はじめに
東京工業大学 横田研究室の藤井です。
本日(2024/03/11)Mixtral-8x7B-Instruct-v0.1から日本語継続事前学習を行ったSwallow-MX-8x7b-NVE-v0.1をリリースさせて頂きました。
本モデルの開発は、産総研、東京工業大学 岡崎研究室、横田研究室の合同プロジェクトにて行われました。公式プロジェクトページはこちらです。
Swallow-MX はMoE(Mixture of Expert)モデルの継続事前学習モデルであり、Denseモデルにおいて有効性が示されている継続事前学習手法がMoEモデルにおいても有効であることを示す結果が得られました。
Denseモデルに対する継続事前学習に関しては、以下のブログやNLP2024の我々の論文をご覧ください。
リリースモデル
- 日本語継続事前学習済みモデル
本記事では、Swallow-MXモデルについてと、モデル開発の中で得られた知見について紹介します。
また、Mistralから継続事前学習を行った、Swallow-MSも同時に公開していますので、以下の記事から詳細をご覧ください。
プロジェクトメンバー
Swallow-MX とは

(Swallow-MX モデルイメージ)
Swallow-MXはMixtralの日本語能力を強化した大規模言語モデル(8x7B)です。Licenseは継続事前学習元のMixtralのライセンスであるApache-2.0を継承し、商業利用可能なモデルとなっています。
我々がSwallowモデル群でも採用した評価タスク中での平均スコアは以下のようになっており、Mistral社が公開しているMixtralモデルよりも高い日本語性能が達成できています。
| モデル名 | 日本語スコア(NLI除く平均) |
|---|---|
| Mistral-8x7B-v0.1 | 0.4418 |
| Swallow-MX-8x7B-v0.1 | 0.5208 |
モデル評価
日本語の評価タスクはllm-jp-evalとJP LM Evaluation Harnessから一部を採用しました。
使用しているタスクはSwallow (Llama 2継続事前学習)において採用したタスクと同様です。
日本語平均スコアで見るとSwallow-MXは、Swallow-70B、Qwen-72Bの次に性能が良いモデルと言えるでしょう。
| モデル名 | 日本語スコア(NLI除く平均) |
|---|---|
| Swallow-70b | 0.5528 |
| Qwen-72B | 0.5244 |
| Swallow-MX-8x7B-v0.1 | 0.5208 |
| japanese-stablelm-base-beta-70b | 0.5138 |
| Llama-2-70b-hf | 0.4830 |
| karakuri-lm-70b-v0.1 | 0.4669 |
| Mistral-8x7B-v0.1 | 0.4418 |
各評価タスクごとの結果は以下のようになっています。
| モデル名 | 平均 | JCom | JEMHopQA | NIILC | JSQuAD | XL-Sum | MGSM | WMT20-en-ja | WMT20-ja-en |
|---|---|---|---|---|---|---|---|---|---|
| Swallow-70b | 0.5528 | 0.9348 | 0.6290 | 0.6960 | 0.9176 | 0.2266 | 0.4840 | 0.3043 | 0.2298 |
| Qwen-72B | 0.5244 | 0.9294 | 0.5566 | 0.4518 | 0.9159 | 0.2179 | 0.6320 | 0.2561 | 0.2356 |
| Swallow-MX-8x7B-v0.1 | 0.5208 | 0.9258 | 0.5843 | 0.5687 | 0.9148 | 0.2589 | 0.4360 | 0.2705 | 0.2074 |
| japanese-stablelm-base-beta-70b | 0.5138 | 0.9115 | 0.4925 | 0.6042 | 0.9192 | 0.2573 | 0.4160 | 0.2765 | 0.2335 |
| Llama-2-70b-hf | 0.4830 | 0.8686 | 0.4656 | 0.5256 | 0.9080 | 0.2361 | 0.3560 | 0.2643 | 0.2398 |
| karakuri-lm-70b-v0.1 | 0.4669 | 0.8579 | 0.5125 | 0.5713 | 0.9100 | 0.1464 | 0.2720 | 0.2540 | 0.2113 |
| Mistral-8x7B-v0.1 | 0.4418 | 0.8347 | 0.5335 | 0.3549 | 0.8847 | 0.2192 | 0.3120 | 0.1970 | 0.1987 |
英語スコアの低下幅
| モデル名 | 英語スコア(平均) |
|---|---|
| Mixtral-8x7B-Instruct-v0.1 | 0.6335 |
| Swallow-MX-8x7B | 0.6129 |
| Llama-2-70b | 0.6268 |
| Swallow-70b | 0.6042 |
Llama-2のときと同様に、Swallow-MXも継続事前学習元のベースモデルから2ポイントほど英語スコア(平均)が低下しています。そのため、MoEモデルであることがスコアの低下幅低減につながる等の示唆は得られていません。
学習ライブラリ
Mixtralの継続事前学習には、独自のライブラリであるmoe-recipesを利用しました。
moe-recipesは、Swallow-MSの学習に利用したllm-recipesを元に開発されたライブラリで、MoEモデルの継続事前学習と、事前学習ができるように設計されています。
分散学習設定
MoEの学習にはExpert Parallelismと呼ばれるMoEのExpertを別々のGPUに配置しメモリを削減する手法や、Denseモデルと同様に3D Parallelism(Data Parallelism, Tensor Parallelism, Pipeline Parallelism)を利用して学習する分散学習方法があります。今回の学習に使用したライブラリは開発期間が少なかったこともあり、実装が容易いDeepSpeed ZeRO3のみを利用した分散学習手法を採用しています。
今回、学習を行ったABCIはInterconnectが良いこともあり90〜100TFLOPS程度で学習することができていました。
学習
次に、Swallow-MXの実際の学習に使用した学習設定について説明します。
ハイパーパラメータ
学習に使用したハイパーパラメータは以下のとおりです。
| LR | LR min | global batch size | weight decay | grad clip |
|---|---|---|---|---|
| 2.0E-5 | 2.0E-6 | 1024 | 0.1 | 1.0 |
また Optimizerには、AdamWを利用し、
加えて、学習速度向上のために FlashAttentionを利用しました。
(Swallow-MX学習時のLearning Rate推移)
また参考までにcheckpointサイズを示しますと、1つあたり523GBでした。
以下に学習時のLossの推移を示します。
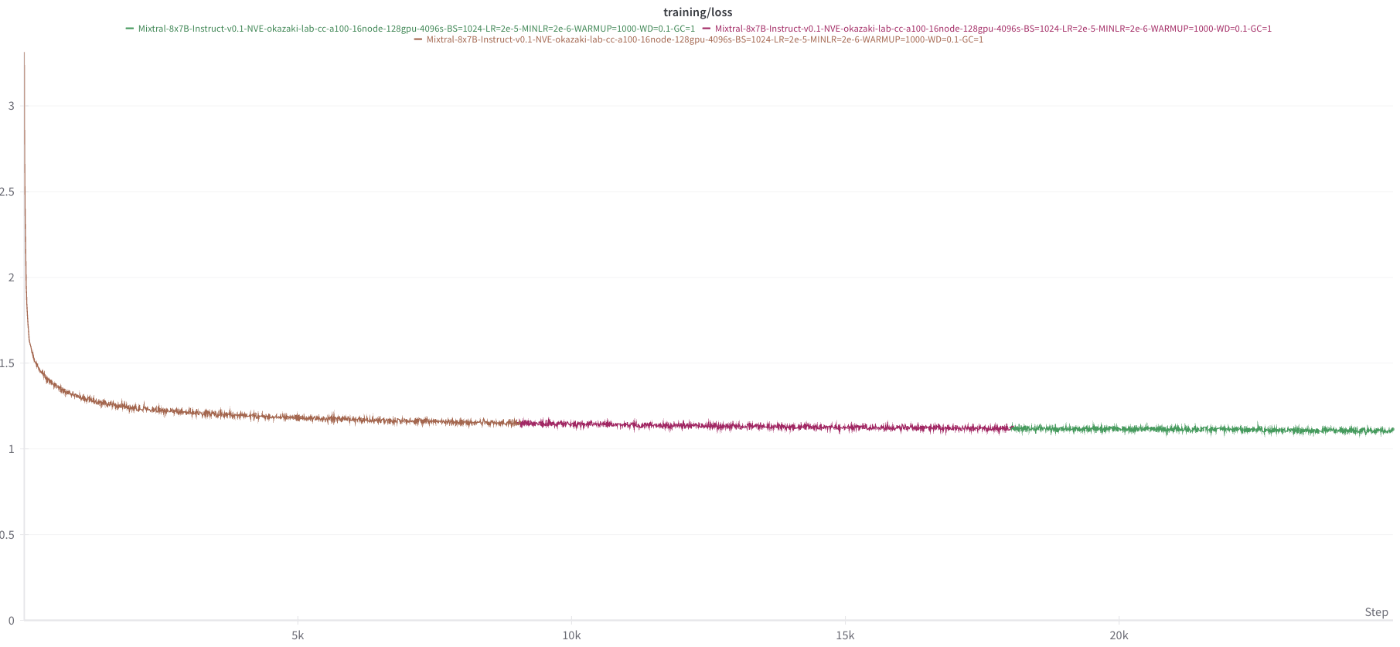
(Swallow-MXのTraining Loss推移)
またLoadbalancing Lossの推移は以下のようになっています。
(Swallow-MXのLoadbalancing Loss推移)
学習データセット
Swallow-MXの学習には以下のデータセットを利用しました。
-
Swallow Corpus
日本語コーパス:英語コーパス:数学、コードコーパスの割合は、64.4:25.6:10となっています。
総学習Token数は、104.9B Tokenです。
遭遇した問題
DeepSpeed ZeRO 3が動作しない問題
こちらのPull Requestに示されているように、DeepSpeed ZeRO 3は1月末時点では、MoEモデルを学習することができず、backward時に停止してしまう問題がありました。
こちらについて、Microsoft DeepSpeedチームの田仲さんが修正を行ってくれたため、こちらの変更を使用することで、正しくReduce Scatterが行われるようになりました。
Lossが異様に下がる問題
以下のように、Lossが異様に低下し過学習しているかのような挙動を示す事態に遭遇しました。
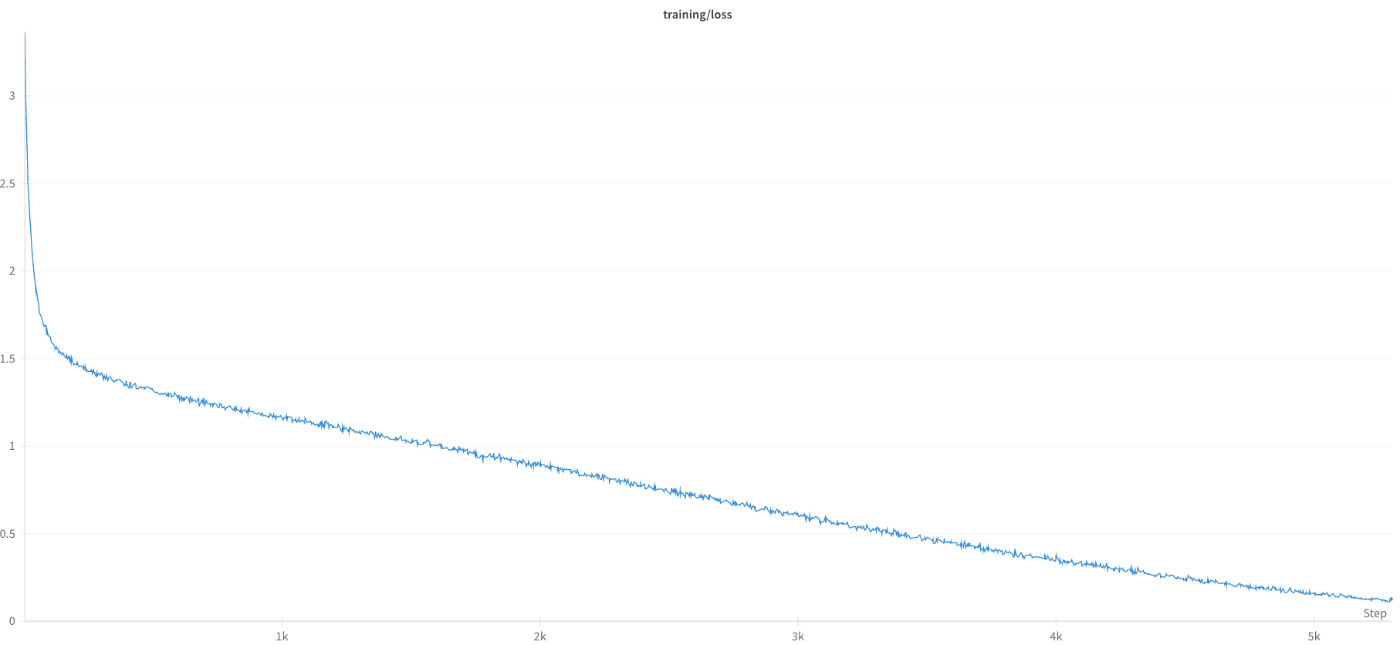
原因は、Huggingface Acceleratorの.prepare()メソッドにdataloaderを通していたからでした。HuggingFace acceleratorはCustome DataLoaderを正しく扱えないようで、データセットの一部分を見ただけですべてのデータセットを見終わったとみなし、2epoch目に突入するという動作をしていることが明らかになりました。
該当箇所(修正後)
model, optimizer, _, _, scheduler = accelerator.prepare(
model,
optimizer,
train_dataloader,
validation_dataloader,
scheduler,
)
のように、accclerator.prepare()から返ってくるdataloaderについては_にて無視する措置を行ったところ、学習が正常に行われるようになりました。
この問題は非常に気づきづらく、データローダーがおかしいのではないかと疑った際に、最初の100iteration程度は同じデータを使用している形跡がデバッグモードにしても発見できなかったため、可能性から除外していました。
しかし、他の怪しい箇所をいくら検証しても原因らしく点が発見できず、途方に暮れていた際に、たまたまノード不良が発生し、jobがkillされました。そのジョブは検証用ジョブであったため復帰させる必要はなかったのですが、とりあえず復帰させてみると下図のようにLossが大きくズレる事態が発生しました。
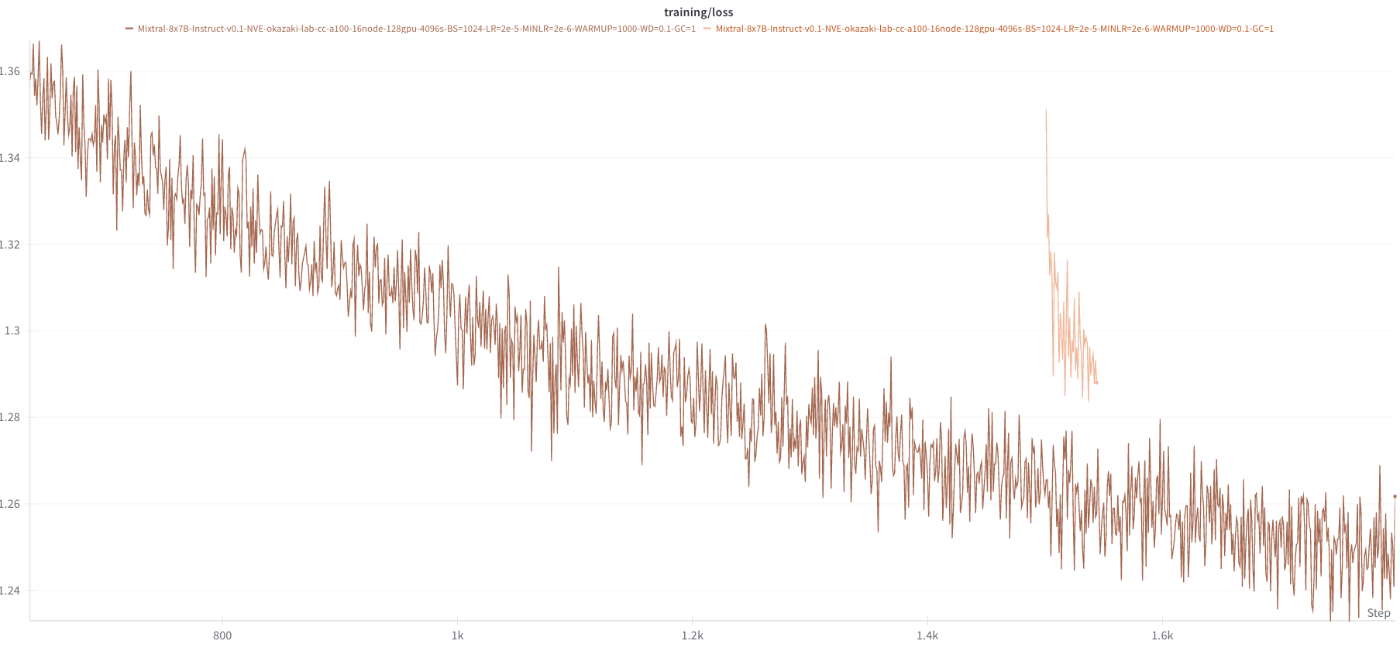
最初は、checkpoint save, load周りの実装ミスかと思ったのですが、どうも違うようであり、dataloaderに起因していることが判明してきました。また、最初の100iteraiton程度では、どうようにcheckpoint loadを行い学習を再開してもどうようのLoss乖離現象は発生しないことが分かりました。
以上の点から、100iteration以降1,000iteration未満の間でなにかおかしな挙動が発生していること、そして同じデータが学習されていることが追加調査で判明しました。
Custom DataLoader自体は、Megatron-LM、Megatron-DeepSpeed、llm-recipesでも使われて実績がある実装であったため、最も怪しい箇所としてHuggingFace Accleratorが候補に上がりました。そこで、HuggingFace AcceleartorにDataLoaderを管理させない措置を行うと、上記の問題がすべて解決することが分かりました。
今後の研究
この記事では、Mixtral-8x7Bから日本語継続事前学習を行いSwallow-MXを開発したことに関する説明を行ってきました。Swallowプロジェクトでは、来年度以降も引き続き大規模言語モデルを効率的に学習する方法について研究開発を行っていきます。
本プロジェクトで作成されたモデル(Swallow, Swallow-MS, Swallow-MX)を利用した活動等が広がるように今後も、学習で得られた知見やモデルを公開していく予定です。

Discussion
moe-recipesのライブラリは事前学習もできるのでしょうか?
公式にサポートしているわけでは、ありませんが、
config.jsonを作成いただけば可能です。モデルを構成するのは以下のようになっていますので、使いやすいように適時変更いただけますと 🙏