はじめに
東京工業大学の藤井です。
本日(2024/07/01) Meta-Llama-3-8BとMeta-Llama-3-70Bから日本語を中心としたコーパスで継続事前学習を行ったLlama-3-Swallow-8B-v0.1、Llama-3-Swallow-70B-v0.1とそのinstructモデルであるLlama-3-Swallow-8B-instruct-v0.1、Llama-3-Swallow-70B-instruct-v0.1をリリースさせていただきました。
このモデルはMeta社のライセンスを踏襲しており、商用利用が可能です。
本モデルの開発は、産総研、東京工業大学 岡崎研究室、横田研究室の合同プロジェクトにて行われました。
公式プロジェクトページはこちらです。
Swallow Projectでは、Llama-2、Mistral、Mixtralなど様々なモデルから継続事前学習を行い、高い日本語性能を示すモデルをリリースしてきました。今回リリースさせていただいたのは、Llama-2の後継であり、高い英語性能を示すLlama-3から継続事前学習を施したモデルです。
Llama-3は非常に高い性能を示す有用なモデルですが、Metaが公式ブログで以下のように述べているように、日本語などの非英語言語における性能は十分と言えないのが現状です。
However, we do not expect the same level of performance in these languages as in English.
そこで我々Swallow Projectでは、Llama-3に対しても、他のモデルに行ったように継続事前学習を施すことで高い日本語性能と高い英語性能を有するモデルを作ることを試みました。また、これまでの知見を利用してより効率的に日本語を性能を上昇させつつ、英語性能を損なわないようにも気を配りました。
過去の取り組みについては、以下のブログや過去のプロジェクトページをご覧ください。
-
Swallow Llama-2 プロジェクトページ
https://tokyotech-llm.github.io/swallow-llama -
Swallow MS/MXプロジェクトページ
https://tokyotech-llm.github.io/swallow-mistral -
Swallow Llama2 ブログ
https://zenn.dev/tokyotech_lm/articles/d6cb3a8fdfc907 -
Swallow MS ブログ
https://zenn.dev/tokyotech_lm/articles/3f71df3cd2e589 -
Swallow MX ブログ
https://zenn.dev/tokyotech_lm/articles/5f4211b9ed3197
2024年度 プロジェクトメンバー
-
東京工業大学 岡崎研
-
東京工業大学 横田研
-
産業技術総合研究所
Llama-3 Swallow とは

(Llama-3-Swallow-v0.1 シリーズのイメージ画像)
Llama-3 Swallowとは、Meta社が2024/04/18にリリースした高性能な英語モデルLlama-3-8B、Llama-3-70Bから継続事前学習を行い日本語性能を強化したモデルの総称です。
ベースモデルと、指示応答性能を強化したinstructモデルが各サイズ(8B, 70B)ごとに存在するため計4つのモデルが存在します。
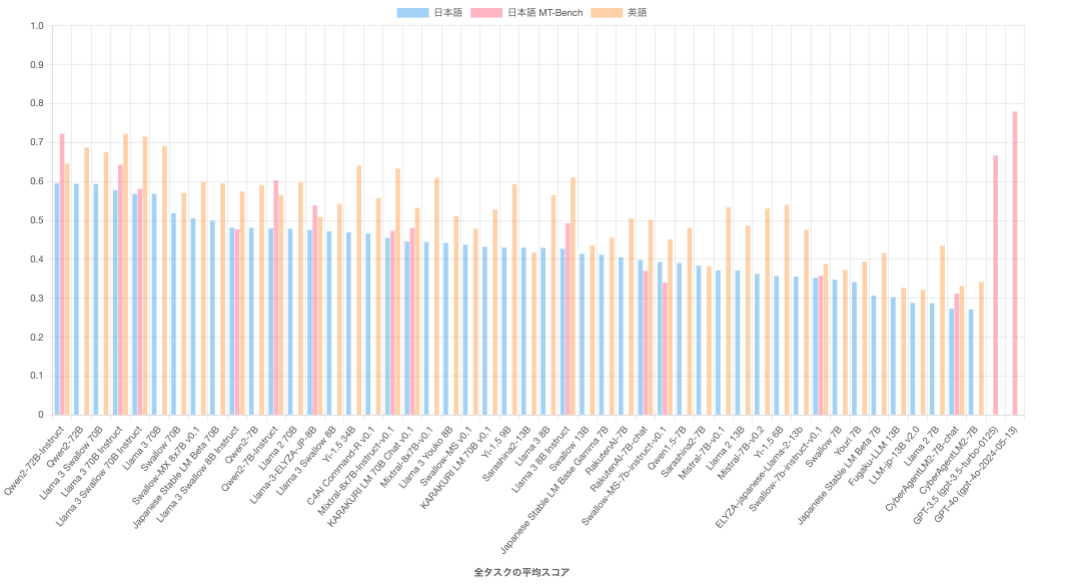
モデル評価のセクションで詳しく述べますが、Llama-3-Swallow-8B-v0.1、70B-v0.1ともに元モデルであるLlama-3-8B、70Bの日本語性能を上回る性能をベンチマーク上、示しています。
| モデル名 | 日本語スコア(平均) | 英語スコア(平均) |
|---|---|---|
| Meta-Llama-3-8B | 0.4292 | 0.5648 |
| Llama-3-Swallow-8B-v0.1 | 0.4717 | 0.5420 |
| Meta-Llama-3-70B | 0.5682 | 0.6905 |
| Llama-3-Swallow-70B-v0.1 | 0.5934 | 0.6749 |
また、英語スコアの低下幅もかなり小規模に押さえられていることは、昨年度からの改善として上げられます。
Llama-3-Swallow-70B-v0.1については、Qwen2-72Bと並び、オープンなモデルとしては日本語性能においてトップレベルの性能を示しています。
モデル評価
今回リリースしたモデルの詳細な比較について紹介します。
なお、プロジェクトページには、他のモデルとの比較を以下のように可視化できるサービスもありますので、詳細についてはそちらも参照いただけますと幸いです。
こちらのリンクです。https://swallow-llm.github.io/evaluation/
Llama-3-Swallow-8B-v0.1の評価
以下は7B、8Bサイズの他のモデルとの日本語性能の比較になります。
| Ja Avg | モデル名 | JCom. | JEMHopQA | NIILC | JSQuAD | XL-Sum | MGSM | WMT20-en-ja | WMT20-ja-en | JMMLU | JHumanEval |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.2872 | Llama 2 7B | 0.2618 | 0.4914 | 0.3301 | 0.8001 | 0.1742 | 0.0560 | 0.1764 | 0.1742 | 0.2824 | 0.1250 |
| 0.3473 | Swallow 7B(語彙拡張) | 0.4888 | 0.5044 | 0.5925 | 0.8424 | 0.1823 | 0.1240 | 0.2505 | 0.1482 | 0.3219 | 0.0183 |
| 0.3712 | Mistral-7B-v0.1 | 0.7471 | 0.4482 | 0.2691 | 0.8588 | 0.2026 | 0.1880 | 0.1430 | 0.1738 | 0.4213 | 0.2598 |
| 0.4375 | Swallow-MS v0.1 | 0.8758 | 0.5153 | 0.5647 | 0.8762 | 0.1993 | 0.2400 | 0.2507 | 0.1667 | 0.4527 | 0.2335 |
| 0.4805 | Qwen2-7B | 0.8776 | 0.4627 | 0.3766 | 0.8984 | 0.1716 | 0.5480 | 0.2080 | 0.1949 | 0.5871 | 0.4183 |
| 0.4292 | Llama 3 8B | 0.8356 | 0.4454 | 0.4002 | 0.8881 | 0.1757 | 0.3320 | 0.2199 | 0.2087 | 0.4558 | 0.3311 |
| 0.4423 | Llama 3 Youko 8B | 0.8660 | 0.4902 | 0.5155 | 0.8947 | 0.2127 | 0.2840 | 0.2740 | 0.2180 | 0.4493 | 0.2183 |
| 0.4717 | Llama-3-Swallow-8B-v0.1 | 0.8945 | 0.4848 | 0.5640 | 0.8947 | 0.1981 | 0.4240 | 0.2758 | 0.2223 | 0.4699 | 0.2890 |
Llama-3-8Bと比較してLlama-3-Swallow-8B-v0.1は約4ポイントの改善が見られています。(日本語タスク平均において)
Qwen2-7Bにわずかに平均スコアにおいて下回っていますが、ほぼ同水準とみなして良いレベルと考えています。タスク別に観察すると、JCom., JEMHopQA, NIILC, XL-Sum, WMT20-en-ja, WMT20-ja-enなどの日本語の質問応答、自動要約、機械翻訳においてLlama-3-Swallowの方が、Qwen2を上回っていますが、MGSM、JMMLU、JHumanEvalなどの算術推論、一般教養、コード生成についてはQwen2を下回っています。
このように、Llama-3-Swallow-8B-v0.1は、高い日本語性能を示すものの、改善の余地があるタスクが依然として存在する形になっています。
Llama-3-Swallow-70B-v0.1の評価
次に70B規模のモデルのbaseモデルにおける比較は以下になります。
| Ja Avg | モデル名 | JCom. | JEMHopQA | NIILC | JSQuAD | XL-Sum | MGSM | WMT20-en-ja | WMT20-ja-en | JMMLU | JHumanEval |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.4781 | Llama 2 70B | 0.8651 | 0.5157 | 0.5464 | 0.9130 | 0.2372 | 0.3640 | 0.2657 | 0.2402 | 0.5496 | 0.2841 |
| 0.5183 | Swallow 70B | 0.9178 | 0.6178 | 0.6910 | 0.9208 | 0.2279 | 0.4720 | 0.3046 | 0.2301 | 0.5750 | 0.2262 |
| 0.5937 | Qwen2-72B | 0.9607 | 0.6399 | 0.5617 | 0.9261 | 0.2362 | 0.7560 | 0.2747 | 0.2419 | 0.7831 | 0.5567 |
| 0.5682 | Llama 3 70B | 0.9473 | 0.6042 | 0.5965 | 0.9207 | 0.2254 | 0.6720 | 0.2855 | 0.2526 | 0.6975 | 0.4799 |
| 0.5934 | Llama 3 Swallow 70B | 0.9714 | 0.6695 | 0.6881 | 0.9218 | 0.2404 | 0.7080 | 0.3072 | 0.2548 | 0.7049 | 0.4683 |
Llama-3-70Bと比較してLlama-3-Swallow-70B-v0.1のスコアの改善は、日本語タスク平均において約2.5ポイントとなっています。継続事前学習により日本語性能が向上していますが、ベンチマーク上のスコアでは改善幅は、小さくなっています。
また、他のモデルとの比較ですがQwen2-72Bと0.03ポイント差であり、オープンな70B規模のモデルの中でトップレベルの性能を有していると表現して差し支えない性能をベンチマーク上、示しています。
Llama-3-Swallow-8B-instruct-v0.1の評価
これまでは、継続事前学習を施しただけのベースモデルに関する評価について解説してきましたが、次は指示チューニングを施したinstructモデルについてです。
まずは、Japanese MT-Benchのスコアです。
| JMT Avg | モデル名 | coding | extraction | humanities | math | reasoning | roleplay | stem | writing |
|---|---|---|---|---|---|---|---|---|---|
| 0.3118 | CyberAgentLM2-7B-chat | 0.1198 | 0.3793 | 0.4231 | 0.1011 | 0.1799 | 0.4760 | 0.3568 | 0.4583 |
| 0.3578 | Swallow-7b-instruct-v0.1 | 0.1947 | 0.3156 | 0.4991 | 0.1900 | 0.2141 | 0.5330 | 0.4535 | 0.4624 |
| 0.3398 | Swallow-MS-7b-instruct-v0.1 | 0.2235 | 0.3743 | 0.4611 | 0.1060 | 0.3404 | 0.4287 | 0.3969 | 0.3877 |
| 0.3699 | RakutenAI-7B-chat | 0.2475 | 0.3522 | 0.4692 | 0.2140 | 0.3926 | 0.4427 | 0.3977 | 0.4434 |
| 0.6030 | Qwen2-7B-Instruct | 0.4635 | 0.6909 | 0.6857 | 0.5970 | 0.5042 | 0.6667 | 0.5353 | 0.6808 |
| 0.4926 | Llama 3 8B Instruct | 0.3744 | 0.6876 | 0.6225 | 0.2070 | 0.5032 | 0.5248 | 0.5326 | 0.4884 |
| 0.5382 | Llama-3-ELYZA-JP-8B | 0.2908 | 0.6421 | 0.6406 | 0.3088 | 0.5500 | 0.6740 | 0.5251 | 0.6744 |
| 0.4766 | Llama-3-Swallow-8B-Instruct-v0.1 | 0.3547 | 0.6508 | 0.5371 | 0.2718 | 0.4007 | 0.5493 | 0.4752 | 0.5730 |
| 0.4728 | Mixtral-8x7B-Instruct-v0.1 | 0.4552 | 0.6680 | 0.5799 | 0.2987 | 0.3870 | 0.5300 | 0.4499 | 0.4137 |
Swallow Projectのinstructモデルはinstructデータの不足などもあり、あまり性能が高くありませんでしたが、上表の通り、ある程度の水準にまで到達することができました。2024年4月にリリースしたSwallow-Instruct-v0.1シリーズなどで培ってきた知見を元に、Mixtral-8x7B-Instruct-v0.1と同程度の指示追従性能を達成しました(MT-Benchスコア上)。
しかし、Qwen2-7B-chatなど指示チューニングに加えてDPO等のチューニングを追加で行ったモデルと比べるとLlama-3-Swallow-8B-Instruct-v0.1は、低い性能になっています。次のリリースに向けてDPOを施したモデルを開発するための準備を進めていますので、この点は今後の課題となりそうです。
次に、Instructモデルの言語理解タスクの性能についてです。
| モデル名 | Ja Avg | En Avg |
|---|---|---|
| CyberAgentLM2-7B-chat | 0.2733 | 0.3307 |
| Swallow-7b-instruct-v0.1 | 0.3524 | 0.3879 |
| Swallow-MS-7b-instruct-v0.1 | 0.3927 | 0.4511 |
| RakutenAI-7B-chat | 0.3980 | 0.5011 |
| Qwen2-7B-Instruct | 0.4793 | 0.5646 |
| Llama 3 8B Instruct | 0.4269 | 0.6107 |
| Llama-3-ELYZA-JP-8B | 0.4754 | 0.5084 |
| Llama-3-Swallow-8B-Instruct | 0.4811 | 0.5743 |
| Mixtral-8x7B-Instruct-v0.1 | 0.4550 | 0.6322 |
ベースモデルのセクションでも述べたように、Llama-3-Swallow-8Bでは、英語性能の低下を最小化することに成功しました。そのため、他のLlama-3からの継続事前学習モデルと比較して、高い日本語性能と英語性能の両方を兼ね備えたモデルとなっています。
Llama-3-Swallow-70B-instruct-v0.1の評価
次に70BサイズのモデルのJpanese MT-Bench評価とGPT-3.5、GPT-4oとの比較です。
まず、Llama-3-Swallow-70B-instruct-v0.1の性能ですが、Llama-2からの継続事前学習 + チューニングモデルであるKARAKURI LM 70B Chat v0.1より高い性能をスコア上、示しています。しかし、Llama-3-70B-Instructよりも低いスコアを示しており、現在のSwallowチームのチューニング手法、チューニングデータが未熟であることが露呈しました。
| JMT Avg | モデル名 | coding | extraction | humanities | math | reasoning | roleplay | stem | writing |
|---|---|---|---|---|---|---|---|---|---|
| 0.4797 | KARAKURI LM 70B Chat v0.1 | 0.2804 | 0.5862 | 0.6240 | 0.2934 | 0.4183 | 0.5530 | 0.4859 | 0.5964 |
| 0.6424 | Llama-3-70B-Instruct | 0.5969 | 0.8410 | 0.7120 | 0.4481 | 0.4884 | 0.7117 | 0.6510 | 0.6900 |
| 0.5809 | Llama-3-Swallow-70B-Instruct-v0.1 | 0.5269 | 0.7250 | 0.5690 | 0.4669 | 0.6121 | 0.6238 | 0.5533 | 0.5698 |
| 0.7228 | Qwen2-72B-Instruct | 0.5699 | 0.7858 | 0.8222 | 0.5096 | 0.7032 | 0.7963 | 0.7728 | 0.8223 |
| 0.6661 | GPT-3.5 (gpt-3.5-turbo-0125) | 0.6851 | 0.7641 | 0.7414 | 0.5522 | 0.5128 | 0.7104 | 0.6266 | 0.7361 |
| 0.7791 | GPT-4o (gpt-4o-2024-05-13) | 0.7296 | 0.8540 | 0.8646 | 0.6641 | 0.6661 | 0.8274 | 0.8184 | 0.8085 |
GPT-3.5、GPT-4oとの比較でも、Llama-3-Swallow-70B-Instruct-v0.1との間には大きな差があり、指示追従性能については改善の余地があることを示しています。
次にInstructモデルの言語理解タスク性能です。
| Ja Avg | モデル名 | JCom | JEMHopQA | NIILC | JSQuAD | XL-Sum | MGSM | WMT20-en-ja | WMT20-ja-en | JMMLU | JHumanEval |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.4454 | KARAKURI LM 70B Chat v0.1 | 0.8847 | 0.5139 | 0.5668 | 0.9096 | 0.1369 | 0.2800 | 0.2526 | 0.2095 | 0.4648 | 0.2354 |
| 0.5777 | Llama-3-70B-Instruct | 0.9419 | 0.6114 | 0.5506 | 0.9164 | 0.1912 | 0.7200 | 0.2708 | 0.2350 | 0.6789 | 0.6610 |
| 0.5683 | Llama-3-Swallow-70B-Instruct-v0.1 | 0.9607 | 0.6188 | 0.6026 | 0.9236 | 0.1389 | 0.6560 | 0.2724 | 0.2532 | 0.6572 | 0.6000 |
| 0.5955 | Qwen2-72B-Instruct | 0.9634 | 0.6268 | 0.5418 | 0.9210 | 0.1644 | 0.7840 | 0.2592 | 0.2327 | 0.7713 | 0.6909 |
| En Avg | モデル名 | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.5319 | KARAKURI LM 70B Chat v0.1 | 0.4100 | 0.6873 | 0.6315 | 0.3677 | 0.9049 | 0.5941 | 0.3882 | 0.5724 | 0.2305 |
| 0.7225 | Llama-3-70B-Instruct | 0.4400 | 0.7999 | 0.6552 | 0.4024 | 0.9127 | 0.7992 | 0.9052 | 0.8326 | 0.7555 |
| 0.7150 | Llama-3-Swallow-70B-Instruct-v0.1 | 0.4520 | 0.8174 | 0.6758 | 0.4050 | 0.9230 | 0.7883 | 0.8688 | 0.8152 | 0.6890 |
| 0.6455 | Qwen2-72B-Instruct | 0.4360 | 0.7588 | 0.6857 | 0.3913 | 0.9110 | 0.8391 | 0.8499 | 0.2436 | 0.6939 |
日本語スコア平均、英語スコア平均ともに、Llama-3-70B-Swallow-Instruct-v0.1は、Llama-3-70B-Instruct を下回っています。継続事前学習を施した時点では、Llama-3-Swallow-70B-v0.1は学習元のLlama-3-70Bを日本語スコア平均で上回っていましたが、チューニングを施したことで、スコア上、その効果が失われてしまいました。
学習ライブラリ
Llama-3-Swallowの学習には、Llama-2-Swallowのときと同様にMegatron-LMを利用しました。
HuggingFace形式のcheckpointをMegatron-LM形式に変換するためのcheckpoint converterの実装や、Llama-3のtokenizerを使用できるようにする変更など、ある程度の変更は必要でした。Swallow Projectでは、公式Megatron-LMのfork版を利用することで、効率的に継続事前学習を行いました。
分散学習設定
主に以下の設定で学習を行いました。
(空きノードの関係等から一部の実験については可能な範囲で途中からGPU数を変更する措置を行いました。)
| モデル名 | node数 | DP | TP | PP | SP | Distributed Optimizer |
|---|---|---|---|---|---|---|
| Llama-3-Swallow-8B | 4node | 4 | 2 | 4 | ✔ | ✔ |
| Llama-3-Swallow-70B | 32node | 2 | 8 | 16 | ✔ | ✔ |
Data Parallel + Tensor Parallel + Pipeline Parallelを組み合わせた3D Parallelismを利用しています。
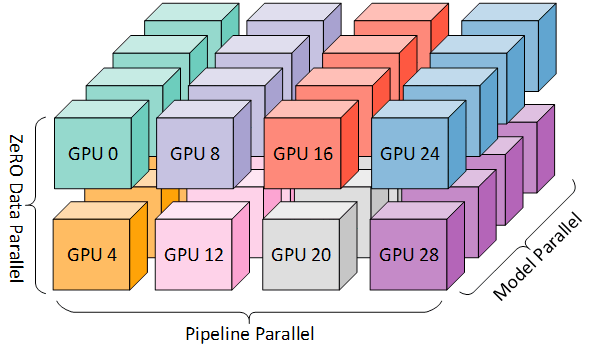
(3D parallelism Microsoft Research blogより)
学習
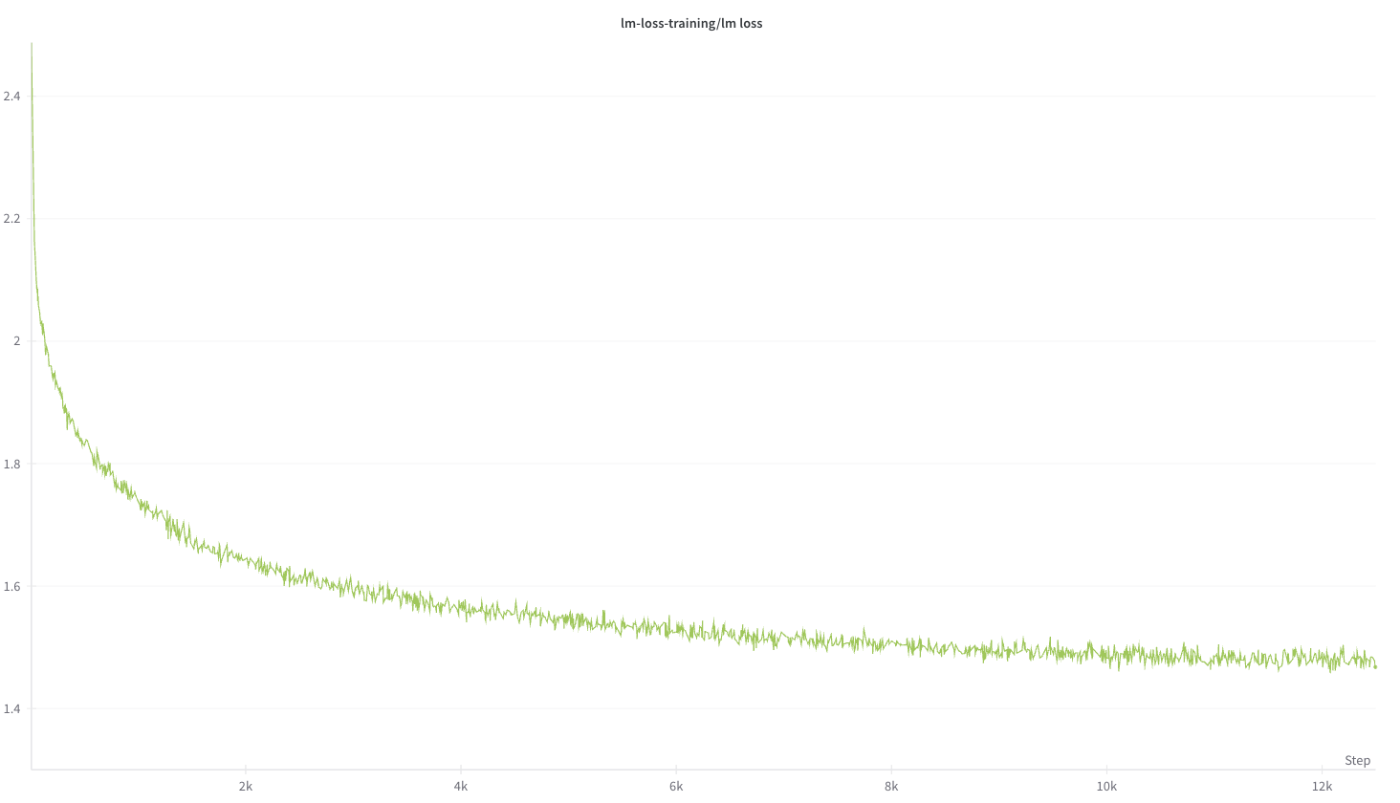
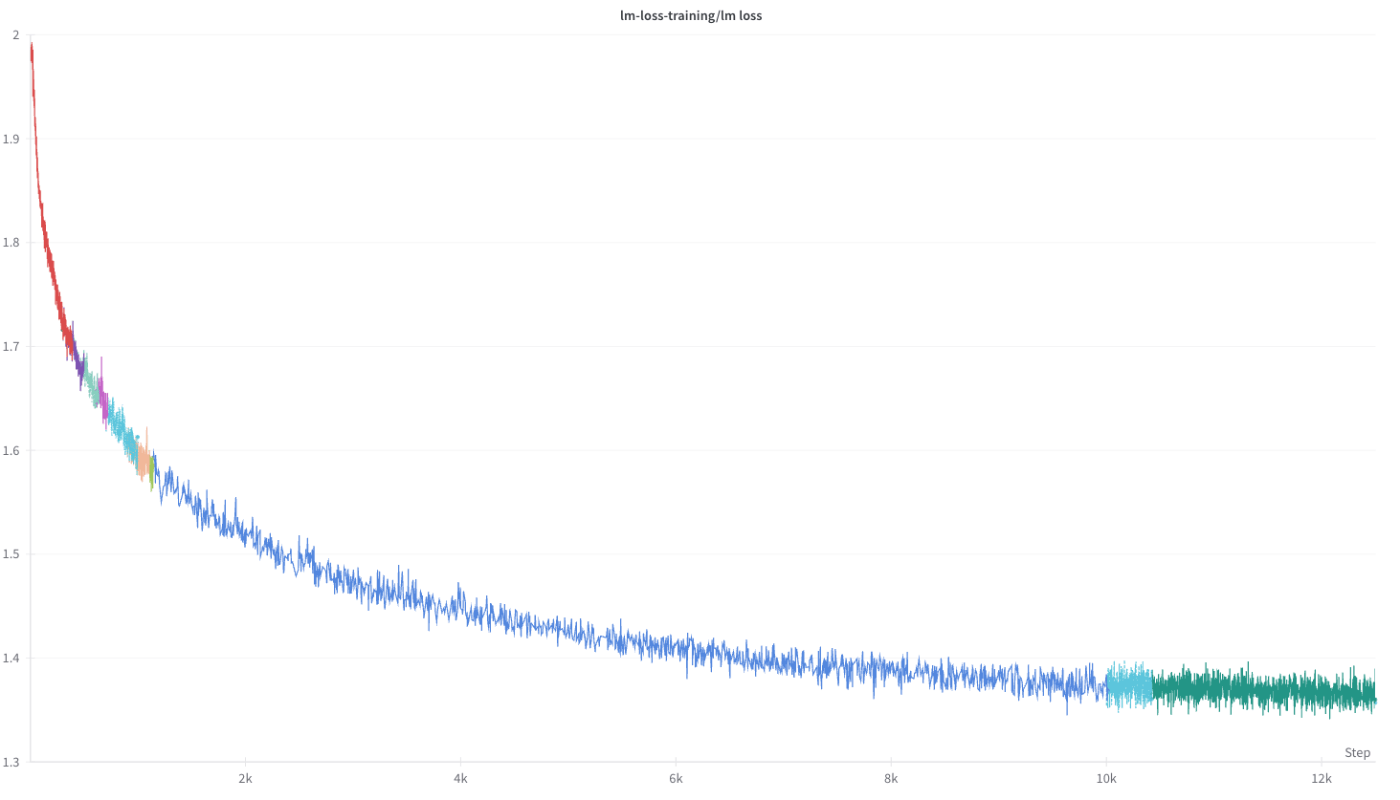
以下にLlama-3-Swallowの学習曲線を示します。
Llama-3-Swallow-8B-v0.1 の学習曲線(Training Loss)
Llama-3-Swallow-70B-v0.1 の学習曲線(Training Loss)
ハイパーパラメータ
学習に使用したハイパーパラメータは以下の通りです。
| モデルサイズ | LR_max | LR_min | global batch size | weight_decay | grad_clip |
|---|---|---|---|---|---|
| 8B | 2.5E-5 | 2.5E-6 | 1024 | 0.1 | 1.0 |
| 70B | 1E-5 | 1E-6 | 1024 | 0.1 | 1.0 |
またOptimizerにはAdamWを利用し、
加えて、学習速度向上のためにFlashAttention、TransformerEngineを利用しました。
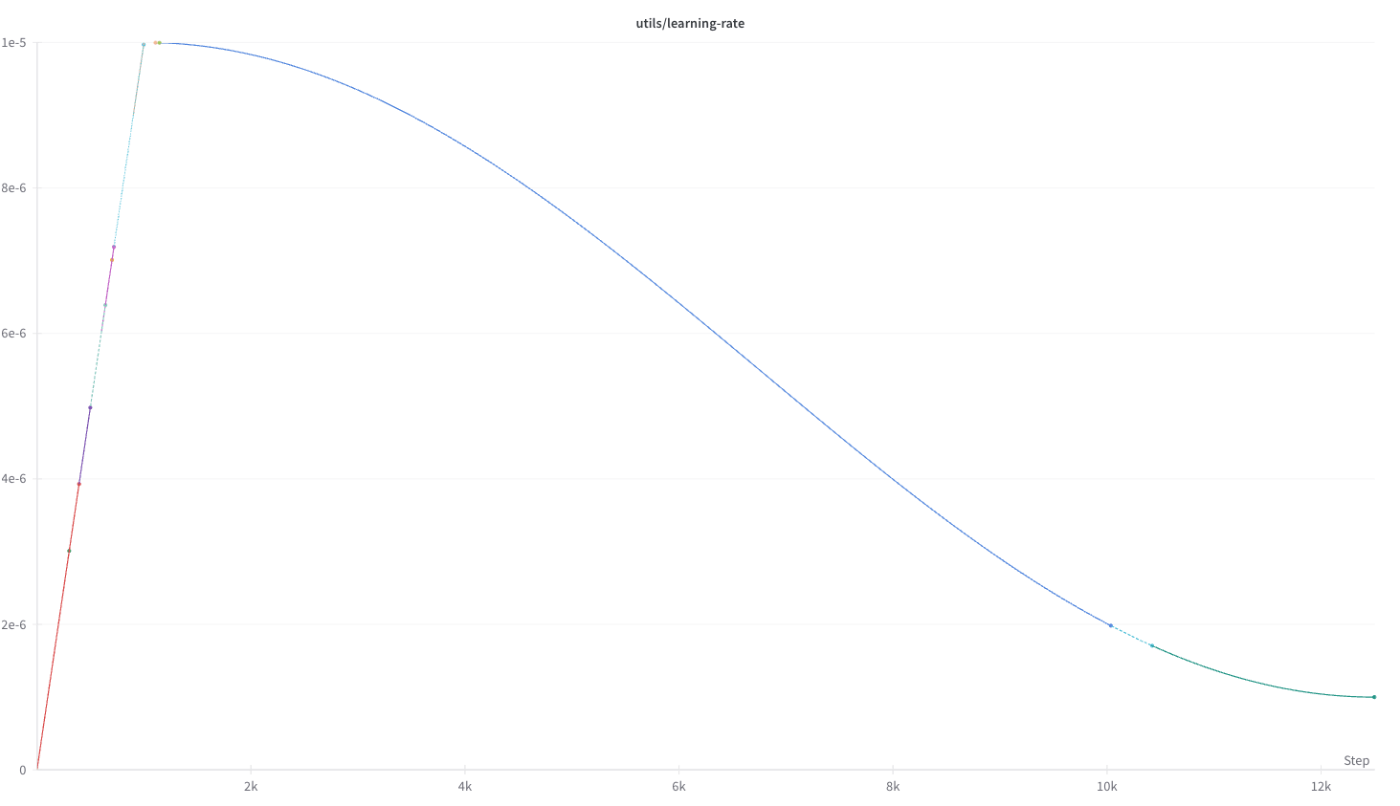
(Llama-3Swallow-70BにおけるLearning Rateの推移)
また学習の状況を把握するためのloggingには、Weights & Biases(通称 wandb)を利用しました。
学習データ
継続事前学習には、以下のデータセットを利用しました。
- Algebraic Stack
- Cosmopedia
- English Wikipedia
- Japanese Wikipedia
- Laboro ParaCorpus
- OpenWebMath
- RefinedWeb
- Swallow Corpus
学習準備中の出来事
HuggingFace Transformers version
Llama-3のconfig.jsonに記載の通り、Llama-3に対応しているtransformersバージョンは4.40.0以降なのですが、4.39.3でもLlamaForCuasalLMなど諸々のクラスはあるのでTokenizerも含め一見問題なく動いてしまいます。
しかし、transformers==4.39.3を利用してLlama-3 Tokenizerでtokenizeを行った結果と、transformers==4.40.0以降を利用してLlama-3 Tokenizerにてtokenizeを行った結果は異なります。
こちらの問題に実際に遭遇しましたが、大規模実験開始前に気づくことができました。
HuggingFace Llama-3 tokenizer
以下のように4/23にtokenizer.jsonに変更が入っています。
こちらの変更前のversionを利用しているとadd_special_tokens=Trueを指定していても、bos(begin of sentense)が挿入されない問題がありました。学習時のコードでは、こちらの影響を受けないような実装をしていたのですが、評価時はこちらの影響を受けてしまう実装だったため、すでに評価したモデルを1から評価することが必要になりました。(Swallow評価チームに感謝です)
ノード不良
今回の一連の実験でもノード不良に数回見舞われました。
しかし今回は、昨年度の教訓からジョブを複数人で流す際は、流しているノード番号を事前に控え、管理者が一元管理するなどの体制を取ったため、特に問題なく学習を進めることができました。
またノード不良を検知するためのスクリプトや、学習を監視し実験が停止していないかどうか通知するツールにより大部分を自動化することに成功しました。
ノードの利用率もほぼすべての期間、90%を超えており、ノード不良等が発生しているせいで予定していた配分で実験が流せない期間を除くと100%に近い利用率を達成しました。
ストレージ起因のTFLOP/sの低下
ABCIのストレージサービスにアクセスが集中し、データのprefetchが遅れるなどが発生し、学習速度が低下する自体が発生しました。最初は通信周りの問題やGPU不良を疑ったのですが、プロファイリングを行い通信時間を可視化しましたが、特段、通信時間が増加している様子は確認されませんでした。
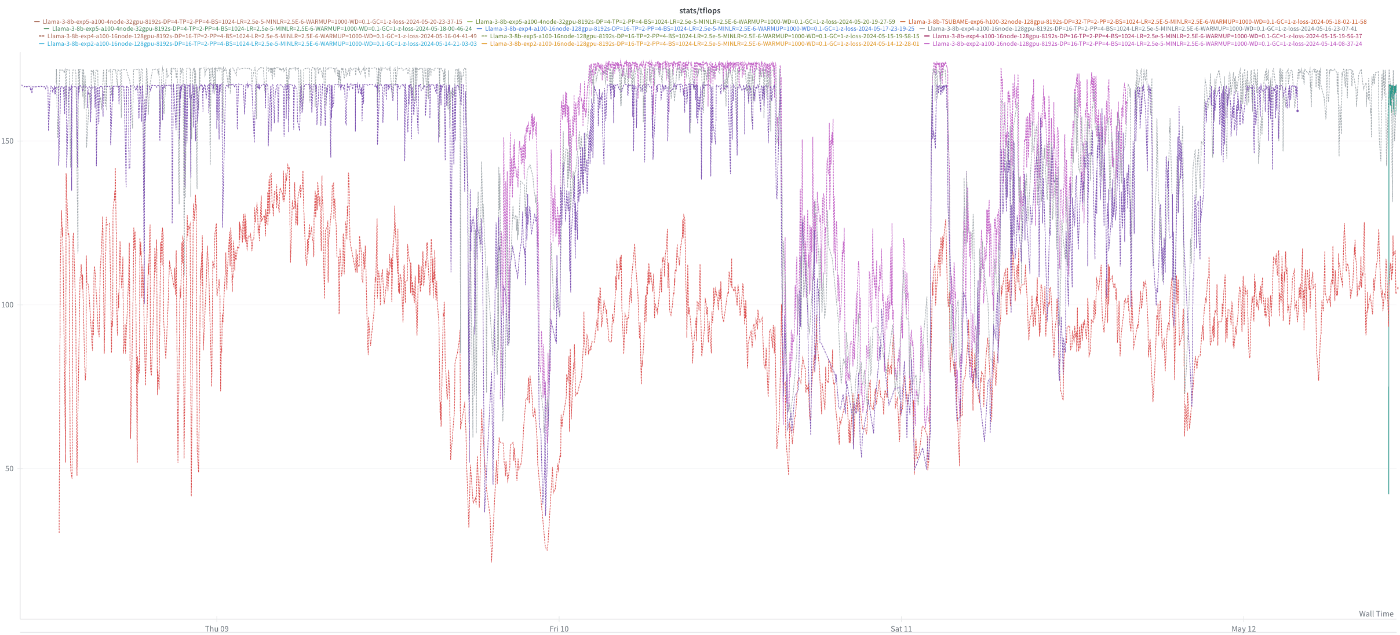
(データアクセス遅延によりTFLOP/sが乱高下する様子)
ABCIに確認したところ、実際に問題が発生した時刻にストレージ全体の利用量が増加傾向にあったようなため、ストレージ起因の学習速度低下と結論付けました。
H100(TSUBAME 4.0)での検証
Swallow Projectでは、H100を利用した学習を今後本格的に行っていくことに備えて、TSUBAME 4.0での検証を横田研究室を中心に行っています。
Megatron-LM、llm-recipes、各種評価ツールをTSUBAME上で動作することを早くから確認しています。また、TransformerEngine FP8 hybridの利用などについても実証実験を行っており、学習への影響等を分析しています。
今後の研究
Swallowプロジェクトでは、今後もより日本語に強いLLMの開発に向けて研究開発を進めていきます。
学習の高速化のための工夫により同じ計算予算でより多くの学習を行えるようにしたり、学習手法自体に工夫を加えたり、学習データを工夫することで性能を改善したりするなど、研究課題はたくさんあります。
実は、計算資源が足らず、できていない施策は多くあります。
また、Yi-1.5、Qwen-2、Nemotron、Gemma-2からの継続事前学習などについても興味がありますが、計算資源の関係からどうしても後回しになっている部分があります。Swallow Projectに予算や計算資源を何らかの形で提供いただいたり、計算資源等を供与する形での共同研究等は非常にありがたいです。ぜひお声がけください。

Discussion