はじめに
Turing の End-to-End(E2E) 自動運転チームでチームマネージャをやっている棚橋です。今回はE2E自動運転チームでブログの連載企画を行います。本連載企画ではEnd-to-End(E2E)自動運転の最新技術やTuringの取り組みを紹介します。第一回はTuringで取り組んでいるE2E自動運転の概要と課題について取り上げます。
End-to-end自動運転とは?
Turing が取り組んでいる自動運転の方式はE2E方式と呼ばれるもので、従来の自動運転の仕組みとは大きく異なっています。従来のシステムでは、緻密に設計された無数のソフトウェアモジュールが複雑に連動して動く仕組みですが、E2E方式では全ての判断をMLモデルに委ねるため、MLモデルの開発とそのデータ作りが主戦場です。
技術が違うということは必要な技術も人材も大きく異なります。MLエンジニアだけでなく、大規模データ処理パイプラインを構築するためのデータ基盤エンジニアが非常に重要な役割を果たします。また、クリーンなデータを収集するために、センサーデータのキャリブレーションやカメラの動画データの扱いも非常に重要となります。
E2E自動運転ではブラックボックスなMLモデルの判断で運転を行うことになるため、安全性や説明性の問題が存在します。この理由から、特に大手の自動車会社ではあまり受け入れられてこなかったという経緯があります。一方で、昨年公開されたE2E自動運転モデルのTeslaのFSD v12がほぼ人間レベルの運転レベルを実現したり、中国のメーカーもそれに続いて完成度の高いE2E自動運転を開発していることから、最近ではE2E自動運転への注目が集まりつつあります。
従来の自動運転の方式は小さいモジュールを大量に集めて繋げることで動く複雑なシステムです。

E2E自動運転では、カメラ画像(または動画)を入力として、車の経路を出力する単一のモデルを作成します。

TuringにおけるE2E自動運転の開発
Turingでは2025年までに東京の複雑な道路を30分以上介入なしで運転できるようなE2E自動運転モデルを開発する「Tokyo30」というプロジェクトに取り組んでいます。
E2E自動運転ではMLモデルが主役であると冒頭で述べましたが、特にデータをどのように作るかが非常に重要なプロセスとなります。近年、データの品質を改善することでMLモデルの精度改善を行う「データセントリックAI」という考え方が注目されていますが、E2E自動運転においても高品質なデータ(量・質・多様性)を集めることが重要であると考えています。
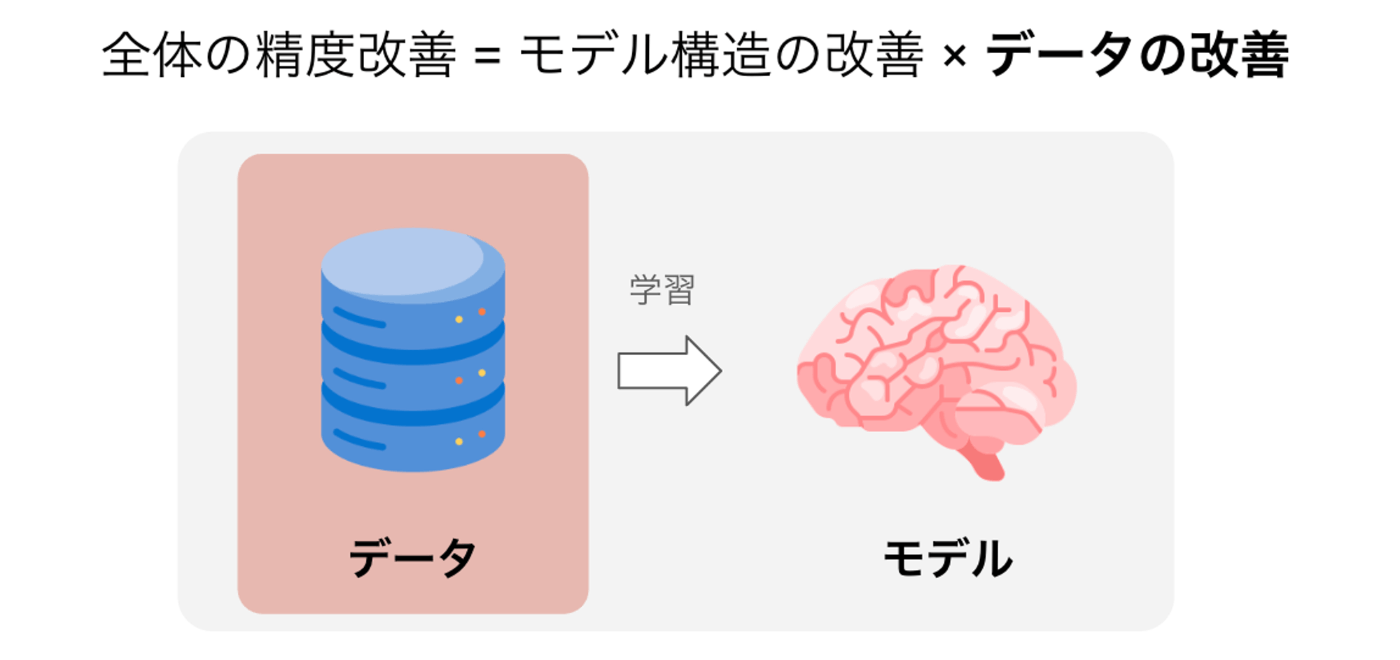
Turingでは高品質なデータを作成するための仕組みとしてMLOps基盤を構築しています。これはMLモデルを作るための工場のような存在であり、良質な車が良質な工場から作られるのと同様に、良い自動運転モデルは良いMLOps基盤から作られると考えています。
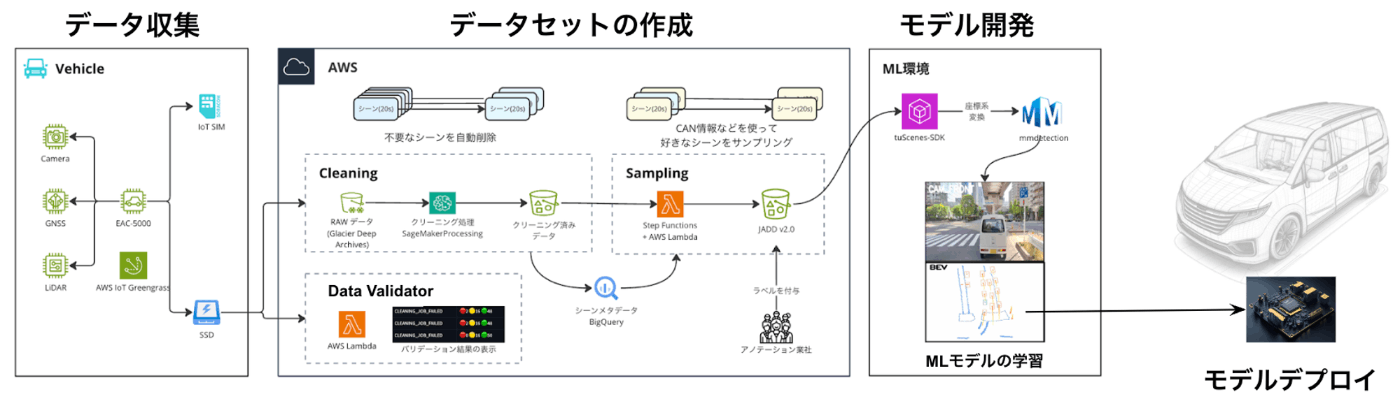
以下の図は私たちが構築したMLOps基盤の全体像で、データ収集車の開発、データ収集オペレーション、Cloudでのデータパイプライン、センサーキャリブレーション、オートラベリング基盤、データセットSDK、GPUクラスタ上での大規模モデル学習、エッジデバイスでモデルを動かすためのモデルデプロイなど、多くの要素から構成されています。
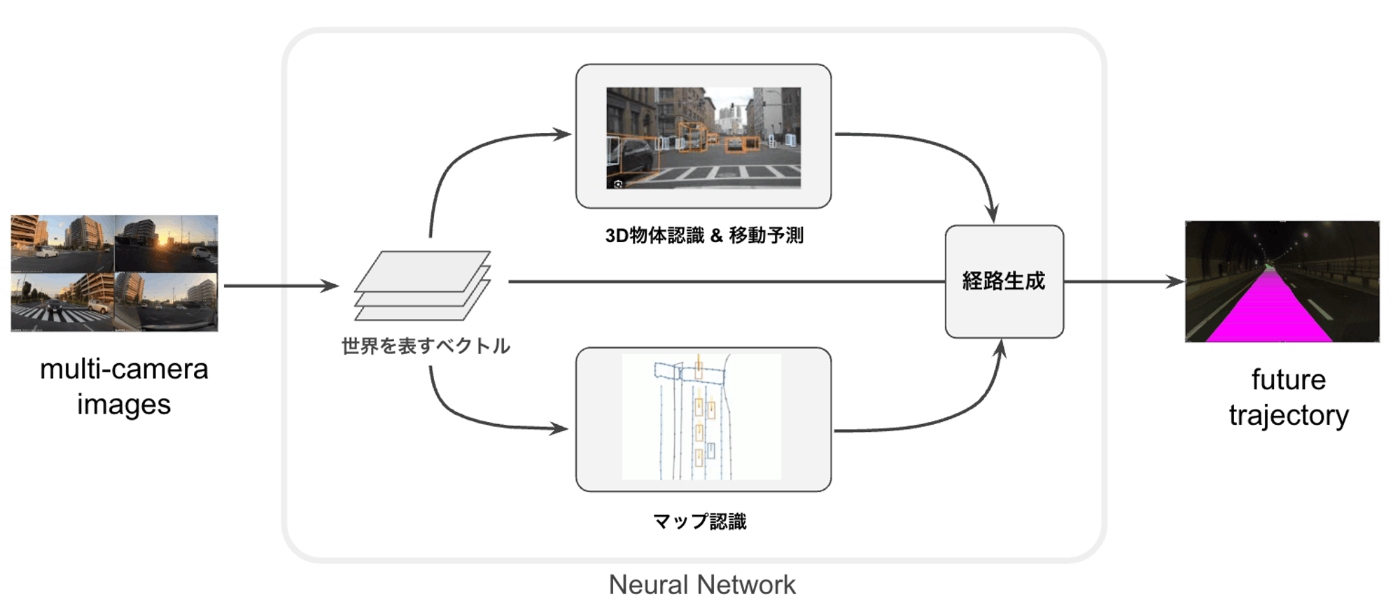
モデル開発
我々の開発しているモデルはマルチカメラの入力に対してマップ認識や3次元物体認識など様々なサブタスクを行い、Bird’s Eye View (BEV)特徴と呼ばれる特徴量を共通の特徴として獲得します。この特徴を用いて未来の自車の経路を出力し自動運転を行います。モデル開発の詳細は後ほど本連載の記事で紹介していく予定です。
E2E自動運転の学習方法
行動クローニング
自動運転においてどのように学習をしたら最適な運転ができるのかを考えます。強化学習の文脈でこの問題を定義すると、長期的な報酬(reward)を最大化するような運転方策(policy)を獲得することとなりますが、運転において報酬とは何かが自明ではないため、適切に報酬を定義する必要があります。この問題を解決するための一つの方法が模倣学習です。模倣学習には、行動クローニング(Behavioral Cloning; BC)や逆強化学習などがあります。
E2E自動運転の学習では行動クローニングがよく使われています。これは、以下の図において予測した経路(下図の赤線)と実際の運転データ(下図の青線)の経路の差分が小さくなるように学習する方法です。行動クローニングの利点は実際の走行データに対する教師あり学習として定式化することができるという点で、強化学習などと比較して実装や計算が容易で、大規模なデータにスケールさせることができます。
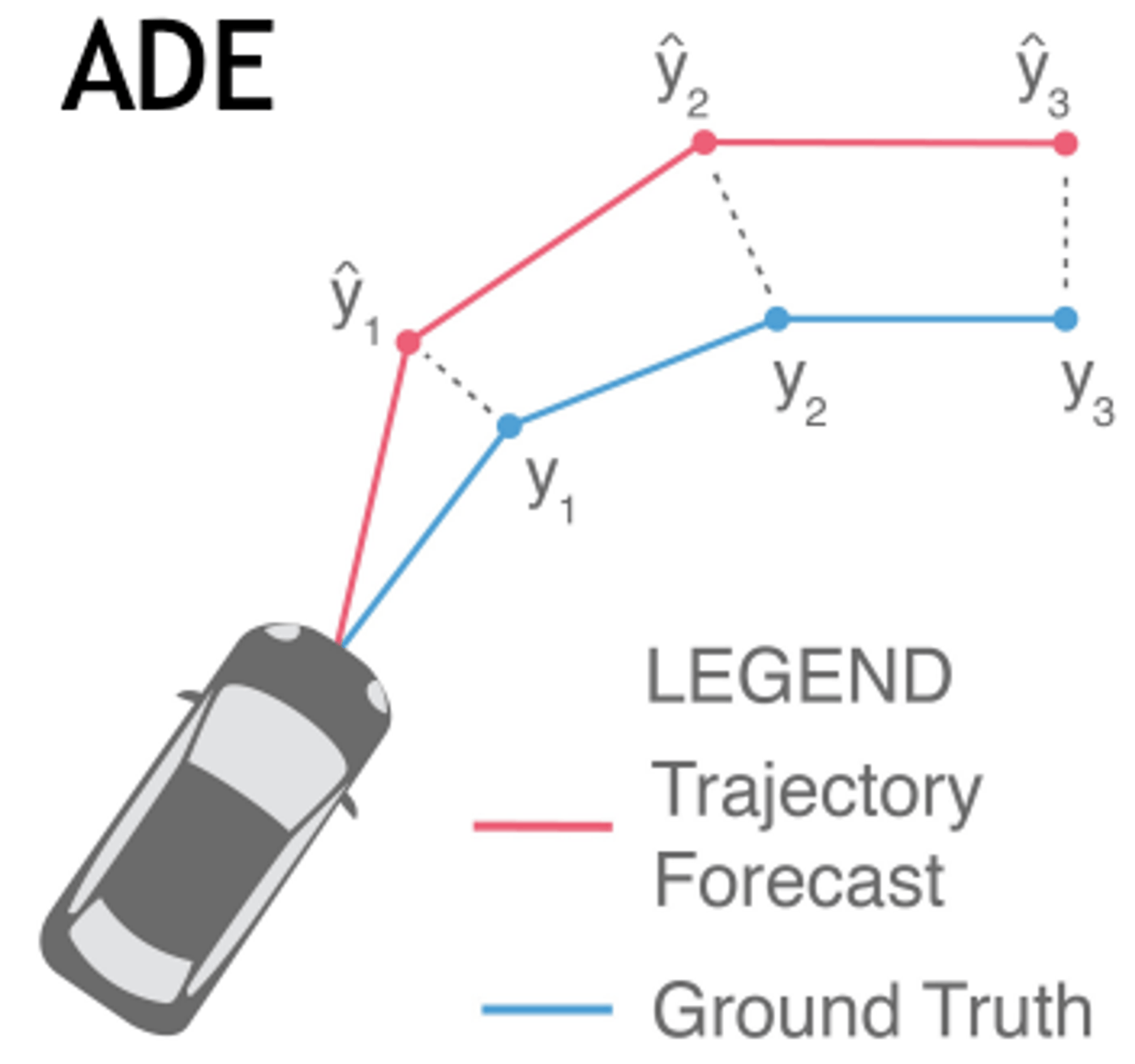
https://research.nvidia.com/labs/avg/publication/ivanovic.pavone.arxiv2021/
具体的には、以下のような損失関数の最小化問題としてパラメータの更新を行います。ここでLがADEのようなパスの誤差で、
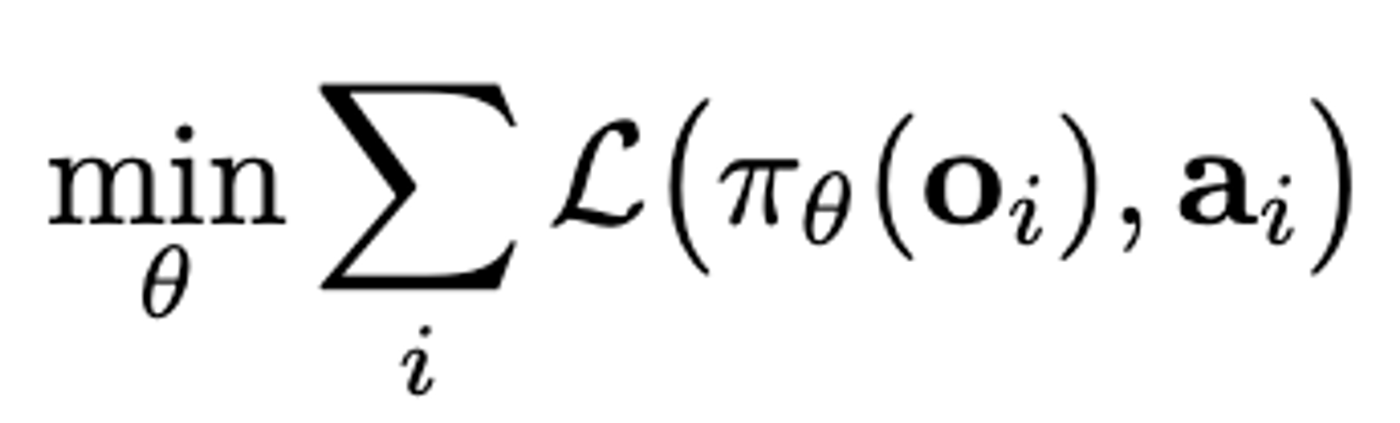
E2E自動運転の課題
共変量シフト問題
行動クローニングでは状態sとその時の行動aのペア
誤差が蓄積すると、学習データに含まれない状態(道路から大きくはみ出る等)に陥ってしまった時に、学習データに存在しない状態となるため、元の状態に戻る動作ができなくなるという問題が生じます。以下の図ではお手本となる線から外れて復元できずに壁にぶつかっています。

https://web.archive.org/web/20200219053949/https://web.stanford.edu/class/cs234/slides/lecture7.pdf
解決方法1: データ拡張
画像を歪ませる
単純に収集したデータで学習を行なっても車がまっすぐ走らないという行動クローニングに関する話がcommaのブログで取り上げられており、対策として横制御に関しては画像を歪ませるシミュレータを用いて擬似的に横にズレた状態を再現し元々走行していたラインに戻るような行動を学習しています。しかしこの方法は画像を歪ませることによって人工的なartifactが入ってしまうという新しい問題を生んでしまいます。そこで、KL-divergenceを損失関数として導入し、特長空間において歪んだ画像と元の画像の分布が近くなるようにしてこの問題を解決しています。

参考資料: commaのブログ
NeRFやGaussian Splattingを使う
イギリスの自動運転AIスタートアップのWayveではGhost GymというNeRFを用いたシミュレーションシステムを構築しています。過去数年間、データ収集用に走行した車両のデータを用いてロンドンの街をNeRFによって3次元再構築可能にしています。NeRFを使うことで、視点位置をずらした場合の視点からの画像をレンダリングすることができるため、実際に走行した位置からずれた場所から元の走行ラインに戻る時の画像とトラジェクトリを学習データに含めて、モデルに復元する能力を持たせる学習を行っています。
参考資料: wayveの発表動画

カメラを複数取り付ける
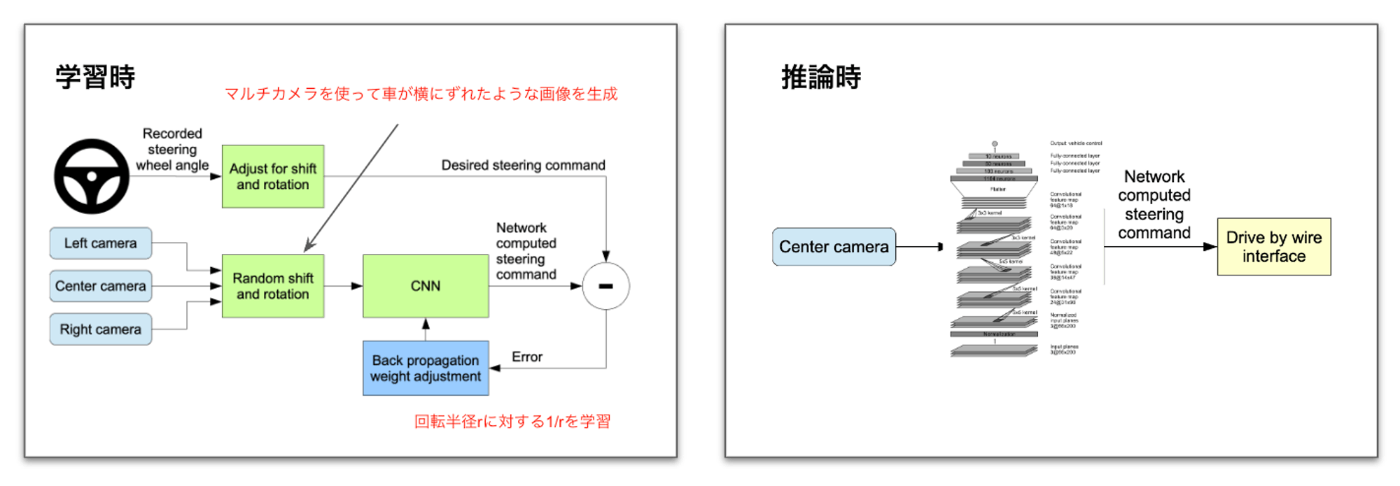
NVIDIAのE2E自動運転のプロジェクトの一つにDAVE-2というものがあり、DAVE-2では面白い方法で行動模倣の問題を解決しています。DAVE-2はCNN(畳み込みニューラルネット)をNVIDIAの車載用デバイス(DrivePX)で動作させて、フロントカメラのみを用いてステアリングの制御を行っています。データ収集の際にはフロントカメラに加えて、左右に配置したカメラの映像を取得し、学習時に左右カメラの画像を用いて、道からズレたシーンを擬似的に表現して道の中央に復元するようなパスの学習を行なっています。DAVE-2ではこのような方法で72時間の学習データを用いて10マイル手放しで自動運転ができたと報告しています。
解決方法2: 強化学習
Waymoの研究「Imitation Is Not Enough: Robustifying Imitation with Reinforcement Learning for Challenging Driving Scenarios」では、多くの学習データが存在するような通常の状況では行動クローニングが機能するが、レアな状況では正しく運転できなくなることが指摘されています。
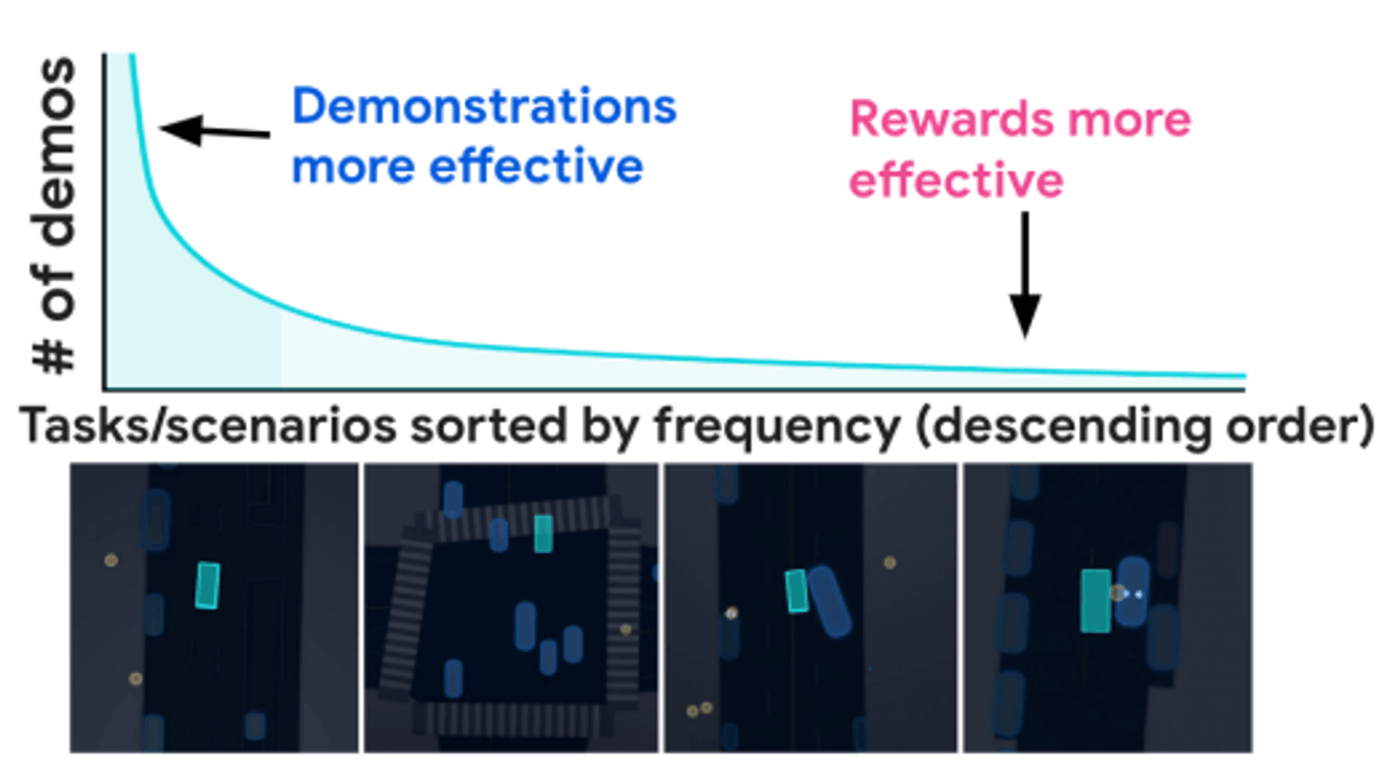
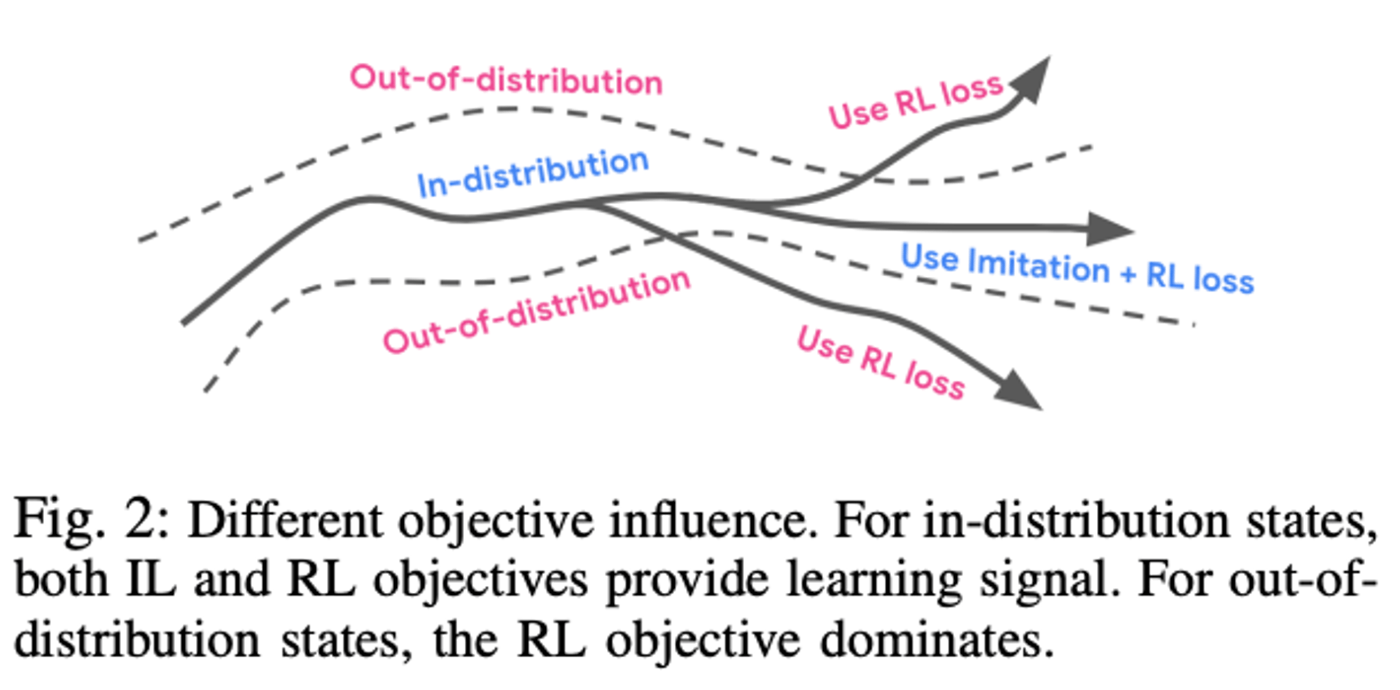
レアな状況では強化学習がより有効であることから、提案手法ではレアな状況と通常の状況のシーンを区別して扱い、通常の状況(下図の青字の線)では教師あり学習(BC)と強化学習を用い、レアな状況(下図の赤字の線)では強化学習を用いるという戦略を取ることで、難しい状況でも正しく運転できるようになったと報告されています。
実際にベースライン(下図の左)と提案手法(下図の右)を比較すると、提案手法では出てきた車に対してうまく対処できていることが確認できる。Waymoはこの方法で100kマイルのデータを使った学習を行ない、実際の走行データと強化学習を組み合わせた方法としては最も大規模な学習を行なったと主張しています。

Causal Confusionの問題
行動クローニングの別の問題として、causal confusionの問題があります。例えば、赤信号になるとブレーキをかけることを学習してほしいのに、モデルは間違えて自車のスピードが減速している時にブレーキをかけるであったり、周りの車が減速している時に止まるという間違った因果関係を学習してしまうことがあります。この問題を解決するには因果グラフを構築するなどの対処法が提案されていますが複雑な処理を要します。
この問題に対して、Wayveの実証実験では、学習時に情報源に対してノイズを加えることを提案しています。これは深層学習におけるdropoutと同様の効果が期待でき、このようにすることで、一つの情報源に頼りすぎないような学習が行えると期待できます。
まとめ
E2E自動運転の連載企画の第一回として、技術の概要やTuringでの取り組みを紹介しました。繰り返しになりますが、E2E自動運転の開発にはデータが命ですので、MLエンジニアに限らず大規模データを扱うことが得意な方やクラウドのインフラ構築に興味がある方に活躍の場がたくさんあります。興味を持っていただけたら私のTwitter(https://x.com/tanahhh) にDMいただくか、Turingの採用サイト(https://herp.careers/v1/turing) からカジュアル面談を申し込みください!

Discussion