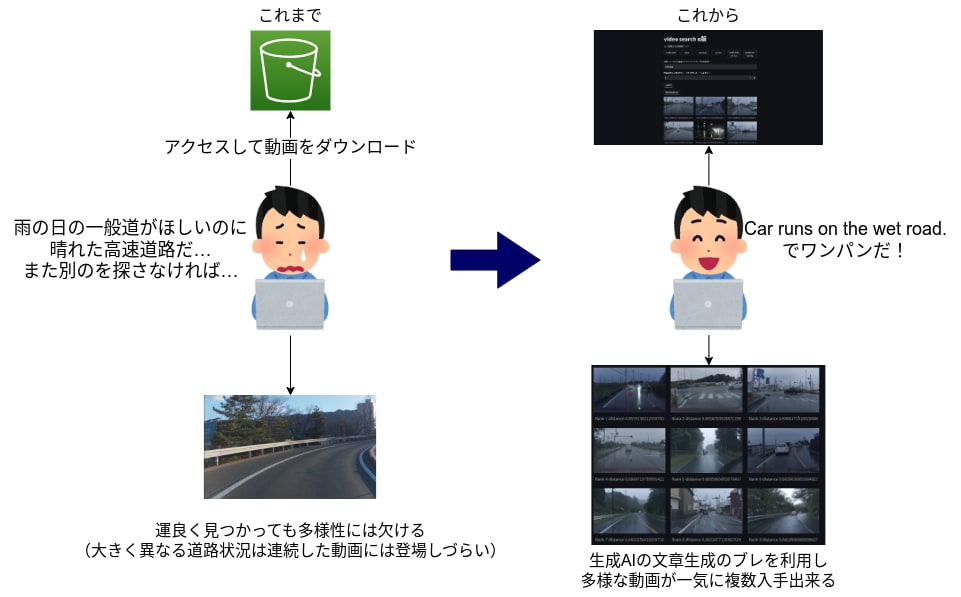
ワンパンで動画を探せると嬉しい
課題
Turingでは、走行パートナーの方々と共に大量の走行データを収集してきました。車両にカメラ・データ収集キットを載せて、文字通り毎日朝から晩までデータを取っています。記録してきたデータは80TBを超えてきていますが、これまではこれらの動画の検索が出来ないという問題点がありました。動画を使用する際には当てずっぽうで動画をダウンロードし、中身が用途に適したものであるかを確認しなければいけませんでした。これではダウンロードにかかる時間や、当たりくじを引くまでの時間が生産性を低下させてしまいます。
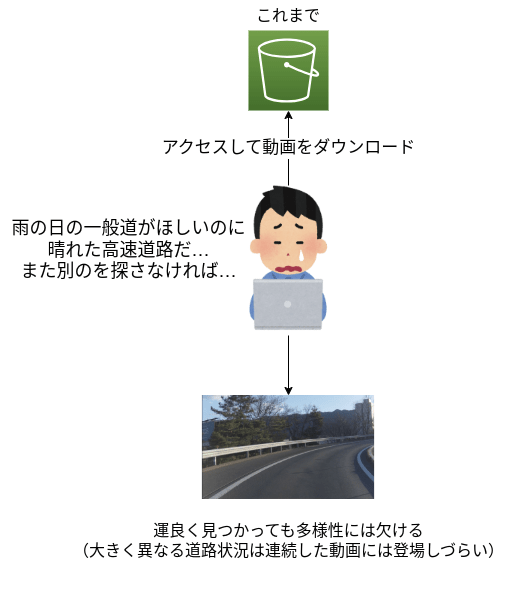
運ゲーによる生産性の低下の例
そこで、動画を使いやすくするというミッションが与えられました。
全体の構成を考える
与えられた課題は「いい感じに動画データを使いやすくする」なので、どう実現するかは自由に決められました。
最初に出てきたアイデアは「動画にタグ(信号機、夜など)をつけて、タグ毎のテーブルを作る」というものでした。しかしデータベースにするとなるとスキーマを考える必要があったり、どのようなタグに対してテーブルを作成するかも決めないといけないため、タグをつける考えはやめました。次に、いくつかの動画のサムネイル画像に対して物体検出を行ってみた結果、以下の画像のように信号機があるからといって必ずしも信号機を検出してくれるわけではないし、つけられたキャプションも誤りがあるということがわかりました。個人の主観ですが、データベースに入っているデータは事実として正しいものであるのが自然であるような気がしたため、この案は辞めることにしました。

よく見ると、セブンイレブンが歯ブラシを持った手の絵にされている
色々考えた結果、「画像の文章化をし、これと検索ワードの類似度から近いものを選ぶ」という方法を取ることにしました。これならば多少AIのブレがあっても問題になりませんし、文章化の部分はAIの発展にしたがって簡単にやり直すことも出来ます。(少なくともデータベースを構築し直すよりは簡単だと考えました。)
具体的には以前、同じチームの岩政さんが使用していたBLIP-2[Li+ 22]とGRiT[Wu+ 22]を使用し、GPTに文章化を手伝ってもらうことを行います。
これだけだとただの画像の説明文を生成するだけになってしまい、動画特有の時系列情報が失われてしまいます。そこで、今回は取得しているログデータから、「平均速度」「ステアリング角」「撮影時間」を抽出し、これらを考慮した上でGPTに文章化してもらうことにしました。これにより、画像だけでは取得出来ないが、動画を見れば人間が理解できるような情報も一部説明文に入れ込むことが出来ます。
さらに、自然言語で検索しやすくするために、文章をopenAIの提供するtext-embedding-ada-002でベクトル化したものを保存することにしました。これにより、単語の完全一致ではなくなんとなく似た単語で検索しても問題なくなります。また、GPTには英語の文を出力してもらいますが、日本語での検索も可能になります。
結果として以下のような全体構成図が出来上がりました。
次の章からは各部分について解説していきます。
視覚情報の抽出
ffmpegを使用して、動画から最初のフレームの画像を取得するのは以下のようにして出来ます。
ffmpeg -i input.mp4 -vframes 1 output_file.jpg
BLIP-2
BLIP-2は事前学習済みの画像エンコーダーとLLMを使いその間に2段階のQuerying-Transformerという変換器を持ったモデルです。
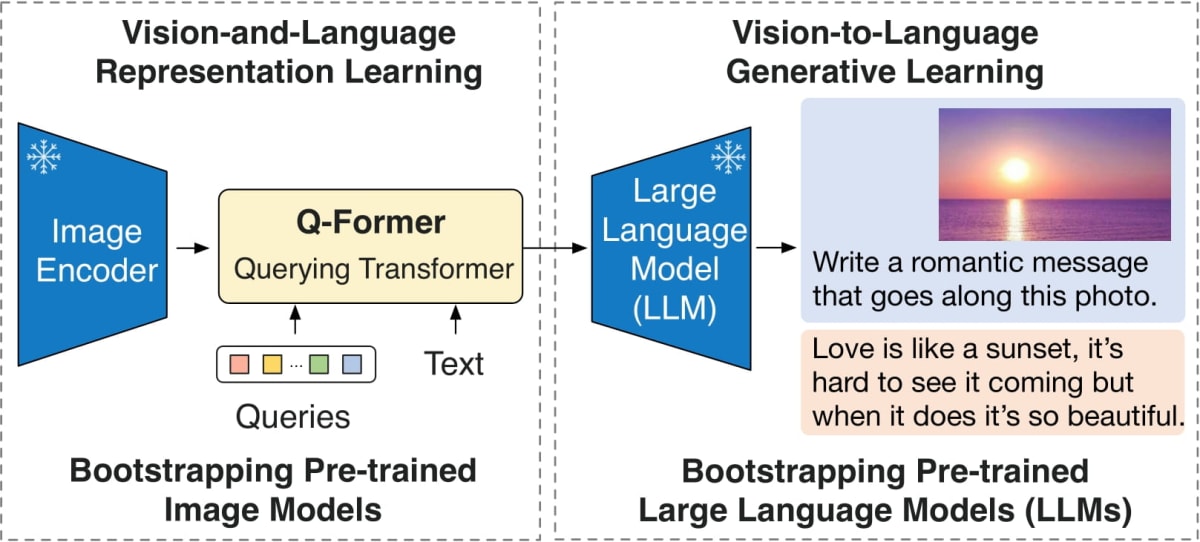
BLIP-2のモデル構造(論文より引用)
詳しいことはここでは述べませんが、要するにImage2Textをしてくれるモデルです。Hugging FaceのTransformersライブラリに含まれており、比較的容易に使用することが出来ます。ただし、内部にLLMを含むので、パラメータ数が比較的少ないとは言え、float16に量子化したあとでもGPUメモリが8GBくらい必要です。
使い方
有志の方によるDemo notebookがあるので、それを参考にすれば大体のことは出来ます。
- モデルをロードし、GPUに載せる
from transformers import AutoProcessor, Blip2ForConditionalGeneration
import torch
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
# by default `from_pretrained` loads the weights in float32
# we load in float16 instead to save memory
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
- キャプション生成する
import requests
from PIL import Image
# 画像の読み込み
url = 'https://storage.googleapis.com/sfr-vision-language-research/LAVIS/assets/merlion.png'
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
inputs = processor(image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text) # singapore merlion fountain
- 質問を投げる
prompt = "Question: which city is this? Answer:"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=10)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)# singapore
BLIP-2は画像全体の雰囲気を捉えることが上手です。
例えば、以下の画像では「a car driving down a highway with a factory in the background(工場が背景に映っている高速道路を走行している車の画像)」と返してくれます。

確かに工場が映っていて高速道路を走行している
一方で、細かな物体検出は苦手です。例えば上の画像は信号機が映っていませんが、 Question: Are there traffic lights in this photo? Answer: というプロンプトに対して「yes」と返してきました。
BLIP-2では他に天気を読み取ってもらいました。大体はうまく行くのですが、以下のような雲がたくさん映っているが、晴れているという場合にはcloudyと言ったり、明らかに雨でない画像に対してrainyと言ったりしています。このあたりはまだまだ改善の余地がありそうです。また、これだけでも画像のキャプショニングは出来ていると言えますが、より画像内に映っているものを反映したキャプショニングを行うために、他のモデルも使用します。

晴れなのに曇判定されてしまう画像

曇りなのに雨判定されてしまう画像
GRiT
BLIP-2が画像全体をキャプショニングするのに対し、GRiTは検出した領域に対してキャプショニングします。
以下の画像のように画像の各部分についてキャプショニングをしてくれます。ただし、先にも述べたように、特定の物体を必ず検出してくれるわけではないので注意が必要です。検出してくれる数が多く、キャプションを行う分、誤りも結構あります。

GRiTによるDense Captioningの例
使用方法
installは公式のinstall.mdを見るのが確実です。
git clone https://github.com/facebookresearch/detectron2.git
cd detectron2
git checkout cc87e7ec
pip install -e .
cd ..
git clone https://github.com/JialianW/GRiT.git
cd GRiT
pip install -r requirements.txt
# modelのダウンロード
mkdir models && cd models
wget https://datarelease.blob.core.windows.net/grit/models/grit_b_densecap_objectdet.pth && cd ..
# 実行
python demo.py --test-task DenseCap --config-file configs/GRiT_B_DenseCap_ObjectDet.yaml --input demo_images --output visualization --opts MODEL.WEIGHTS models/grit_b_densecap_objectdet.pth
これだけで、結果の画像が出力されます。demo.pyの中身は以下のようになっています(一部抜粋)。
if __name__ == "__main__":
mp.set_start_method("spawn", force=True)
args = get_parser().parse_args()
setup_logger(name="fvcore")
logger = setup_logger()
logger.info("Arguments: " + str(args))
cfg = setup_cfg(args)
demo = VisualizationDemo(cfg)
if args.input:
for path in tqdm.tqdm(os.listdir(args.input[0]), disable=not args.output):
img = read_image(os.path.join(args.input[0], path), format="BGR")
start_time = time.time()
predictions, visualized_output = demo.run_on_image(img)
logger.info(
"{}: {} in {:.2f}s".format(
path,
"detected {} instances".format(len(predictions["instances"]))
if "instances" in predictions
else "finished",
time.time() - start_time,
)
)
今回は、GPT-3.5に入力するための物体検出した結果のboxとキャプションが欲しいので、こんな感じのコードを追加します。
if args.input:
results = {}
for path in tqdm.tqdm(os.listdir(args.input[0]), disable=not args.output):
img = read_image(os.path.join(args.input[0], path), format="BGR")
start_time = time.time()
predictions, visualized_output = demo.run_on_image(img)
# 中身をcpuに移動
instances = predictions["instances"].to(torch.device("cpu"))
# 検出したbox
pred_boxes = instances.pred_boxes.tensor.detach().numpy().tolist()
# それへのキャプショニング
pred_object_descriptions = instances.pred_object_descriptions.data
result = {"pred_boxes": pred_boxes, "pred_object_descriptions": pred_object_descriptions}
results[path] = result
これを保存しておけば、以下のようなjsonが得られます。
"2022-07-04--11-47-22--73.jpg":
{"pred_boxes":
[[563.044921875, 376.6695556640625, 741.5957641601562, 560.1747436523438], [799.757080078125, 415.2471923828125, 889.5087890625, 488.3712158203125], [2.6843347549438477, 391.2938537597656, 1914.0106201171875, 1194.54931640625], [121.3943099975586, 2.6437325477600098, 1834.0716552734375, 307.88116455078125], [3.593453884124756, 891.66455078125, 333.22039794921875, 1161.6207275390625], [1063.3922119140625, 422.3622131347656, 1903.8070068359375, 1174.3211669921875], [1480.653076171875, 417.1390686035156, 1569.3511962890625, 479.8834228515625], [145.28738403320312, 176.90570068359375, 1402.25390625, 996.85009765625], [512.4483642578125, 345.1810302734375, 777.23974609375, 612.1792602539062], [1020.2953491210938, 394.2611389160156, 1067.8372802734375, 449.5586242675781], [236.82540893554688, 546.211181640625, 476.3074951171875, 639.2946166992188], [1097.804443359375, 406.3769836425781, 1924.3970947265625, 827.6743774414062], [722.435791015625, 184.59027099609375, 884.230712890625, 346.7625427246094]],
"pred_object_descriptions":
["white van on the road", "a white car on the road", "the white lines on the road", "a hazy gray sky", "white line on the road", "white line on the side of the road", "car on the road", "the cars are driving on the road", "the van is white", "a white van on the road", "white line painted on the road", "a bridge over the road", "a tall multi story building"]
},
GPT-3.5による文章化
これまでに
- BLIP-2による画像のキャプション及び、画像内の天気
- GRiTによる物体検出及び物体へのキャプショニング
のデータが得られました。これをGPT-3.5に渡して文章化してもらうことを考えます。
以下のような画像を文章化してみましょう。

以下が、BLIP-2, GRiT, ログからのデータとして与えられます。ただし、ログからのデータは、一定のルールに従って、予め言語化した上でプロンプトに入れます。例えば速度の場合は以下です。
- 平均速度5km/h 以下 : almost stop
- 平均速度25km/h 以下 : slow
- 平均速度60km/h 以下 : normal
- それ以上 : fast
# BLIP-2の結果
Description from model: a road with a sign that says "no parking"
Weather from model: sunny
Time inferred from only image: at noon
# ログからのデータ
Average Speed of this car: slow
Does this car turn left in this movie?: Car turns left.
Does this car turn right in this movie?: The car is making a big right turn.
Actual time: 15:54:53
# GRiTの結果
Object Detection Results
white line on the road: X:1292 Y:747 Width:360 Height:295
two black and yellow signs: X:503 Y:389 Width:192 Height:417
a black and yellow sign: X:597 Y:395 Width:94 Height:397
a black and yellow sign: X:507 Y:400 Width:88 Height:383
a road near a field: X:41 Y:518 Width:1882 Height:681
a sign attached to a metal pole: X:190 Y:335 Width:176 Height:595
red and white sign: X:850 Y:330 Width:87 Height:86
a yellow and black sign: X:199 Y:1102 Width:1040 Height:93
a sign advertising prices: X:855 Y:412 Width:80 Height:191
a yellow sign with black letters: X:777 Y:404 Width:82 Height:205
yellow sign on the fence: X:516 Y:1133 Width:176 Height:73
yellow and red sign on the ground: X:872 Y:601 Width:282 Height:111
caution signs on the road: X:668 Y:498 Width:504 Height:242
red and yellow ladder: X:676 Y:624 Width:154 Height:105
red light on the pole: X:961 Y:336 Width:66 Height:117
a white and yellow sign: X:687 Y:295 Width:59 Height:87
orange and white cone: X:685 Y:525 Width:53 Height:108
a blue and white sign: X:932 Y:461 Width:102 Height:60
何も考えずに、「以下は1920x1280の画像をAIに入力して得られた結果です。この画像を文章で説明してください」と入力してみました。
- GPT-3.5の場合
この画像は、1928x1028の解像度を持つ道路の光景を表しています。
天候は晴れで、時間は昼の正午頃であると推測されます。
ログからのデータによると、この車の平均速度は遅いです。
映像中でこの車は左に曲がっており、また大きな右折も行っています。
実際の時刻は15時54分53秒です。
また、GRiTの結果からは、以下のオブジェクトが検出されました:
道路上の白線:X座標1292、Y座標747、幅360、高さ295
黒と黄色の2つの標識:X座標503、Y座標389、幅192、高さ417
黒と黄色の標識:X座標597、Y座標395、幅94、高さ397
黒と黄色の標識:X座標507、Y座標400、幅88、高さ383
野原の近くの道路:X座標41、Y座標518、幅1882、高さ681
金属のポールに取り付けられた標識:X座標190、Y座標335、幅176、高さ595
赤と白の標識:X座標850、Y座標330、幅87、高さ86
黄色と黒の標識:X座標199、Y座標1102、幅1040、高さ93
価格を宣伝する標識:X座標855、Y座標412、幅80、高さ191
黒の文字の黄色の標識:X座標777、Y座標404、幅82、高さ205
フェンスに取り付けられた黄色の標識:X座標516、Y座標1133、幅176、高さ73
地面にある黄色と赤の標識:X座標872、Y座標601、幅282、高さ111
道路上の注意標識:X座標668、Y座標498、幅504、高さ242
赤と黄のはしご:X座標676、Y座標624、幅154、高さ105
ポールについた赤い信号:X座標961、Y座標336、幅66、高さ117
白と黄の標識:X座標687、Y座標295、幅59、高さ87
オレンジと白のコーン:X座標685、Y座標525、幅53、高さ108
青と白の標識:X座標932、Y座標461、幅102、高さ60
以上がAIによる画像の説明です。
- GPT-4の場合
以下は、入力された1928x1028ピクセルの画像についてのAIによる解釈です:
画像は、日中の晴天に撮影された道路の風景を描いています。画像の中には、複数の標識が配置されています。
その中には、"駐車禁止"の表示が含まれていることがモデルから推測されています。
黒と黄色の標識が複数存在し、これらは様々な位置とサイズで配置されています。
また、一部の標識は金属のポールに取り付けられていたり、フェンスに取り付けられていたりします。
一部の標識は価格を広告しているかもしれません。
道路はフィールドに近く、画像の一部には白線が引かれています。
この道路では、特定の車がゆっくりと進行し、大きく右に曲がりつつも左にも曲がっていることが記録されています。
他にも、赤と白の標識、黄色と赤の標識、白と黄色の標識、青と白の標識が存在します。
また、赤と黄色のはしご、ポールに取り付けられた赤いライト、オレンジと白のコーンも視認できます。
すべてのこれらの要素は、その道路が何らかの注意を必要とする状況であることを示唆しているかもしれません。
と明らかに、gpt-4の方がいい感じの返答を返してくれます。しかし、gpt-4はAPIの料金がgpt-3.5の30倍なので、なるべく3.5を使用したいです。ここからはプロンプト芸です。最終的に以下のようなプロンプトを先頭につけることで、いい感じの表現が得られました。
You are given a description of the object recognition model for the thumbnail image of the video taken by the drive recorder,
a description of the weather, the time the image was actually taken,
the time of day (day or night) inferred from the image alone,
the average speed of the car, and the maximum angle of the steering wheel.
Assume you are a blind but intelligent image caption creator.
Note that the potions given are the coordinates of the upper left corner of the object and the size of the object.
Using the relative position and size of the objects,
describe this image in about 150 words in a way that an elementary school student could understand.
Include how fast the car is going (fast, slow, normal) and whether it is turning right or left or going straight.
日本語訳:
ドライブレコーダーで撮影された動画のサムネイル画像の物体認識モデルの説明、
天気の説明、画像が実際に撮影された時間、
画像だけから推測される時間帯(昼か夜か)、
車の平均速度、ハンドルの最大角度が与えられる。
あなたが盲目だが知的な画像キャプション作成者だと仮定する。
与えられたポーションは、オブジェクトの左上隅の座標とオブジェクトのサイズであることに注意。
物体の相対的な位置と大きさを使って、この画像を小学生が理解できるように150字程度で説明しなさい。
車の速さ(速い、遅い、普通)、右折か左折か直進かも含めなさい。
結果、このような返答が得られます。
In this video thumbnail image taken by a car's drive recorder, we see a sunny day with a road ahead.
The car is moving slowly, like a turtle. It's turning left, making a small bend on the road.
The image was taken around noon, when the sun is high up in the sky.
On the road, we can see a white line that guides the cars.
There are two black and yellow signs standing close together, and another similar sign a bit further away.
These signs give information to drivers.
There is also a big sign attached to a metal pole, which advertises something.
In the distance, there is a road near a wide field, where cars can travel.
Near the road, there's a red and white sign, cautioning drivers about something important.
There are also other signs with words and pictures on them,
like a yellow one with black letters and another with prices advertised.
As we look around, we notice many other signs and markings on the road to keep drivers safe.
These include caution signs, a ladder-like structure,
a red light on a pole, and more signs with different colors and shapes.
We even see some orange and white cones, usually placed for special reasons.
Overall, it seems like the driver is being careful and paying attention to the road signs as they drive slowly and make a turn.
日本語訳:
車のドライブレコーダーが撮影した動画のサムネイル。車は亀のようにゆっくりと進んでいる。
小さなカーブを曲がりながら左折している。画像は太陽が高い位置にある正午頃に撮影された。
道路には、車を誘導する白い線が見える。黒と黄色の標識が2つ近くに立っており、少し離れた場所にも同じような標識がある。
これらの標識はドライバーに情報を与えている。金属製のポールに取り付けられた大きな看板もある。
遠くの広い畑の近くに道路があり、車が通れるようになっている。
道路の近くには赤と白の標識があり、ドライバーに重要なことを警告している。
他にも、黄色に黒文字の看板や、値段の書かれた看板など、文字や絵の書かれた看板がある。
周囲を見回すと、ドライバーの安全を守るための標識や表示が道路上にたくさんあることに気づく。
注意標識、はしごのような構造物、ポールの上の赤いライト、色や形の違う標識などだ。
オレンジと白のコーンも見えるが、これは通常、特別な理由で設置されるものだ。
全体として、ドライバーはゆっくり運転しながら道路標識に注意を払い、曲がっているように見える。
いい感じですね。これなら使えそうです。ちなみにAPIにかかる料金ですが、大体1枚の画像に付き送信側のtokenが500, 返答側が250程度なので1万枚分の文章の生成にかかる料金はわずか12.5ドル程度です。GPT-4だと大体300ドル程度かかるようです。
Bardでやってみた
この検索システムを構築している最中にBardが画像の入力に対応しました。同じ画像でやってみた結果は以下でした。(日本語訳済み)
送られてきた画像には、標識とコーンで塞がれた道路が写っている。標識は日本語で、"停止位置 "と "工事中ですのでご協力ください "と書かれている。
コーンは黄色とオレンジ色で、両方向の道路をふさいでいる。
画像は遠くから撮影したもので、道路と標識が上から写っている。
空は青く、背景には数本の木がある。
この画像は、道路が工事のために閉鎖されていることを示唆している。
標識とコーンは、ドライバーは一旦停止し、工事関係者に協力すべきことを示している。
この画像はまた、背景に住宅があることから、工事が住宅地で行われていることも示唆している。
この画像は、工事は混乱を招くが、インフラを改善するためにも必要であることを視覚的に喚起している。
この画像はまた、通行止めに遭遇したら、ドライバーは忍耐強く、協力的であるべきであることを示唆している。
住宅地にあるという嘘も有りますが、概ね正しい結果を返してくれます。特に日本語の文字列を認識しているのが特徴的でしょう。なんとなくですが結果の出力を見るとBardも今回構築したように自然言語モデルの前に画像用のモデルを繋げているような気がします。GoogleはGCPやGoogleDrive、Google LensなどでOCR技術を開発してきているので、それを使用するというのは自然なように思われます。
文章のベクトル化
返答を取り出し、text-embedding-ada-002と呼ばれる文章をベクトル化してくれるAPIを使用して、ベクトル化します。
response = openai.Embedding.create(input=[message], model="text-embedding-ada-002")
最後に、このベクトルのファイル名を動画ファイル名がわかるようにして、npyの形で保存します。
検索
検索は検索文を同じようにtext-embedding-ada-002でベクトル化し、保存した各ベクトルとの”近さ”をなんらかの方法で計算し、ソートします。以下は、scipyのcosineを使用する例です。
import os
from typing import List, Tuple
import numpy as np
from scipy.spatial.distance import cosine
def find_closest_vectors(ref: np.ndarray, folders: List[str], top_k: int) -> List[Tuple[str, float]]:
file_similarity_pairs = []
for folder in folders:
for file in os.listdir(folder):
if file.endswith('.npy'):
a = np.load(os.path.join(folder, file))
vec = a[0]
similarity = cosine(ref, vec) # Compute cosine distance
file_similarity_pairs.append((folder +"/"+ file, similarity))
# Sort by similarity (cosine distance, so smaller is more similar)
file_similarity_pairs.sort(key=lambda x: x[1])
return file_similarity_pairs[:top_k]
これだと4.5万件からの検索に大体8.5秒程度かかります。
ファイルをまとめて高速化
まず考えられるのは別々のファイルになっているベクトルをList[Tuple(str, List[ float] )]としてまとめて1ファイルにすることでioによる律速をなくすことです。これはpickleを使用して以下のようにして実現できます。
def create_file_vector_paris(folders: List[str]):
file_vector_pairs = []
for folder in folders:
for file in os.listdir(folder):
if file.endswith('.npy'):
a = np.load(os.path.join(folder, file))
vec = a[0].astype('float32') # NMSLIB requires float32 type
file_vector_pairs.append((folder + "/" + file, vec))
with open('file_vector_pairs.pkl', 'wb') as f:
pickle.dump(file_vector_pairs, f)
これを使って同じように近いベクトルを求めるコードは以下です。
def find_closest_vectors_scipy(ref:np.ndarray, top_k:int):
with open('file_vector_pairs.pkl', 'rb') as f:
file_vector_pairs = pickle.load(f)
start = time.time()
file_similarity_pairs = []
for elem in file_vector_pairs:
similarity = cosine(ref, elem[1])
file_similarity_pairs.append((elem[0], similarity))
file_similarity_pairs.sort(key=lambda x: x[1])
end = time.time()
print(f"Time taken to find closest vectors scipy: {end - start} seconds")
return file_similarity_pairs[:top_k]
これで大体1.9秒程度で近いベクトルを求められるようになりました。依然として遅いので、さらに高速化してみます。コサイン類似度を求める部分をnumpyでそのまま書いてみます。
def find_closest_vectors_numpy(ref:np.ndarray, top_k:int):
with open('file_vector_pairs.pkl', 'rb') as f:
file_vector_pairs = pickle.load(f)
start = time.time()
file_similarity_pairs = []
for elem in file_vector_pairs:
similarity = np.dot(ref, elem[1]) / (np.linalg.norm(ref) * np.linalg.norm(elem[1]))
file_similarity_pairs.append((elem[0], similarity))
file_similarity_pairs.sort(key=lambda x: x[1], reverse = True) # np.dotのときはreverse=True
end = time.time()
print(f"Time taken to find closest vectors numpy: {end - start} seconds")
return file_similarity_pairs[:top_k]
これでおおよそ0.57秒で近いベクトルが求められるようになりました。
近似最近傍探索を使用した高速化
近似最近傍探索は、あるベクトルに近いベクトルを探す際に、高速で解を求める探索です。詳しくは東大の松井先生の以下のスライドが参考になります。
今回は以下のフローチャートを参考に、faiss-cpuとnmslibを使用してみます。
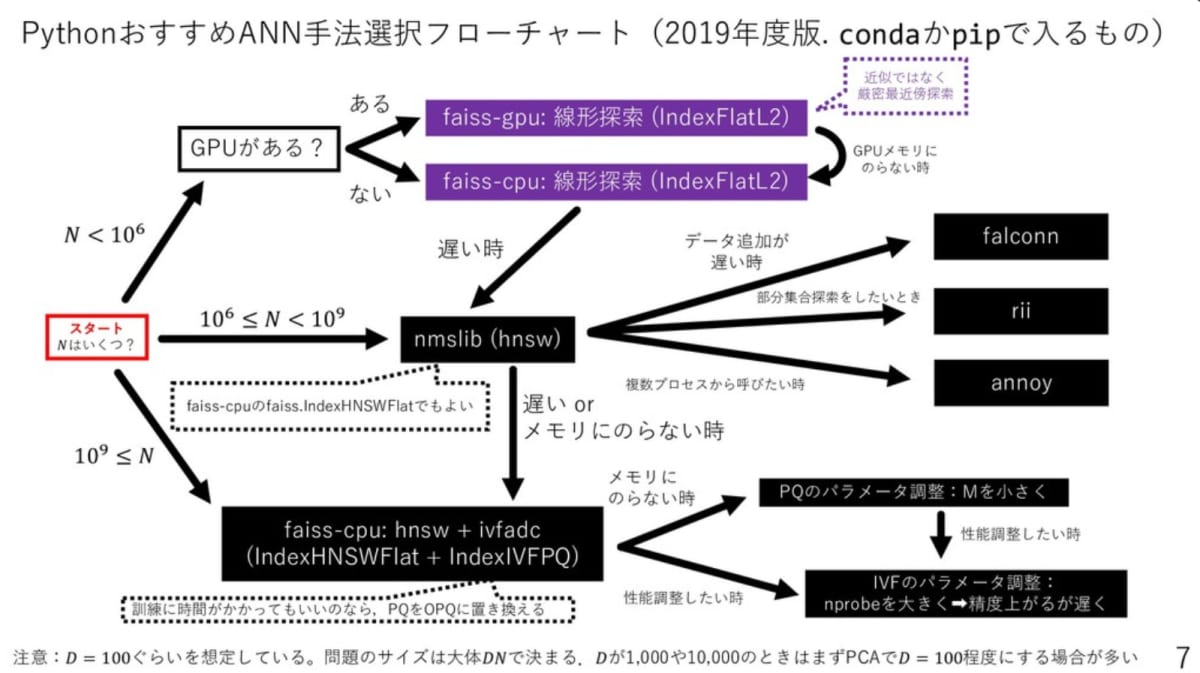
上記スライドより引用
faiss-cpu
faissはmetaが開発したライブラリです。公式のinstall方法はcondaを使用する方法か、ソースからビルドする方法しか提供されていませんが、pipでも、 pip install faiss-cpu でインストール出来ます。メルカリなどでも使用されているようです。今回はfaiss-cpuの高速化のうち、SIMDを使用して高速に厳密解を求める方法を試します。
近似最近傍探索をする場合は、大体の場合、まずデータを追加してindexを作成します。以下は、faissでindexを作成し、保存するコードです。
def create_index_faiss(folders: List[str], index_path: str='index.faiss') -> faiss.Index:
start = time.time()
dimension = 1536 # You should specify the dimension of your vectors
# If index doesn't exist, create it
index = faiss.IndexFlatL2(dimension)
file_vector_pairs = []
for folder in folders:
for file in os.listdir(folder):
if file.endswith('.npy'):
a = np.load(os.path.join(folder, file))
vec = a[0].astype('float32') # Faiss requires float32 type
file_vector_pairs.append((folder + "/" + file, vec))
# Add all vectors to the index
vectors = np.vstack([pair[1] for pair in file_vector_pairs])
index.add(vectors)
# Save the index
faiss.write_index(index, index_path)
end = time.time()
print("Faiss Index created in", end - start, "seconds")
return index
faissの場合はindexの作成に6.9秒かかりました。探索は以下のようにします。
def find_closest_vectors_faiss(ref: np.ndarray, index_path: str, top_k: int) -> List[Tuple[str, float]]:
with open('file_vector_pairs.pkl', 'rb') as f:
file_vector_pairs = pickle.load(f)
# Search the top_k closest vectors
start = time.time()
index = faiss.read_index(index_path)
_, indices = index.search(ref[np.newaxis, :].astype('float32'), top_k)
# Sort and retrieve the top_k file-similarity pairs
file_similarity_pairs = [file_vector_pairs[i] for i in indices[0]]
end = time.time()
print(f"Time taken to find closest vectors faiss: {end - start} seconds")
return file_similarity_pairs
検索は0.27秒でした、numpyの例の2倍速いですね。
nmslib
nmslibは近似的に近傍ベクトルを見つけるライブラリで、グラフ探査のアルゴリズムを使用しているようです。以下のようにしてindexを作成します。作成には19秒ほどかかりました。
def create_index_nmslib(folders: List[str], index_path: str='index.bin'):
start = time.time()
# Initialize NMSLIB index
index = nmslib.init(method='hnsw', space='cosinesimil')
file_vector_pairs = []
vector_ids = []
# Read vectors from files and add them to index
for folder in folders:
for file in os.listdir(folder):
if file.endswith('.npy'):
a = np.load(os.path.join(folder, file))
vec = a[0].astype('float32') # NMSLIB requires float32 type
file_vector_pairs.append((folder + "/" + file, vec))
vector_ids.append(len(file_vector_pairs) - 1)
index.addDataPoint(id=len(file_vector_pairs) - 1, data=vec)
# Index build
index.createIndex(print_progress=True)
# Save the index
index.saveIndex(index_path)
end = time.time()
print("nmslib Index created in", end - start, "seconds")
探索は以下のようにして行います
def find_closest_vectors_nmslib(ref: np.ndarray, top_k: int, index_path: str='index.bin') -> List[Tuple[str, float]]:
# Load the file_vector_pairs
with open('file_vector_pairs.pkl', 'rb') as f:
file_vector_pairs = pickle.load(f)
start = time.time()
# Query for the top_k most similar vectors
index = nmslib.init(method='hnsw', space='cosinesimil')
# Load the index
index.loadIndex(index_path)
ids, distances = index.knnQuery(ref.astype('float32'), top_k)
# Create pairs
file_similarity_pairs = [(file_vector_pairs[id_][0], 1 - distance) for id_, distance in zip(ids, distances)]
end = time.time()
print(f"Time taken to find closest vectors nmslib: {end - start} seconds")
return file_similarity_pairs
実行時間は0.14秒で更に短くなりました。ただし、nmslibは欲しい近傍ベクトルの数が多い場合に必ずしもそれを返すようにはなっていないようで、1000個欲しい場合に300個程度しか返ってこないなどといった問題があり、使用しないことにしました。
また、faissにもnmslibと同様のアルゴリズムを使用する faiss.IndexHNSWFlat があるのですが、探索時間は0.24秒とnmslibほど早くはならなかったため、今回はfaiss-cpuの IndexFaltL2 を使用することにしました。
使いやすくする
streamlitを使用したwebアプリ化
以下のようにして簡単に実装できます。
st.title("video search α版")
st.write("よく使用される検索ワード")
common_keywords = ['traffic light', 'night', 'wet road', 'tunnel', 'make a big left turn', 'people are walking']
# リストの長さに応じたカラムを作成
columns = st.columns(len(common_keywords))
for i, keyword in enumerate(common_keywords):
# 各カラムにボタンを配置
with columns[i]:
if st.button(keyword, use_container_width=True):
st.experimental_set_query_params(search_text=keyword)
search_text = st.text_input("検索したい文言を入力してください: ", value=st.experimental_get_query_params().get("search_text", [""])[0])
download_csv_index_number = st.number_input("検索結果の上位何件のデータをダウンロードしますか?: ", min_value=9, max_value=5000, value=9, step=1)
if st.button("Search"):
response = openai.Embedding.create(input=[search_text], model="text-embedding-ada-002")
embeds = [record['embedding'] for record in response['data']]
ref_vector = np.array(embeds[0])
closest_vectors = find_closest_vectors(ref_vector, download_csv_index_number)
# このあとの処理は各自自由に…
image_paths = []
captions = []
for idx, (image_path, dist) in enumerate(closest_vectors, 1):
image_paths.append(image_path)
captions.append(f"Rank {idx}: {image_path} \n distance {dist}")
df = pd.DataFrame({"image_path": image_paths, "caption": captions})
csv = df.to_csv(index=True).encode("utf-8")
# 上位n件のデータを含んだcsv
st.download_button(
"Download CSV",
data = csv,
file_name = "search_result.csv",
mime = "text/csv"
)
image_list = [Image.open(img_path) for img_path in image_paths[:9]]
cols = st.columns([1,1,1], gap="small")
for idx, col in enumerate(cols):
with col:
for i in range(3):
st.image(image_list[i*3 + idx], caption=captions[i*3+idx])
実行は以下のようにします。
streamlit run main.py
これにより、エンジニアでなくても、簡単に誰でも使えるシステムが出来上がりました。
検索したいクエリを入力しcsvをダウンロードしたい場合は上位何件の動画情報をダウンロードしたいかも設定しておきます。検索ボタンを押せば上位9件の動画のサムネイル画像とcsvのダウンロードボタンが表示されるようになります。
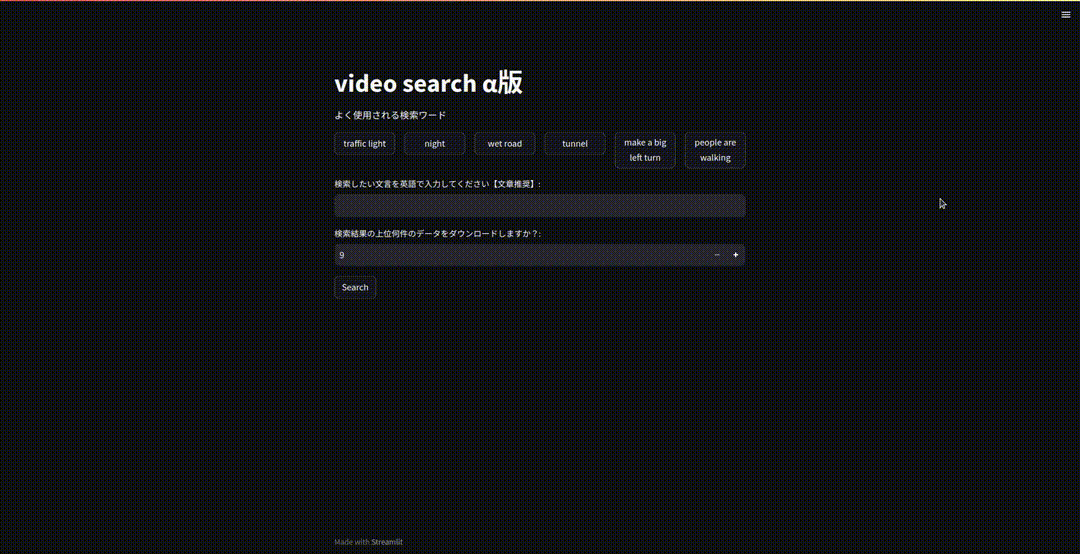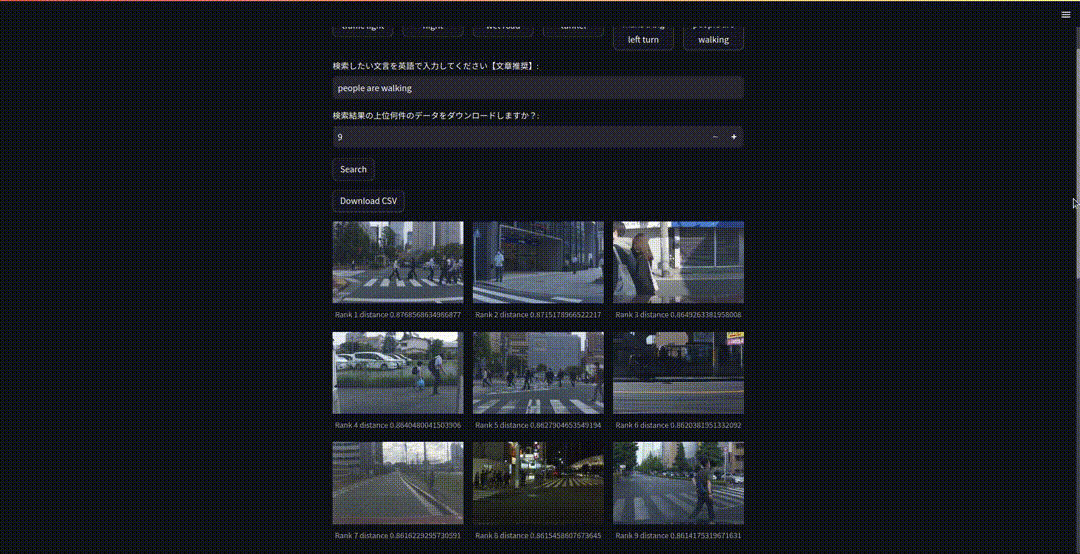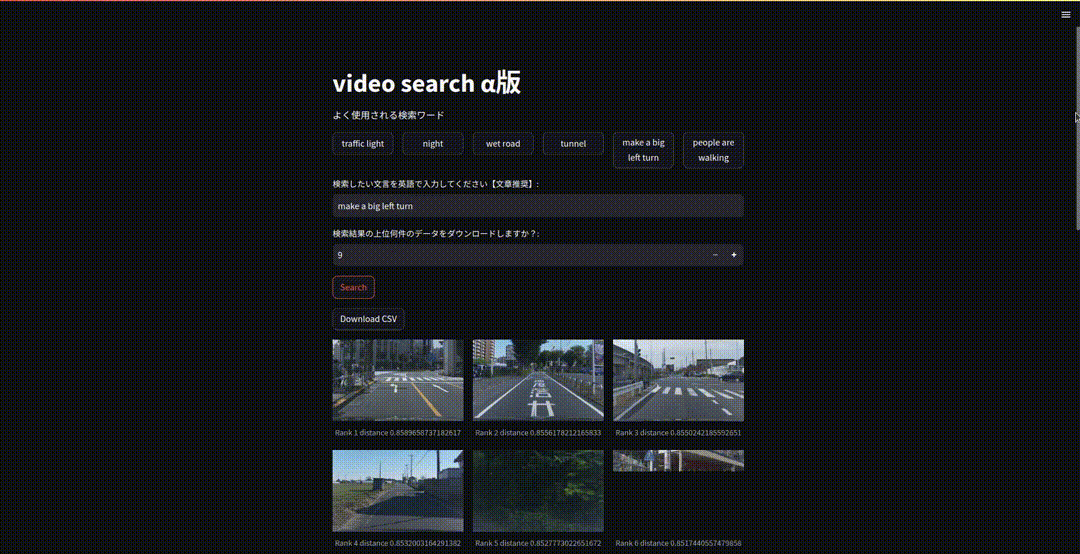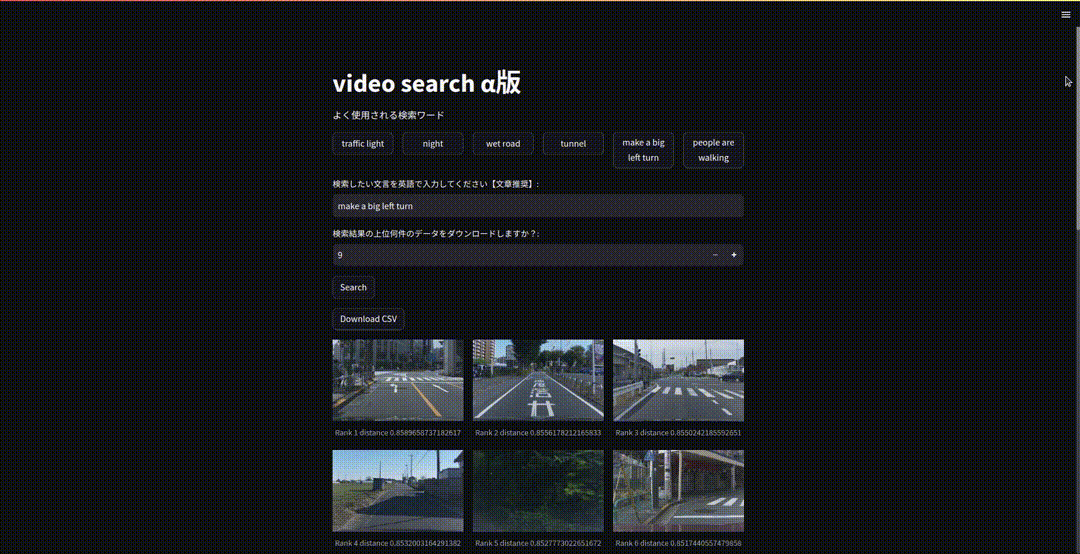
FastAPIを使用したAPI化
streamlitでブラウザを触るよりも、簡単に大量にダウンロードしたい場合があると思います。その場合はこんな感じで実行できます。この場合、返却するオブジェクトをhttp経由で返却できるように少しだけ変更しています。
from fastapi import FastAPI
from pydantic import BaseModel
import numpy as np
import openai
import faiss
import pickle
from typing import List, Tuple
app = FastAPI()
class SearchRequest(BaseModel):
search_text: str
download_number: int
def find_closest_vectors(ref: np.ndarray, top_k: int, index_path: str = 'index.faiss' ) -> List[Tuple[str, float]]:
with open('file_vector_pairs.pkl', 'rb') as f:
file_vector_pairs = pickle.load(f)
# Search the top_k closest vectors
index = faiss.read_index(index_path)
dist, indices = index.search(ref[np.newaxis, :].astype('float32'), top_k)
# Sort and retrieve the top_k file-similarity pairs
file_similarity_pairs = [{"filepath": file_vector_pairs[i][0], "distance" :float(dist[0][idx])} for idx,i in enumerate(indices[0])]
return file_similarity_pairs
@app.post("/search/")
async def create_search(request: SearchRequest):
# OpenAIでの処理
response = openai.Embedding.create(input=[request.search_text], model="text-embedding-ada-002")
embeds = [record['embedding'] for record in response['data']]
ref_vector = np.array(embeds[0])
closest_vectors = find_closest_vectors(ref_vector, request.download_number)
return {"closest_vectors": closest_vectors}
以下のようにしてリクエストを送ることで、欲しい情報が得られます。
curl -X POST "http://localhost:8000/search/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-d "{\"search_text\":\"Hello world\",\"download_number\":10}"
まとめ
複数の画像を認識するAIとChatGPTから動画を検索するシステムを構築する例について紹介しました。まだまだ、物体検出をよりターゲットを絞った高精度なものに置き換えたり、OCRを入れたりなど色々発展が考えられます。画像を認識するAIと、ChatGPT、そして文章を検索するシステムが粗結合であるためにどこか一箇所にブレークスルーが起こっても簡単に変えられるためまだまだいじり甲斐がありそうです。
Turingでは自動運転モデルの学習はもちろんのこと、自動運転を支える基盤モデルの作成、EV開発、MLOpsなどにも積極的に取り組んでいます。興味がある方は、是非、Turing の公式 Web サイト、採用情報などをご覧ください。

Discussion