はじめに
東京工業大学 横田研究室の藤井です。
本日(2024/03/11)Mistral-7B-v0.1から約 100B Token継続事前学習を行ったSwallow-MSをリリースさせて頂きました。
本モデルの開発は、産総研、東京工業大学 岡崎研究室、横田研究室の合同プロジェクトにて行われました。公式プロジェクトページはこちらです。
Swallow-MS は高い日本語能力を示すSwallow-7Bを上回り、7Bモデルでありながら、Swallow-13Bに迫る日本語性能を示しました。
リリースモデル
- 日本語継続事前学習済みモデル
本記事では、Swallow-MSモデルについてと、モデル開発の中で得られた知見について紹介します。
また、MoE(Mixture of Expert)モデルのMixtral-8x7B-Instruct-v0.1から約100B Token 継続事前学習を行った、Swallow-MXも同時に公開していますので、以下の記事から詳細をご覧ください。
プロジェクトメンバー
Swallow-MS とは

(Swallow-MS モデルイメージ)
Swallow-MSはMistralの日本語能力を強化した大規模言語モデル(7B)です。Licenseは継続事前学習元のMistralのライセンスであるApache-2.0を継承し、商業利用可能なモデルとなっています。Swallow-MSには、2つの特徴があります。1つ目は、高い日本語性能、2つ目は、数学性能が高いことです。順に説明していきます。
我々がSwallowモデル群でも採用した評価タスク中での平均スコアは以下のようになっており、Mistral社が公開しているモデルよりも高い日本語性能が達成できています。また、昨年2023年12月に公開したSwallow-7Bよりも高い性能を示しており、7BでありながらSwallow-MSモデルはSwallow-13Bモデルに迫る性能を示しています。
| モデル名 | 日本語スコア(NLI除く平均) |
|---|---|
| Swallow-7B | 0.3940 |
| Swallow-13B | 0.4625 |
| Mistral-7B-v0.1 | 0.3725 |
| Swallow-MS(7B) | 0.4532 |
次に、数学性能についてです。
日本語における数学性能はlm-evaluation-harnessのMGSMにより計測しました。
Swallow-MSは、Mistral-7B-v0.1よりも高い数学能力を示し、他のモデルと比較しても高い数学能力を有していることが分かります。
| モデル名 | MGSM |
|---|---|
| Swallow-MS(7B) | 0.2240 |
| Qwen-7B | 0.2160 |
| Mistral-7B-v0.1 | 0.1760 |
| japanese-stablelm-base-gamma-7b | 0.1680 |
| Swallow-7B-plus(語彙拡張あり) | 0.1360 |
| Swallow-7B (語彙拡張あり) | 0.1240 |
| nekomata-7b | 0.1240 |
| Llama-2-7b | 0.0760 |
| Japanese Stable LM Beta 7B (語彙拡張なし) | 0.0720 |
| ELYZA-japanese-Llama-2-7b-fast | 0.0720 |
| youri-7b | 0.0640 |
| ELYZA-japanese-Llama-2-7b (語彙拡張なし) | 0.0600 |
| calm2-7b | 0.0600 |
| Japanese Stable LM Beta 7B (語彙拡張あり) | 0.0520 |
モデル評価
日本語の評価タスクはllm-jp-evalとJP LM Evaluation Harnessから一部を採用しました。
使用しているタスクはSwallow (Llama 2継続事前学習)において採用したタスクと同様です。
性能評価
同規模の他のモデルの比較を以下に示します。
日本語タスクの平均スコアでは、我々が評価した14個のモデルの中で最高の性能をSwallow-MSは示しています。
| モデル名 | 平均 | JCom | JEMHopQA | NIILC | JSQuAD | XL-Sum | MGSM | WMT20-en-ja | WMT20-ja-en |
|---|---|---|---|---|---|---|---|---|---|
| Swallow-MS-7b | 0.4524 | 0.8570 | 0.4915 | 0.5519 | 0.8802 | 0.1988 | 0.2240 | 0.2494 | 0.1667 |
| japanese-stablelm-base-gamma-7b | 0.4301 | 0.7364 | 0.4643 | 0.5568 | 0.8910 | 0.2293 | 0.1680 | 0.2390 | 0.1561 |
| nekomata-7b | 0.4185 | 0.7417 | 0.4928 | 0.5022 | 0.8707 | 0.1676 | 0.1240 | 0.2673 | 0.1815 |
| Swallow-7b-plus(語彙拡張あり) | 0.4090 | 0.5478 | 0.5493 | 0.6030 | 0.8544 | 0.1806 | 0.1360 | 0.2568 | 0.1441 |
| Swallow-7b(語彙拡張あり) | 0.3940 | 0.4808 | 0.5078 | 00.5968 | 0.8573 | 0.1830 | 0.1240 | 0.2510 | 0.1511 |
| youri-7b | 0.3768 | 0.4620 | 0.4776 | 0.4999 | 0.8506 | 0.1957 | 0.0640 | 0.2671 | 0.1971 |
| Qwen-7B | 0.3742 | 0.7712 | 0.4234 | 0.2376 | 0.8594 | 0.1371 | 0.2160 | 0.1689 | 0.1801 |
| Mistral-7b-v0.1 | 0.3717 | 0.7301 | 0.4245 | 0.2722 | 0.8563 | 0.2006 | 0.1760 | 0.1405 | 0.1733 |
| ELYZA-japanese-Llama-2-7b (語彙拡張なし) | 0.3467 | 0.5791 | 0.4703 | 0.4019 | 0.8226 | 0.1312 | 0.0600 | 0.1795 | 0.1289 |
| Japanese Stable LM Beta 7B (base, 語彙拡張なし) | 0.3366 | 0.3610 | 0.4478 | 0.4432 | 0.8318 | 0.2195 | 0.0720 | 0.1946 | 0.1226 |
| ELYZA-japanese-Llama-2-7b-fast | 0.3312 | 0.5308 | 0.4330 | 0.3898 | 0.8131 | 0.1289 | 0.0720 | 0.1678 | 0.1143 |
| Llama-2-7b | 0.3201 | 0.3852 | 0.4240 | 0.3410 | 0.7917 | 0.1905 | 0.0760 | 0.1783 | 0.1738 |
| calm2-7b | 0.3098 | 0.2198 | 0.5047 | 0.5066 | 0.7799 | 0.0233 | 0.0600 | 0.2345 | 0.1499 |
| Japanese Stable LM Beta 7B (base, 語彙拡張あり) | 0.2937 | 0.2172 | 0.4482 | 0.4309 | 0.8202 | 0.0757 | 0.0520 | 0.1601 | 0.1453 |
学習ライブラリ
今回の学習には、独自に開発したllm-recipesと呼ばれるライブラリを利用しました。こちらのライブラリは、私が開発していたkotoba-recipesを元に本Swallow Project用に微調整を行ったライブラリです。
主な特徴としては以下が挙げられます。
- HuggingFace Transformers の
from_pretrained()で呼び出せるモデルであれば、すべてのモデル(denseに限る)を継続事前学習することができる - 指示チューニング、継続事前学習両方に対応している
- PyTorch FSDPにより30B未満のモデルサイズであれば、高速に学習可能
このような特徴をもったllm-recipesを利用し、Swallow-MSの継続事前学習を行いました。
Megatron-LM、Megatron-DeepSpeed、gpt-neoxなどのライブラリではなく、独自開発のライブラリを利用したのには以下のような背景があります。
- 次々に公開されるモデルのたびに、ライブラリに変更を加えて対応を行っていると、実装コストが非常にかかる
- 3D Parallelismを利用するまでもない規模のモデルサイズの場合に、手軽に学習を始められるライブラリの必要性がある
特に、1の問題意識は深刻であり、これを解決する必要性を感じていたため、独自ライブラリの開発に踏み切りました。
学習ライブラリを開発する際にハマった点
こちらのDiscussionにあるように、HuggingFaceではモデル側でinput_idsとlabelsをshiftさせる措置が行われています。そのため、Megatron-LMなどのライブラリと同様にDataLoader側でshiftする処理を書いてしまうと余分にshiftしてしまうことになり、Next Token Predictionができなくなってしまいます。

Loss自体はこのミスがあっても問題なく下がるため、発見が遅れました。
分散学習設定
Swallow-MSは7Bであり、モデルサイズが大きくないこともあり、学習速度の点でFSDP FULL_SHARDを利用しても大きな速度低下はないため、FSDP FULL_SHARDを利用しました。
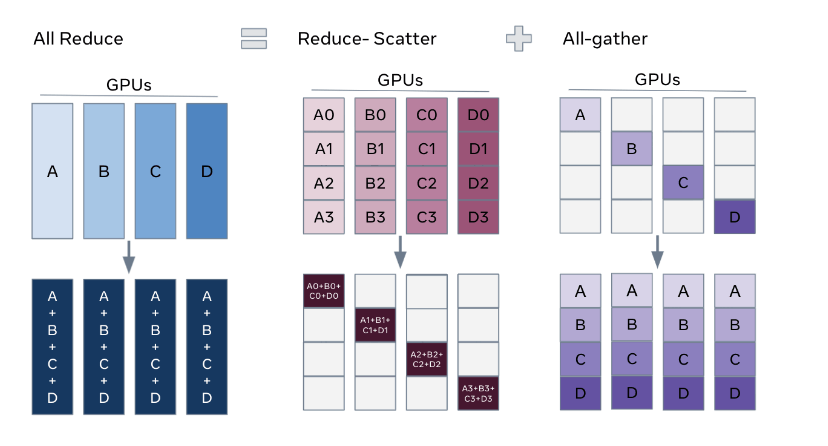
(PyTorch Docsより)
FULL SHRADでは、通常のDP(データ並列: Data Parallel)と比べ、Forward時に必要なパラメーターをAll-gatherする必要があるので全体の通信量としては1.5倍になりますが、大きくメモリ消費量を削減することができる分散手法です。
学習
Swallow-MSは、語彙拡張を行っているモデルです。そのため、vocab sizeは以下のように増加しています。
| モデル名 | vcaob size |
|---|---|
| Mistral-7b-v0.1 | 32,000 |
| Swallow-MS | 42880 |
また学習に使用したハイパーパラメータは以下のとおりです。
| モデル名 | LR | min LR | global batch size | weight decay | gradient clipping |
|---|---|---|---|---|---|
| Swallow-MS | 2.0E-5 | 6.7E-5 | 1024 | 0.1 | 1.0 |
またOptimizerにはAdamWを利用し、
加えて、学習速度向上のために FlashAttentionを利用しました。
(Learning Rateの推移)
上記のハイパーパラメータにて、Swallow Corpus、日本語WikipediaとAlgebraicStack、RefinedWeb、Pile arXivを混合したデータを用いて学習を行いました。学習時のLossの推移は以下のようになりました。
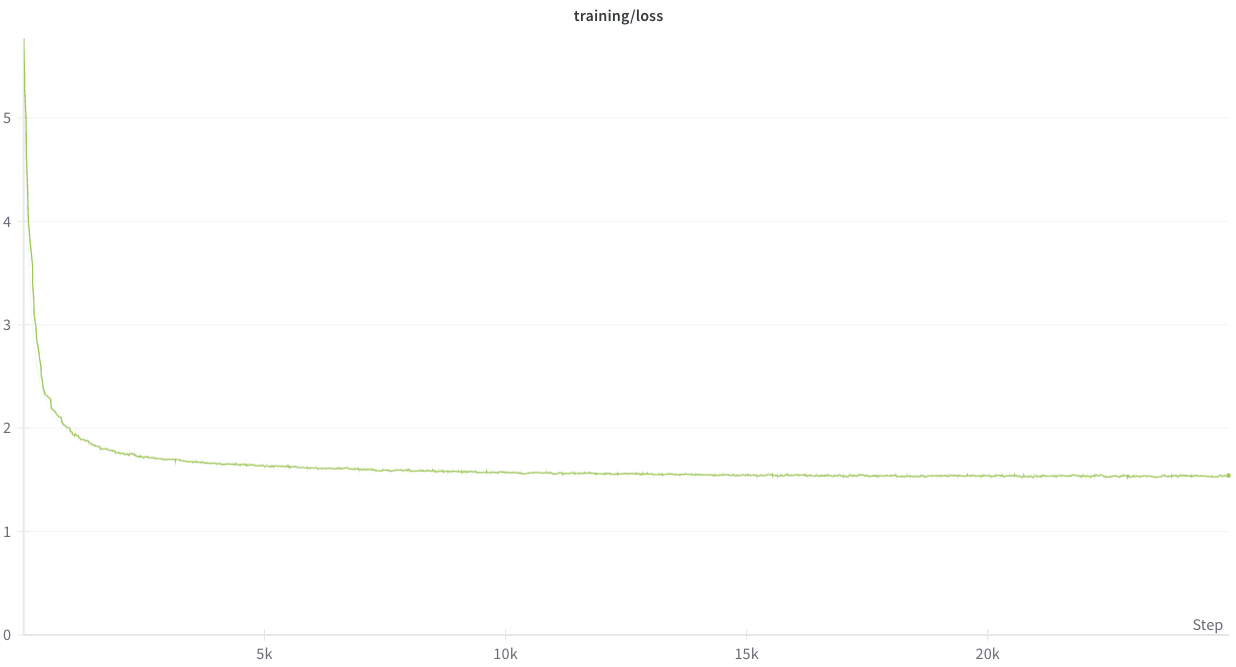
また、checkpoint頻度は500iteration毎に指定していました。
参考までにcheckpoint容量を示します。
14G model.pt
28G optimizer.pt
16K rng.pt
4.0K scheduler.pt
学習データセット
Swallow-MSの学習には以下のデータセットを利用しました。
-
Swallow Corpus
学習率に対する敏感性
Swallowモデルを学習する際は、Meta社がLlama 2の学習に使用した学習率から、継続事前学習で利用する学習率を決定し、予備実験を通して学習が安定する学習率を探索しました。しかし、Mistralの場合は、Mistral 7BのTech ReportにLearning Rateに関する記載がないため、学習率として参考にするべき値がありませんでした。そこで、とりあえず、同じ7BのモデルであるLlama-2-7bを継続事前学習する際に利用した学習率であるLR=1E-4を利用して予備実験等を行いました。

(LR=1.0E-4 日本語+英語コーパスでの学習Loss)
日本語と英語による多言語コーパスにて学習を行ったところ、Loss Spikeはありましたが、きちんと学習することができました。一見問題なく学習できていそうですが、評価してみると以下の問題が明らかになりました。
- 英語スコア(平均)が25,000iteration学習した後も0.5218 -> 0.3543 と大きく低下してしまっている。
- MGSM(日本語)が0.1800 -> 01480 と低下してしまっている。
また、データセットにAlgebraicStackを追加して学習してみると以下のようになり、学習を継続することが難しいほどのLoss Spikeに見舞われました。
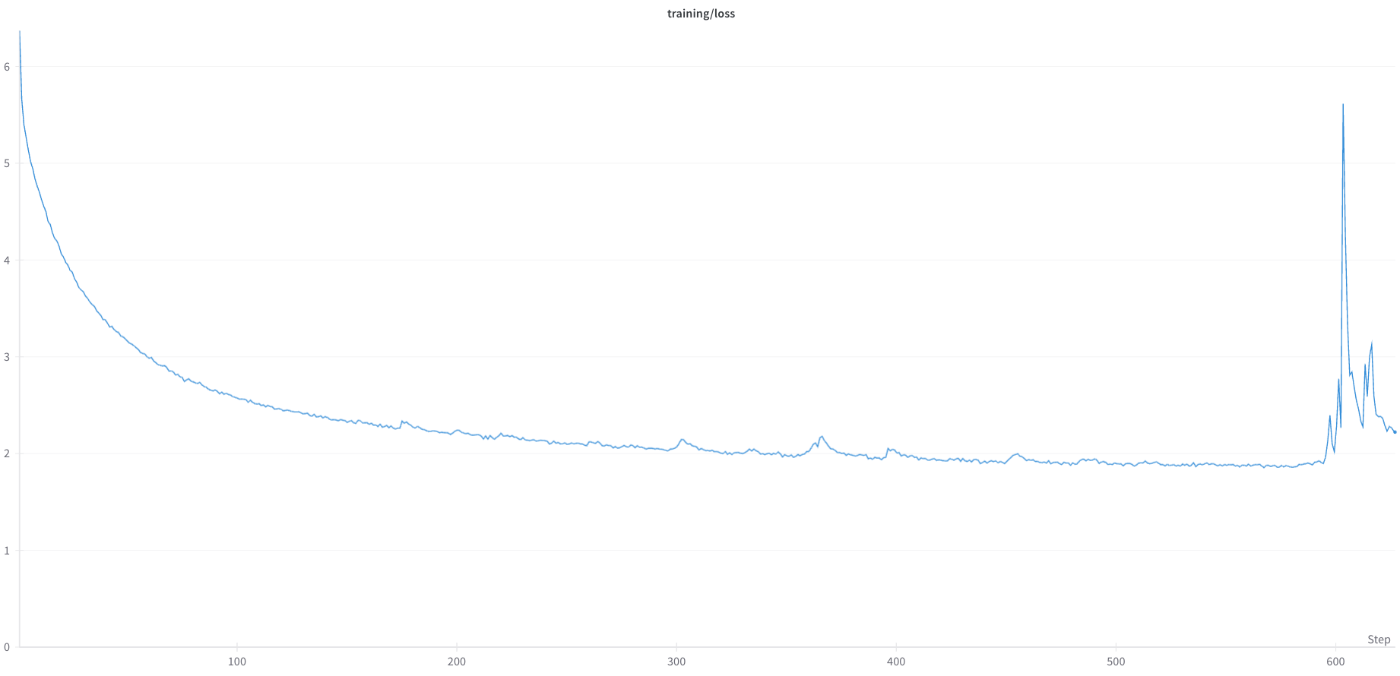
(多言語コーパス+AlgebraicStackにてLR=1.0E-4にて学習した結果)
これらの結果を受けて、Lossだけでなく2,000iteration学習した際のcheckpointにて評価を行い、最適な学習率を探索することにしました。(学習率以外にも、warmingup iterationを増やすなどの探索も行いました。)
学習率が2,000iteration学習時における性能に与える影響はかなり大きく,
以下のようになりました。
| モデル名 | LR | min LR | 日本語(NLI除く) | 英語 | MGSM(日本語) |
|---|---|---|---|---|---|
| Mistral-7b-v0.1 | - | - | 0.3725 | 0.5599 | 0.1800 |
| 実験1 | 1.0E-4 | 3.3E-6 | 0.3375 | 0.3600 | 0.0880 |
| 実験2 | 1.0E-6 | 1E-6 | 0.2182 | 0.5499 | 0.0480 |
| 実験3 | 2.0E-5 | 6.6E-7 | 0.4044 | 0.5208 | 0.1600 |
| 実験4 | 6.0E-5 | 2.0E-6 | 0.3804 | 0.4268 | 0.1160 |
この結果から、LR=1.0E-4にした際の英語スコアの低下は学習初期に発生していること、そして、学習率を変更することである程度、英語スコアの低下は低減されることが分かりました。
今後の研究
Swallowプロジェクトは、今後も研究を続けていきます。今回のSwallow-MSに関係するテーマですと、以下のような課題があります。
- Mistralの高い数学能力、コード生成能力をどのようにして日本語に転移させるのか
今回の実験では、計算資源等の兼ね合いで、MGSMスコアの改善要因が学習データにあるのか、それともLRを含めたハイパーパラメータにあるのかの切り分けができませんでした。まず、その点について実験を行う必要があります。また、どのようなコーパスが数学能力の向上につながるのかといったデータセット面の調査についても網羅性が足りていません。 - 一般に数学能力とコード生成能力は相関するとの言説がありますが、継続事前学習において、同様のことが言えるのかの検証が必要です。
また、上記の課題に取り組むだけでなくSwallow Projectでは、大規模言語モデルを効率的に学習する方法について今後も研究を行っていきます。
Swallow Projectでは、学習したモデル、学習知見を今後も公開していきます。

Discussion