
Turing株式会社のアドベントカレンダー2日目です!1日目はCTOの青木さんのカレー屋さんとスタートアップ:CTO of the year 2023でオーディエンス賞受賞です。
自動運転・AIモデル開発チームの岩政(@colum2131)です。
Turingは完全自動運転車の開発を目標としており、自動運転AIや車両、LLMの開発など様々なことに取り組んでいます。今回の話は、自動運転AIの物体認識などのPerceptionタスクにおいて個人的に面白いなと思ったVision-CentircなEnd-to-Endモデルの紹介です[1]。
Transformerベースの画像認識
Transformerは、大規模言語モデル(Large Language Model; LLM)などに用いられる重要なアーキテクチャです。2017年に"Attention Is All You Need"というタイトルで公開されて、言語処理をはじめ様々なドメインで汎用的に用いられるようになりました。
画像認識の分野でもTransformerが使われるようになりました。2020年の5月にTransformerを物体認識タスクに応用するDETRや、2020年の10月には画像分類タスクにおいてCNN構造を一切用いずにTransformerがメインの構造として記述可能なVision Transformer(ViT)が発表されました。それ以降、CNN以外の様々なTransformer構造が提案されて、画像分類以外に多くのタスクでState-of-The-Art(SoTA)を達成しました。
今回はTransformerの物体検出、特に自動運転の文脈における3次元物体検出モデルであるPETRv2について紹介します。
Transformerベースの2次元物体検出: DETR
特にこの物体認識をEnd-to-End(E2E)で行うDETRは、今回紹介するPETRにおいて強くインスピレーションを受けているため簡単に紹介します。
DETRのモデル構造は非常にシンプルで、
- ResNetなどのBackboneなどによって画像
I∈R^{H×W×3} F∈R^{H_F×W_F×C} - 特徴マップ
F PE∈R^{H_F×W_F×C} F'∈R^{(H_F⋅W_F)×C} - Transformer-encoderによって
F' N Q_{object}∈R^{N×C} - 最終的な物体クエリは全結合層によりクラス分類やBounding Boxの座標値が出力される
の通りです。イメージとしては、1と2の過程で画像から抽出される特徴量を言語トークンのように変換して、Transformer-encoderでそれらのトークンお互いの情報を共有し、Transformer-decoderで最終出力用のトークンにその情報を受け渡してトークン同士で再度情報を共有する流れです。
特徴的なのは言語モデルなどのTransformer-decoderであれば自己回帰的に処理されますが、計算コストが高い問題があります。そのため、DETRのTransformer-Decoderは一度に並列に処理されます。また、位置埋め込みや物体クエリは学習可能パラメータで、特に物体クエリはそれぞれ異なる値を持ちます。
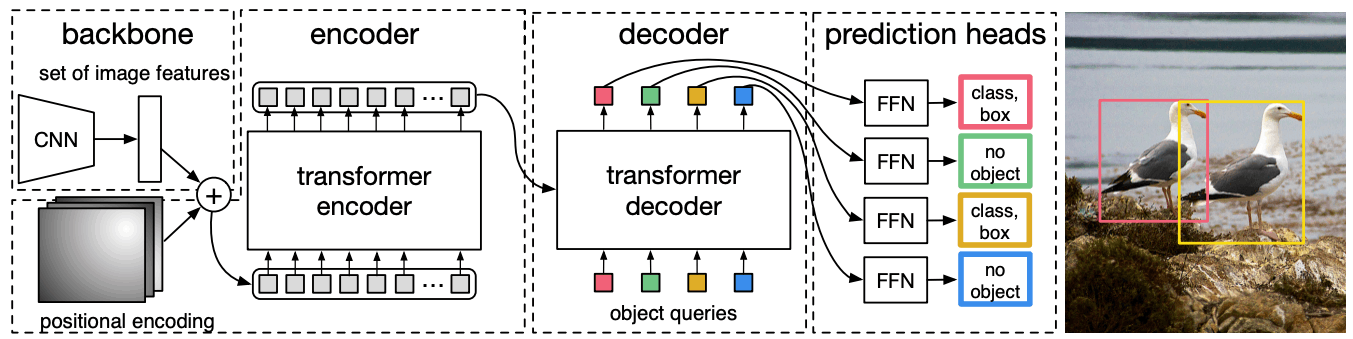
DETR[Carion+ 20]より引用
DETRの論文内でも比較的コードが簡易的に書けることを主張しています。といってもPyTorchのnn.TransformerというTransormerクラスが定義されており、このクラスを用いることでTransformer-encoder/decoderを簡易的に記述することができます。
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
DETRをベースとしたマルチカメラ3次元物体検出: DETR3D
このDETRを2次元物体検出からマルチカメラ3次元物体検出に拡張したのがDETR3Dです。
DETRは単一のカメラ画像を用いていました。単一カメラであれば、位置埋め込みを行うことで特徴マップ間内の位置の近さを与えることができますが、マルチカメラになると複雑になります。それぞれの画像の特徴量を抽出した後に、ある視点の特徴マップと別の視点の特徴マップに元の空間的な近さがあればその情報をうまく組み合わせて使いたいです。
DETR3Dはこの問題に対して、特にCross-Attentionを改良しました。物体クエリごとに3次元参照点を予測し、さらに各カメラパラメータから各画像(特徴マップ)ごとに相当する画像領域から画像特徴をサンプリングしました。これにより複数カメラであっても、3次元空間上で”近い”領域をうまく使うことができます。
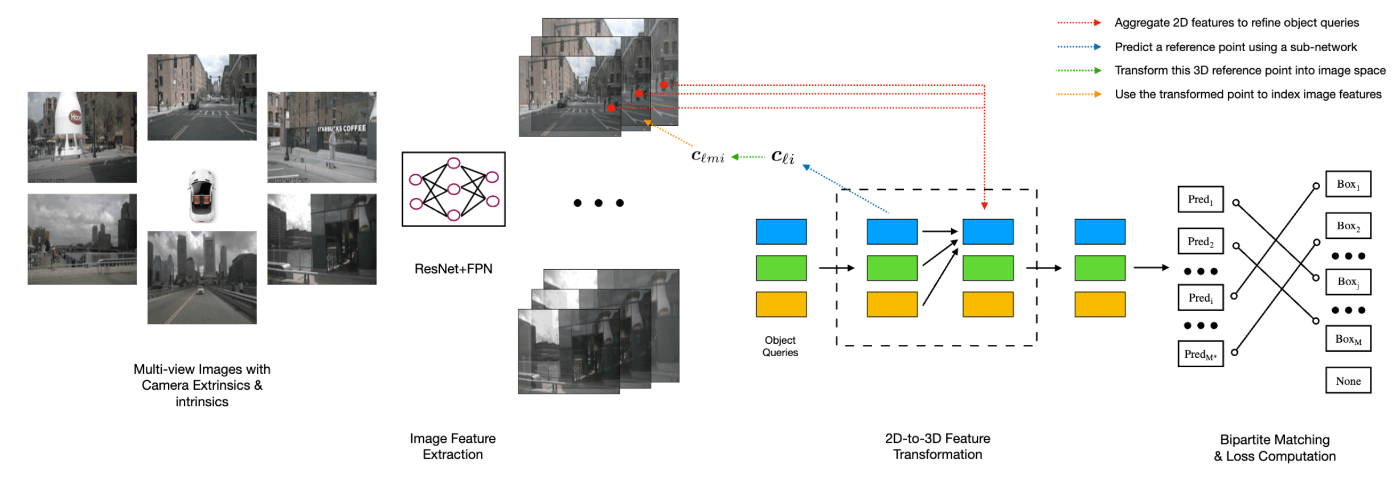
DETR3D[Wang+ 22]より引用
DETR3Dの欠点をシンプルに解決したマルチカメラ3次元物体検出: PETR
DETR3Dの欠点として、3次元参照点を正確に予測することができない、各カメラにおける画像特徴量をサンプリングするだけで他のカメラビューを統合した表現学習ができない、処理が複雑であることが挙げられます。
PETRは、DETR3Dの欠点をシンプルに解決します。というのも根本的な考え方は、特徴マップに対する位置埋め込みを2次元の位置埋め込みではなく3次元位置埋め込みとして行えば良い、といった考え方です。下の簡略図でもわかるように、**DETRとPETRの大きな差分は2D/3D PE(位置埋め込み)**しかありません。ではその位置埋め込みはどのように行うのか、以下で見ていきましょう。
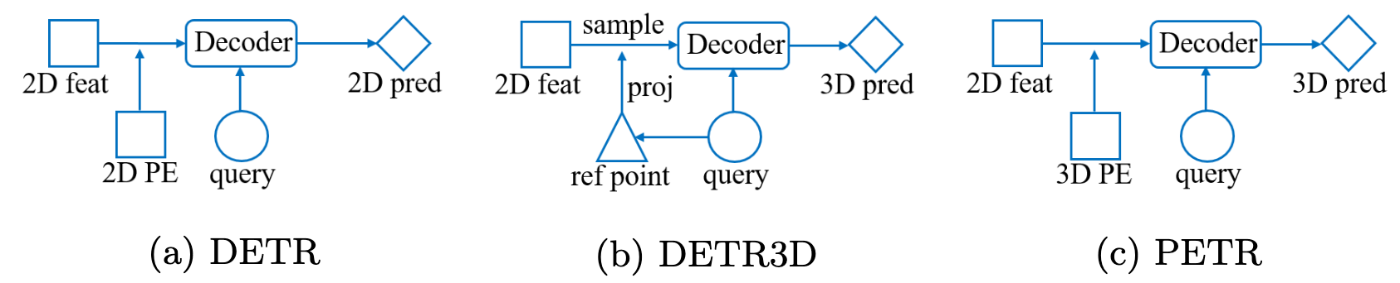
PETR[Liu+ 22]より引用
PETRの3次元位置埋め込みの考え方は、特徴マップの各2次元座標をカメラパラメータを用いて3次元座標に変換することです。
実装はシンプルです。まず特徴マップの深度方向
3次元座標の変換において、各カメラの内部パラメータ、外部パラメータからなる世界座標系から画像座標系への変換行列の逆行列
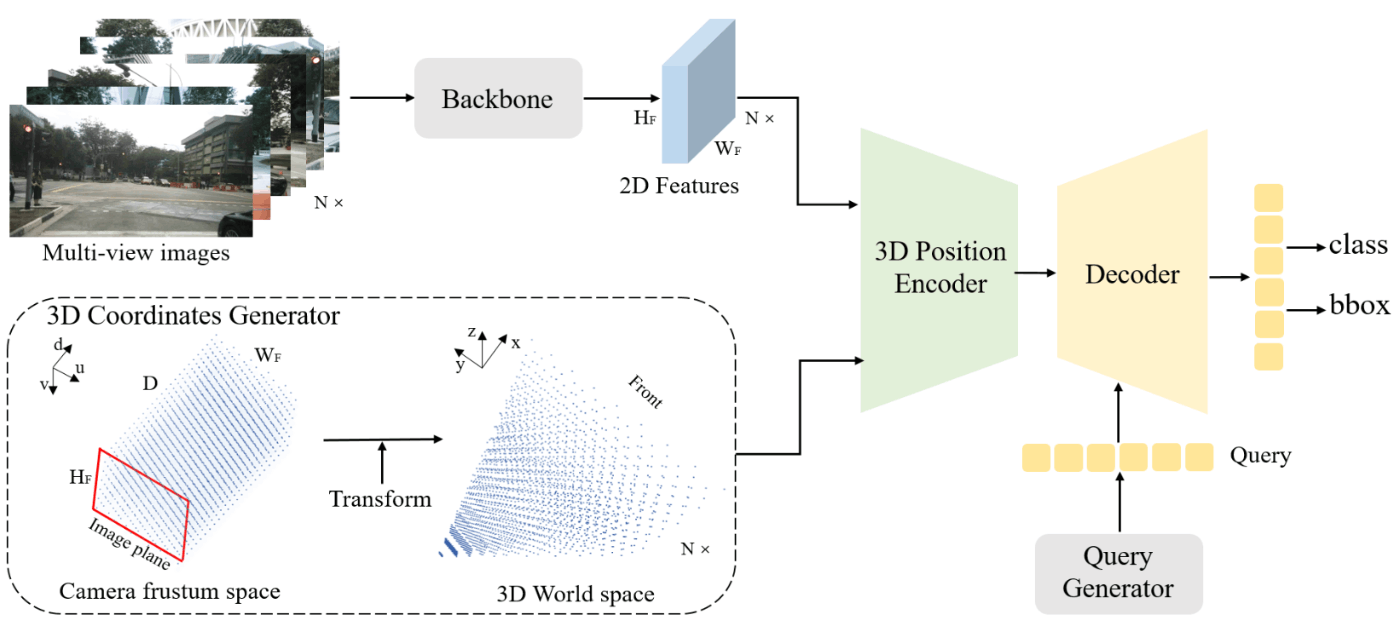
PETR[Liu+ 22]より引用
この3次元座標点はカメラ数Nとすると
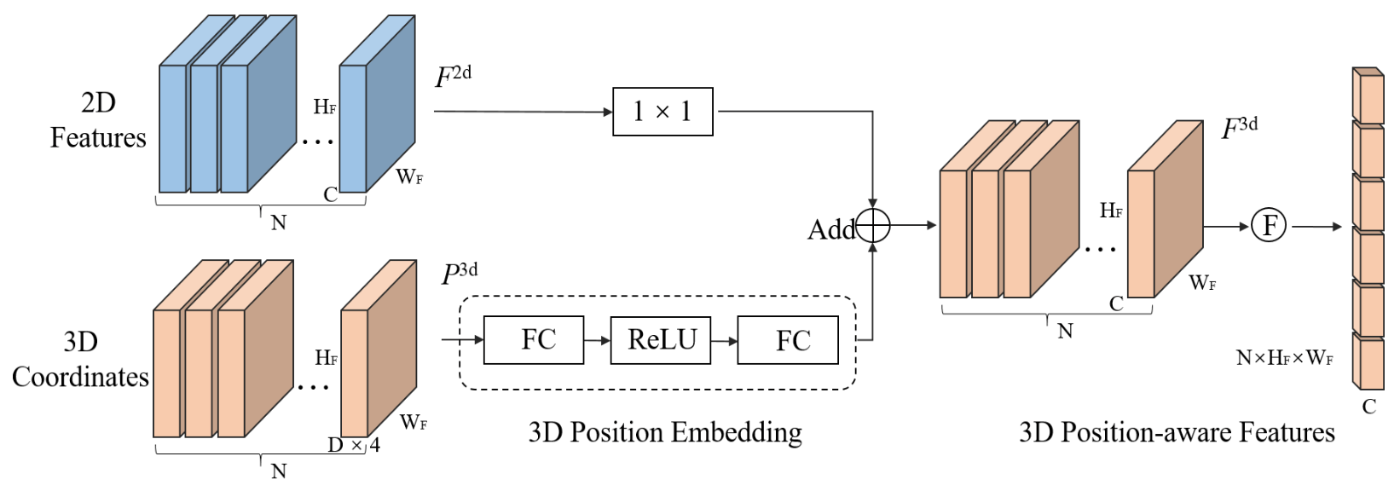
PETR[Liu+ 22]より引用
それ以降は物体クエリの生成においてDETRに対する改善はあるものの通常のTransformer構造と同等です。物体クエリは、はじめに学習可能なアンカーポイントとして最小値0、最大値1の一様分布から3次元点を生成して小さなMLPによって初期層の物体クエリとします。Transformer-encoder/decoderは通常の構造のまま用います。また、最終的な出力や損失関数は3次元物体検出に沿ったものが用いられます。
以上より、PETRはもとのDETRのコードにおけるposとself.query_posを変更するだけでモデルは実装できます。変更も比較的シンプルであるのも非常に嬉しい点です。公式実装もPETRとしてgithubに公開されています。位置埋め込みの実際の実装はこちらを参照してください。
時系列・深度情報をシンプルに導入したマルチカメラ3次元物体検出: PETRv2
PETRはシンプルな構造ながら、その性能としても当時の3次元物体検出モデルのFCOS3DやBEVDet、DETR3Dと同様の条件で比較しても高い性能を示しました。一方でPETRの課題点はまだ存在します。
PETRv2では、PETRの課題点の解決や精度の向上のため主に3つのことを取り組まれました。
- 時間モデリング: 過去フレームの画像特徴を”うまく”活用する
- 位置埋め込みと画像特徴の活用: 位置エンコーディングの際に画像特徴を用いることで暗黙的に画像から得られる深度等を位置埋め込みに与える
- マルチタスク: 3次元物体検出以外のレーン検出やBird’s-Eye-View(BEV)セグメンテーションなどのタスクを効率的に学習できるようにする
時間モデリング(Temporal Modeling)
PETRの1つ目の課題点として、時系列の情報を活用することができない点、そもそも時系列を考慮されていない点が挙げられます。
この問題に対してPETRv2は、時刻t-1で観測した世界は時刻tで自車が動いた時にはどこに存在するか、という考え方で、特に時刻t-1の画像特徴量のまま、それに対する位置埋め込みのみを自車の動きを伝えることで過去の情報を使うことができないか、という発想の転換のもと時間モデリングを行います。
具体的な処理は
イメージとしては、論文中のfigureにある通り、異なる時刻間でも位置埋め込みが指す先は同じであるといった感じです。

PETRv2[Liu+ 22]より引用
この時間モデリングを行うことで、時刻数
位置埋め込みと画像特徴の活用
PETRの3次元位置埋め込みはカメラパラメータに依存するだけで、画像情報を用いません。そのため想定する3次元位置と誤るケースがあり、例えば正面に車があったとしても、カメラ画像の下部がボンネットを写していたとしても、その深度情報をうまく活用することができません。
そこでPETRv2は、画像特徴から2層のMLPと最後のsigmoid層によって生成されるattention weightを3次元位置埋め込みの要素ごとに掛けることで、画像の特徴を汲み取った位置埋め込みを生成します。Transformer-encoderを通すことなく、そのままdecoder層に渡します。その際のvalueは位置埋め込みが加算されていない値で、keyは位置エンコーディングされた点で与えられます。このkey-valueの指定で、その後の処理で更新されるクエリは、3次元位置埋め込み情報が付与されない純粋な画像特徴を活用できる?ことを目的としているのかもしれません。

PETRv2[Liu+ 22]より引用
マルチタスク
PETRでは3次元物体検出のみを行なっていましたが、それ以外のタスクを効率的に学習するためにPETRv2では拡張します。
基本的な考え方として、クエリの初期化をより明示的なものにする、という点です。BEVセグメンテーションであれば、ランダムに位置埋め込みをしたBEVクエリではなく一定間隔に3次元のアンカーポイントを初期値としてシンプルなMLPによって効果的なBEVクエリとして生成されます。同様に、3次元レーン検出では、直進方向に対して一定間隔でポイントが打たれたアンカーレーンを定義して、そのアンカーレーンを初期値としてシンプルなMLPによって効果的なレーンクエリとして生成されます。その後の損失関数や実際のBEVセグメンテーションや3次元レーンの出力は論文を参照してください。
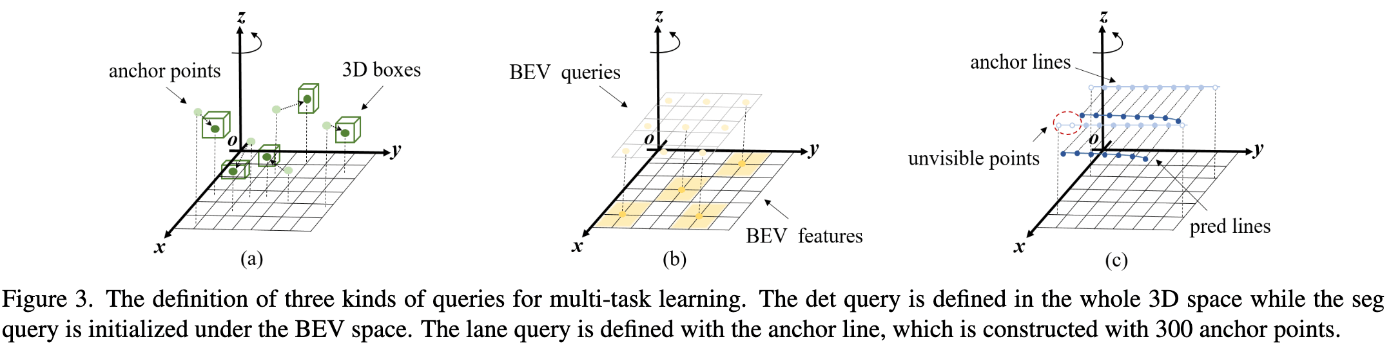
PETRv2[Liu+ 22]より引用
PETRv2のパフォーマンス
3次元物体検出およびBEVセグメンテーションをnuScenes、3次元レーン検出をOpenLaneを用いて評価されました。
まず3次元物体検出は、VoVNet(V2と表記)を用いたPETRv2が従来のPETRの性能を更新しました。特にPETRv2は時間モデリングを行なっているため、検出物体の速度誤差の指標であるmAVEがPETRに比べて0.808m/s→0.343m/sと大きく改善しました。

PETRv2[Liu+ 22]より引用
BEVセグメンテーションにおいても3次元レーン検出でも従来手法を上回りました。
特にレーン検出において、CVPR2023 Worksop CompetitionのOpenLane Topology Challengeにおいて、1st place solutionにて3D Lane DetectionでPETRv2を用いられました。複数のbackboneを試して、ViT-Lでepoch数を増やすことで大幅に精度が向上したことも興味深い点です。
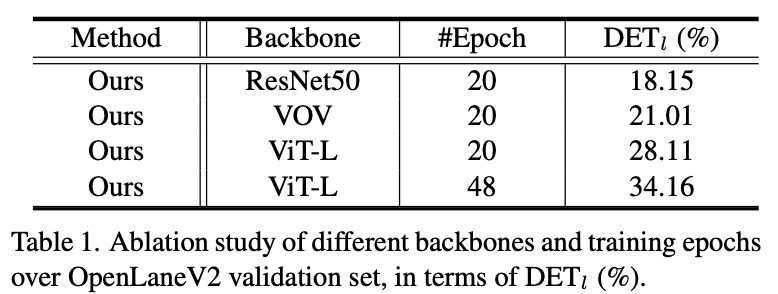
Wu+(2023)より引用
PETRv2の感想
PETRやPETRv2など、DETRベースでいわゆるPerceptionモデルを構築することは非常に興味深く、今後とも発展性のある手法だと思います。特に基本的なネットワークで記述できる点はとても嬉しいです。近年では、BEVFormerなど明示的にBEV空間を中間表現に持つモデル(Dense Query based Methods[2])が発展しているものの、比較的少ないクエリ数で3次元空間を表現できるPETRをはじめとするSparse Query based Methodsは計算コストを大きく軽減する可能性があります。Sparse Queryは明示的なBEV空間を持つことができない問題点はありますが、PETRv2が提案した時間モデリングやマルチタスク学習はその問題を解決する方法として大きく期待できます。
一方で、やはりSparse Queryはタスク特異的にしか解けないのでは、という疑問があります。UniAD[3]をはじめとして、BEV Encoderを先に学習してPredictionおよびPlanningを後段で学習する2段階の学習などの相性は非常に悪いように思えます。”いいBEV表現抽出機”としてのある意味backbone的な機能をSparse Queryで持たせることには、まだ発展の余地がありそうです。
より細かくいけば時間モデリングは現状の仕組みであれば静止物体に対しては効果的なものの動的物体をうまく捉えることができない問題があるように思います。後段のTransformer-decoderでその情報をうまく扱っているかもしれませんが、時間的な位置埋め込みを行うことや、同じ1次元シーケンス上に持たずに”いい感じに”時系列特徴を捉えられるようになればいいのかもしれません。また、ナイーブなTransformer構造であるため収束が遅いなど別途課題はありそうです(PETRでは言及されている)。
おわりに
この記事ではPETRv2について、その成り立ちからモデル構造について紹介しました。自動運転におけるVision-Centricな3次元物体検出もどんどん発展していき、手法として非常に興味深いモデルが毎日のように公開されています。
こういったVision-Centricなアプローチを車に乗せるには実際に学習して、評価して、実機でどのように動作するか、を検証する必要があります。データ収集から学習、評価、車へのデプロイを回すパイプラインを一緒に構築する仲間を募集しています!興味がある方はぜひ採用情報もご覧ください!
参考文献
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020, August). End-to-end object detection with transformers. In European conference on computer vision (pp. 213-229). Cham: Springer International Publishing.
- Wang, Y., Guizilini, V. C., Zhang, T., Wang, Y., Zhao, H., & Solomon, J. (2022, January). Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In Conference on Robot Learning (pp. 180-191). PMLR.
- Liu, Y., Wang, T., Zhang, X., & Sun, J. (2022, October). Petr: Position embedding transformation for multi-view 3d object detection. In European Conference on Computer Vision (pp. 531-548). Cham: Springer Nature Switzerland.
- Liu, Y., Yan, J., Jia, F., Li, S., Gao, A., Wang, T., & Zhang, X. (2023). Petrv2: A unified framework for 3d perception from multi-camera images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 3262-3272).
- Caesar, H., Bankiti, V., Lang, A. H., Vora, S., Liong, V. E., Xu, Q., ... & Beijbom, O. (2020). nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 11621-11631).
- Chen, L., Sima, C., Li, Y., Zheng, Z., Xu, J., Geng, X., ... & Yan, J. (2022, October). Persformer: 3d lane detection via perspective transformer and the openlane benchmark. In European Conference on Computer Vision (pp. 550-567). Cham: Springer Nature Switzerland.
- Wu, D., Jia, F., Chang, J., Li, Z., Sun, J., Han, C., ... & Wang, T. (2023). The 1st-place Solution for CVPR 2023 OpenLane Topology in Autonomous Driving Challenge. arXiv preprint arXiv:2306.09590.
-
近年の自動運転におけるVisionベースのEnd-to-Endモデルについては@abemii_
さんの[CV勉強会@関東 ICCV2023]ビジョンベースの End-to-End 自動運転に向けたシーン表現が参考になります ↩︎ -
Dense/Sparse Query based Methodsという用語はDelving into the Devils of Bird’s-eye-view
Perception: A Review, Evaluation and Recipe[Liu+ 22]にならって用いています ↩︎ -
UniADの日本語資料としては弊社エンジニアの方の[CV勉強会@関東 CVPR2023] UniAD: Planning-oriented Autonomous Drivingが参考になります ↩︎

Discussion