はじめに
Turing株式会社ソフトウェアエンジニアの堀ノ内です!
私が所属する自動運転チームでは2024 ~ 2025年に発売予定の自動車に搭載する自動運転システムの開発を行っています。Turingでは車両前方に取り付けられたカメラの画像を入力とし、機械学習モデルが進むべき経路を推論、その経路に沿って実際に車両を動かすための制御信号(ステアリング、アクセル、ブレーキ)をCANで車両に送信することで以下の画像のような自動運転を実現しています。

今回のブログでは以下について記載し、私達のチームの仕事内容について知って頂くきっかけになればと思います。
- Turingの自動運転システムの紹介
- GMSLカメラの評価と発生した問題
- Linuxカーネル及びドライバのデバッグ
Turingの自動運転システム
Turingでは「カメラ画像入力 → 機械学習モデルで経路を推論 → 車両制御」の流れを実現するために必要なハードウェアやソフトウェアを全て含めて 自動運転システム と呼んでおり、詳細化した図が以下です。
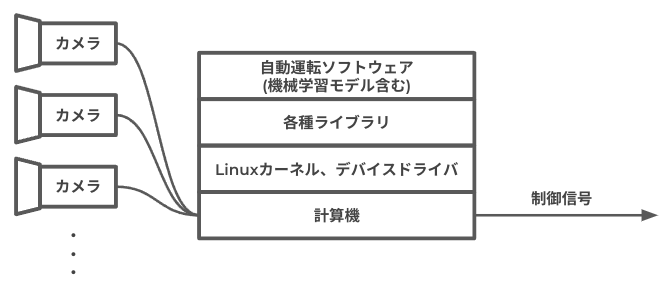
自動運転というとそのアルゴリズムや機械学習方面にフォーカスがあたることが多いのですが、それを実行するための計算機やカメラのハードウェア的な性能も密接に関係してくるため、私達のチームでは計算機/カメラといったハードウェアの選定/調達/評価から計算機上で動作するLinuxディストリビューションの構築、車両に対する制御信号の合わせこみなど、自動運転システムを実現するために必要となる様々な業務を行っています。
カメラの評価と発生した問題
前述したようにTuringの自動運転ではカメラ画像を入力として車両が進むべき経路の推論を行うため、カメラは非常に重要なコンポーネントの1つです。一口にカメラといっても様々な方式、スペックのものがありますが、車載に耐えうる信頼性や自動運転システムで必要とされるフレームレート、解像度、LEDフリッカー軽減機能、接続台数などを考慮した上でGMSLカメラの採用を検討しています。

今回動作確認に使用した計算機は上記GMSLカメラを正式にサポートしていることが明言されており、カメラの動作確認を行う手段として以下のGStreamerコマンドが用意されていました。
$ gst-launch-1.0 v4l2src device="/dev/video0" ! "video/x-raw, format=(string)UYVY, width=(int)1920, height=(int)1080" ! nvvidconv ! xvimagesink sync=false
ざっくり言うと、 /dev/video0につながっているV4L2対応カメラからUYVYフォーマット/1920x1080の解像度で画像をキャプチャし画面に表示するという内容です。これを実行すると正常に画像が表示されます。

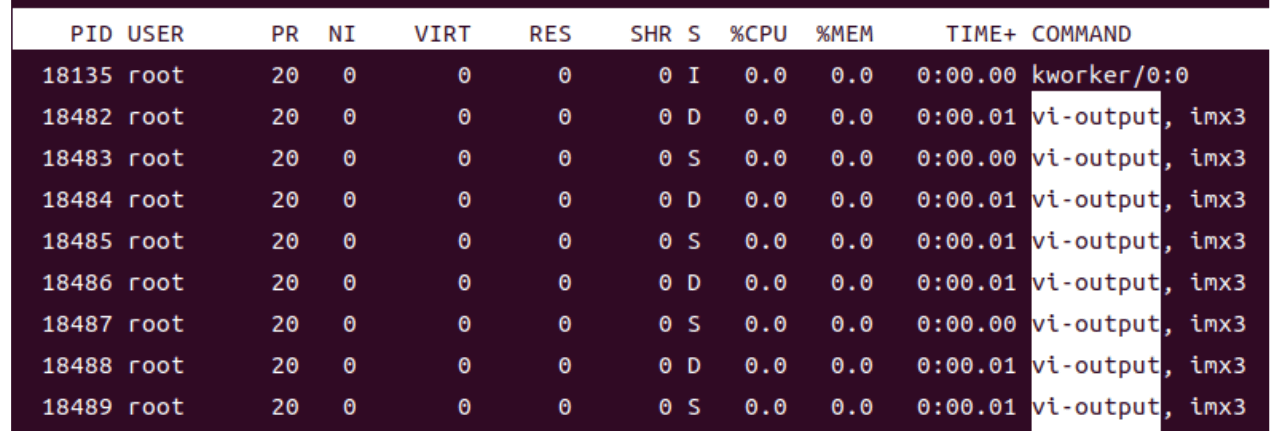
一見何の問題も無いように思われるのですが、リソースの使用量を確認するためtopコマンドを打つと、vi-outputというプロセスが1つのCPUを50%近く使用していることが分かります。

Turingの自動運転システムでは最終的に車両前方/後方/左右合計8台のカメラを同時にキャプチャする予定であり、かつカメラキャプチャの後段には機械学習モデルでの経路推論、車両制御といった重い処理が待ち構えています。ですのでカメラ1台のキャプチャでCPUを大量に消費してしまうわけにはいきません。そこでこの現象の原因究明に取り組みました。
原因の調査
プロセスの詳細を調査
まず、vi-outputとはどんなプロセスなのでしょうか?topコマンド実行中にcキーを押すと、実行コマンドがフルパスで表示されますが、vi-outputは[ ]付きで表示されるため、カーネルスレッドであることが分かります。またカメラキャプチャのコマンドを打った際に出現するため、Linuxカーネル(以降カーネルと呼ぶ)空間上で動作しているカメラに関連したドライバである可能性が高そうです。

不具合箇所を大まかに特定
こうなるとカーネルとドライバのソースコードが必要になってきます。ソースコードはGPLでライセンスされているため、計算機のメーカーに問い合わせすれば受領できるはずですし、それを見越して公開されていることもあるようです。今回は公開されているソースコードを発見し以降の調査に用いました。
カーネルやドライバのソースコードは膨大ですので不具合箇所にある程度あたりをつけなければ調査が進みません。そこでカーネル空間で動作するソフトウェアをトレースするftraceを使用します。webで検索すれば情報は多くでてくるので詳細は割愛しますが、以下のように実行することで、trace.logに関数の呼び出し履歴を得ることができます。
// どの種類のトレーサーをサポートしているかの確認
$ sudo cat /sys/kernel/debug/tracing/available_tracers
function_graph function nop
// 使用するトレーサーの指定
$ sudo bash -c "echo function > /sys/kernel/debug/tracing/current_tracer"
// トレース開始
$ sudo bash -c "echo 1 > /sys/kernel/debug/tracing/tracing_on"
// しばらくそのままにしてトレース終了
$ sudo bash -c "echo 0 > /sys/kernel/debug/tracing/tracing_on"
// ログ取得
$ sudo cat /sys/kernel/debug/tracing/trace_pipe > trace.log
得られたtrace.logをvi-outputで検索すると以下のような箇所がありました。
vi-output, imx3-33415 [009] ...1 6605.881441: kthread_should_stop <-tegra_channel_kthread_capture_enqueue
vi-output, imx3-33415 [009] ...1 6605.881442: kthread_should_stop <-tegra_channel_kthread_capture_enqueue
vi-output, imx3-33415 [009] ...1 6605.881443: _raw_spin_lock_irqsave <-tegra_channel_kthread_capture_enqueue
vi-output, imx3-33415 [009] d..2 6605.881443: _raw_spin_unlock_irqrestore <-tegra_channel_kthread_capture_enqueue
vi-output, imx3-33415 [009] ...1 6605.881444: kthread_should_stop <-tegra_channel_kthread_capture_enqueue
vi-output, imx3-33415 [009] ...1 6605.881444: kthread_should_stop <-tegra_channel_kthread_capture_enqueue
vi-output, imx3-33415 [009] ...1 6605.881445: kthread_should_stop <-tegra_channel_kthread_capture_enqueue
vi-output, imx3-33415 [009] ...1 6605.881445: _raw_spin_lock_irqsave <-tegra_channel_kthread_capture_enqueue
vi-output, imx3-33415 [009] d..2 6605.881446: _raw_spin_unlock_irqrestore <-tegra_channel_kthread_capture_enqueue
vi-output, imx3-33415 [009] ...1 6605.881446: kthread_should_stop <-tegra_channel_kthread_capture_enqueue
以降しばらく繰り返し
一番上の行はタイムスタンプ6605.881441にtegra_channel_kthread_capture_enqueue()という関数内でkthread_should_stop()という関数が呼ばれたという意味になります。これらの処理がマイクロ秒単位でしばらくの間繰り返されていました(分かりやすいように6行目に空白をいれています)。
ドライバの処理内容の調査と修正
tegra_channel_kthread_capture_enqueue()をソースコード内で調べてみると以下の内容となっており、ログの内容と一致していることが分かります。また、処理の内容が分かりやすいようにコメントを入れました。一言で言うと、キャプチャデータが得られるまでスリープして、得られたらユーザアプリケーションに渡すためのキューに詰めるという関数のようです。
static int tegra_channel_kthread_capture_enqueue(void *data)
{
while (1) {
// この関数が呼ばれた、またはchan->start_waitに対してwake_up()がコールされた際に
// 第二引数がTrueならば関数を抜け以降の処理へ。Falseならばスリープする。
// 本来はここでデータが得られるまでスリープすることを期待しているが、
// ftraceのログと照らし合わせるとlist_empty(&chan->capture)が常にFalseに
// なっており、ビジーループに陥っている可能性がある
// kthread_should_stop()
// 誰かがkthread_stop()を呼ぶとTrueを返す。スレッドを終わらせたい時に使う。
// list_empty(&chan->capture)
// リスト構造であるchan->captureが空の場合Trueを返す。
// ここではカメラのキャプチャデータが入っているchan->captureが空の場合はスリープし
// 空でない場合は以降の処理に進むために使われる
wait_event_interruptible(chan->start_wait, (kthread_should_stop() || !list_empty(&chan->capture)));
// キャプチャ中は基本的にkthread_should_stop()がFalseになっているのでwhileの条件はTrue
while (!(kthread_should_stop() || list_empty(&chan->capture))) {
// chanの中身を参照している途中に別スレッドから値を書き換えられないように排他処理
spin_lock_irqsave(&chan->capture_state_lock, flags);
// エラーが起きた場合の処理
// エラーが発生するとdequeue_buffer()が行われずlist_empty(&chan->capture)が
// Falseのまま冒頭のwait_event_interruptible()が呼び出され・・・を繰り返し
// ビジーループに入る可能性がある
if ((chan->capture_state == CAPTURE_ERROR) || !(chan->capture_reqs_enqueued < (chan->capture_queue_depth * chan->valid_ports))) {
spin_unlock_irqrestore(&chan->capture_state_lock, flags);
break;
}
// 排他処理解除
spin_unlock_irqrestore(&chan->capture_state_lock, flags);
// リストであるchan->captureから要素を1つ取り出してbufとして返す
// whileの中の処理であるため、取り出す処理を繰り返し、
// chan->captureが空になるとNULLが返るためbreakする
buf = dequeue_buffer(chan, false);
if (!buf)
break;
// 上で取り出したbufをユーザアプリケーションに渡すためのキューに入れる
vi5_capture_enqueue(chan, buf);
}
// 誰かがkthread_stop()を呼ぶとここでbreakしてループが終わる
if (kthread_should_stop())
break;
}
return 0;
}
本来ループ冒頭のwait_event_interruptible()でデータが得られるまでスリープすることを期待しているはずが、エラー発生時に限ってはカメラのデータを格納したリストからデータの取り出しが行われないことでスリープせずビジーループに陥ってCPU使用率が高くなっている可能性がありそうです。
そこでカーネルのログであるdmesgを確認してみると、キャプチャ開始時に何かしらのエラーが発生した形跡が確認できました。

ひとまずエラー時もdequeue_buffer()を入れてリストをクリアするといいのでは?との考えから以下のような修正を入れてみます。

そしてNVIDIA公式の手順を参考にカーネルをビルドし実機に適用したところ、CPU使用率が下がっていることが確認できました。

また、カメラ8台の同時キャプチャも問題ありません。

今後のアクション・まとめ
CPU使用率は下がったもののオリジナルのコードはNVIDIA製であり、かつ関連するコードが多く複雑であるため、今回行った修正が本当に正しいのか判断が難しいのが実情です。したがって、今後は副作用がないかを確認するため連続稼働試験を行ったり、NVIDIAのフォーラムへの修正提案のやりとりを行う予定です。またキャプチャ開始時に発生しているエラーの原因も引き続き究明していきます。
<フォーラムへの投稿>
本ブログでは自動運転システムに搭載するためのGMSLカメラの動作確認時に発生したCPU使用率が増大する問題について、カーネル/ドライバのソースコードレベルで解析を行い、修正することでCPU使用率が下がることの確認までを紹介しました。一口に自動運転システムと言っても様々なレイヤがあり、幅広い技術分野で自動運転システムの実現を目指していることがお分かり頂けたかと思います。
最後に
これまでご紹介した通り、Turingの自動運転チームでは自動運転の機械学習モデルやアルゴリズム開発以外にも、ハードウェア選定/評価、Linux上での組み込みソフトウェア開発、Linuxディストリビューションの構築など低レイヤ寄りのタスクが多く存在します。優れた自動運転システムを開発するため、このようなレイヤに興味があるエンジニアを広く募集しておりますので、ご興味のある方はTuring公式サイトや採用情報をご覧ください。また自動運転チームに限らずTuringについてお話しできる場として「Turingカジュアル面談の部屋」もありますので、お気軽にご連絡ください!
最後になりますが、自動運転チームは本当に幅広い分野を扱うチームです。時にはFusion360でカメラマウンタを設計して3Dプリントしてみたり、車につなぐハーネスを作ってみたり、仕事の息抜きにメンバーではま寿司にランチに行ったりと、楽しくてやりがいのあるチームです。終わりまでこのブログを読んでくれた好奇心旺盛なそこのあなた!join待ってます!


Discussion
もとのコードを確認した、多分ですが、以下の3点気をつけたほうがいいかも
1.dequeue_buffer()を呼ぶことで、画像キャプチャの流れが変わった可能性があります。
2.例えば壊れた(e.g., CAPTURE_ERROR)フレームがあったとして、もともとdequeしないはずが、ここでdequeされて、逆にリソースの無駄。
3.同じく、壊れた(e.g., CAPTURE_ERROR)フレームがあったとして、上位システムでエラーハンドリングできなくなって、認識システムで誤った処理をしちゃう
手元にデバイスがないから確認できないが、解決として、これはいかがでしょうか?bufferいじらず行けるかも?!