はじめに
東京工業大学 横田研究室の藤井です。
本日(2023/12/19)Llama 2から日本語継続事前学習を行ったSwallow-7B, Swallow-13B, Swallow-70Bをリリースさせて頂きました。
本モデルの開発は、産総研、東京工業大学 岡崎研究室、横田研究室の合同プロジェクトにて行われました。公式プロジェクトページはこちらです。
Swallow-70Bはオープンな日本語モデルにおいて最高の日本語性能を記録しました。
(後述のモデル評価セクションを参照のこと)
リリースモデル
- 日本語継続事前学習済みモデル
- 上記モデルに指示チューニングを施したモデル
本記事では、Swallowモデルについてと、モデル開発の中で得られた知見について紹介します。
プロジェクトメンバー
Swallow とは

(Swallowモデルイメージ)
Llama 2の日本語能力を強化した大規模言語モデル(7B, 13B, 70B)です。Llama 2 Communicty Licenseに従う限り、商業利用可能なモデルとなっています。
我々が採用した評価タスク中での平均スコアは以下のようになっており、Meta社が公開しているモデルよりも高い日本語性能が達成できています。
| モデル名 | 日本語スコア(NLI除く平均) |
|---|---|
| Meta Llama-2-7b-hf | 0.3201 |
| Swallow-7B | 0.3940 |
| Meta Llama-2-13b-hf | 0.3963 |
| Swallow-13B | 0.4625 |
| Meta Llama-2-70b-hf | 0.4830 |
| Swallow-70B | 0.5528 |
HuggingFaceのモデルカードの例と同じ様に使用することで、それぞれの環境で試すことが可能です。
モデル評価
日本語の評価タスクはllm-jp-evalとJP LM Evaluation Harnessから一部を採用しました。
詳細についてはプロジェクトページを参照ください。
性能評価
次に評価概要について説明します。
7B, 13B, 70Bの各モデルサイズごとに日本語スコア平均と英語スコア平均を掲載しています。
7B
| 提供元 | モデル名 | 日本語平均 | 英語平均 |
|---|---|---|---|
| Meta | Llama-2-7b-hf | 0.3201 | 0.4895 |
| CyberAgnet | calm2-7b | 0.3098 | 0.4026 |
| ELYZA | ELYZA-japanese-Llama-2-7b | 0.3467 | 0.4703 |
| ELYZA | ELYZA-japanese-Llama-2-7b-fast | 0.3312 | 0.4608 |
| Stability AI Japan | japanese-stablelm-base-beta-7b | 0.3366 | 0.4736 |
| Stability AI Japan | japanese-stablelm-base-ja_vocab-beta-7b | 0.2937 | 0.4545 |
| Stability AI Japan | japanese-stablelm-base-gamma-7b | 0.4301 | 0.4860 |
| 東工大・産総研 | Swallow (語彙拡張なし) | 0.4063 | 0.4385 |
| 東工大・産総研 | Swallow (語彙拡張あり) | 0.3940 | 0.4399 |
上図のとおり、Swallow(語彙拡張なし), Swallow(語彙拡張あり)ともにMeta社のLlama-2-7b-hfよりも高い日本語性能を獲得しています。また、我々と同様にLlama-2から継続学習を行った他のプロジェクトのモデルと比較して高い日本語能力が獲得できているとスコアから評価できます。
Stability AI JapanがMistral-7B-v0.1から継続事前学習を行ったモデルが最も日本語性能が高いと評価されています。これには様々な仮説が考えられますが、1つにBaseモデルであるMistral-7Bの性能の高さに起因する説が存在します。

Swallow-7B (語彙拡張あり)のTraining Loss (学習Token数は約100B Token)
13B
| 提供元 | モデル名 | 日本語平均 | 英語平均 |
|---|---|---|---|
| Meta | Llama-2-13b-hf | 0.3963 | 0.5398 |
| LLM勉強会 | llm-jp-13b-v1.0 | 0.2889 | 0.3893 |
| ストックマーク | stockmark-13b | 0.2495 | 0.2881 |
| 東工大・産総研 | Swallow (語彙拡張あり) | 0.4625 | 0.4922 |
13Bにおいても7B同様に、Swallow-13BはMeta社のLlama-2-13b-hfを上回る日本語性能を発揮しています。13Bモデルにおいては、学習データセットを変化させた際のモデル性能への影響を観察するために、今回の学習のために岡崎研究室が開発したSwallow Corpusデータセット以外の2つでも実験を行っています。
詳細については、モデルリリースとともに公開しているこちらをご覧ください。

Swallow-13B (語彙拡張あり)のTraining Loss(Swallow Corpusデータセット) (学習Token数は約100B Token)
70B
| 提供元 | モデル名 | 日本語平均 | 英語平均 |
|---|---|---|---|
| Meta | Llama-2-70b-hf | 0.4830 | 0.6268 |
| Stability AI Japan | japanese-stablelm-base-beta-70b | 0.5138 | 0.6288 |
| 東工大・産総研 | Swallow (語彙拡張なし) | 0.5595 | 0.6024 |
| 東工大・産総研 | Swallow (語彙拡張あり) | 0.5528 | 0.6042 |
70Bにおいても7B, 13Bと傾向は同じです。
Swallow-70BはMeta社Llama-2-70b-hfを上回る日本語性能を発揮しています。
また、同様に日本語継続学習を行った事例と比較してもSwallowの日本語性能は上回っており、現状では日本語最強Baseモデルと表現しても差し支えないでしょう。

Swallow-70B (語彙拡張あり)のTraining Loss (学習Token数は約100B Token)
語彙拡張の有無
7B, 70Bでの評価結果を観察するに語彙拡張ありのモデルは、語彙拡張なしのモデルと比較して0.4〜1.3ポイントほど日本語スコアが低下することが確認されています。(約100B Token学習後)
7Bにおける語彙拡張の有無によるスコア差は、70Bのそれと比較して大きいことが観測されています。13Bモデルにおいて語彙拡張なしの実験を行っていないため、検証の余地はあるもののモデルサイズが小さいほど語彙拡張の影響を受けるものと思われます。また、この現象は、先行事例であるStability AI Japanでの実験でも確認されています。
加えて、我々は代表的なcheckpointである20B Token, 40B Token, 60B Token, 80B Token, 100B Token学習させた時点でのcheckpointのモデルについても評価を行っています。こちらを観測する限りでは、学習Token数を増やすことで語彙拡張の影響を縮小することが可能とは考えにくい形となっていますが、引き続き検証を進めていきます。
Swallow-7Bにおける例(以下の表の算出式は上記と少々異なります)
| 学習Token数 | 日本語平均(Swallow-7B 語彙拡張なし) | 日本語平均(Swallow-7B 語彙拡張あり) |
|---|---|---|
| 20B Token | 0.3474 | 0.3357 |
| 40B Token | 0.3429 | 0.3507 |
| 60B Token | 0.3714 | 0.3559 |
| 80B Token | 0.3800 | 0.3684 |
| 100B Token | 0.3847 | 0.3714 |
40B Token学習させた時点では逆転していますが、基本的に語彙拡張をしたモデルの方が、語彙拡張なしのモデルよりも1.2ポイントほど低い傾向が続いています。そのため、上述の通り学習Token数を増やせば語彙拡張の有無の差が縮小するという見方には疑問符がつきます。しかしながら、この実験結果だけで結論づけることは難しいとも考えています。
英語スコアの低下
我々の継続事前学習モデルは日本語性能を上昇させることに成功しましたが、英語性能については低下してしまっています。特に小さなモデル(7B)ほど顕著に英語スコアが低下しています。
英語事前学習済みモデルであるLlama 2から日本語継続事前学習を行なうことで、高い日本語性能を獲得することが目的とはいえ、英語性能が保てるのであれば保ちたいと考えています。もちろん、英語性能の維持に固執して日本語性能を上昇させることができないのでは問題ですが、両立することが可能なのではないかと考えています。この点については引き続き実験を行っていく予定です。
使用ライブラリ
以上でSwallowについてと、モデルの性能について説明を行いました。次に学習に使用したライブラリについて説明を行います。
学習にはMegatron-LMを利用しました。HuggingFace形式で公開されているLlama 2のcheckpointをMegatron形式のcheckpointに変換し、そこから継続事前学習を行なうという形をとりました。
transformersのTrainerクラスや、llama-recipesなどのライブラリを改造し、学習を行うことも考えましたが、学習速度やライブラリとしての成熟度が高く、実験を主に行った横田研究室の私(藤井)や中村さんにとって馴染みが深いMegatron-LMを採用しました。
分散学習
本プロジェクトでは、ABCI大規模言語モデル構築支援プロジェクトのリソースで実験を行いました。
具体的にはNVIDIA A100(40GB) x 8 を60ノード利用し学習を行いました。
7B, 13B, 70Bの学習を効率的に行うために後述する3D Parallelism + Sequence Parallelism + Distributed Optimizer(DeepSpeed ZeRO1相当)を利用して学習を行いました。
160〜180 TFLOPSほどの速度で学習を行い、効率的に計算機環境を利用しました。
3D Parallelism
Data Parallel + Tensor Parallel + Pipeline Parallelを組み合わせた3D Parallelismを利用しています。
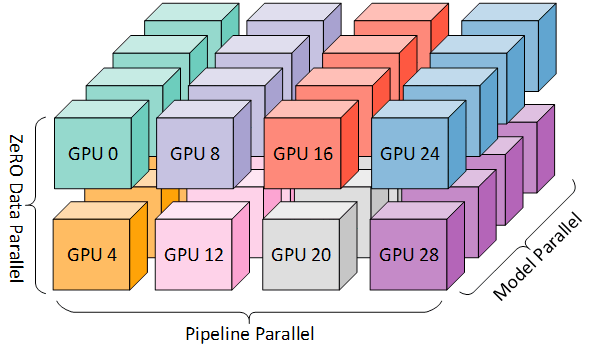
(3D parallelism Microsoft Research blogより)
Data Parallelにおけるメモリ効率化: 通常のデータ並列はモデルとOptimizer statesをすべてのData Parallel workerの間で複製しています。しかしながら、この方法はメモリ効率上非効率です。DeepSpeed ZeRO 1のようにOptimizer Statesを分散して保有することでこの問題を解決できます。今回は、Megatron-LMに実装されているDistributed Optimizerを利用することとしました。
Sequence Parallelの導入: Tensor Parallelを導入するだけでは、LayerNormやDropoutに関しては並列化されずにTensor Parallel group間で複製されてしまっています。これらの部分は多くのActivation memoryを使用するためtensor parallel group間で分割することができるとメモリ効率化が達成できます。そこでTransformer LayerにおいてTensor Parallel Groupにより分割できていない部分をsequence dimenstionで分割しActivationが消費するメモリを削減しました。

(Reducing Activation Recomputation in Large Transformer Modelsより)
分散学習に関する用語について詳しく知りたい方は以下の記事をご参照ください。
学習config
主に以下の設定で学習を行いました。空きノードの関係等から一部の実験については可能な範囲で途中からGPU数を変更する措置を行いました。
| モデル名 | node数 | DP | TP | PP | SP | Distributed Optimizer |
|---|---|---|---|---|---|---|
| Swallow-7B(語彙拡張なし) | 2node | 4 | 2 | 2 | ✔ | ✔ |
| Swallow-7B(語彙拡張あり) | 4node | 8 | 2 | 2 | ✔ | ✔ |
| Swallow-13B(語彙拡張あり) | 8node | 8 | 2 | 4 | ✔ | ✔ |
| Swallow-70B(語彙拡張なし) | 16node | 2 | 8 | 8 | ✔ | ✔ |
| Swallow-70B(語彙拡張あり) | 32node | 4 | 8 | 8 | ✔ | ✔ |
学習設定
base vs chat
継続事前学習を行なう際のベースモデルにLlama-2-7b-chat-hf, Llama-2-13b-chat-hfなどのchatモデルを利用するか、Llama-2-7b-hf, Llama-2-13b-hfなどのbaseモデルを利用するのかについてですが、我々はすべてbaseモデルから学習を行っています。
このように決めた理由としては、Llama-2-7b, Llama-2-13b, Llama-2-70bを評価した際、7B以外の13B, 70Bにおいては評価スコア上baseモデルの方がchatモデルよりも高いスコアを記録したためです。
また自前で指示チューニングを行なう予定であったため、chatモデルを利用せずとも問題ないとの考えもありました。
詳細学習設定
モデルアーキテクチャは、Llama 2からの継続事前学習であるため同じです。語彙拡張を行っているモデルのみ語彙サイズがデフォルトのLlamaとは異なります。
| モデル名 | hidden_size | FFN hidden_size | num_layers | attention_heads | vocab_size |
|---|---|---|---|---|---|
| Llama-2-7B-hf | 4096 | 11008 | 32 | 32 | 32000 |
| Swallow-7B(語彙拡張なし) | 4096 | 11008 | 32 | 32 | 32000 |
| Swallow-7B(語彙拡張あり) | 4096 | 11008 | 32 | 32 | 43176 |
| Llama-2-13B-hf | 5120 | 13824 | 40 | 40 | 32000 |
| Swallow-13B(語彙拡張あり) | 5120 | 13824 | 40 | 40 | 43176 |
| Llama-2-70B-hf | 8192 | 28672 | 80 | 64(8) | 32000 |
| Swallow-70B(語彙拡張なし) | 8192 | 28672 | 80 | 64(8) | 32000 |
| Swallow-70B(語彙拡張あり) | 8192 | 28672 | 80 | 64(8) | 43176 |
また学習に使用したハイパーパラメータは以下の通りです。
| モデルサイズ | LR_max | LR_min | global batch size | weight_decay | grad_clip |
|---|---|---|---|---|---|
| 7B | 1e-4 | 3.3e-6 | 1024 | 0.1 | 1.0 |
| 13B | 1e-4 | 3.3e-6 | 1024 | 0.1 | 1.0 |
| 70B | 5e-5 | 1.6e-6 | 1024 | 0.1 | 1.0 |
またOptimizerにはAdamWを利用し、
加えて、学習速度向上のためにFlashAttentionを利用しました。
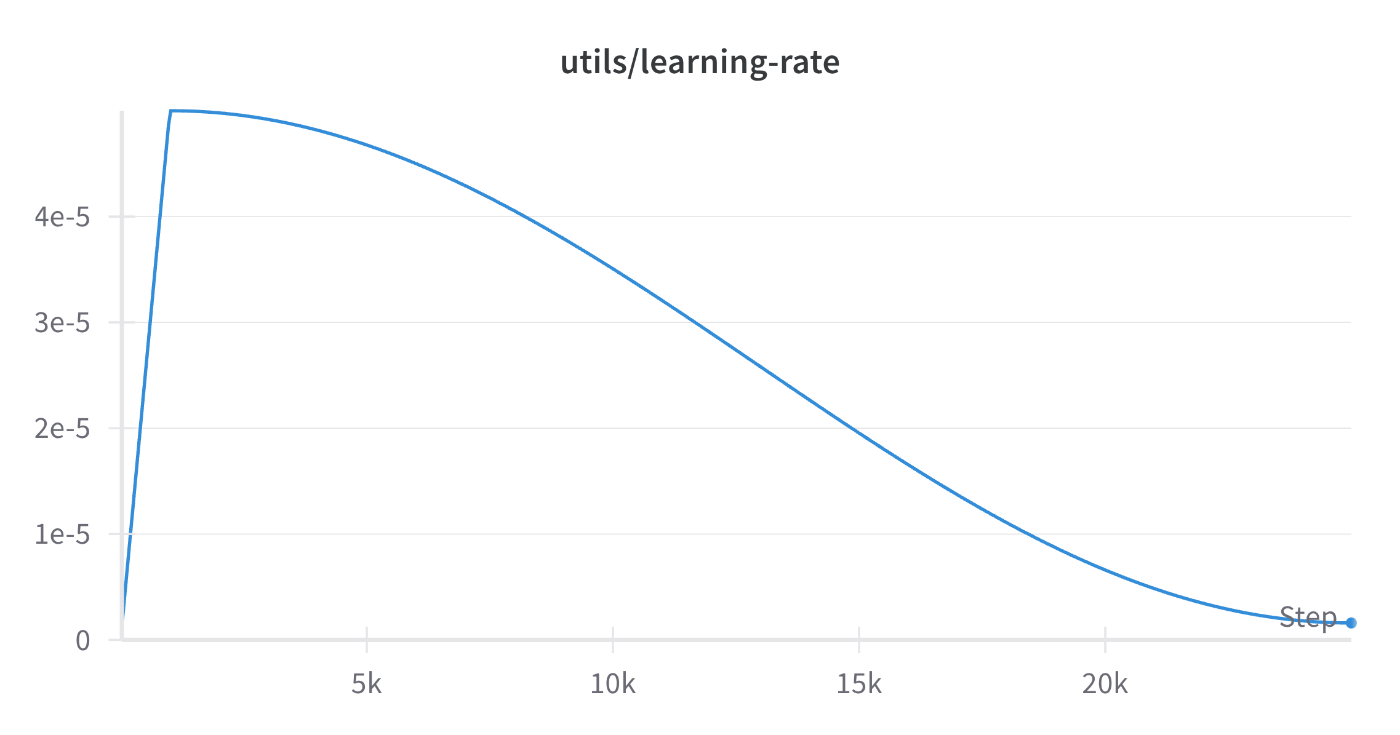
(Swallow-70B(語彙拡張なし)におけるLearning Rateの推移)
また、checkpoint頻度は500iteration毎に指定していたため定期的に不必要なcheckpointを削除しました。参考までにモデルサイズ別のcheckpoint容量を記載します。(分散学習のconfigによっては変化します)
| モデルサイズ | checkpoint容量 |
|---|---|
| 7B | 90GB |
| 13B | 172GB |
| 70B | 900GB |
Activation Checkpointing and Recomputations
すべてのActivationをメモリに保存してbackward時に使用するのではなく、モデル内の特定の"checkpoint"におけるActivationのみをメモリに保持し、その他のActivationはbackwardで必要になったときに再計算を行なうActivation Checkpointingを採用しました。
また今回の実験では、--recompute-granularity "selective"を利用し、必要メモリ量が少ないが再計算コストが高いactivationはメモリに保持し、必要メモリ量が多いが再計算コストが比較的小さいActivationは保存せず再計算を行なう措置をとりました。これにより、メモリ効率化と学習速度の維持を同時に成し遂げました。
ノード不良
学習には、分散学習の都合から60ノードを32ノード、16ノード、8ノード、2ノード、2ノードのように分けてGPUノードを利用しました。このうち32ノード実験においては8回ほどノード不良によりjobをkillしcheckpointから学習を再開する措置を行いました。
LLM-jpのプロジェクトにて175Bモデルを49ノードで学習させていた際ほどGPUの不良に悩まされることはありませんでしたが、それなりに苦労しました。
自動で学習が止まっていることを検知する独自スクリプトを採用していたため、学習を監視する業務からは解放されていましたが、学習を再スタートさせる措置については私が人力で行っていました。
学習管理
学習スケージュルの管理にはGoogle Spreadsheetを利用していました。正確な実験終了時間や、実験開始時間、job投入時間については基本的に自分のカレンダーに予定として記入していました。ABCIのリソースをできる限り有効に使うために、予定表の組み換えや、問題が発生した場合に他の実験に影響が生じた分をモデルの評価jobを専有プロジェクト外で行なうなど対応をお願いをして調整し、後続実験への影響を最小化していました。

実験計画が実験を行っている1ヶ月の間に変更になるなどもありましたが、余分なノードができるだけ発生しないように調整を行いました。
checkpoint convert
Megatron-LMがデフォルトでサポートしているのは以下です。
- HuggingFace形式checkpoint → Megatron形式checkpoint
- Megatron形式checkpointのTP, PP変更
これでは、学習を行う上では問題ないですが、Megatron形式のcheckpointをHuggingFace形式に変換することができません。そこで今回私は、テンソルレベルで完全に変換可能なconvert scriptを作成することとしました。
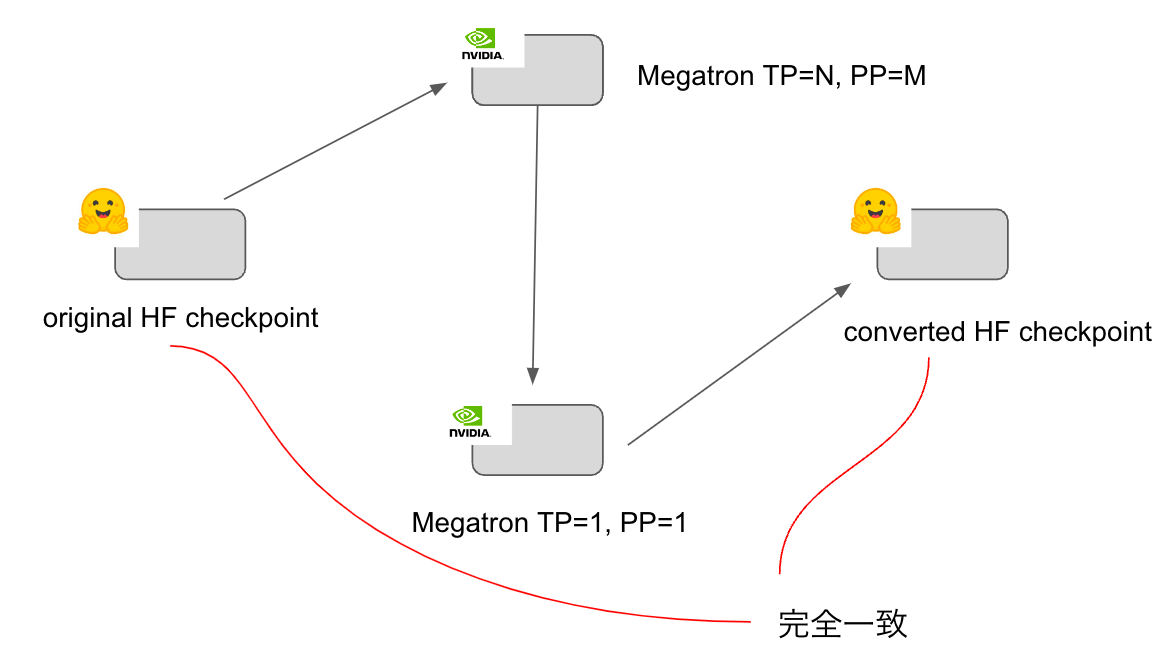
上図のように、HF checkpointをMegatron形式に変換した後に、再度HF checkpointに戻す操作を行ってもテンソルレベルで完全に一致する変換スクリプトを作成することが出来ました。
変換スクリプトの挙動については、7B, 13B, 70Bにて検証を行っており、検証のために専用のスクリプトを作成し、変換スクリプトが正しく動作しているのかについて細部まで検証を行いました。
H100上での性能測定
今回の実験に直接的には関係しませんが、将来的な学習速度向上のために今回使用したMegatron-LMを利用してH100上で速度性能測定を行いました。
結果は以下のようになりました。
| precision | TransformerEngine | TFLOPS |
|---|---|---|
| BF16 | None | 448 |
| BF16 | True | 548 |
lambdalabsのblogにてBF16でTransformerEngineを利用した際に、TransformerEngineを利用していない場合と比較して22%のSpeedupを記録したとあるので今回の測定結果と合致しています。
また、Microsfotの論文にてBF16にてTransformer Engineを利用せずに442TFLOPSを記録したとの報告があるため、我々の測定結果と合致しています。
今後計算資源については、H100が主流となることが予想されるため、現時点で効率的に利用することができると分かったことは今後の研究開発において良い影響を与えることになるかと思います。
おわりに
この記事では、Llama 2から日本語継続事前学習を行いSwallowを開発したことについて説明を行ってきました。我々が学習を行う中で得られた知見や、実際に学習に使用したライブラリのコードの使い方等については次のブログ記事にて、さらに説明する予定です。
また、我々はすでに次の実験を準備しており、計算資源についてもある程度の規模は確保できています。内容についてはこの場で報告できませんが、次に行なう実験で得られたモデルについてもオープンにしていきます。
岡崎研究室、横田研究室では継続学習、大規模モデルを効率的に学習する手法について今後も研究開発を行っていきます。
H100やA100などの計算資源が確保でき次第行いたい実験は多数存在する状況です。計算機環境を提供いただく形での共同研究など、企業、学術組織を問わず共同研究などを積極的に模索しています。
本記事をご覧になり、共同研究などにご関心をお持ちの方は、どうぞ遠慮なくご連絡いただければ幸いです。

Discussion
素晴らしいレポートをありがとうございます! 語彙の拡張前と後を比べて、英語と日本語の全体的な圧縮率はどの程度ですか?