はじめに
こんにちは、End-to-End自動運転開発チーム(以降E2Eチーム)で自動運転システムを開発している堀ノ内と塩塚です。本記事はE2Eチームの取り組みを知ってもらう連載企画の第二弾として、End-to-end自動運転におけるマップ認識のあり方と、実際のTuringの開発状況についてお話します。
Turingでは2025年までに東京の複雑な道路を30分以上介入なしで運転できるようなE2E自動運転システムを開発する「Tokyo30」というプロジェクトに取り組んでいます。
私達が目指すE2E自動運転の基本概念については連載企画第1回の以下の記事を参照ください。
End-to-end自動運転におけるマップ認識
E2E自動運転モデルのメインの仕事は、自己車両がどのような経路で進むべきか(Path Planning)を決めることですが、これを賢く行うには、周囲の物体を検出(3次元物体検出)したり、周りの道路がどのように構成されているかを認識(マップ認識)したりすることが重要であると考えています。
End-to-end自動運転では、従来のシステムのように緻密に設計された無数のソフトウェアモジュールが複雑に連動して動くのではなく、全ての判断を機械学習モデルに委ねるため、この機械学習モデルをいかに賢く作るかというところに全てがかかっています。
End-to-endな自動運転で近年大きく注目を浴びたのは、CVPR2023でBest Paper Awardを受賞したUniAD [Yihan Hu+, CVPR2023] です。この手法は、これまでPerception (マップ認識もここに該当)したものを使って下流のPredictionやPlanningを行うようなモジュールベースの従来手法に比べ、それぞれのタスクで相互作用できるようなアイディアを提案し、nuScenesデータセットを使った評価で多くの項目において従来手法を上回りました。マップ推論の結果はTransformerのKey, ValueとしてPlanningなどのタスクに活用されます。
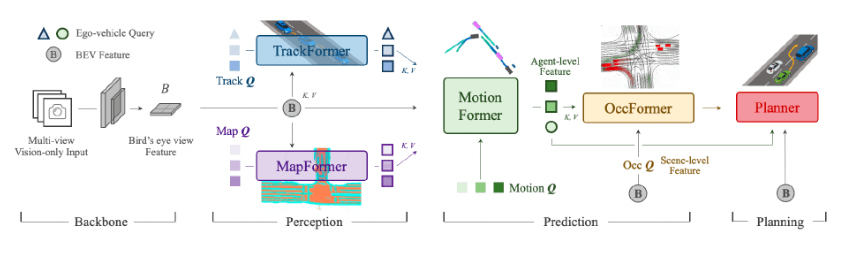
UniADのデザイン図:論文より引用
また、CVPR2024年に採択されているNVIDIAが提案したPARA-Drive [Xinshuo Weng+, CVPR2024] では、明示的にPlanningにマップ認識の結果を伝えなくても、中間表現を共有することでマップ認識などのサブタスクの結果をPlanningに伝えることが可能だと報告されています。この手法は、推論時はPlanningのヘッドのみを有効化することでモデルの軽量化が行えることや、モデル構造全体のシンプル化など多くの利点があります。
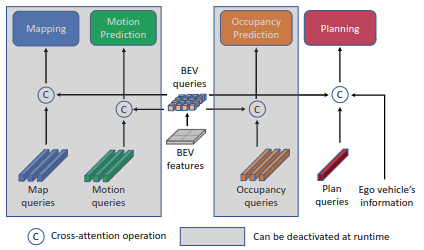
Para-Driveのアーキテクチャ図:論文より引用
研究分野だけでなく、E2Eモデルで走行していると言われているTesla FSD v12もマップ認識を行っており、以下の動画にあるように走行中にリアルタイムで白線などの道路情報を推論させています。
これらの代表的な研究や事例でも言及されるように、Path Planingを賢く行うために周囲の状況を認識させることは有効的な手段です。
E2Eチームでの取り組みについて
先の事例と同様、私達E2Eチームでもマップ推論を自動運転モデルのサブタスクとして学習させています。
データ作成
モデルの学習には学習データが必要です。マップの学習に使用可能なデータセットには、nuScenesやArgoverse2などがありますが、それらのデータで学習したモデルをTuringの自動運転車両上でそのまま使用することは難しいです。理由としては、カメラなどのセンサ条件の違い、外国と日本のドメインギャップ、権利の問題などが挙げられます。どの理由もクリティカルですが、そもそも道路は国ごとに異なるので海外のデータで学習したモデルを日本で使用することは困難です。そのため私達自身で、学習に必要なデータを集めてマップの教師データを作成する必要があります。
データ収集
Turingでは「Tokyo30」に向けて、走行データを東京中で日夜取得しています。そのデータ収集車両には、8台のカメラやLiDAR、GNSSなどを搭載しています。
現在数千時間程度のデータを収集しており、2025年末までに数万時間の走行データを取得予定です。
マップアノテーション作成
取得したカメラ、LiDAR、GNSSなどの情報をもとに、東京のマップアノテーションを作成しています。ここでいうマップアノテーションはレベル4自動運転で用いられるようなHDmapと比べると、白線や走行可能エリア、横断歩道、レーントポロジーなどで構成された比較的軽量なものになっています。東京の様々な場所のマップを作成し、機械学習モデルに学習させています。
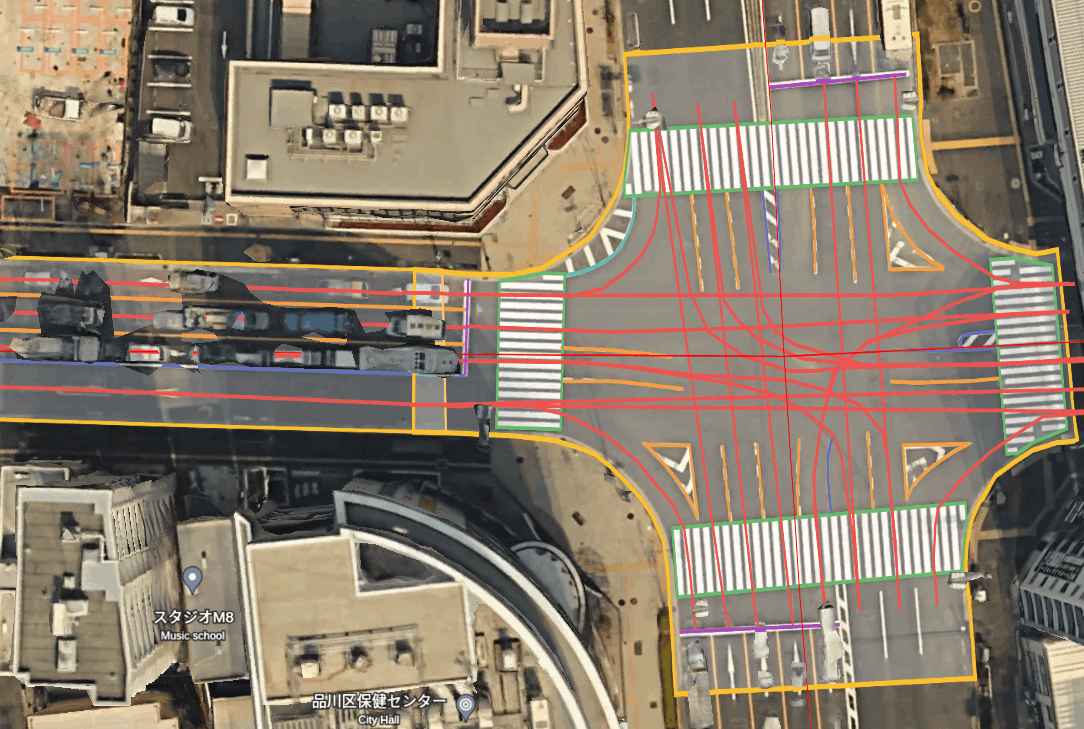
マップアノテーションのイメージ
学習・可視化可能な形への座標変換
アノテーションデータは緯度経度などの世界座標系で作成しています。それらを座標変換して、モデルの学習時は自分から見た相対座標系で与えたり、カメラ画像にオーバーレイして教師データや学習結果を可視化したりしています。
ここでは、どのようにアノテーションデータを学習データに変換したり、可視化用に座標変換しているのか説明します。
世界座標から相対座標への変換 (学習用)
前述の通り、我々が学習してる機械学習モデルは自分を中心に白線や走行可能エリアなどを認識します。そのため、世界座標系でアノテーションされた教師データを相対座標系に変換します。
これには、自己位置推定の結果を用います。世界座標系での自己(車の基準点)の位置と回転をマップアノテーションに反映することで変換可能です。変換後、モデルの学習データとして使う際は適当な範囲をクリップして使っています。(例えば前後左右50mなど)
# world_map_annotation : マップアノテーションの世界座標
# world_to_ego_position : 自己の世界座標での位置
# world_to_ego_rotation : 自己の世界座標での回転
# ego_relative_map_annotation : マップアノテーションの自己に対する相対座標
ego_relative_map_annotation =
world_to_ego_rotation * (world_map_annotation - world_to_ego_position)
# map_train_label : 学習に使うマップアノテーション
map_train_Label = clip(ego_relative_map_annotation)
相対座標から画像座標への変換 (可視化用)
モデルの学習観点だけ見ると相対座標への変換で十分なのですが、カメラ画像に合わせて確認することは学習データの妥当性の観点で重要です。画像座標への変換は、カメラと自己(車の基準点)の位置や回転の関係と、カメラの内部パラメータを用いることでできます。
まず、カメラと自己の関係から、マップをカメラ基準の相対座標に移します。
# ego_relative_map_annotation : マップアノテーションの自己に対する相対座標
# ego_to_cam_transtation : カメラの自己に対する位置
# ego_to_cam_rotation : カメラの自己に対する回転
# cam_relative_map_annotation : マップアノテーションのカメラに対する相対座標
cam_relative_map_annotation =
ego_to_cam_rotation * (ego_relative_map_annotation - ego_to_cam_transtation)
その後カメラの内部パラメータを使って、画像座標に変換します。
# cam_relative_map_annotation : マップアノテーションのカメラに対する相対座標
# intrinsic_matrix : カメラの内部パラメータ
# image_map_annotation : マップアノテーションの画像座標
image_map_annotation = intrinsic_matrix * cam_relative_map_annotation
座標変換の結果、画像にマップアノテーションをオーバーレイすることができ、正しく学習データが作成できているか確認することができます。

画像にオーバーレイした結果のサンプル
モデル学習
学習時では大きく2段階に分けて検証を行っています。マップ推論用モデルでの学習と、自動運転モデルのサブタスクとしての学習です。
マップ推論用モデルでの学習
先行事例で紹介したUniADやPARA-Driveのような自動運転モデルで学習する前に、まずマップ推論のみをターゲットにしたモデルを学習します。この段階では、モデルの性能を重要視するのではなく、モデルをある程度固定することで私達が作成したデータセットが正しく作られているか、学習データロード用のツールキットが想定通りの挙動をしているかなどを確認します。この検証では、MapTR [Bencheng Liao+, ICLR2024] やStreamMapNet [Tianyuan Yuan+, WACV2024] のようなマップ推論用のモデルを参考にしています。
このようなカメラ画像を用いたマップ推論技術は2020年代に入った頃より盛んに研究され始め、特にBevformer [Zhiqi Li+, ECCV2022] などのTransformerベースのモデルが高い能力を発揮したことで注目を集めることになりました。今年開催されたComputer Vision系のトップカンファレンスであるCVPR2024でも、MGMap [Xiaolu Liu+, CVPR2024] やMapUncertaintyPrediction [Xunjiang Gu+, CVPR2024] などが採択されており最先端で研究が進められている技術であることが分かります。
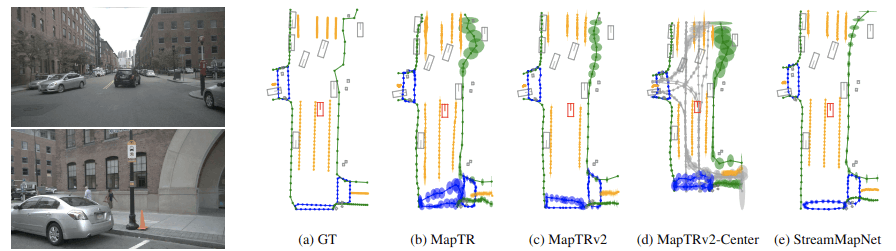
Producing and Leveraging Online Map Uncertainty in Trajectory Prediction より。代表的なマップ推論モデルの推論結果とその信頼度を可視化したもの。
自動運転モデルのサブタスクとしての学習
マップ推論用モデルでの検証ができたら、自動運転モデルに組み込んで学習します。ここでは、サブタスクとして学習したマップ推論がどのようにメインタスクのPath Planningや他サブタスクの物体検出などに影響を与えているかを検証します。
我々が学習している自動運転モデルはUniADやPARA-Driveなどと同様に、BEV-featureと呼ばれる中間表現を各タスクで共有しています。そのため、よいサブタスクを学習させることで、よい中間表現を獲得でき、最終的にPath Planningの向上が期待されます。実際に、あるサブタスクの向上が他のタスクにいい影響を与えることが確認できています。
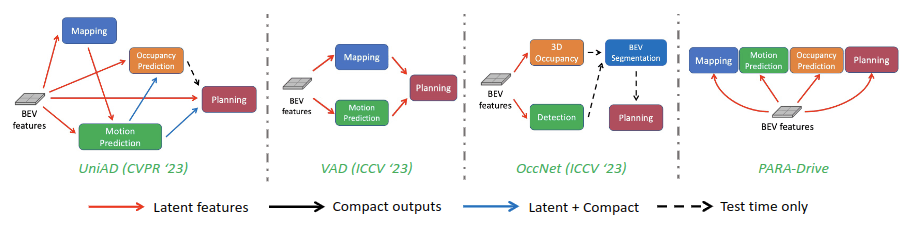
PARA-Drive: Parallelized Architecture for Real-time Autonomous Driving より。代表的なE2E自動運転モデルの概略図
おわりに
End-to-end自動運転チームでは「Tokyo30」の実現に向けて、データ収集からデータインフラ構築、アノテーション作成、モデル学習、デプロイと一気通貫の開発を行っています。これらを行うには、機械学習エンジニアに加え、クラウドなどのインフラエンジニアやデータパイプラインなどを整えるソフトウェアエンジニアが不可欠です。もし興味を持っていただけたら筆者らのメール (堀ノ内:tsukasa.horinouchi@turing-motors.com) やX (塩塚:https://x.com/shiboutyoshoku) にご連絡いただくか、弊社の採用情報をご覧ください。カジュアル面談やオフィス見学などライトな交流も大歓迎です。

Discussion