1. はじめに
こんにちは、TuringのEnd-to-End自動運転チーム(以降E2Eチーム)で自動運転システムを開発している加藤です。本記事はE2Eチームの取り組みを知ってもらう連載企画の第四弾として、End-to-End自動運転における三次元物体検出のあり方と、三次元物体検出の代表的な手法を紹介し、Turingの開発状況についてお話します。
Turingでは2025年までに東京の複雑な道路を30分以上介入なしで運転できるようなE2E自動運転システムを開発する「Tokyo30」というプロジェクトに取り組んでいます。
私達が目指すE2E自動運転の基本概念については、連載企画第1回の以下の記事を参照ください。
また、私達はEnd-to-End自動運転モデルの開発において、物体認識やマップ認識のサブタスクを組み合わせるマルチタスク学習に取り組んでいます。E2E運転におけるサブタスクの考え方と、マップ認識については、連載企画第2回の以下の記事を参照ください。
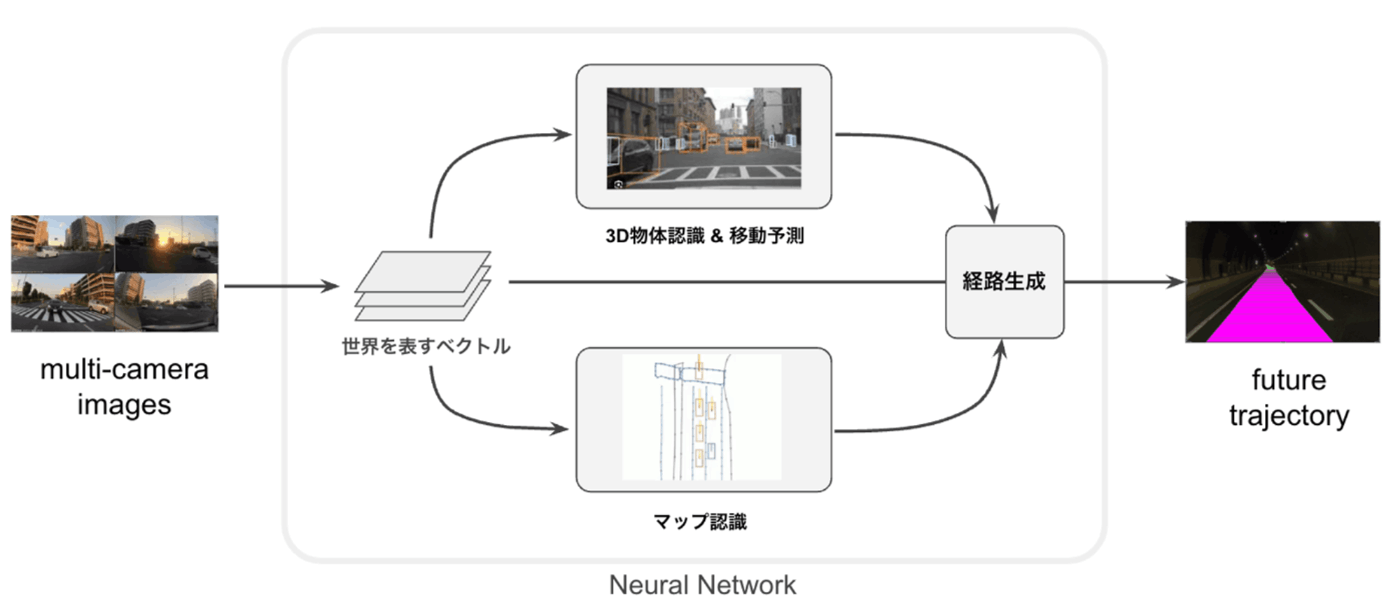
E2Eチームが開発している自動運転の基本概念
2. End-to-End自動運転における三次元物体検出
自動車を運転するには、周囲の状況を認識し、その後の変化を予測しながら行動を決定する必要があります。自動運転においてその仕組みを実現するための基本となるタスクが三次元物体検出です。三次元物体検出は、カメラ画像や点群データを元に、周囲のオブジェクトの三次元的な位置(x, y, z)、サイズ(width、length、height)、角度(row、pitch、yaw)を推定するタスクです。オブジェクトの移動速度や属性情報を同時に推定する場合もあります。検出対象は、自動運転向けの場合、車両、歩行者、障害物などになります。
End-to-End自動運転は、センサ入力からパスプランニングまでを一つの機械学習モデルで行う仕組みですが、三次元物体検出や、その結果を使ったモーション予測もその一部として組み込まれていることが多いです。三次元物体検出をEnd-to-End自動運転モデルのサブタスクに加えることで、プランニングの妥当性も向上することが期待されます。また、ブラックボックスになりがちな深層学習のモデルが世界をどのように認識しているかを出力させることで、モデルの挙動を解析することに役立ちます。
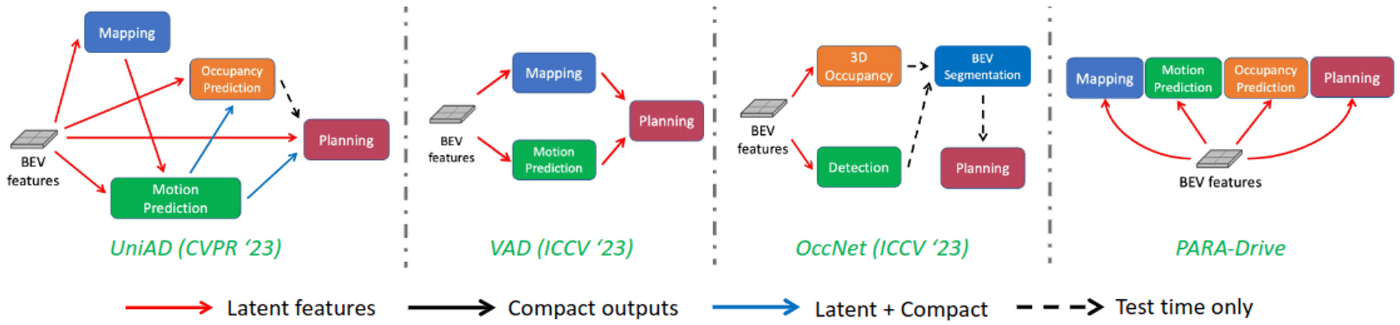
PARA-Drive: Parallelized Architecture for Real-time Autonomous Driving より。代表的なE2E自動運転モデルの概略図
自動運転の世界において三次元物体検出は当たり前のように行われており、三次元物体検出の認識結果をユーザインターフェースに表示することはエンドユーザの安心にも繋がります。E2Eモデルで走行していると言われているTeslaのFSDも、ナビ画面にリアルタイムで三次元物体検出の結果を表示させています。
3. 三次元物体検出の代表的な手法
三次元物体検出モデルは利用するセンサに応じて多種多様なものが提案されています。三次元物体検出の先駆けとなったモデル(VoxelNetなど)は、二次元の物体検出を単純に三次元に拡張したようなものでしたが、計算効率の観点からBEV(Bird-Eye-View; 鳥瞰図)状の特徴を利用するものが主流となりました。
LiDAR点群のみを利用したBEV特徴のモデルとしてはPointPillarsが有名です。PointPillarsについては以下の解説もご覧ください。
カメラ画像のみを利用する三次元物体検出手法でBEV特徴を利用するものとしては、BEVFormerが知られています。また、近年はVision Transformerベースの手法が発展してきています。Vision Transformerベースの物体検出手法については以下の解説をご覧ください。
LiDAR点群とカメラ画像の両方を利用するものとしては、BEVFusionがスタンダードです。BEVFusionはカメラとLiDARのデータそれぞれからBEVの特徴量を作成し、それらを結合したものを用いて最終的な予測を行うモデルです。
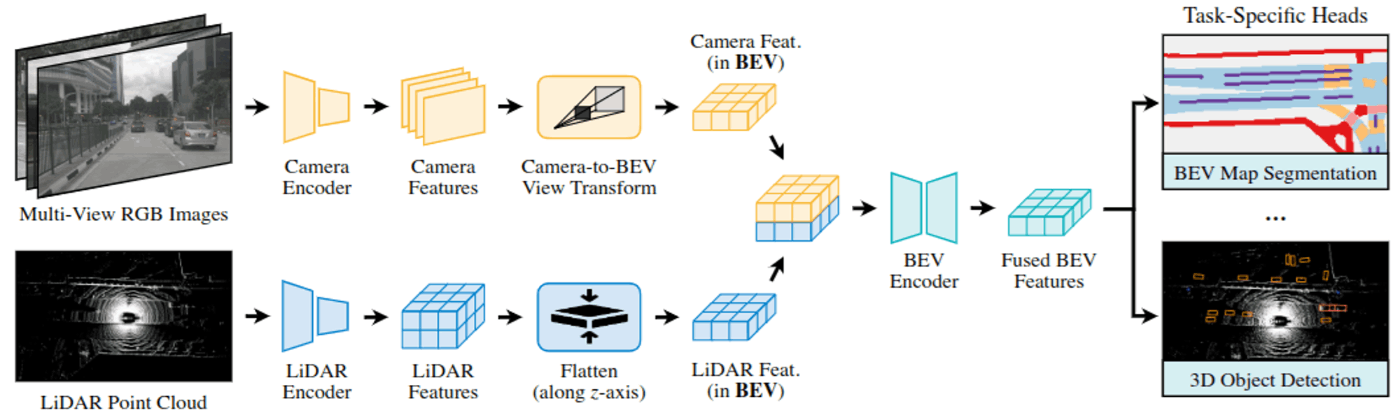
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation より。BEVFusionのアーキテクチャ図
4. E2Eチームでの取り組みについて
TuringのE2Eチームも三次元物体検出とモーション予測をサブタスクの一つとして取り入れることを検討しており、さらにそのトレーニングデータを作成するためのオートラベリングにも取り組んでいます。
4.1 オートラベリング
三次元物体検出のモデルを学習するためには、教師データとして三次元的なアノテーションが必要となります。Tokyo30プロジェクトでは数万時間の走行データを収集する予定となっており、その全てのデータに人手でアノテーションを行うことが現実的ではありません。そこで、一部の走行データに対するアノテーションから三次元物体検出モデルを学習し、他の走行データにはその三次元物体検出モデルの予測結果を教示データとして付与するオートラベリングを行います。
4.1.1 アノテーション
まずは一部の走行データに対して、人手のアノテーションを行います。Turingはデータ収集時にLiDARの点群データも取得しており、測定された距離に基づくアノテーションを可能にしています。アノテーションでは、三次元物体検出のためにオブジェクトの種類、位置、サイズ、角度をアノテーションします。また、インスタンスIDを付与し、動画の中でオブジェクトがどのように移動したかを確認できるようにしておきます。
アノテーションの作業は複数の作業者で分担して行います。作業者によってアノテーションの基準が異なることがないように、アノテーションガイドを作成しています。

Turingの走行データのアノテーション例
4.1.2 オートラベリング用のモデル学習
アノテーションデータが準備できたら、それを用いてオートラベリング用のモデルを学習します。
Turingはカメラのみを用いた自動運転モデルを開発していますが、オートラベリングの際にはカメラ画像とLiDARの両方のデータを利用できます。現在は、BEVFusionをベースとしたモデルを自社データで学習して利用しています。
オートラベリングの処理はオフラインで実行するため、リアルタイムで計算を行う必要はありません。大規模な計算機を利用し、速度より精度を重視した工夫を追加できます。例えば、走行データの動画において、予測を行いたいフレームの過去や未来の情報もモデルの入力に追加することで、より高精度なラベリングが可能になります。
モデルの学習が完了したら評価用のデータと、人手のアノテーションを付与していない走行データに対して物体検出の推論を行います。以下の画像はテストデータに対するオートラベリングの結果を可視化したものです。オレンジの枠は自動車、青の枠は歩行者を示していますが、昼・夜いずれの画像においても画像に映っているオブジェクトを検出することに成功しています。

新しい走行データに対するオートラベリングの結果
4.1.3 マルチオブジェクトトラッキング
自動運転モデルを学習する際にモーション予測を行うためには、オートラベリングの結果にもインスタンスIDを付与することが必要となります。動画の中で車両や歩行者がどのように動いたかを教示データとして付与することで、動きの予測を行う機械学習モデルを学習できます。現在はBEVFusionによる物体検出結果に対して後処理を行い、フレーム間でのオブジェクトトラッキングを行っています。オブジェクトトラッキングを行う際も人手でアノテーションした結果と比較して、精度評価を行います。

物体検出の結果を点、トラッキングの結果を線で示した例(左:人手によるアノテーション結果、右:トラッキングアルゴリズムによる推定結果)
4.2 自動運転モデルのサブタスクとしての学習
三次元物体検出とトラッキングによるオートラベリングが完了したら、自動運転モデルのサブタスクとして学習に利用します。Turingは自動運転モデルを学習する際は、カメラ画像のみを利用します。オートラベリングの結果は、人手によるアノテーションに比べると少し精度が劣りますが、大量の教示データを利用することが可能となります。オートラベリングの結果を利用してモデルを学習すると、人手でアノテーションしたデータのみを用いてモデルを学習するよりも、評価データに対する精度が向上します。
さらに、複数のタスクを同時に解くマルチタスクな自動運転モデルを学習する際、三次元物体検出のオートラベリングの結果を利用すると、マップ認識やパスプランニングなどの他のタスクの精度も向上することを確認しています。三次元物体検出のタスクが上達するということは、三次元的な空間認識能力が向上することを意味しており、それにより他のタスクを解く力も向上したと考えられます。
5. おわりに
End-to-End自動運転における三次元物体検出の位置付けと、E2Eチームでの取り組みについて簡単にご紹介しました。E2Eチームでは自社データを用いて三次元物体検出モデルを学習し、主要な交通オブジェクトの認識が可能となることを確認していますが、今後はさらなる精度向上を目指しています。そのためには三次元のコンピュータビジョンタスクを得意とする機械学習エンジニアを必要としています。
さらに、E2EチームはData-Centric AIを合言葉に、データセットの質的・量的改善にも取り組んでおり、センサデータの地道な前処理やデータパイプラインの構築もさらに発展させていく必要があると考えています。もしE2E自動運転の開発のために一肌脱ごうというソフトウェアエンジニアがいたら、筆者のメール (加藤:toshiyuki.kato@turing-motors.com) にご連絡いただくか、弊社の採用情報をご覧ください。カジュアル面談やオフィス見学などライトな交流も大歓迎です。

Discussion