こんにちは。TURING株式会社でインターンをしている、東京大学学部3年の三輪と九州大学修士1年の岩政です。
TURINGは完全自動運転EVの開発・販売を目指すスタートアップです。私たちの所属する自動運転MLチームでは完全自動運転の実現のため、AIモデルの開発や走行データパイプラインの整備を行っています。
完全自動運転を目指すうえで避けて通れない課題の一つに信号機の認識があります。AIが信号機の表示を正しく理解することは、自動運転が手動運転よりも安全な運転を達成するために欠かせません。信号機を確実に認識したうえで、周囲の状況を総合的に判断して車体を制御し、安全かつ快適な走行を実現する必要があります。
TURINGでは信号機の認識に取り組むため、15,000枚規模のデータセットを準備し、高精度なモデルのための調査・研究を開始しました。この記事ではデータセットの内製とその背景にフォーカスしつつ、YOLOXを用いた試作モデルについても最後に紹介したいと思います。
1. 信号機の難しさ
信号機の意味するところは小さな子供でも理解できます。頻繁に車に乗っている幼児は「信号が青になったら車が進んで良いのだ」と知っていることがありますし、小学校に入るころにはほとんどの子供が歩行者用信号の青と赤を認識して、適切なタイミングで道路を横断できるようになります。しかし、AIにこれを理解してもらうのは案外難しい問題です。そこには、様々な事情があります。
1.a. コンテクスト理解の難しさ
信号機の認識が難しい理由として挙げられるものの一つが、コンテクスト(文脈)理解の困難です。
例えば、この写真はTURINGのデータセットで見つかったものです。右前のバスのガラスに信号機が反射して写っています。これはどのように理解すべきでしょうか。
人間は「この信号機は窓に反射している」というコンテクストから、この信号機の情報をどのように理解すればいいかを判断できます。しかしAIにとって、窓に反射した信号機と本物の信号機を区別することは容易ではありません。

以前有名となった事例に、「前方を信号機を積んだトラックが走っているために自動運転車が誤認識した」というものもあります。正しくコンテクストの理解ができている人間には信号機がトラックと共に移動するのはあり得ないとわかるのですが、AIはこれをまだ理解できていなかったのです。
コンテクスト理解はこのようなレアな場面でのみ必要なわけではありません。実は「どの信号機を見るべきか」という基本的な問題さえ、AIにとっては十分に難しいタスクとなります。下の画像で見るべきは右側の信号機ですが、これを判断するには「自分がこのあとどのように進むのか」という予測が必要になります。多くの人が自然にできることでも、AIにとっては非自明な問題です。

1.b. ハードウェアの事情
一方、AIの目となるハードウェアであるカメラに由来する問題もあります。
まず、多くのカメラには「信号の光が写らないことがある」という問題があります。LED式の信号機が50Hzまたは60Hzで点滅するため、カメラのフレームレートと露光時間によってライトが写らなくなってしまうのです。

このような問題はフレームレートを調整することで緩和できます。多くのドライブレコーダーでは29Hzのような中途半端なフレームレートを採用し、信号機の点滅と噛み合ってしまうことを防いでいます。それでも運悪く真っ暗な信号機が写ってしまうことは避けがたい問題です。
機械学習のうえでは、十数枚に一度消えてしまう程度であれば連続する数フレームを入力するなどの方法で対処できますが、画像1枚に対する処理では限界があります。
また、信号機は多くの場合にカメラから遠く、高い位置にあります。このため、カメラの視野における信号機の占める領域は小さくなりがちです。下の画像は1928x1208pxの画像です。中央左上のあたりに二つの青信号が写っています。人間の目でははっきりと見えますが、これらはそれぞれ22x9pxと23x11pxというかなり小さなオブジェクトです。このようなオブジェクトの検出は難しいタスクになります。

そもそも、写真では赤なのか青なのか黄色なのかよくわからない、ということもあります。例えば次の写真はおそらく赤ですが、青と言われれば青にも見えます。実はこの信号機は人間の目でも難しく、時系列と周囲の状況を考慮して判断することになりました。AIにも難しい問題です。

1.c. 複雑性と多様性
コンテクスト理解の難しさ、ハードウェアの事情に加えて指摘しなければならないのが、日本の信号機の複雑性と多様性です。
日本の信号機は複雑です。3色の区別に加え、矢印、点滅などの意味を正しく把握しなければなりません。さらに「自転車専用」「時差信号」「スクランブル式」といった、自然言語で書かれた標示板が加わる場合もあります。信号機の上に「予告信号」と書いてあるのを理解できなければ、自動運転車はその前で立ち尽くしてしまうかもしれません。
信号機自体の多様性も問題を困難にしています。
例えば関東の信号機の向きは横が一般的ですが、北海道では縦のものも一般的に使われています。新しいフラットな信号機もあれば、古いものもあります。ゼブラ板のついたものや、「懸垂型」と呼ばれる形の信号機もあります。

矢印信号も常に本体の下につくわけではありません。
表示される矢印にしても、単なる右折、直進、左折だけではなく、斜めのものやUターンするものもあります。路面電車用の灯火である「黄色の矢印」「赤のバツ印」といったものもあり、これも問題を複雑にしています。

https://commons.wikimedia.org/wiki/File:Signal_LED.jpgより / CC BY-SA 3.0
人間の運転者が見るのは自動車用信号だけではありません。歩行者用信号を見て右左折のタイミングを判断したり、自動車用の信号が黄色になりそうなことを予測したりすることができます。AIは歩行者用信号も理解できることが望ましいですが、歩行者用信号にもさまざまなバリエーションがあります。
また、AIが歩行者用信号の「点滅」と、先ほどの「写っていないだけ」の信号機を区別するためには、時系列を考慮する必要があります。点滅の認識も苦手なタスクの一つです。
1.d. 現状
ここまで見たとおり、信号機の認識は非常に難しい問題です。間違いなく重要であるにもかかわらず、日本の信号機に特化したデータセットは現状ほとんどありません。アメリカなど、海外の一部地域に特化したデータセットはいくつかありますが、もちろんそのまま使うわけにはいきません。
そこでTURINGでは日本の信号機認識のためのデータセットを作成し、この問題に取り組むことにしました。
2. アノテーションツール選定
画像や動画、音声などの生データに対し、ラベル、数値データ、2値素性のような機械処理しやすい情報を付与する作業をアノテーションといいます。TURINGでは、独自に取得した走行データに信号機の領域や表示内容の情報をアノテーションし、信号機認識のためのデータセットを作ることにしました。
人手によるアノテーションに本格的に取り組むのは会社として初めての試みです。外注等も検討しつつ、まずはアノテーションを社内で一度やってみる必要があると判断しました。
そこでまず、アノテーションに用いるツールの選定を行います。
ツールの選定に際し、以下のような点を考慮しました。
-
環境構築が容易であること
社内の非エンジニアがアノテーションに参加する可能性や、将来的に外注する可能性を考慮すると、環境構築が容易であることはほぼ絶対条件となります。主要なブラウザで動作するWebツールやクロスプラットフォームのアプリケーションが理想的でした。
-
機能が十分であること
一部のアノテーションツールは構造化されたラベルを扱えなかったり、動画を読み込めなかったりしました。信号機は複雑なラベル付けが必要になる可能性があるので、そのようなツールは選べませんでした。
-
継続的にメンテナンスされていること
開発がアクティブであり、メンテナンスが継続的であること、できればオープンソースであることを条件としました。
-
手が痛くならないこと
UIが悪くないものを選びました。人手によるアノテーションではAX(𝑨𝒏𝒏𝒐𝒕𝒂𝒕𝒐𝒓 𝑬𝒙𝒑𝒆𝒓𝒊𝒆𝒏𝒄𝒆)が大切です。キーバインディングが利用可能なことが望ましいです。
これらの条件をもとにさまざまなアノテーションツールを検討したうえで、TURINGではCVATを利用することにしました。
CVATはOpenCV(インテル)が開発するオープンソースのアノテーションツールです。Web上で動作するので環境構築が容易です。開発は活発に行われており、アノテーションに必要な機能はある程度揃っています。キーバインディングもあり、手が痛くなりません。セグメンテーションデータ作成などの用途では半自動アノテーションなどのリッチな機能も色々あるようですが、今回はObject Detection用のデータ作成なのでそこはあまり触りませんでした。
TURINGではCVATをローカル環境でセルフホストし、アノテーションを行うことにしました。
3. アノテーションの実施
3.a. タスクの構成
TURINGで2022年に取得した500時間の走行データから、適当に15,000枚の画像を切り出しました。これを30分割し、1セット500枚としてアノテーションタスクを設定しました。
ラベルは比較的シンプルな設計にしました。上で見たとおり信号機の表示にはさまざまな例外的なパターンがあるため、最初から完璧を目指しても仕方ないだろうと思われます。
Empty
Green
Yellow
Red(Left, Forward, Right)
P_Red
P_Green
Emptyは点滅、またはカメラの都合で光っていない信号に付与するラベルです。Green, Yellowはそれぞれ青、黄色の自動車用信号です。また、Redはサブラベルとして三方向の矢印信号のON/OFFの情報も設定します。P_Redは歩行者用の赤信号、P_Greenは歩行者用の青信号を指します。
アノテーションはCVATのGUI上で実施します。下の画像ではこのほかP_Redを2つ、Emptyを2つアノテーションする必要があります。

今回の分類では判断基準がほとんど自明なので、ラベル同士の区別についてはあまり問題になりません。ただ、どれくらい小さい信号機までアノテーションするのか、という点についてはアノテーターごとに揺れてしまう可能性があります。気付ける限りで、全ての信号機をアノテーションすることにしました。
また、カメラに対して横向きの信号機についても判別がつく限りアノテーションすることにしました。こちらは特に「横向き」というようなラベルは設けませんでした。
こういう感じで、代表・社員・インターンが総出でアノテーションします。業務中に手が空いた人や、頭を休めたい人が隙間時間でやる、という運用にしました。早い人は1セット500枚あたり30~40分程度で完了します。プロのアノテーターが複数現れました。
(一日一万回は盛ってます)
3.b. アノテーションの結果
3週間弱で15,000枚のアノテーションが完了しました。
画像自体はたくさんありますが、信号機が写っているのはこのうち20%強でした。ただし複数の信号機が写っている画像も多く、全部で6,852個の信号機のデータができました。1枚当たりの信号機の個数の分布は以下のようになりました。
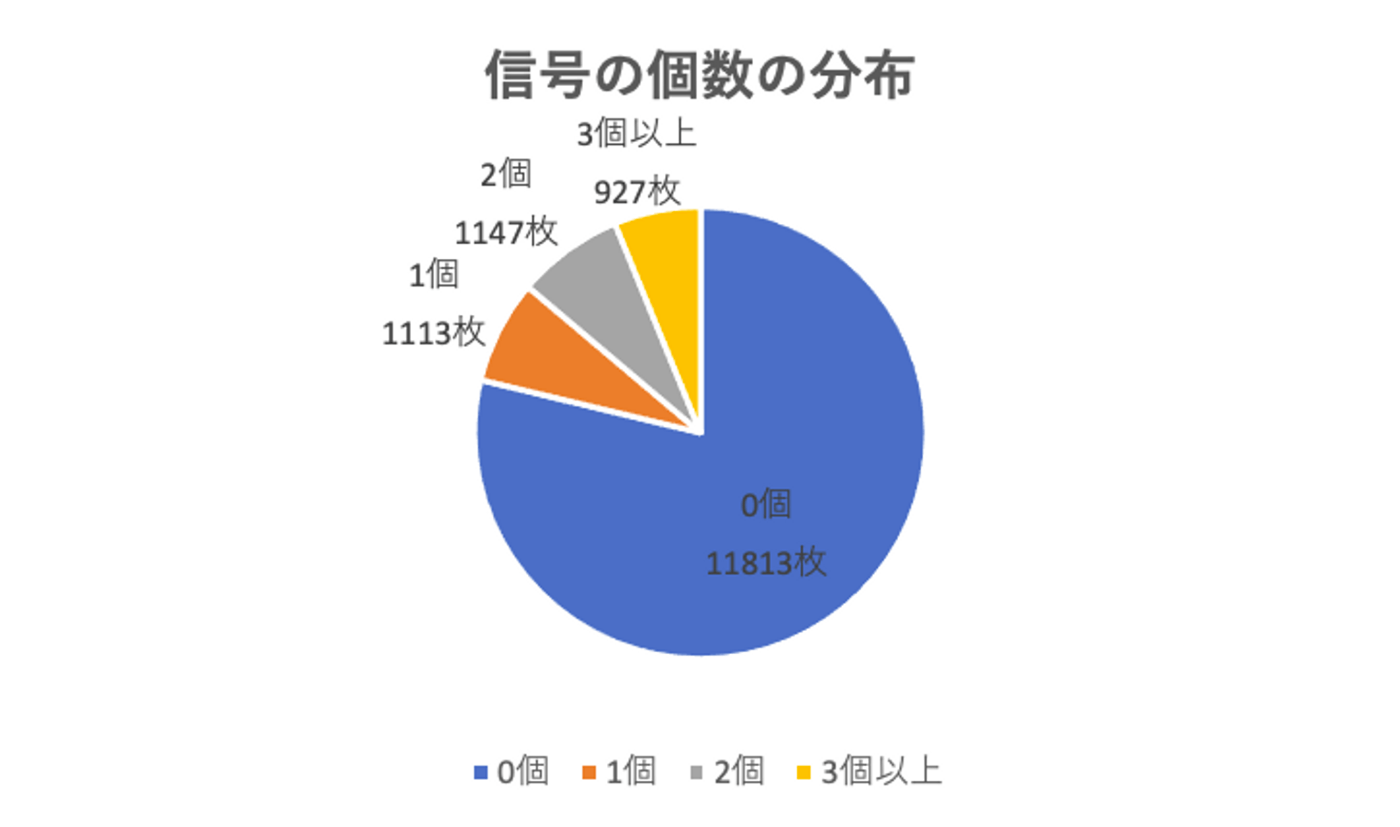
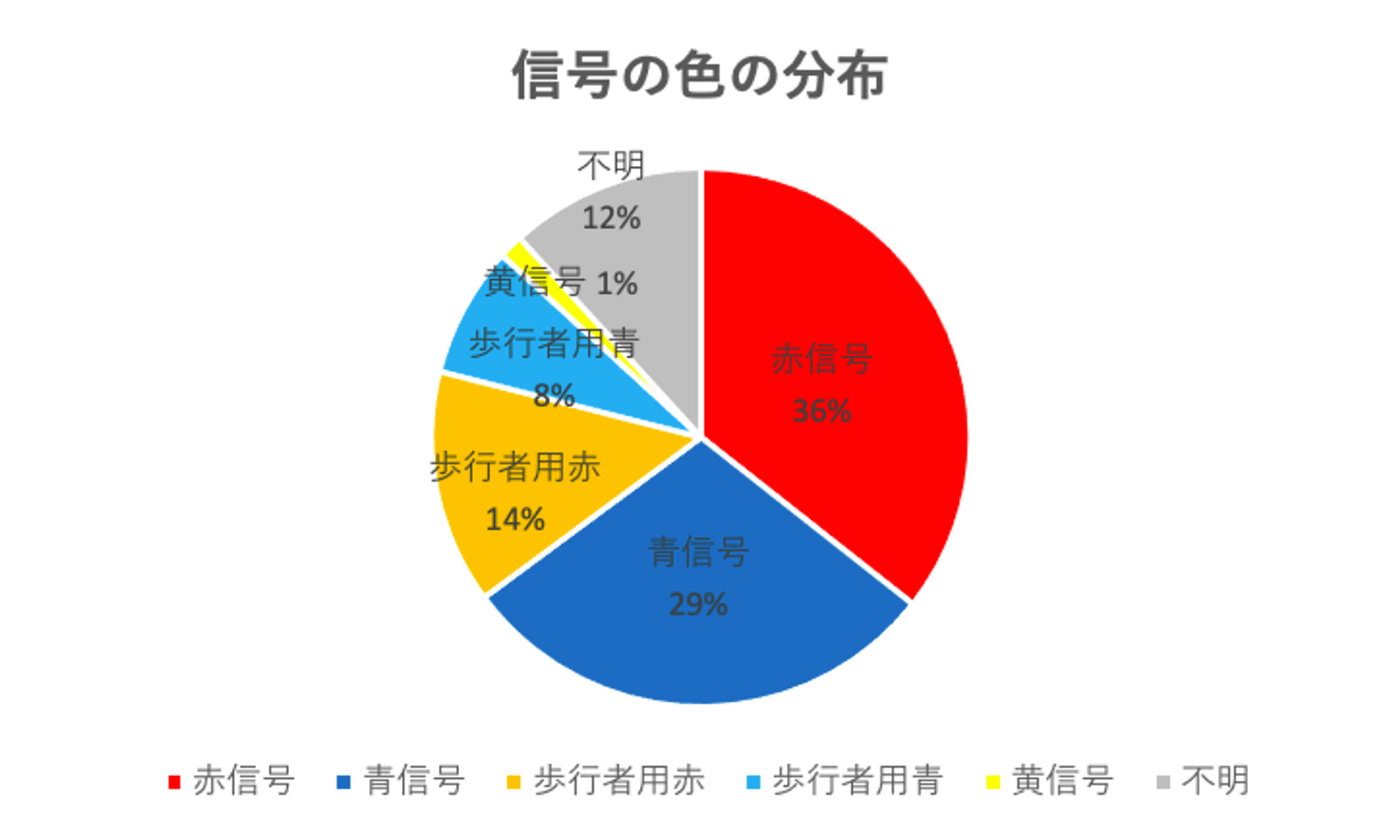
最も多いのが赤信号、次に多いのが青信号で、黄信号は全体で99個しかデータがありませんでした。黄信号は表示されている時間が非常に短いので、写っていることも稀になります。なお、矢印を伴う赤信号も非常にレアでした。
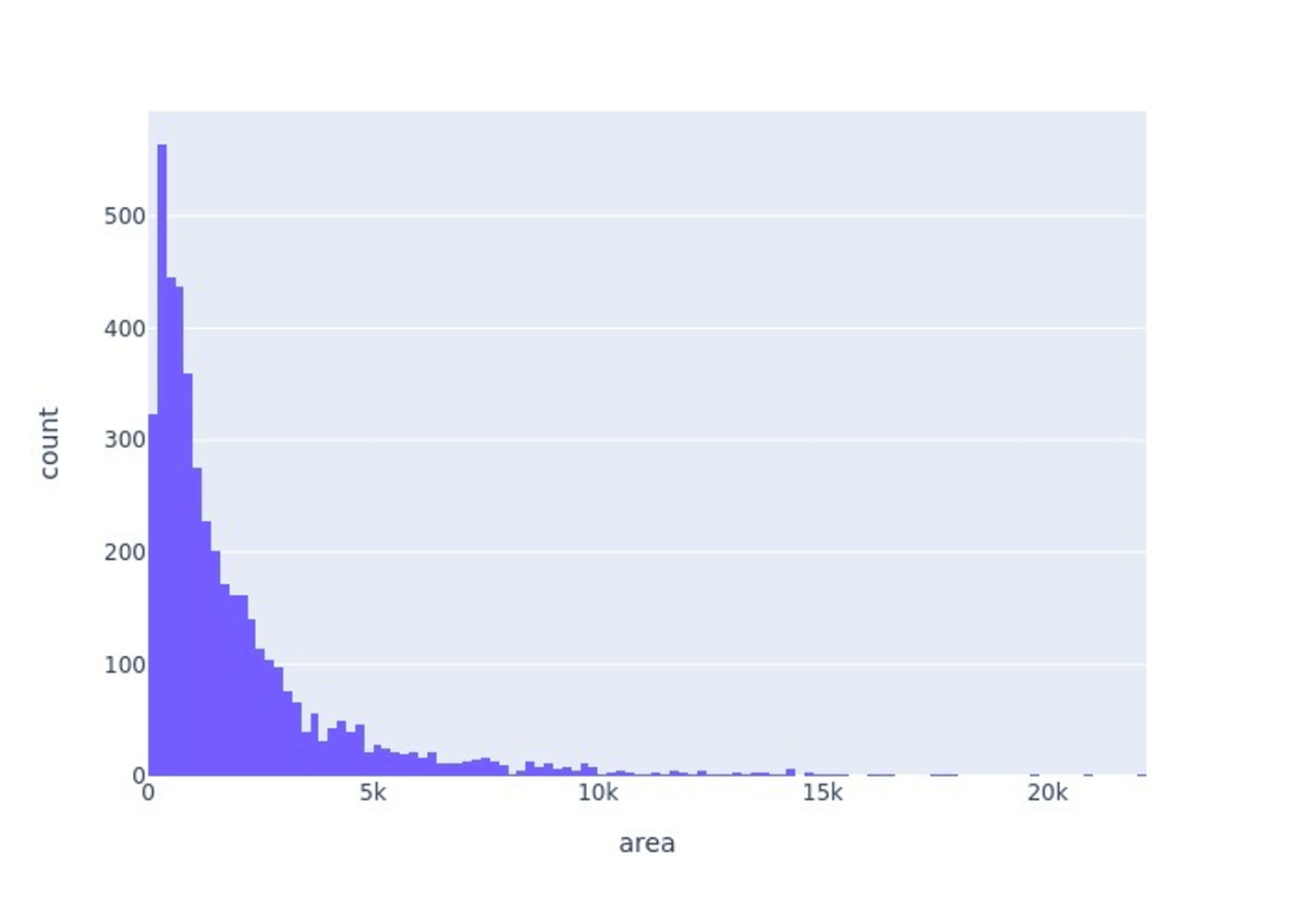
Box Size(信号機の領域のサイズ)の分布は以下のようになっています。面積が400px程度(約20x20px)の信号機が最も多く、基本的にかなり小さい領域の検出が必要であることがわかります。
このアノテーションプロジェクトでCVATを使ってみて、課題も見えてきました。
まず、CVATのプロジェクト管理がややイマイチでした。Projects > Tasks > Jobsという階層関係があるのですが、プロジェクトにアクセスできるアカウントは一つのみで、個々のアノテーターが全貌を把握することができないようになっています。業務委託のような形式ならそれでも問題ないのかもしれませんが、社内でワイワイ進めていくならプロジェクト全体を把握できた方が便利です。
また、CVATにはシンプルなキーバインディングがあるのですが、カスタマイズがあまり効きません。「Rを押したら赤信号の領域を作る」といった設定が出来ると良いのですが、今のところは難しそうです。
社内ではChrome拡張で対処できないか、と話しています。そのうちChatGPTにお願いする予定です。
4. モデルの作成
以上で作成したデータセットを用いて、ベースラインとなるモデルを作っていきます。物体検出によく用いられるYOLOXを使います。
4.a. YOLOXのモデルの構造
YOLOは深層学習ベースの物体検出モデルであり、高速かつ高精度な検出が可能でリアルタイムの物体検出に適しています。これまでYOLOをベースにしたモデルが複数展開されており、YOLOXはその中の1つです。
YOLOv4やv5といった従来のYOLOと比べてYOLOXの特徴的なところは「アンカーフリー構造」を取り入れたことで、より高速にこれまで以上の精度を達成したということです。2021年のコンピュータビジョンとパターン認識に関する国際的な会議であるCVPRにおいて開催されたワークショップのStreaming Perception Challengeでは、YOLOXが優勝しています。
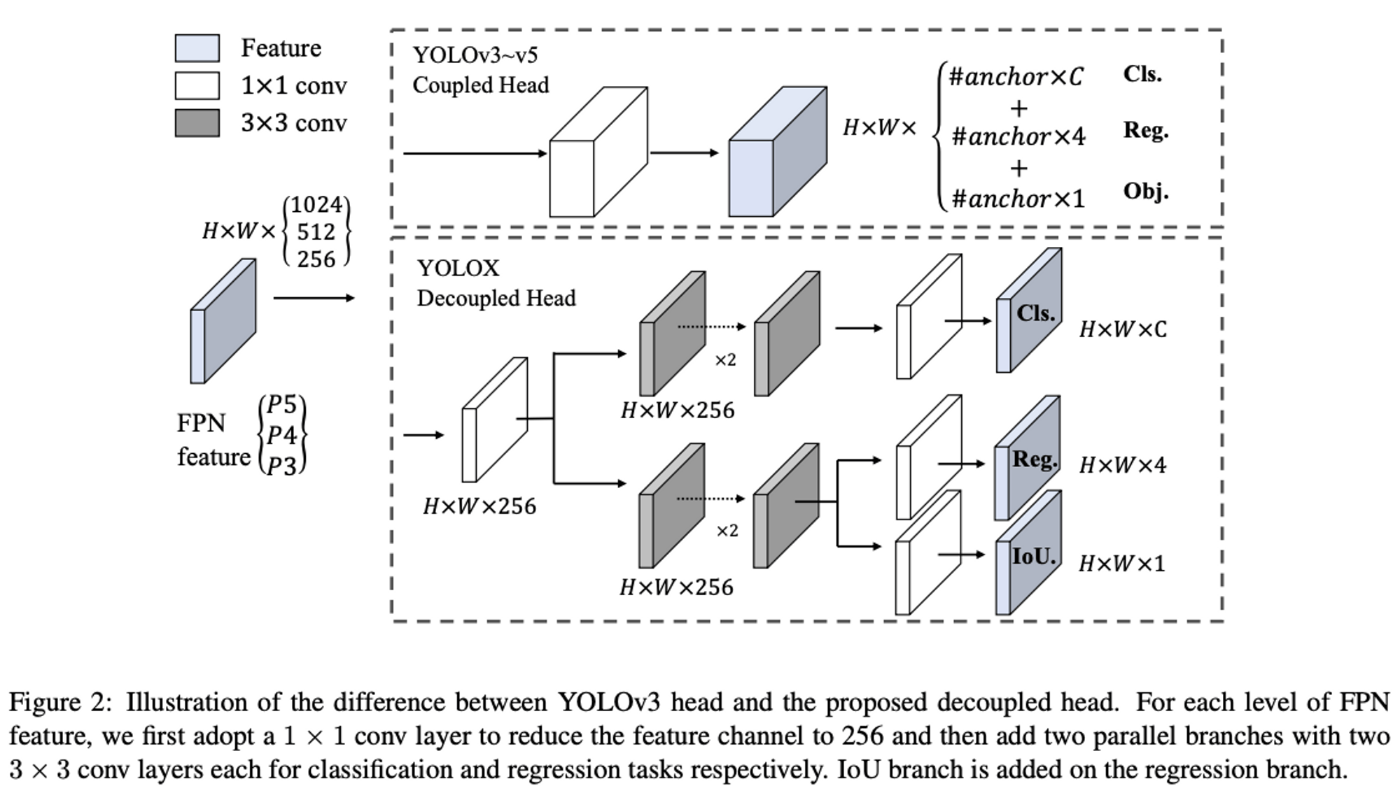
YOLOX: Exceeding YOLO Series in 2021から引用
YOLOXの大きな改良点としては「検出の分類・回帰構造のマルチヘッド化(decoupled head)」「強いデータ増強の追加」「アンカーフリー構造」「学習時の正例サンプルの改良(multi positives)」「SimOTA」が挙げられています。ここでは、特徴的な構造であるアンカーフリー構造について紹介します。
物体検出のアンカーを基準とした構造は、ドメインに特化したアンカーの数やサイズ、アスペクト比を調整する必要があり、汎用性に欠ける問題があります。一方で、アンカーフリーの構造は、調整が必要なハイパーパラメータが少なく、様々なドメインに適応しやすく、また、アンカーフリーの検出モデルの構造がシンプルになるため、より高速に学習・推論ができるようになります。
YOLOv3やYOLOXでは、Darknet53構造を用いて画像特徴抽出を行います。Darknet構造では、層が深くなるにつれて、特徴マップのサイズは徐々にダウンサンプリングされます。YOLOXでは、元の画像サイズから8分の1、16分の1、32分の1されたグリッド状の特徴マップを物体検出に用います(例えば、元画像が512×512ピクセルの場合、32分の1にダウンサンプリングされた特徴マップは16×16になります)。
従来のYOLOの構造では、サイズの異なるアンカーボックスを、特徴マップの各セルで複数個出力させていましたが、アンカーフリーのYOLOXでは、特徴マップの1つのセルにつき1つのアンカーボックスを出力する構造になっています。このアンカーフリー構造を追加することで精度を向上させつつ高速に物体検出が可能になりました。
4.b. YOLOXの学習結果・精度について
動画のように信号機の検出が行えるようになりました。
テストデータでのAverage Precisionは0.504、Average Recallは0.614です。ラベルがシンプルなこともあり検出はよくできています。推論速度も非常に速く、リアルタイムでの検出も可能です。
精度は昼間の方が高く、夜は落ちる傾向があります。夜になると遠くが見えづらくなるほか、信号機以外のライトがたくさん点灯することもあり、正確な判断は難しくなります。また、Box Sizeについては、車に近い大きい領域ほど検出しやすく、非常に遠くにある小さな信号の検出は精度が弱い傾向がありました。これらは直感的な結果です。
高速道路上の電光掲示板を赤信号と間違ってしまうような誤りもありました。この辺りはコンテクストをさらに理解させる必要がありそうです。

4.c. 今後の課題と方向性
誤検出についてもさらなる傾向等の分析が必要ですが、それ以外にも課題が残っています。
今回作成したモデルでは信号機の矢印を検出していません。矢印を含む信号機の画像自体が非常に少なかったことも背景の一つですが、矢印の予測結果をどのように扱うかという問題もあります。
今回扱っている三方向の矢印で可能な組み合わせを単純に展開してしまう場合、組み合わせは八通りあるため、赤信号だけで八つのクラスを用意することになります。
正解ラベルの方を[1(赤信号), 0, 0, 0, 0, 0, 1(左矢印), 1(中矢印), 0(外矢印)]のようにする、という方法もあり得ますが、one-hot表現を諦めることになってしまいます。この辺りは今後取り組んでいかなければならない点となりそうです。
また、動画データを扱っていますが、今回は1画像単位での推論です。したがって、ある画像での信号機の写り方が悪くうまく検出できていない場合や、カメラのフレームレートと信号機の露光時間によってライトが写り込まず、適切な色を検出できない場合があります。
今後、時系列データとしての処理を取り入れることで、過去のフレームの情報を活用し、より高精度な検出を目指していきます。
5. まとめ
この記事では、AIが信号機を認識することの難しさを確認し、学習データの不足を解決するために行ったデータセットの内製について書きました。TURINGでは作成したデータセットを用いてベースラインとなるモデルを準備し、信号機の認識モデルの開発を進めています。今回は予備的な調査としてシンプルな分類を行いましたが、実際に存在する多様な信号機をどのように分類しラベル付けすべきか、あるいは異なる方法でアプローチするのか、という点についても検討を進めていく必要があります。
今回はアノテーションの話をたくさんしましたが、TURINGの自動運転MLチームがアノテーションばかりしているというわけではありません。TURINGが目標としているTeslaは人手によるアノテーションを減らすため、オートラベリングの研究を推進しています。TURINGでも、白線検出の分野では時系列情報を用いたオートラベリングを実現したほか、自己教師あり学習などの「アノテーションレス」な手法についても研究を行っています。
私たち自動運転MLチームは、最も強力な自動運転モデルを作ることを目標としています。2023年は大規模モデルを構築するために必要な50,000時間分のデータを取得する計画をし、必要な準備を着々と進めています。
最強の自動運転モデルの開発に興味がある方は、TURINGの採用ページをご覧ください。
CEOの山本、CTOの青木、Director of AIの山口のDMも解放しています。お気軽にご連絡ください。

Discussion