E資格メモ
強化学習
DQN
- CNNを用いて行動価値関数を推定する
経験再生 (experience replay)
- エージェントの経験をデータ集合Dに蓄積する
- このデータ集合Dから取り出したものを再生記憶(replay memory)
- 利点 (通常のオンラインQ学習と比較して)
- パラメータの更新時に、同じ経験を何回も使える→計算量の大きなエピソードの進行の回数を抑制
- 更新の分散を軽減できる
- 過去の様々な状態で行動分布が平均化されるため、直前に取得したデータが次の行動の決定に及ぼす影響を軽減できる
- これにより、パラメータの振動やパラメータの発散を避ける
目標Qネットワークの固定
- 課題
- 学習の目標値算出に用いるネットワークと、行動価値Qの推定に用いるネットワークが同じ場合、行動価値観数を更新すると目標値も変化してしまい、学習が不安定 ▶︎Qネットワークの固定
- 概要
- 目標値の算出に用いるQネットワークの固定し、一定周期でこれを更新することで学習を安定
- 固定されるパラメータ「θ-」
報酬のクリッピング
- 報酬の値を {-1,0,1} の3値に制限すること
- これにより「報酬のスケールが与えられたタスクによって大きく異なる」という問題解決
- ゲームごとに学習率を調整することがなくなった



A3C

モデルベース
- 環境モデルが既知 (実際にこれがわかっているのは稀)
- 例) AlphaGo
モデルフリー
-
環境モデルを明示的に学習せず、試行錯誤
-
モデルフリー
- 手法
-
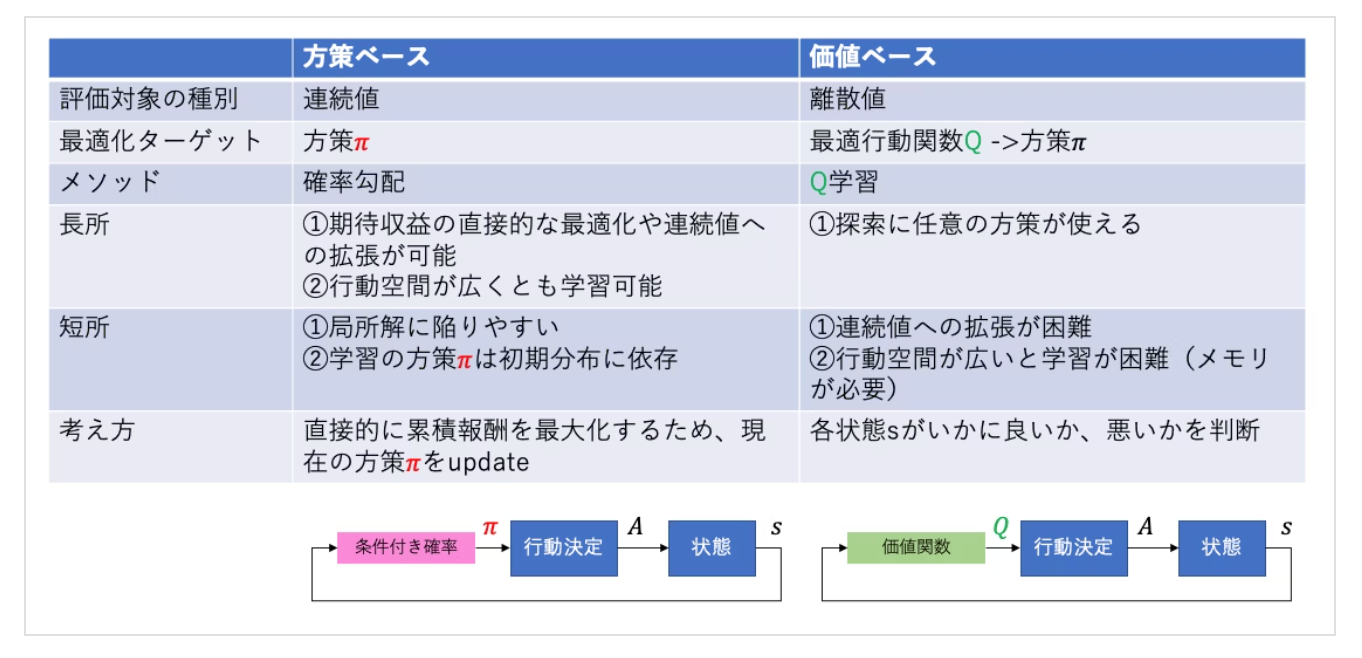
価値ベース
- 期待累積報酬を表す価値関数を最適化することで、最適な方策を間接的に求める
- 例) DQN
- 期待累積報酬を表す価値関数を最適化することで、最適な方策を間接的に求める
-
方策ベース
- エージェントは行動を選択する確率分布(方策)を直接最適化
- 例) A3C
- エージェントは行動を選択する確率分布(方策)を直接最適化
-
価値ベース
- 手法
状態価値関数・行動価値関数



Snext : 遷移確率
S : 状態
a : 行動
-
状態価値関数
- 状態 s から開始して、その後の方策 π に従って行動した場合に得られる累積報酬の期待値
- ある状態 s がどれだけ良い状態であるかを表す指標
-
行動価値関数
- 状態 s において行動 a を選択し、その後の方策 π に従って行動した場合に得られる累積報酬の期待値
- ある状態 s において行動 a を選択することがどれだけ良いかを表す指標
方策オン型→ SARSA (学習安定、サンプル効率X)
- 概要
- ある方策に従って行動を選択し、その選択に基づいて行動価値関数を更新
- メリット
- 学習過程で生じる予期せぬ変動が少なく、学習が安定する傾向にある
- デメリット
- サンプル効率が低い
SARSA 実際の行動に基づいて学習 (on-policy)
- SARSAは、各状態において特定のアクションを実行した際の期待報酬(Q値)を更新していくことで学習
- Q値の更新には、現在の状態、行動、報酬、次の状態、そして次の行動の5つの要素
- 実際の行動に基づいて学習するため、慎重な行動戦略を学習しやすい傾向があある
- SARSAは実際に行動した結果のみ学習に利用するため、想定外の行動によるQ値の急激な変化が起きにくい事が考えられます
- 方策オン型なので、「行動を決定する方策」と「行動価値関数の更新に利用する方策」は同じ
Q(s, a) ← Q(s, a) + α [r + Q(s_next, a_next) - Q(s, a)]
方策オフ型 → Q学習 (学習不安定)
- 概要
- 行動価値関数の更新についてはその状態における最大の行動価値関数を用いて行う
- メリット
- どのような方策であっても最適な行動価値関数を推定
- デメリット
- 学習が不安定
Q学習 (off-policy)
-
Q学習は、エージェントが実際に実行している行動(ポリシー)とは異なる、最適な行動を想定して学習を進めます。つまり、学習中に得られた経験を、必ずしも今後の行動に直接反映されない
-
SARSAより行動価値関数の収束早い
-
方策オフ型なので、「行動を決定する方策」と「行動価値関数の更新に利用する方策」異なる
-
行動価値関数を更新する際、行動価値の小さい探索結果は反映されにくい傾向
-
SARSAと違い、行動価値関数Qの更新が行動の決定方法に依存しない
-
流れ
- STEP0 : 方策πとθ^*の初期化
- STEP1 : データ集め、方策πに従ってs,a,r,s' のデータを集める
- STEP2 : 方策評価
- STEP3 : 方策更新
Q(s, a) ← Q(s, a) + α [r + Q(s_next, a_max) - Q(s, a)]

経験再生を適用

Q固定ネットワーク適用
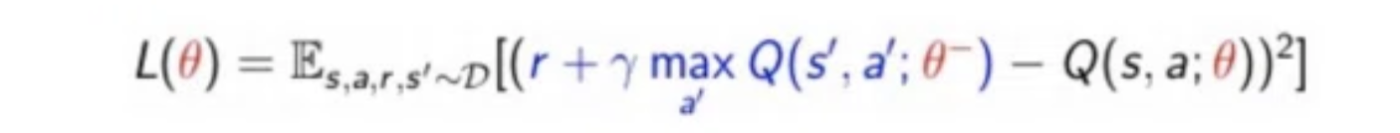
DQN
- 技術のキモ
-
経験再生
- 過去の経験を保存し、ランダムにサンプリングして学習に使用するテクニック
- 経験間の相関性を打破し、学習の安定性を向上させる
-
固定Qターゲット
- 一定の間隔でTDターゲットの部分を固定することで、学習を安定させることができる
-
報酬のクリッピング
- 報酬のスケールが異なるタスク間でも同じネットワークを使用して学習を行うことが可能
-
経験再生
TD法
-
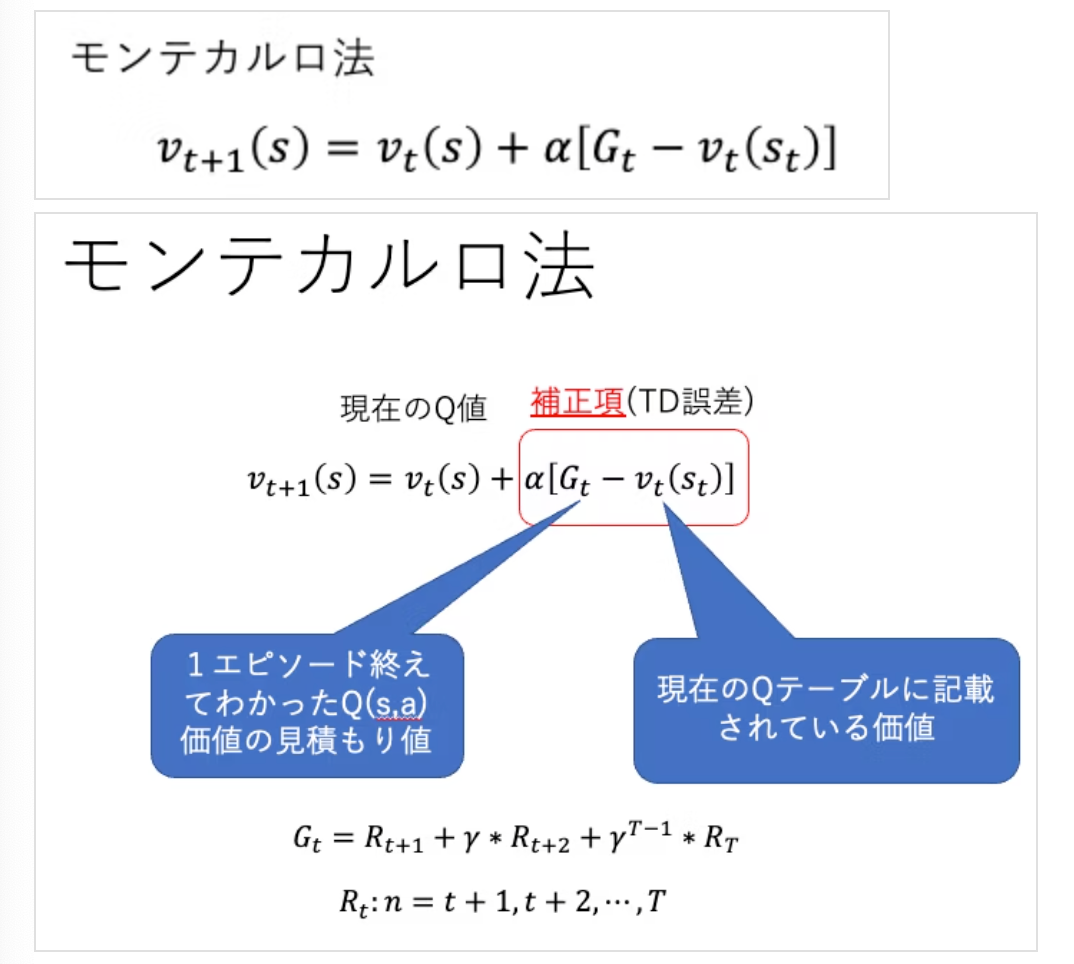
行動価値関数の更新→以前は、モンテカルロ法
- 課題) エピソードが終了するまで価値関数の更新を行わないため、更新頻度が低く、学習の収束が遅い
- 改善策→TD法
- 課題) エピソードが終了するまで価値関数の更新を行わないため、更新頻度が低く、学習の収束が遅い
-
TD法
- 強化学習において、ある状態や行動の価値を、次の状態や行動の価値を使って推定する手法
- 優れている点
- モデルフリー: 環境のモデル(状態遷移確率)を知らなくても学習できる
- オンライン学習: エピソードの最後まで待たずに、途中で価値関数を更新できる
Actor-Critic (方策ベース+価値ベース) 1990
-
概要
- 方策ベースでエージェントの行動を制御する「Actor」と、価値ベースで行動の価値を評価する「Critic」を組み合わせている
- Actorが良い行動を学ぶ一方、Criticがその行動の価値を評価することで、方策ベースの手法の高い表現力と価値ベースの手法の安定性を兼ね備えている
-
詳細
- Actor
- 方策をパラメータ化し、与えられた状態に対して行動を選択する方策ベースの手法で、エージェントの行動を制御
- Critic
- 価値行動関数を近似し、与えられた状態と行動の組み合わせに対してその価値を評価
- Actor
-
ベースライン関数
- 報酬の分散を低減し、学習の安定性を向上させるために用いられる
A3C (方策ベース) 2016 DeepMind
- 概要
- Actor-Criticを基にした方策ベースの手法
-
非同期での方策パラメータ更新
- 複数のエージェントがそれぞれ異なる環境で独立に行動し、それぞれの経験に基づいて方策のパラメータを更新する
- 非同期学習によって経験間の相関性による学習効率の低下を緩和
-
アドバンテージ関数の使用
- →行動の価値を直接的に評価し、方策の更新においてどの行動が平均的な行動よりも優れているかを判断するのに役立つ
方策勾配法・方策勾配定理
-
方策勾配法
- MLにおける勾配降下法を活用して、方策πを確率的勾配法に基づいて直接学習する手法
- 方策をパラメータθを用いて表現し、RLにおける目的関数 J(θ)を最大にするようにパラメータを求める
-
方策勾配定理
- 方策勾配法において勾配を計算する基盤となるもの
メモ
- モデルベース(環境モデル(状態遷移確率p(s’|s,a)、報酬関数r(s,a,s’))を使用する)
- 環境モデルが既知
- DP法
- 方策反復法
- 価値反復法
- モデルフリー(環境モデル(状態遷移確率p(s’|s,a)、報酬関数r(s,a,s’))を使用しない)
- <価値ベースの手法>
- モンテカルロ法
- TD法 (Temporal Difference)
- SARSA
- Q-learning
- DQN
- 経験再生(Experience Replay)
- ターゲットネットワーク(Target Network)
- 固定Qターゲット
- DQN
- <方策ベースの手法>(価値関数を経由に直接方策を求める)
- 方策勾配法
- REINFORCE
- ベースライン付き方策勾配法
- A3C,A2C ((Asynchronous) Advantage Actor-Critic)
- DDPG
- <価値ベース+方策ベースの手法>
- Actor-Critic
アクセラレータ (デバイスにより高速化)
-
CPU
- 採用) MIMD
-
GPU/GPGPU
- 採用) SIMD, SIMT
-
SIMD(Single Instruction Multiple Data)シムディー、シムド 複数データ
- 単一の命令形で複数のデータを処理する
並列計算の一種 - これにより、GPUやベクトルプロセッサは同一の操作を大量のデータに対して同時に行うことが可能
- 単一の命令形で複数のデータを処理する
-
SIMT(Single Instruction Multiple Thread) 複数スレッド
- NVIDIA独自(というか提案?)のアーキテクチャ。
SIMDの改善。 単一の命令を 複数のスレッド に対して同時に適用する処理方法- 32本のスレッド(1 Warp)に対して1つのインストラクションを1度に実行する
- NVIDIA独自(というか提案?)のアーキテクチャ。
-
MIMD(Multiple Instruction Multiple Data)ミムディー
- 複数の命令列で複数のデータを処理する
- CPUの並列計算手法
- 各プロセッサが異なるデータに対して異なる命令を実行することが可能
-
GPU (Graphics Processing Unit)
- 単純な並列計算を得意としますが、複雑な計算は苦手なのでCPUのような幅広い処理には向いていません。CPUは汎用的な用途で、GPUは並列計算に特化した用途で用いるのが効率的であるため、GPUはCPUと組み合わせて使用することが一般的
- 一般的な計算タスクもできるように設計されている
- CPUに比べて、GPUはコア当たりの計算能力は低い
- GPUのコアは、それぞれ独立に制御することはできない
- 高速なメモリアクセス→「オンメモリチップ」
- オンメモリチップ : プロセッサ内部に組み込まれた高速なメモリ
- 必ずしも精度を16bitの浮動小数点に落とす必要はない
-
GPGPU (General Purpose GPU)
- これまで3Dグラフィックのみに使われてきたGPUを一般的な用途(General Purpose)にも利用しようというプログラミング手法
-
TPU (Tensor Processing Unit)
- Googleが独自に開発したNPUのことで、機械学習における大規模な行列演算を得意
- DL向けのASCI (Application Specific Integrated Circuit)
- 大量にコアを持つことで並列計算能力が高い
- SIMDを採用
-
NPU (Neural network Processing Unit)
- 機械学習のニューラルネットワーク処理に特化したプロセッサ
-
MXU (Matrix Multiply Unit)
- TPUの主要部分で、行列の乗算と畳み込みを高速に行う
- MXUの存在はTPUの演算処理を大幅に向上
-
VMU (Vector Multiply Unit)
- ベクトル乗算ユニットは、コンピュータのCPU(中央処理装置)やGPU(グラフィックス処理装置)に搭載される、SIMD(Single Instruction, Multiple Data:単一命令、複数データ)演算を高速に行うためのハードウェア
Disk I/O
- ディスクへのデータの読み書きを指す用語で、コンピュータ全体の処理速度に影響を与える
開発
仮想化

-
仮想化技術
- ハードウェア仮想化
-
ホスト型 (ゲストOS, ホストOS)- HWにホストOSをインストールし、その上で仮想化SWを実行
- 既存のOSをホストOSとして利用すればすぐに仮想環境を構築することができる利点
- HWを制御する際にはホストOS経由なのでオーバーヘッド大きくなる
-
ハイパーバイザー型(ゲストOS)- 物理サーバーにハイパーバイザーと呼ばれる仮想化PFを直接インストール
- ホストOS存在しない
- ▶︎仮想マシン上にゲストOSをインストールし、通常のサーバーと同じようにアプリを稼働できる
-
- OSレベル仮想化
-
コンテナ型(ホストOS)- ホストOSのカーネルを共有
- ホストOS機能を活用しアプリケーション実行環境を分割することで、各アプリケーションに隔離された環境を提供
- ホストOS上に複数の「隔離環境」を構築
-
- ハードウェア仮想化
-
オーバーヘッド
- コンテナ < ハイパーバイザー < ホスト
Docker
- Docker daemon
- Dockerコマンドを受信し実行するSW
- Docker client
- ユーザーがDockerと情報をやり取りするための主要なインターフェース
分散並列学習(Distributed Parallel Training)
- 大量のデータや大規模なモデルを効率的に学習するために編み出された手法
- 複数の計算リソースを用いて、学習プロセスを分割し、並列化・分散化
- ノード
- 1 nodeに8 GPUもしくは4 GPUを搭載すること多い
データ並列化 (Data Parallel)
- モデルの複製をそれぞれのGPUが持つことで、学習を高速化
-
グローバルバッチサイズを大きくすることで学習時間を短縮することを目的とした並列化手法
- グローバルバッチ : 分散学習環境全体で一度に処理されるデータ量
- ローカルバッチ : それぞれのGPUで一度に処理するデータ量
- 割り当てられたデータセットをそれぞれ学習、誤差逆伝播の後に、モデルの勾配をGPU間で共有することで同期
パラメータ更新方法 (同期・非同期)
- パラメータ更新方法
-
同期型- 全てのワーカの順伝搬及び逆伝搬が終わるのを待つ
- 陳腐化された勾配問題 (stale gradient)は発生しない
- スループット低い
- GPU間に性能の差があると性能の遅いGPUに更新時間が依存するため無駄
-
非同期型- 他のワーカを待たなくて良い
- スループット高い
- 古いモデルの勾配で更新することがあり得るので学習が不安定になる
- GNMTはこっち⭐️
-
モデル並列化 (Model Parallel)
- 概要
- モデルを分割して複数GPUに分散させることで1つのGPUでは収まりきらないモデルを学習
- 通信コストが処理時間短縮を目指す際のボトルネック
- どのようなモデル分割が良いかはモデル依存
- 手法
- Tensor Parallel
- Pipeline Parallel
https://zenn.dev/turing_motors/articles/0e6e2baf72ebbc
Tips
- 計算能力とメモリ容量が限られている場合、モデル並列化もデータ並列化も特に有効ではなく、大規模なモデルではモデル並列化が有効
L1正則化
- Lasso回帰
- L2より特徴量選択に適している
- いくつかのパラメータを0にするスパース表現
- モデルの重みの値を制約することで過学習を防ぐのに使用される
- 極端な値の重みは過学習の原因となりやすいため、損失関数に重みの絶対値の総和を加算することで、重みの値を一定範囲内に収めやすくする効果ある
L2正則化
- Ridge回帰
- MLでは、weight decay, 回帰では、リッジ回帰 や ティホノフ正規化として知られている
- 最適化関数SGDとAdamの違いにより、L2正則化の効果異なる時ある
- Adamでは、学習率の自動調整が行われるためL2正則化による減衰が意図した値にならない
陰的正則化→パラメータに間接的に制約を課す正則化の総称
- 械学習モデルの学習において、明示的な正則化手法 : 陽的正則化(例えばL1正則化やL2正則化)を用いなくても、モデルの学習過程そのものに自然と過学習を抑制する効果が現れる現象を指す
- 例
- 陰的正則化 : 早期停止
Dropout ▶︎ NNの過剰適合を抑える
- バッチ正規化層の前にドロップアウトを適用すると、学習中の不安定さや性能の低下が生じる可能性あり
- 一般的にはバッチ正規化の後にドロップアウトを適用
- p = 1 - dropout_ratio : 各ユニットは確率pで存在している
DropConnect (2013)
- ノードの不活性化させるのではなく、代わりにノード間の結合をランダムに切る
- 全結合層の重みをランダムに0にする
- 一定の割合でネットワークを断ち切る(重み行列の要素をランダムにゼロにする)ことで過剰適合を抑制する
- 学習時のみに使用される、推論時にはdropconnectを無効化し、学習時とは異なる全ての重みを使用して処理を行う

Batch Norm→「NN訓練を安定化させ高速化するテクニック」


- 概要
- 学習時に用いた系列データより長い系列データがテストに出てきたとき対応できない
- データをより均一に処理するために平均や分散といった統計量を用いてデータを正規化
- PyTorchにおける
track_running_stats パラメータによって、推論時に使用される統計量が下記2つ- 入力データのバッチごとの統計量
- 学習中に計算された移動平均および移動分散
- PyTorchにおける
- 高さ、幅、バッチの平均・分散をとる
- Conv-Reluの出力である特徴マップのうち、kチャンネル目の出力のそれぞれについて ch毎に正規化された固定分布を求めたい
- 正規化するだけだと、全チャンネルが同じ分布になってしまい、CNNの表現力が落ちる
- ▶︎ スケーリング・シフトも行うことでバッチ正規化層挿入前の変換を保つ y = rx + β
- テスト時に用いる平均と分散は、不偏推定値を用いるべきだが、実装の都合上移動平均を用いることも考えられる
- ミニバッチごとのデータ数が極めて少ない場合にも適していない⭐️
- 特徴
- 学習を速く進行させられる = 学習率を大きくできる
- 初期値にそれほど依存しない
- 過剰適合を抑制 = Dropoutなどの必要性を減らす
- 欠点
- ミニバッチが小さいと推定される平均・分散が正確ではなくなり学習が安定しない
Layer Norm
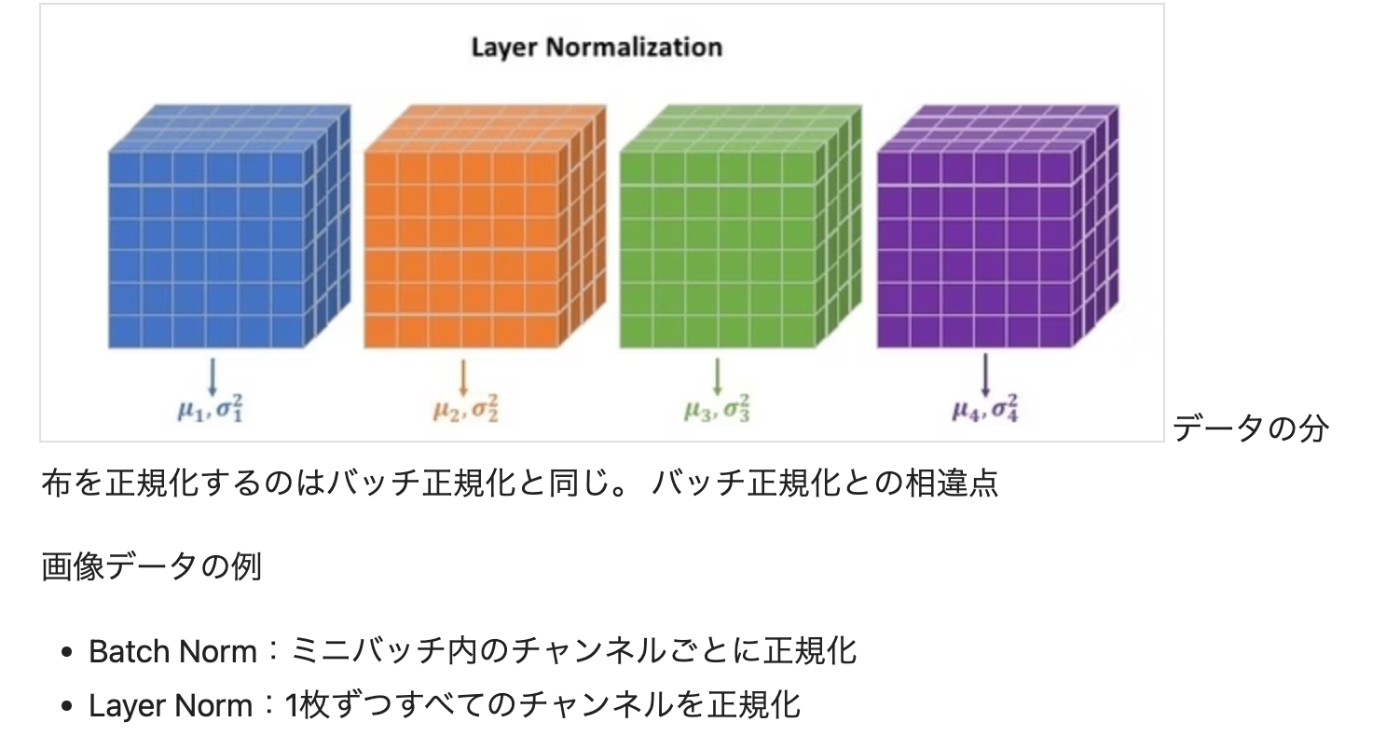
- 概要
- 1つのデータに対して全てのチャネルの平均と分散も求める手法
バッチ正規化の欠点である「ミニバッチサイズに依存する」こと、「系列データへの対応が難しい」を改善したもの- RNN系のモデルに対して有効
- 学習の初期段階での不安定さが解消され、学習速度が向上
- バッチサイズが小さい場合でも安定して学習できるため、メモリ効率も良い
- デメリット
- 平均と分散をチャネル全体で考慮するため、各チャネルの部分的な情報を保持しにくい
Instance Norm
- 概要
- データの各特徴量における平均0, 分散1
- 各チャネルの関係を捉えることができない
- インスタンス正規化は、画像全体の統計量ではなく、各チャンネル(色成分)ごとの統計量に基づいて正規化を行うため、画像全体のコントラスト情報を除去することができる
- その結果、スタイル転送後の合成画像のコントラストは、コンテンツ画像のコントラストに依存せず、スタイル画像のコントラストがより強く反映されるようになりました。
- つまり、コンテンツ画像のコントラストに関係なく、常に一定のコントラストでスタイル転送を行うことが可能になったのです。
-
- contrast norm (コントラスト正規化)とも呼ばれる
- 2016に Style Transfer(スタイル転送) の仕組みの一部として提案された
-
Style Transfer(スタイル転送)
- 画⾵を変換するアルゴリズムのこと
- 2枚の画像を⼊⼒として,⽚⽅をコンテンツ画像,⽚⽅をスタイ
ル画像とする
- スタイル転送がインスタンス正規化を導入した理由
- スタイル転送の出力が、合成画像のコントラストはコンテント画像のコントラストに依存していないように見えたから
-
Style Transfer(スタイル転送)
- コントラストなどのスタイルはcontent imageではなくstyle imageで決めるべきと言う考え方
- Content imageはコントラストの情報は捨てるべきという考え方
- Batch Normの場合、コントラストが強い画像1枚を取り出してみても、正規化後の分散は1よりも大きくなり、正規化後もコントラストが強くなる
- Instance Normはサンプル毎に計算するから、他に影響しない
- 用語
- コンテキスト画像 : 構造・内容
- スタイル画像 : 画風
- コントラスト正規化
- 画像のコントラスト(明暗の差)を調整する処理
AdaIN (Adaptive Instance Normalization) 適応的インスタンス正規化
- コンテンツ画像とスタイル画像の間で適応的に調整を行う機能が、Instance 正規化に追加されたもの
- リアルタイムで任意のstyle transferを可能にするAdaptive instance normalizationという手法を開発
- コンテンツ画像に対するスタイルの様々なコントロールが可能に
Group Norm
- 概要
- レイヤー正規化とインスタンス正規化の中間に位置する
- 1つのデータと部分的なチャネルに対して平均分散を求める
- もともとのチャネル数が少ない場合は、グループ正規化としての効果が薄れる
CNN
-
受容野
- ある刺激が特定の神経細胞や受容器によって感知される範囲
- CNNにおいては、入力層に近い層ではエッジやブロブなどの単純な情報が抽出されるが、層が深くなるにしたがって、テクスチャ、物体のパーツ、最終層では物体クラスと高度な情報が抽出
- 浅い層は、エッジやテクスチャといったシンプルな点に反応
- 深い層は、複雑な特徴や物体全体の形状に反応する
-
単純型細胞
- 入力パターンの変化に敏感であり、画像の特徴抽出を行う
-
複雑型細胞
- 単純型細胞で抽出された特徴の位置感度を低下させることで、受容野内の物体の位置がわずかに移動しても同じ物体と認識できる
-
畳み込み
- 入力中に同じ特徴が複数箇所生じる場合にも有効
- 同じ重みを使い回すことをパラメータ共有または重み共有といい、これは全結合層に比べてメモリ効率が良い
-
畳み込みの等価性 = 以下の2つの処理結果が一致
- 平行移動の後に畳み込みをする
- 畳み込みの後に平行移動をする
-
等価性によって、「元の対象物とずらしたあとの対象物が同一物体である」とモデルが認識できない課題
- → 解説するのが「プーリング層」
-
畳み込みの出力サイズ
- [W+2P-FW/S], [W+2P-FH/S]
- W : 画像サイズ、P : パディング、FW : フィルターサイズ、S : ストライド
-
プーリング層
- 入力データの微小な位置変化に対してほぼ不変な表現を出力
- モデルの計算量やメモリ使用量を少なくする効果あり
- プーリングには特徴マップの統計量を修正する効果はない

-
im2col (image to columns)
- 畳み込みの対象となる領域をベクトル化し、それを並べた行列を作成する処理を指す
- 画像認識において用いられている関数です。動作としては多次元配列を2次元配列へ、可逆的に変換
- これの最大のメリットは高速な行列演算ができるnumpyの恩恵を最大限に受けられる
- 画像データ(の集まり)を1つの行列にする、という関数

MobileNet
depthwise separable conv
-
depthwise conv
-
1チャネルに1つのフィルタが対応しており、各チャネルごとに対応したフィルタで畳み込みする。畳み込み処理はチャネルごとに独立しており、入力と出力のチャネル数は変わらない - dw畳み込みでは、各層ごとに畳み込みをするため、層間の関係性は全く考慮されない
- 特にCPUでは(GPUに比べて)nxnの畳み込みは時間がかかるので、dw畳み込みで畳み込み計算量を減らすことで、大幅に速度を改善
-
-
pointwise conv (1x1 conv)
- 別名1x1 Convolutionと言われるように、単純にWindow Sizeが1x1の畳み込み。
- 1x1の畳み込みということは単純に
ピクセルごとのチャネル方向の圧縮だと考えるとわかりやすいかも - Window Sizeが1x1であること以外は通常の畳み込みと同じなので、出力のチャネル数はフィルタの数と等しい
- 最大のメリットは層数を簡単に任意の値に変更できる点
-
通常の畳み込みが空間方向とチャネル方向の畳み込みを同時に行うのに対して、Depthwise(空間方向) を行なったのちにPointwise(チャネル方向) を行なうようにしているだけ。**ポイントは空間方向とチャネル方向の畳み込みを同時に行うのではなく、順に行うという点。
-
Convolutionにおいて空間方向の計算よりチャネル方向の計算の方が圧倒的に多いことがわかる(★)
-
グループ化畳み込み
- 全チャンネル一気に畳み込まず、分割した各グループ内のチャンネル内でのみ,それぞれ畳み込みを並列に行う層
- 畳み込みの処理をグループに分解することで計算速度向上およびワイド化による表現力向上が狙える
- ResNextで提案 (G=32 論文)

-
dilated conv (ダイレイト畳み込み)
- dilate = 1 の Dilated Convolution は普通の畳込み、dilate が 1 増えるごとに間隔が 1 ずつ開く
- 膨張畳み込みではカーネルも膨らんでいるのでスライディングウィンドウ走査はストライド1で密に走査することは行わず、2~4ストライド程度でスキップした位置で畳み込む
- この「
スキップ操作 + カーネルの膨張」の組み合わせにより,受容野の範囲を拡大させることができ、なおかつ、効率的に広範囲のコンテキストを取り入れることができる - 膨張畳み込み層は「少ない層数で広範囲のコンテキストを畳み込むことができる」利点を持つ

- 簡単に受容野を増やすには
- 層の数を増やす・フィルターを大きくする
- 受容野の一辺の長さは層数とフィルターの一辺の長さに対して線形なので、画像がとても大きい場合はあまり有用ではない
- プーリング層を使う
- プーリング層を入れると画像がその分小さくなってしまうことがある
- 層の数を増やす・フィルターを大きくする

-
transposed conv (転置畳み込み) = Up sampling
- 入力データを拡大するためにデータを補完してから畳み込み
- 2D畳み込み層と反対のアップサンプリング畳み込み操作を行う層
- 逆畳み込みという名前から誤解されやすいのですが、畳み込みの逆プロセスではない。畳み込みをする前の入力データを完全に復元するものでもない
- セグメンテーションや生成分野などでよく使われる
- https://nisshingeppo.com/ai/whats-deconvolution/


RandAugment
- 登録された複数のデータ拡張を指定されたハイパーパラメータに基づき実行する拡張手法
- 指定するパラメータ
- (1) 何種類の拡張手法をランダムに選択するか
- (2) その各手法に対してどの程度の強度で変換を行うか指定
- 強度 : データ拡張においてどの程度の変換や変更をデータに適用するかという度合いを示す
MixUp
- 異なる2つの画像を線形に結合して新しい訓練データを作り出す手法
Model
ResNet
- projection shortcut
- xの次元をF(x)の次元に合わせる役割
- スキップコネクション
- 勾配消失問題を解決
- ボトルネック構造
- 低次元に一時的に次元数を落とし、畳み込みを行った後に再び次元数をもとに戻す構造
- アーキテクチャ
- CONV-BN_ReLU
- ドロップアウトを使用
WideResNet
- チャネル数と層数との関係を実験によって調査
- アーキテクチャ
- BN-ReLU-Conv
DenseNet
- 概要
- 特徴マップをチャンネル方向に結合
- そのショートカット結合は、あるブロック内ですでに作られた特徴マップ全てを対象
- ResNetの正当な進化版
- Denseブロックは、全ての畳み込み層間を密にスキップ接続し、特徴マップを「チャンネル方向に」結合する構造
ViT
- 概要
-
画像を系列データにみなし、Transformerに適応するアイデア - Source Target AttentionやMasked Self Attentionがない、Transformerのエンコーダ構造を含むアーキテクチャ
-
- 技術のキモ
-
パッチ分割
- 画像をトークン化するために、画像を均等に分割してそれらをパッチとして扱う
- それぞれのパッチを直列化して固定長のベクトルに変換する
- この際、線形層を用いて各パッチを固定された次元のベクトルに変換
-
位置埋め込み
- 各トークンに自分の位置を知らせる情報を追加
- パッチ分割だけだと画像の位置情報が注意機構に伝達されない問題
-
クラストークン
- 埋め込みを終えたデータの先頭にクラストークンを結合する
- self attentionによって得られる、画像全体のデータの関係性を捉えたベクトル
- エンコーダ内の注意機構を通って、特徴を学習
- 初期値は、標準正規分布に従った乱数から生成
- クラストークンはパッチが埋め込まれたものと共に処理されるため、ベクトルの次元数は埋め込まれたベクトル次元数と同じ
-
エンコーダーブロック
- Embedded Patches → Norm → Multi-Head Attention → Norm → MLP
- 通常のTransformerと異なるのはレイヤー正規化の位置
- 構成要素
- MHSA、LayerNorm、MLP
- 正規化 : Layer Normalization
- 活性化関数 : GELU
- Embedded Patches → Norm → Multi-Head Attention → Norm → MLP
-
パッチ分割
Object Detection


- task
- 物体が含まれる短形領域であるバウンディングボックス
- 評価 : IoU (★計算)
- 0.5を超えると良いとされている
- 評価 : IoU (★計算)
- それに対応するクラスを予測
- 評価
- AUC
- AP(Average Precision)(★計算)
- mAP (APの全クラス平均)
- 評価
- 物体が含まれる短形領域であるバウンディングボックス
-
Non-maximum suppression (非最大値抑制)
- バウンディングボックスを1つに限定する処理
- バウンディングボックスが重複した際に、最も「物体らしさ」が高いボックスのみを残し、他のバウンディングボックスを排除するというアルゴリズム
- フロー
- (1)すべてのバウンディングボックスの中から最も「物体らしさ」の高いボックスを選択し、ラベル「1」を付与。
- (2) 重複率(IoU: Intersection over Union)が一定の値以上のバウンディングボックスにラベル「0」を付与。
- (3) ラベルが付いていないボックスについてこの処理を繰り返す。
R-CNN (2014)
- R-CNN(2014)
-
選択的探索 (selective search)
- ピクセルレベルで類似する領域をグルーピングしていくことで候補領域選出
- 似た特徴を持つ領域を結合していき、1つのオブジェクトとして抽出
- 約2,000個の候補領域を選出
- その一つ一つをCNNに入力することで特徴マップを取得し、SVMで分類
- その後、バウンディングボックスの回帰を実施
-
徹底的探索法(Exhausitive Search) ※ selective searchの前
- 領域の候補が非常に多くなり、高性能な識別器と組み合わせると計算量が大きくなりすぎる
- 評価指標
- IoU
- mAP
- 課題
- 候補領域ごとにCNNの計算をするので検出速度が遅い
- → 「画像全体を複数回畳み込んで特徴マップを生成し、得られた特徴マップから各候補領域に該当する部分を抜き出す(Fast R-CNN)」
- 候補領域ごとにCNNの計算をするので検出速度が遅い
-
選択的探索 (selective search)

Fast R-CNN (2015)
- Fast R-CNN (2015)
- 特徴
- 画像全体を1回CNNに通し、共有された特徴マップを生成することでR-CNNの問題点であった計算を大幅に改善した
- ステップ
-
- 画像全体を1回CNNに通して共有された特徴マップを生成
-
- 出力された特徴マップに対し、selective searchで抽出した候補領域をROI Poolingで固定サイズの特徴ベクトル変換
-
- 1つのネットワークでクラス分類とBB回帰を同時に実施 (Multi-task Loss )
-
-
ROI(Region of Interest) Pooling
- 多様な物体候補領域のサイズを、分類を行う層に入力するための一定の大きさに変形するプーリング手法
- 領域候補を求めるテンソルの固定サイズになるようにセクションに分割し、Max poolingを用いて値を埋めていく
- 損失関数
-
Multi-task Loss ⭐️
-
L = Lcls + λ[u>=1]Lloc- u >= 1 となっているのは、Llocが背景クラス u=0に対応していないため。u=0の時は係数を0として、u>=1の時は、2つの誤差の均衡を制御するためのパラメータλをかける
- L = クラス分類loss + BB回帰loss
- SSDでも用いられているloss
-
-
Multi-task Loss ⭐️
- 課題
- 候補領域を選出するためにselective searchを用いており、これが時間がかかりボトルネック
- 特徴

ROI Pooling
- RoI Poolingの対象となっているfeature mapは入力画像と比較して解像度が低いため、RoI Poolingされた領域が実際に対応している画像領域が、元々のregion proposalの画像領域とずれてしまうという問題
- 何れにせよ、RoIの取得と、ピクセルの割り当て時に丸め誤差が発生し、これがセグメンテーションなどの位置ずれがあまり許されないアプリケーションでは問題になります
Faster R-CNN (2015)
- 概要
- 領域提案ネットワーク(Region Proposal Network, RPN)と呼ばれるサブネットワークで候補領域を選出し、selective searchを完全に置き換え、end2endで学習できるようにしたアーキテクチャ
- 特徴
-
2つのモジュールから構成 (畳み込み層が出力する特徴マップを共有)
- RPN
- Fast R-CNN
-
2つのモジュールから構成 (畳み込み層が出力する特徴マップを共有)
-
RPN損失関数
- Lcls : 対数損失関数
- Lreg : smooth L1関数
- プロセス
-
- 画像をCNNに通し、特徴マップを生成
-
- 物体候補領域の生成 (RPN : Region Proposal Network)
- Region Proposalsを生成
- Anchor Box ( 異なるスケールおよびアスペクト比を持つ短形領域) を作成
- 物体候補領域の生成 (RPN : Region Proposal Network)
-
- 物体の精査と分類
- RPNで生成された提案領域にROI Poolingを適用し、固定サイズに変換
- 最終的に分類とBB回帰を実施
- ※
- RPNの学習においては、アンカーボックスの数をk個とすると、物体と背景の分類のために2k個のスコアをBB回帰のために 4k個のスコアを算出する

- RPNの学習においては、アンカーボックスの数をk個とすると、物体と背景の分類のために2k個のスコアをBB回帰のために 4k個のスコアを算出する
-

Mask R-CNN (2017)
- 概要
- 物体検出とセグメンテーションを同時に行う
- Faster R-CNNをベースに、特にセグメーションマスクを予測するための新しいブランチを追加
- 特徴
-
RoIAlign (Region of Interest) ロイアライン
-
ROI Pooling の改良版、セグメンテーションや小さな物体の検出に有効
- ROI Poolingでは特徴マップとピクセルのズレが生じていた
- 画像から物体が存在すると予測される領域のことで、物体検出の際に重要な役割
- 丸め込みを行わず、双線形補間で得られた点から出力を計算すること
- Faster R-CNNでは、このRoIの座標を整数値に丸めてピクセルに割り当てる方法であるRoI Pooling
- →この方法では座標を丸めるため誤差が大きくなり、セグメンテーションマスクの作成などの細かい処理には不便
-
ROI Pooling の改良版、セグメンテーションや小さな物体の検出に有効
-
マスクブランチ
- 物体のマスク(形状)を生成するための追加のサブネットワーク
- 各ROIから対応するピクセル単位の2値マスクを予測 (物体か背景か)
-
RoIAlign (Region of Interest) ロイアライン
- 損失関数
- L = L_cls + L_box + L_mask
YOLOv1 (2016)

- 概要
- 分割されたグリッドごとにクラス推定とBBの回帰を行う
- それまで二段階(検出と識別)で行われていた物体検出を一度の作業(全体を検出)にすることで高速化に成功
- End-to-Endモデルの最初期モデル
- 固定サイズのグリッドに分割
- S*Sのグリッドセルに分割 (s=7論文)
- 物体の中心がどのグリッドセルに分割することで、物体の中心がどのグリッドセルにあるかを特定し、そのセルが物体を検出するように学習
- BBの推定
- 物体予測
- 各グリッドセルはC個のクラスに対して条件付きクラス確率を予測
- 選別
- 信頼度の高いBBを基準にNMSで選別
- アーキテクチャ
- Darknetと呼ばれ、24層のCNNと4層のプーリングからなる
- 最終層を除いて活性化層はLeaky ReLU
- 単一ネットワークで完結
-
損失関数
- BBの中心座標(x,y)の損失
- BBの幅と高さ(w,h)の損失
- 物体が存在する予測の信頼度
- 物体が存在しない予測の信頼度
- クラス確率の損失
- 問題点
- グリッドセルは物体が小さい場合には十分な解像度を提供できず、小さな物体検出が困難である

SSD (Single Shot MultiBox Detector)(2016)→「小さな物体の検出」「低解像度の画像の処理」が得意
- 概要
- YOLOとは異なり、大きさの異なる複数の特徴マップを使用して物体のスケールに応じた高精度な検出を行う
-
デフォルトボックス⭐️ SSDの肝!
- 長方形の「枠」です。一枚の画像をSSDに読ませ、その中のどこに何があるのか予測させるとき、SSDは画像上に大きさや形の異なるデフォルトボックスを8732個乗せ、その枠ごとに予測値を計算
- このデフォルトボックスの役割は、それぞれが、
- 1. 自身が物体からどのくらい離れていて、どのくらい大きさが異なるのか
- 2. そこには何があるのか の2つを予測する事
-
ハードネガティブマイニング⭐️
- モデルが誤分類しやすい、つまり学習が進みにくい難しいネガティブサンプルを重点的に選択する
背景クラスのアンカーボックスから、予測が間違っているものを抽出し、再学習に用いることでモデルの精度を向上させる手法- (物体クラスの損失を降順に並び替えて、上位からピックアップし) 物体ラベルが存在するBBと、物体ラベルが存在しないBBの比が3:1になるように調整
- 全てのBBについて学習を行うと背景クラスが過剰に学習され、ネットワークが背景ばかり大量に出力してしまう可能性あり
- アーキテクチャ
- 画像を300x300にリサイズ
- 8732個のデフォルトボックス
- オフセット情報と信頼度
FCOS (Fully Convolutional One-Stage Object Detectionaster) 2019
- POINT
- アンカーフリー
- FPN : Feature Pyramid Network
- センターネス (Center-ness)
- 概要
-
アンカーボックスを利用しないアンカーフリーである
-
アンカーボックスの欠点
- ハイパーパラメータが多い
- pos-sampleとneg-sampleの不均衡
-
One-state (BBの候補領域の選択とクラス判別を一括で行う)を採用
-
計算コスト、学習時間を抑えられる
-
全てが畳み込みで実施 (全結合層なし)
- → 入力画像サイズなんでもOK
-
FPN(Feature Pyramid Networks) を使っている⭐️
- 複数サイズの特徴マップを生成するためのネットワーク
-
ambiguous sample
- 特徴マップの各点が、複数の物体の正解ラベルのBB内にある
-
学習の工夫
- 特徴マップ上のground truth 何に入る全ての点はポジティブサンプルとして扱う
- →物体の中心から離れた点を中心としたBBが予測される
- → 上記を防ぐために、「Center-ness」というindexを学習に加える
-
Center-ness
どのくらいx,yの座標が物体の中央から離れているかを正規化して表している- Center-nessが高いほど、BBは物体の中心に近く、信頼性が高い
- 物体検出の精度工場に寄与する
- 特徴マップ上のground truth 何に入る全ての点はポジティブサンプルとして扱う
-
FCOSの損失関数 (クラス分類、BB回帰、センターネスの3項目の学習を対象)
- Lcls : focal loss
- 分類に成功しているクラスの重みを小さくすることで分類が難しいクラスに焦点を当てた学習を実施
- Lreg : IoU Loss
- Lcls : focal loss
-
実験結果
- YOLOv2やRetinaNetよりAPが高い
-
ambiguous sample
- 概要
- ambiguous sample(曖昧なサンプル)」とは、物体検出モデルの学習時に、どの物体に属するかを明確に決定できないサンプルのこと
- FCOSは、アンカーボックスを使用しない物体検出モデルであり、画像上の各ピクセルを直接回帰することで物体の位置を特定します。この際、複数の物体が重なり合っている領域や、物体の境界付近のピクセルは、どの物体に属するか曖昧になることがある
- 発生原因
- 小さい物体
- 物体の重なり合い
- 物体の境界
- 対処法
- Center-ness
- FPN
アンカーボックスモデルの課題
- ネガティブサンプルとポジティブサンプルはIoUにて区別するため、ほとんどのAnchor Boxがネガティブサンプルになる
- Anchor Boxのサイズやアスペクト比を事前に設計する必要があり、それにより精度が上下する
Segmentation
-
セマンティックセグメンテーション
- ピクセルごとに分類問題を解く
- いくつかのピクセルが孤立して異なるクラスに割り当てわれる問題あり
- →条件付き確率場 (Coonditional Random Field, CRF)による後処理で解決
- CNNを使用しない画像処理でも頻繁に用いられる
- 画像をグラフ構造として表現
- →条件付き確率場 (Coonditional Random Field, CRF)による後処理で解決
-
セマンティックセグメンテーション評価
- IoU (★計算)
- Dice係数 (★計算)
- 関係性 : IoU <= Dice係数
FCN
-
全結合層を用いずに畳み込み層のみ用いて構成
-
転置畳み込み
-
SegNet
-
U-Net
-
Panoptic Segmentation (パノプティック)
- ピクセル毎にclassと物体番号idを推定するタスク
WordEmbedding (単語埋め込み、単語分散表現)
→ 単語数よりも低い固定長ベクトルに変換すること
word2vec
-
word2vec
- 2層のNNのみで構成されている
CBOWとskip-gramで構成-
CBOW (Continuous Bag-of-Words)
- 前後の単語から中央の単語を予測するためのNN
- 中央の単語を予測するので比較的少ないデータセットでも可能
- 語彙が多いほど、より多くのクラスを持った分類問題を解くことになる→ネガティブサンプリング
-
skip-gram
- 中央の単語が与えられた時のその周辺を予測するNN
- 周辺の単語全てを予測するため、CBOWと比べて大規模なデータセット必要
- 希少な単語や少ないデータにも対応可能
-
softmax計算を近似高速計算するために。。(学習の高速化)-
ネガティブサンプリング もしかしてskip-gramの方?
- 正解の単語以外に不正解の単語も学習に使用
- NCE(Noise Contrastive Estimation)を応用
- 全ての単語の内積計算をするのではなく、いくつかの負例を選択して損失計算
- 不正解ラベルをランダムに選択し、これらの負のサンプルを用いてネットワークを学習
- 全ての可能な単語ペアについての分類問題を解く必要がなくなり、代わりに正のサンプルと少数の負のサンプルに対してだけ評価を行う
- これにより、学習に必要なサンプル数が大幅に減少し、計算コストが削減され、学習時間も大幅に短縮する効果あり
-
階層的ソフトマックス
- 通常のsoftmaxを効率化する手法
- 特にボキャブラリーサイズが非常に大きい場合、計算量が増加するが、木構造を使い階層的に単語を分類して計算量を削減
-
ネガティブサンプリング もしかしてskip-gramの方?
LSI : Latent Semantic Indexing (潜在的意味インデキシング)
- モチベーション
- 例えば、「車で行く」と「自動車で行く」は意味として全く同じですが、単語そのものを見ると「車」と「自動車」が異なるため違う文として扱われてしまい、「車」で検索しても「自動車で行く」という文がヒットしません。しかし、「車」も「自動車」も同じ意味なので同じ文として扱われるようにしたい
- Bag of Words によるベクトル空間モデルが使用
- 要は単語の出現順を考慮せず、単語の出現頻度などによって文書をベクトルで表現するモデル
- 肝は、特異値分解 (SVD)。SDVに基づくトピックを推定する手法
- 情報検索の分野で提案された次元圧縮手法
- 各単語と文章がTF-IDFによって重みづけられた行列を特異値分解によって次元を圧縮することで、データ全体からの重要な情報を抽出
GNMT
-
GNMT(2016)
- Googleが開発したニューラル機械翻訳のシステム
- 要点
- LSTMレイヤの多層化
- 双方向LSTM層
- スキップコネクション
- 複数GPUでの分散学習
- 予測の高速化(量子化)
- 8層のエンコーダーおよび8層のデコーダーに対して、1層ごとに1個のGPU割り当て
- エンコーダの一層目のみが双方向LSTMであるため、他の層は前の層の計算が完全に終了する前に計算を開始できる
- もし全部の層を双方向LSTMにした場合、それぞれの層は前の層の順方向と逆方向の計算が終わるのを待たなければならず2GPUしか並列できない
- GPUをネットワークのどの部分に割り当てるかを認識、モデル並列の効率を高めるための工夫を確認⭐️
BERT
-
概要
- Transformerのエンコーダが用いられる
- 双方向なモデル
- 事前学習と再学習の2段階
- 入力は[CLS]から始まり [SEP]で終わる
-
事前学習
- (1) 単語マスク問題
- 局所的な特徴を捉える
- (2) 次の文かどうかを予測する問題
- 大域的な特徴を捉える
- (1) 単語マスク問題
-
再学習
- 教師あり
-
トークン埋め込み
- 単語の違いを表す
-
セグメント埋め込み
- 文の違いを表す
-
ポジション埋め込み
- 入力された単語の順序
GPT
- GPT-1
- 学習方法が事前学習とファインチューニングを同時に行う
- GPT-2
- 1の課題は、タスクがあらかじめ固定されていること
- 学習データ
- データの質重要
- Redditというソーシャルメディアにおいて評価が高いサイト
- GPT-3
- 2と同じく、事前学習のみでさまざまなタスクを解くモデル。RLは使わない
- GPT-3までは、NLP以外のタスクを解くことができない
- 音声
- コードの実行
- 画像
開発・運用環境
蒸留
- 概要
- 教師モデルは学習済みで予測しか行わず、生徒モデルは教師モデルを参考に学習を行う
- 温度付きsoftmax
- 未学習の生徒モデルが学習済みの教師モデルの重要な部分を学習することで、モデルの軽量化を図る
- 通常、複雑な教師モデルからより単純な生徒モデルへの知識の伝達を行うために用いられる
- 教師モデル→生徒モデルへの知識の伝達は、ソフトターゲットだけでなく、特徴量の一致による補助的な損失関数(教師と生徒の中間層出力を一致させるなど)を用いることも可能
- デメリット
- 教師モデルの出力に生徒モデルの出力を合わせる必要がある
-
損失関数(生徒を学習させるとき)
-
ソフトターゲット損失
- 先生の出力(予測結果)を目標分布に用いる
- Teacherの出力には転移させるべき知識が含まれていると考えるため
- 先生の出力(予測結果)を目標分布に用いる
-
ハードターゲット損失
- 正解ラベルを目標分布
-
ソフトターゲット損失
- メモ
- 不正解クラスに対する確率を利用
- 自己蒸留
量子化
- 具体的には、32ビット浮動小数点数を低精度な浮動小数点数や固定小数点数に変換
- 主に学習後に適用
- 量子化による精度低下を最小限に抑えるための再学習が一般的に行われる
- パラメータ、活性化、勾配いずれも量子化の対象
- 活性化を2値化する = ステップ関数に似た形状の関数を適用することと同じ ▶︎ 勾配0問題
- 回避するために、逆伝搬時に、ストレート・スルー・エスティメータ(STE) を適用すると、勾配が0でなくなる
- STE
- 微分不可能な関数を扱うための手法
- 量子化関数やステップ関数など、一部の関数は微分が定義できない、あるいはほとんどの点で微分がゼロになるため、通常の誤差逆伝播法では学習が困難
- 順伝播時にはそのまま関数を適用し、逆伝播時には関数の微分を近似的な値で置き換える手法
- つまり順伝搬ではそのまま、逆伝搬では別の簡単な微分で代用するというもの
- STE
- 回避するために、逆伝搬時に、ストレート・スルー・エスティメータ(STE) を適用すると、勾配が0でなくなる
- 恒等写像関数の微分は1であるため、逆誤差伝搬の計算としては、勾配を素通り
剪定 (プルーニング)
- 概要
- NNの重みを剪定することでモデルを軽量化する手法
- 重要度の低い重みを剪定することで、モデルの計算量とメモリ使用量を削減する効果
- 再学習を行うのが一般的
- 種類
- 非構造化プルーニング
- 重みの絶対値が閾値以下のものを剪定する
- 構造化プルーニング
- ノードやチャンネル全体を剪定する
- 非構造化プルーニング
-
チャンネル剪定
- ネットワーク内の特定のフィルタやチャンネルを削除
- モデルのサイズが減少し、HW上での効率的な実行が可能
- 最小二乗法で残ったチャンネルを再構成
-
宝くじ仮説
- NNには 「部分ネットワーク構造」と「初期値」 の組み合わせにあたりが存在し、それを引き当てると効率的に学習が可能という仮説あり
https://qiita.com/kernelian/items/52c06389fdd9a3e9e526
- NNには 「部分ネットワーク構造」と「初期値」 の組み合わせにあたりが存在し、それを引き当てると効率的に学習が可能という仮説あり
XAI
- LIME、SHAP、CAM、Grad-CAMをおさえる
説明可能性 (XAI)
- 判断根拠の可視化
- CAM, Grad-CAM
モデルの近似
-
大域的な説明>> データセット全体に対してどの特徴が影響しているか
- モデル全体の挙動を理解 (特徴が重要かしる)
予測を行う際にどの特徴がどれだけ影響しているか- モデルそのものが直接的に各特徴の影響度を示すこと
- 例) 回帰係数、特徴量重要度
-
局所的な説明>> 特定の予測に対してどの特徴が影響しているか
- ある入力に対して予測の根拠を知る(どの特徴が予測に寄与したかを知る)
-
予測モデルとは別のモデルが行う解釈- 例) LIME, SHAP
CAM (Class Activation Map)
- 概要
- XX
- 欠点
- GAP層がないと使用できない
- 可視化結果の解像度が粗い
Grad-CAM
- 概要
- 各チャンネルごとの特徴マップに対する勾配を重みとして活性化マップを作成
- ReLU関数を適用することで出力に寄与する部分のみ強調
- 出力クラスに対する特徴マップの重要度を求められるのがGrad-CAM
- 逆伝搬時に特徴マップの勾配を計算するため、追加の計算が必要
- 勾配情報を利用
- 勾配 = 「出力クラスに対する特徴マップの重要度」
- 指定する層は、最後の畳み込み層またはプーリング層を指定することを推奨
- デメリット
- 勾配平均を用いるため、勾配消失が起きたときはGrad-CAMをうまく動作しない
- 勾配を用いない方法として、「Score-CAM」が提案
- 計算速度は、逆伝搬時に追加の計算が必要なためCAMに比べて僅かに遅い
LIME(Local Interpretable Model-agnostic Explanations)
- 局所説明
- 複雑なモデルの出力を加法的線形モデルに変換することで解釈できるようにした
- 元のモデルが複雑だとしても人間が理解できるようにする
- 元のモデルは複雑な境界を持つため、判別の基準がわかりづらい
- 説明したいデータの
- モデルの種類に依存しない
- プロセス
-
- 線形モデルでの表現
-
- シンプルな説明変数の使用
-
- サンプリングと空間の変換
-
- 近似モデルの構築
-
寄与度を一意に求める際の3条件
-
局所正確性 (Local accuracy): 特定のデータに対して、予測モデルの出力と説明モデルの出力が一致する -
欠損値 (Missingness): 指定されていない特徴は影響度がない (寄与度を満たす) -
一貫性(Consistency): モデルの出力値が減少しない特徴においては、寄与度も減少しないこと
※ LIMEに関しては、この3条件を満たす手法として提案された
加法的分解 (Additive Feature Attribution Methods)
- LIMEは特徴を加えていくことによって説明モデルを構成する方法であり、SHAPの開発者はこれを加法的特徴帰属法と呼んだ
SHAP (SHapley Additive exPlanations) 2017 シャプ
-
モデルの出力を特徴の重要度の和として説明
-
局所的な説明方式としてデファクトスタンダード
-
キーワード : Shapley Value, 協力ゲーム理論
-
平均的な限界貢献度のことをShapley Value
-
ゲーム理論における「Shapley値」の考え方を取り入れたもの
-
局所的な説明手法としてデファクトスタンダード
-
協力ゲーム理論⭐️
- プレイヤーがグループを形成しゲームの目標を達成することを考える
-
シャープレイ値⭐️
- 協力ゲームにおいて複数プレーヤーの協力によって得られた利益を各プレイヤーに公正に分配するための手段
- 目標を達成した時の各プレイヤーで公平に評価した貢献度
加法的分解 (Additive Feature Attribution Methods)
- LIMEは特徴を加えていくことによって説明モデルを構成する方法であり、SHAPの開発者はこれを加法的特徴帰属法と呼んだ




最適化手法

Pathological Curvature
- パソロジカル カーヴァチャー
- 最適化の過程で目的関数の局所的な曲率が異常に大きくなることで、パラメータ空間における最適化が不安定になり、学習が滞る現象を指す
- 要因
- NNの重みやバイアスの設定によるもの
- 特に、同じ層にある2つのユニットが非常に似た重みやバイアスをもち、それらの値が微小に異なる場合、目的関数の減少量が非常に小さくなり、曲率も非常に小さくなるので進捗がほとんどなくなる
- 解決方法
- 過去の勾配の変化を利用して振動を抑えるMomentumの利用
- 大きなミニバッチの利用
- 関数の形状が渓谷のようになっており、勾配降下法などの最適化アルゴリズムに影響を与える問題
- この形状での勾配降下法は、一方向に進むスピードが速く、他の方向に進むスピードが遅い場合、オーバーシュートを引き起こし、振動が発生し、最小値に到達するのが遅い

最急降下法 (Gradient Descent : GD)
- 現在のパラメータ位置から目的関数の勾配を計算し、その勾配が最も急な方向にパラメータを更新
- 更新ステップが全てのデータを利用するので、大規模なデータセットに対してはメモリ使用量が多くなる
- 局所最適解に陥りやすい
確率的勾配降下法 (Stochastic Gradient Descent : SGD)
- ランダムに選ばれたデータ(ミニバッチ)を勾配の計算に使う
- ランダム性を追加
- 毎回勾配の値が変わるので、局所最適解に陥りにくい
- 欠点は、並列計算ができず時間がかかる
ミニバッチ学習SGD
-
複数のサンプルをひとまとめにしてパラメータを更新する手法
-
一回のパラメータ更新で複数の定数をランダムに並列計算する
- 最急降下法のように極小値で抜け出せなくなることがなく、SGDのように時間かかることもない
-
Pathological Curavtureというくぼみにハマってしまいオーバーシュートを起こし、時間がかかってしまう場合がある
Momentum
- 過去の勾配情報を利用することで、振動を抑制するアルゴリズム
- 勾配が振動する
- 最適解に向かう際に、勾配の方向が頻繁に反転し、収束が遅くなる現象
- モメンタム = 運動量
ネステロフのモーメンタム (NAG : Nesterov Accelerated Gradient)
- モメンタムを改良したもの、モメンタムが次の位置を予測し、その予測位置での勾配を計算
- モメンタムSGDが引き起こすオーバーシュートを抑制し、最適化の速度を向上
- オーバーシュート
- 一度の更新が大きすぎること
- モメンタムを改良したもので、モメンタムが次の位置を予測し、その予測位置での勾配を計算
AdaGrad (Adaptive Gradient Algorithm) 適応型勾配アルゴリズム
-
学習率を調整しながら、損失関数を最小にしていく手法
- 初めは学習率を高くする
- 最小値に近づいて、学習率を調整
- 過去の勾配の2乗の累積和に基づいて各パラメータの学習率を調整するアルゴリズム
- → 学習の最初から勾配の2乗和を計算し続けることで学習率が低下、学習が停滞
RMSprop (Root Mean Propagation)
- 勾配の2乗に指数関数的な重みをつけた移動平均を利用
- AdaGradよりも高速で収束
- AdaGradを改良したアルゴリズム
-
AdaGradでの課題
- 学習の最初から勾配の2乗の累積和を計算し続けることで、学習率が低下してしまう、学習が停滞してしまう問題
- 学習が進んでいくと分母が大きくなりすぎる→勾配の値に関わらず更新が進まない
- AdaGradの考え方に加えて、過去に更新したパラメータより直近のパラメータに注目して学習率を調整
Adam (Adaptive Moment Estimation)
- モーメンタムとRMSpropの良いところを組み合わせた手法 (RMSPropにmomentumを導入して改良したモデル)
- 過去の勾配の指数関数的に減衰する平均も保持
- 学習率の自動調整が行われているため、L2正則化による減衰が意図した値にならない
正則化⭐️
-
正則化
-
汎化誤差を減少させる目的で導入 - 過剰適合を抑制するために損失関数に正則化項を加えて
新たな目的関数とする
-
-
一般的なアルゴリズムは、、
- モデルの
パラメータを更新して訓練誤差を最小化することで汎化性能を高める - これだけだと、訓練データに過度に適応してしまい、新たなデータに対する性能低下 (
過剰適合)
- モデルの
-
L1正則化は不要なパラメータを削りたい’(次元・特徴量削減)というときに使われる
-
L2は過学習を抑えたいとき
学習率のスケジューリング
- コサインアニーリング
- warm restart
- cyclical learning rate
Xavier法(ザーヴィア)
- 様々な層にわたって勾配の分散を釣り合わせる問いう考え
- 各層での出力の分散が入力の分散に近くなり、逆伝搬時にも勾配が適切に流れる確率が高くなる
- シグモイドやtanhが適している
- 非対称的な活性化関数には適用が難しい
He法
- ReLU向けに値を変更
- ReLU
- 逆伝搬の過程において勾配が保たれやすい特性
教師あり学習
- 回帰タスク → 連続値を予測することが目的。activation funcは、恒等関数が一般的。例として、MSEやMAE
- 性能評価
- R^2 (決定係数)
- 0~1までの値を取り、1に近いほど誤差が小さく精度が高いモデルと言える
- R^2 (決定係数)
- 性能評価
教師なし学習
- 種類
-
クラスタリング
- K平均法、階層的クラスタリング、DBSCAN
-
次元削減
- 主成分分析、t-SNE、UMAP
-
異常検出
- One-Class SVM, Isolation Forest, Local Outlier Factor
-
クラスタリング
- 教師なし学習の手法である次元削減は、データの情報を維持しつつ、特徴量の数を減らすことでデータの可視化や処理速度の向上を目指す手法
半教師あり学習


- 分類器に基づく手法(ブートストラップ法)
-
- 自己訓練(Self Training)
-
- 共訓練 (Co-training)
-
1.Self-training
- ある一つの分類器(教師あり学習)を使ってラベルありデータのみで学習し、ラベルなしデータの分類をします。その後分類したラベルなしデータのうち高い 確信度 で分類できたものは正しいと考え(正しい予測をしたと考え)、ラベルありデータとみなして再度学習
2.Co-training (共訓練)
- Self Trainingの弱点は、信頼度に基づいて「エイ・ヤー」と気合でラベルを順に付けてゆく方法なので、最初に間違えると間違いが増幅される点
- この弱点を少しでも解消しようと考え出されたのがCo-Training
- 異なった視点を持つ2つの分類器を作成してお互いの分類器が持つ情報を交互に補間し合うことでより良い学習を目指す
-
ビュー- 「データの異なる側面や特徴」を表す言葉
- 例えば、画像データの場合、色情報・形状情報と2つのビューとして考えることができる

自己教師あり学習: SSL
- ラベル付の必要性を減らし、大量のラベルがつけられていないデータを効率的に利用
- データの分布が不均一な場合でも学習可能
- AEや自己回帰モデルを活用した手法あり→データの内部構造を捉える
Contrastive learning (SSLの一手法)
- 2つのデータを比較することでモデルの表現力を獲得する自己教師あり学習の一つ
- 目的
- 入力データの表現が類似しているか否かを識別できるようにすること
- 類似したデータと非類似のデータを区別する特徴表現を学習
- クエリエンコーダとキーエンコーダという2つのエンコーダを使う
E2EのContrastive learning
- 特徴抽出と類似度計算を同じモデルないで一貫して学習する手法
表現学習
- 目的
- 入力データをより扱いやすい形に変換すること
- 得られた表現は、元のデータよりも解釈や処理が容易となりMLタスクでの性能向上
半教師あり学習 (代表的3つ)
(1)一致性正規化 Consistency regularization
-
一致性正規化 (良い擬似ラベルは多少生成方法を変えても不変)
- 入力にノイズが乗っていても、その時の出力は入力ノイズが乗っていない時の出力と同じになるべきという考えに基づいた方法
- 代表例)
- VAT
- Mean Teacher
(2) エントロピー最小化 Entropy minimization
-
エントロピー最小化 (良い擬似ラベルはエントロピーが小さい)
- 決定境界は特徴空間上でデータが密集しているところを通るべきでないという考えに基づいた方法
- これを言い換え「ニューラルネットの出力は決定境界から遠くなる」ように学習する手法
- ニューラルネットの出力を決定境界から遠ざけることは、出力のエントロピーを小さくすることで実現されるのでentropy minimizationと呼ばれている
- エントロピーを小さくすることは、モデルの予測の信頼度を高くすることを意味
- 代表例)
-
(3)Pseudo-Label (擬似ラベル)
- ある程度自信を持って予測しているものについてニューラルネットの出力を1-hot化して擬似ラベルを作成し、この擬似ラベルを用いて通常の教師あり学習と同じように学習します。図2にも示すように、1-hot化した擬似ラベルに出力が近づくように学習することで、出力のエントロピーは小さくなるのでentropy minimizationの手法に分類されます
-
(3)Pseudo-Label (擬似ラベル)
-
最近の研究事例
-
FixMatch (2020)- consistency regularizationとentropy minimizationを組み合わせた手法であり、教師ありデータが非常に少ないケースでも高い精度を達成できることが示されています。
-
ドメイン
- データの分布やデータ空間のことをドメインという
- 表現や分布が異なった物をまとめて学習すると精度が落ちるので、同じドメインだけを用いて学習を行う
ドメインシフト
- 事前学習済みモデルにおいて、ソースドメイン(元のドメイン)がターゲットドメインと異なる現象 (確率分布が異なる現象)
- ドメインシフトが発生しているとか言う
- ドメインシフトに対応する手法としてー「ドメイン適応」が存在
ドメイン適応 (転移学習の一種)
- ドメインシフトが存在する状況下でも、学習済みモデルをターゲットドメインに適応させるための技術総称
- ドメインが異なる際に採用されるアプローチ
- ソースドメインで学習したモデルを変換したり、損失関数を追加するなどある
- ターゲットドメインのデータにラベルが付いているかどうかによっても適用される手法が変わる
ML基礎
パターン認識アルゴ
-
k-NN
-
kd-tree- k-NN のような距離に基づいた探索を高速化するためのデータ構造
- 2次元のみではなく、より高次元のデータ群にも用いる
- k次元のデータを効率的に探索するためのデータ構造
- k-NNで探索を行う際に、全データとの距離を計算するのは効率が悪いため、kd-treeのようなデータ構造を用いて高速化を図る
- kd-treeは、データを再帰的に分割することで、探索範囲を絞り込み、計算量を削減
-
近似最近傍探索
- 計算速度を高めた探索法
- 局所感度はっしんぐ、kd-tree, Ball Tree etc.
距離
- ユークリッド距離
- マンハッタン距離
- マハラノビス距離
- コサイン距離
- LP距離
機械学習の誤差を分解
-
バイアス
- モデルの表現力が不足していることによって生じる誤差
- モデルの予測が真の値からどの程度外れているか計測
- バイアスが大きければ、モデルはアンダーフィットであると判断
-
バリアンス
- 訓練データの選び方によって生じる誤差
- モデルの予測がどの程度変動するかを測定
- 予測の一貫性
-
ノイズ
- データの測定誤差などによって生じる誤差
- 観測データ中のランダムな誤差や変動のことを示す
-
「バイアスとバリアンスのトレードオフ」
- 単純なモデル : バイアス高い、バリアンス低い
- 複雑なモデル : バイアス低い、バリアンス高い


- 仮に訓練データに対する誤差が0で、かつ過剰適合がない状態を実現できたとしてもデータノイズが含まれていれば誤差は0
性能指標
-
MAE
- 外れ値の影響を受けにくい
-
MSE
- 外れ値の影響を受ける
- 外れ値の少ないデータセットや外れ値が重要視される場合に適している
-
RMSE
- 外れ値の影響を強く受ける
-
決定係数
- 0-1
-
マクロ平均
- 各クラスの指標を個別に計算し、それらの平均を取る性能指標
- 各クラスが同等に重要であると考えられる場合や、データの少ないクラスも重視したい場合に適している
-
マイクロ平均
- 全クラスをまとめて計算する性能指標
- 全体の性能を重視する場合に適している
生成モデル
- 背景
- 過去生成モデルでは、モデルの複雑さが増すにつれて尤度の計算が困難
- 尤度の計算が複雑でモデルの学習や評価が難しい → 拡散モデルやフローベースで解決
- 確率モデル
-
識別モデル
- 直接p(C|x)をモデリングし、argmaxp(C|x) を解くのが識別モデル
- 入力xが与えられた際の事後確率を最大とする値 argmax p (C|x)を解く
-
生成モデル
- p(x|C)とp(C)をそれぞれモデリングするor同時確率p(x,C)をモデリングしargmax(x,C)を解く
- 利点
- p(x) = Σp(x|C)p(C) と周辺化することで、**データの生起確率p(x)**を得ることができる
- 分類
- VAE・GAN
- 拡散モデル
- フローベースモデル
-
識別モデル
VAE


損失関数
-
第一項
- 復元誤差 : 入力と出力の差を小さくする項
-
第二項
- 非負の正則化項 : エンコーダが出力する潜在変数zの分布をzのモデル分布に近づける
-
概要- データの潜在的な確率分布を推定する
-
ガウス分布の平均と分散を推定
-** p(x) = ∮p(x|z)p(x)dz の対数尤度logp(x)を最大化**するように学習 - 潜在変数と呼ばれる観測できない変数がデータの背後に存在していると仮定している点がAEとの違い
- VAEのエンコーダではガウス分布の平均と分散を出力し、その分布に基づく変数をランダムに生成するため、デコーダからエンコーダへ続けて逆伝搬を行うことができないので、ノイズ変数を導入しこれを改善している
- KLダイバージェンスの非負性、ELBOの最大化
- デコーダの出力が分散一定の正規分布に従っていれば、-logp(x|z)は、デコーダの出力x'を使った二乗損失に置き換えることができる
-
目的関数
- ELBO
-
技術のキモ-
リパラメタリゼーション・トリック
- エンコーダが出力するガウス分布の平均と分散に基づいて潜在変数zを生成するのではなく、標準正規分布 N(0,1)に従うノイズ変数を用いて、
z= μ + σ*ε⭐️ を潜在変数をみなす処理をする- μ : 潜在分布の平均、σ : 標準偏差、ε : 標準正規分布からサンプリングされた乱数
- これで勾配を逆伝搬させて学習できる
-
VQ-VAE (Vector Quantized VAE)
- 通常のVAEにベクトル量子化を用いた離散的な潜在表現を導入したモデル
- 連続的な潜在変数の代わりに、ベクトル量子化によって、あらかじめ定めた固定サイズの潜在表現から離散的なコードを選択する点
- ベクトル量子化(VQ: Vector Quantization) は、連続的なベクトル空間に存在するデータを、有限個の代表ベクトル(コードベクトル)で近似する手法
- エンコーダが出力するガウス分布の平均と分散に基づいて潜在変数zを生成するのではなく、標準正規分布 N(0,1)に従うノイズ変数を用いて、
-
リパラメタリゼーション・トリック
GAN
- 概要
- 識別器は最大化、生成器は最小化を目指す
- 最適なGとDの両方が得られた場合、Dの出力は 0.5 となる
- 技術のキモ
-
モード崩壊
- 特定のデータしか生成しない
-
勾配消失
- DがGよりも大幅に優れているとき、勾配が消失し、生成器の学習が進まなくなる問題
- ネットワークの均衡状態への収束
-
モード崩壊
- 学習率
-
TTUR (Two Time-Scale Update Rule)
- 異なる学習率を使用する方法
- 今回
- Dには高い学習率、Gには低い学習率
- これにより「学習が早く終了するものの実用的でない画像を生成する」という問題が起きにくい
-
TTUR (Two Time-Scale Update Rule)
Wasserstein GAN→GANの「学習が安定しない」「勾配消失が起こりやすい」「モード崩壊が起こる」点をWasserstein距離で解決
(ワッサースタイン)
- 概要
- 目的関数に2つの確率分布間の差を計算するWasserstein距離を導入することで解決した手法
- Wasserstein距離は、全体の確率分布を考慮するため、Gが多様なデータを生成することを奨励し、これが「モード崩壊」を防ぐ
- GANではJSダイバージェンスで分布の比較をしていたのを、2つの分布の損失をWasserstein距離で計算
- Dの重みを一定の範囲でクリッピング
- 生成されたデータの品質を向上させると同時に、学習プロセスの安定性を高めることが特徴
- 従来のGANの訓練不安定性を解決するために、Earth Mover (EM)距離を最小化することに焦点を当てた
-
ワッサースタイン距離
- ある確率分布から別の確率分布へ「質量」を最適に移動させるのに必要な最小コストを表す
- この距離は、確率分布間の差異を評価する方法として有用であり、特に分布が低次元の多様体に支えられている場合に適している
- 最初のGANからの変更点
- optimizerをAdam→ RMSprop
- 識別器Dの活性化関数を省力
- 学習方法を変更
- 問題点
- WGANはクリッピングされた重みが2極化するため勾配消失や勾配爆発が起きやすくなる
- → この課題を勾配に制約をつけることで改善したWGAN-GPが提案

DCGAN
- 画像生成に特化した重要なモデル
プーリング層を畳み込み層(ストライド2以上に設定)に置き換え- GとDの両方でバッチ正規化を採用
G : ReLU, tanh(最終層のみ), D : LeakyReLU- 上記により、DCGANはGANより深い構造を持ったモデルの訓練を可能に
CGAN
- GeneratorとDiscriminatorの各入力にラベル情報を混ぜてあげるだけ
- コスト関数もGANと同じもの
pix2pix (CGANの一種)G:U-Net, D:PatchGAN
- pix2pix (2017)
- 概要
- C-GANを画像から画像への変換の問題に適用
- minmax V(G,D) + λL(G)
- CGANの目的関数V(G,D)にL(G)を追加することで画像の大域的な情報を捉えられるようになり、より違和感のない画像を生成する
- L1やL2損失は、画像の低周波数の構造をよく捉えるが、画像の高周波数の構造をよく捉えられず画像がぼやける→解決するためにPatchGAN
- 白黒→カラーへの変換タスク : Gにおいて入出力画像間でエッジの位置を共有する
- モデル
-
Generator: U-Net適用- 通常のGANと違い、Gにノイズではなく画像を入れる
- 画像変換問題ではSemantic Segmentationと同様に画像ピクセルの細かいディティールを捉えることが重要
- U-Netの複数の層にDropoutを設けることで各層にノイズベクトルzを与え、高品質な画像の生成を可能に
-
Discriminator: PatchGAN- 画像全体ではなく、パッチ単位での識別を学習することで、CGANの学習を画像の高周波成分(画像の詳細なディディール)のモデル化に専念させる
- PatchGAN
- L1の方がL2損失より画像をぼかす効果が低い
-
- 目的関数
-
L1ノルム(L1正則化)採用
- 画像変換問題では、本物らしさだけでなく、入力画像と出力画像の一致具合を測る指標が別途必要となる。つまり、「条件画像と画像のペア」の一致度を保つための制約条件
- cGANの損失関数を使用
-
L1ノルム(L1正則化)採用
- ノイズはDropoutで代用
- メリット
- ペアデータがあれば様々な画像変換タスクに適用可能
- E2E で学習可能
https://toukei-lab.com/pix2pix
- 概要
CycleGAN
- 概要
- 画像を別のスタイルの画像に変換するような問題に対する手法
- GとDが2つずつ存在
- 技術のキモ
- サイクル一貫性損失
- 変換と逆変換を重ねた F(G(y))が元のスタイルyと同じになるかを比較する
- サイクル一貫性損失
拡散モデル
-
概要
- 訓練データに対して逐次的にノイズを施していく「拡散過程」を参照し拡散過程の逆方向を学習し、データを生成
- Diffusion Modelに追加されるノイズはガウシアンノイズと呼ばれます。ガウシアンノイズとは、ガウス分布(正規分布)に従って変動するノイズ
- ガウシアンノイズは、その画像のピクセルレベルでどのようにノイズを付与するかが影響するため、マルコフ連鎖が適用
-
代表例
-
DDPM : Denoising Diffusion Probalistic Model (2020)
- 各時刻の確率分布をガウス分布と仮定して、その平均と分散を深層学習モデルによって推定
- ノイズを段階的に減少させる拡散過程を用いて、高品質な画像生成を実現
- DDPMではノイズ除去にU-Netを用いる
- 各解像度の畳み込みそうの前に空間方向のAttentionを入れることが、高い生成性能のために必要
- すごいけど遅い
- 流れ
- (1)
拡散過程を定義 : データからノイズへの変換が可能になる - (2)
逆拡散過程を定式化 : ノイズからデータへの変換が可能になる (NNを使う) - (3) 逆拡散過程で得られるデータの
尤度の最大化を導出- ノイズから変換されたデータが自然なデータになるように学習
- ゴール) ノイズを載せた画像から推定したノイズの2乗誤差を最小化 (デノイズの学習)
- (1)
-
DDIM ( Denoising Diffusion Implicit Models )
-
ノイズを追加する過程を最適化することで、より効率的に元の画像を復元できる
- DDIMでは、ノイズを追加する際の「時間ステップ」を可変 (DDPMは一定)
- ノイズを追加する過程を制御
- 最大の特徴は、高速化と高品質化の両立
- Implicit : 暗黙
- DDPMと同じ目的関数で学習できる
-
ノイズを追加する過程を最適化することで、より効率的に元の画像を復元できる
-
DDPM : Denoising Diffusion Probalistic Model (2020)
-
GLIDE (Guided Language to Image Diffusion. for Generation and Editing)
- テキスト情報から画像を生成するモデル
- DALL-Eを越したと言われている
- DALL-Eで使われているモデルのベースはVQ-VAEだが、VAE系はGANと比べるとまだ画像が鮮明でないという課題がある
学習データにおける対数尤度の計算
- うまくモデルを設計すれば計算できるよ派
- logp(x)の計算が直接できるようにモデルの形を工夫 → フローベース
- 尤度の計算をxの要素ごとに分解し、順番に計算して統合 → 自己回帰型生成モデル


フローベース生成モデル (FLOWモデル)
-
概要
- 生成データと学習データの分布を合わせるには、尤度の最大化が必要
⭐️尤度を計算して、生成モデルのパラメータθに関して最大化しよう
- 連続的かつ可逆な変換によって、複雑な分布を形成することができる生成モデル
- 単純な変換をいくつも適用することで複雑な変換を構成し、xの確率分布を形成
- 生成データと学習データの分布を合わせるには、尤度の最大化が必要
-
特徴
- データの尤度が求められる
- その尤度を直接最大化することで学習できる
- 逆変換ができる
-
技術のキモ
-
Activation Normalization (ActNorm) Glowで提案
- 基本的にBatch Normと一緒
- Glowで導入された正規化手法
- 各バッチのデータに対してチャネルごとに学習可能なスケールとシフトパラメータを用いて、データの分布をバッチ単位で正規化
-
カップリングレイヤー
データの一部を固定し、残りの部分を変換する手法- 変換とその逆変換が容易に計算できるようになる
- 単純な変換を組み合わせることで複雑なデータ分布を表現
- 例
- NICE, RealNVP
-
Activation Normalization (ActNorm) Glowで提案
NICE
- NFでの変換関数fをNNを使って定義したモデル
- 変換(encoder)と逆変換(decoder)はヤコビアンが容易に計算できる必要あり
- 重みが三角行列なら、NNでも計算が容易
- ただ、そのNNは制約が強すぎて表現力が低い → カップリングレイヤー (Coupling Layer)
Real NVP
- NICEで提案されたアフィンカップリングがベース
- NICEでは、MLPだけだったがCNNへ拡張
- Multi-scale Archi の導入
GLOW
- 正規化Flow
- 代表的な論文: NICE(NON-LINEAR INDEPENDENT COMPONENTS ESTIMATION)
- 簡単な形 (ガウス分布など)の確率分布 q(z)に対して、非線形で可逆な変換fを繰り返し適用することで複雑な分布 q(z)を表現


-
データの分布を学習し、新しいデータを生成するための機械学習モデル
-
画像生成モデル
- GAN, VAE
- 拡散モデル
- フローベース生成モデル
Denoising autoencoder (2008)ノイズ除去
- データにノイズを付加したものを入力して,ノイズを付加されていない元のデータを出力教師とすることで,データからノイズを除去する ( de-noising ) ことを目指す
変分下限(ELBO:Evidence Lower Bound)
- 真のデータ分布とVAEがモデル化する分布(エンコーダーとデコーダーによって生成される)の間の距離を定量化
- 変分下限を最大化することは、VAEが真のデータ分布に近づくように学習することを意味する。
- 変分下限は、KLダイバージェンスと再構築誤差の和として定義される
- KLダイバージェンスは、モデル化する分布と真の分布の違いを測定し、再構築誤差は、デコーダーが元のデータを再現する際の誤差を表す
表現学習
- データから有用な特徴を自動的に抽出し、それを新たな表現として学習する手法
- 表現学習によって得られた表現は、元のデータよりも解釈や処理が容易となり、MLタスクの性能工場に寄与する
距離学習
- サンプルをサブネットワークによって特徴空間に射影し、射影した先で距離を計算し、クラスごとに分離されるように学習
- クラス分類 → 特徴空間内でどのような分類境界を引くか
- 距離学習 → 特徴空間に射影する際に、クラスごとに距離が離れるように射影する
SiameseNet(シャム)
-
SiameseNet(シャム)- 概要
- 画像認識タスクにおいて、ペアのデータが同じクラスに属するか、異なるクラスに属するかを識別するモデルを学習するためのNN
- 特徴間の距離の計算にユークリッド距離が一般用いられる
- 問題点
- 不均衡発生
- 学習時のコンテキストに関する制約あり
- 損失関数
- 2値 CE + L2正則化
- マージンを考慮した2値クロスエントロピー誤差
- 2値 CE + L2正則化
- 概要

Contrastive loss
- Contrastive loss (2016) 対照損失
- 次元削減目的で提案
- 一緒に使われる代表的なネットワークはSiameseNet (シャムネットワーク)
- 相対的な距離を考慮できていない

Triplet Network (トリプレット)
-
Triplet Network (トリプレット)- 概要
- 3つのサンプルを入力とする距離学習手法であり、アンカー・ポジティブ・ネガティブ
- 各サンプルを特徴空間に射影する際は共通のネットワーク用いており、損失関数としてTriplet lossを用いるのが特徴
- 同じクラスのペアと異なるクラスのペアの間の不均衡を解消
- コンテキストの考慮が不要
- 問題点
- 学習がすぐに停滞する
- 学習データセットのサイズが増えてくると考えうる入力の組み合わせが膨大
- クラス内距離がクラス間距離より小さくなることを保証しない
- 学習時の入力ペアの選びに、学習されたモデルの性能に依存
- 学習がすぐに停滞する
- 概要
代表的な学習方法
- Center loss
- SphereFace
- CosFace
- ArcFace
- MagFace(2021)
統計
共役事前分布
- ベイズ統計を扱う際に、複雑な計算を回避するために考えられた事前分布
- 共役事前分布に尤度をかけて事後分布を求めると、事後分布の形は事前分布と同じ
- 共役事前分布に事前分布を設定すると、計算が容易になります。また、ベイズの更新も容易になる


最尤推定
- 観測データに基づいて確率モデルのパラメータを点推定する手法
- 最尤推定を解釈する方法
- 最尤推定は訓練集合で定義される経験分布とモデル分布の間の差を最小化する
- この2つの分布の差は、KLダイバージェンスで測定
MAP推定
- 観測データに基づく尤度と事前分布を組み合わせて、事後確率が最大となるパラメータの値を推定する統計的手法
- θ = argmax p (θ|x) = argmax logp(x|θ) + logp(θ)
ベイズ則
- 条件付き確率に関して成り立つ定理
ベイズ推定
ベイズ最適化
-
獲得関数
- ベイズ最適化においてガウス過程回帰で得られた平均と分散から表せる関数であり、次の候補点を決める指標
- ガウス過程回帰により得られた事後分布から候補点を選択する際に登場
- 代表的な獲得関数
-
PI
- 現場の最大値(最大値)を更新する確率
-
PTR
- PIの派生型
- ある範囲内で最高値を超える確率
- 幅広い領域を探索すると言うより今あるデータを活用する関数
- 局所最適に陥りやすいデメリットあり
-
EI
- 最大値の改善値の算出
- PIやPTRは最大値を更新する確率を表すのに対してEIは改善値の期待値
-
UCB/LCB
- 探索と活用を使い分けできる獲得関数
- UCBは分散を加算することで最大化を目指し、LCBは分散を弾くことで最小化を目指す
-
PI
Softmax with loss
- ソフトマックス関数と交差エントロピー誤差を組み合わせて損失値を計算し、勾配を求めるための逆伝播を実行
# SoftmaxWithLoss クラス: ソフトマックス関数と損失関数(交差エントロピー誤差)を組み合わせたクラス
class SoftmaxWithLoss:
# コンストラクタ
def __init__(self):
self.loss = None # 損失値
self.y = None # ソフトマックス関数の出力
self.t = None # 教師データ(正解ラベル)
# 順伝播メソッド
def forward(self, x, t):
self.t = t # 教師データをセット
self.y = softmax(x) # ソフトマックス関数で計算
self.loss = cross_entropy_error(self.y, self.t) # 交差エントロピー誤差で損失を計算
return self.loss # 損失値を返す
# 逆伝播メソッド
def backward(self, dout=1):
batch_size = self.t.shape[0] # バッチサイズを取得
# 教師データがone-hot-vectorの場合
if self.t.size == self.y.size:
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx # 勾配を返す
sigmoid
- 入力の絶対値が大きくなると勾配消失が生じやすい
- なぜなら、0から1に近づくため


import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
class Sigmoid:
def __init__(self):
# out変数を初期化
self.out = None
def forward(self, x):
# シグモイド関数を適用して出力を計算
out = sigmoid(x)
# 出力をインスタンス変数に保存
self.out = out
# 出力を返す
return out
def backward(self, dout):
# 逆伝播の際の勾配を計算
dx = dout * (1.0 - self.out) * self.out
# 勾配を返す
return dx
Softmax

import numpy as np
def softmax(x):
# オーバーフロー対策として、最大値を引く
x = x - np.max(x, axis=-1, keepdims=True)
# ソフトマックスを計算
y = np.exp(x) / np.sum(np.exp(x), axis=-1, keepdims=True)
return y
ReLU

Leaky ReLU
GELU (Gaussian Error Linear Unit)
- ReLU型の活性化関数
- ガウス関数に基づいた滑らかな非線形性を提供し、勾配が消失しにくいという特性
- ネットワークが大規模であるほど効率的に正則化できる
- これにより、GELUはTransformerのような大規模モデルで広く採用
- ViTのエンコーダの活性化関数はGELU

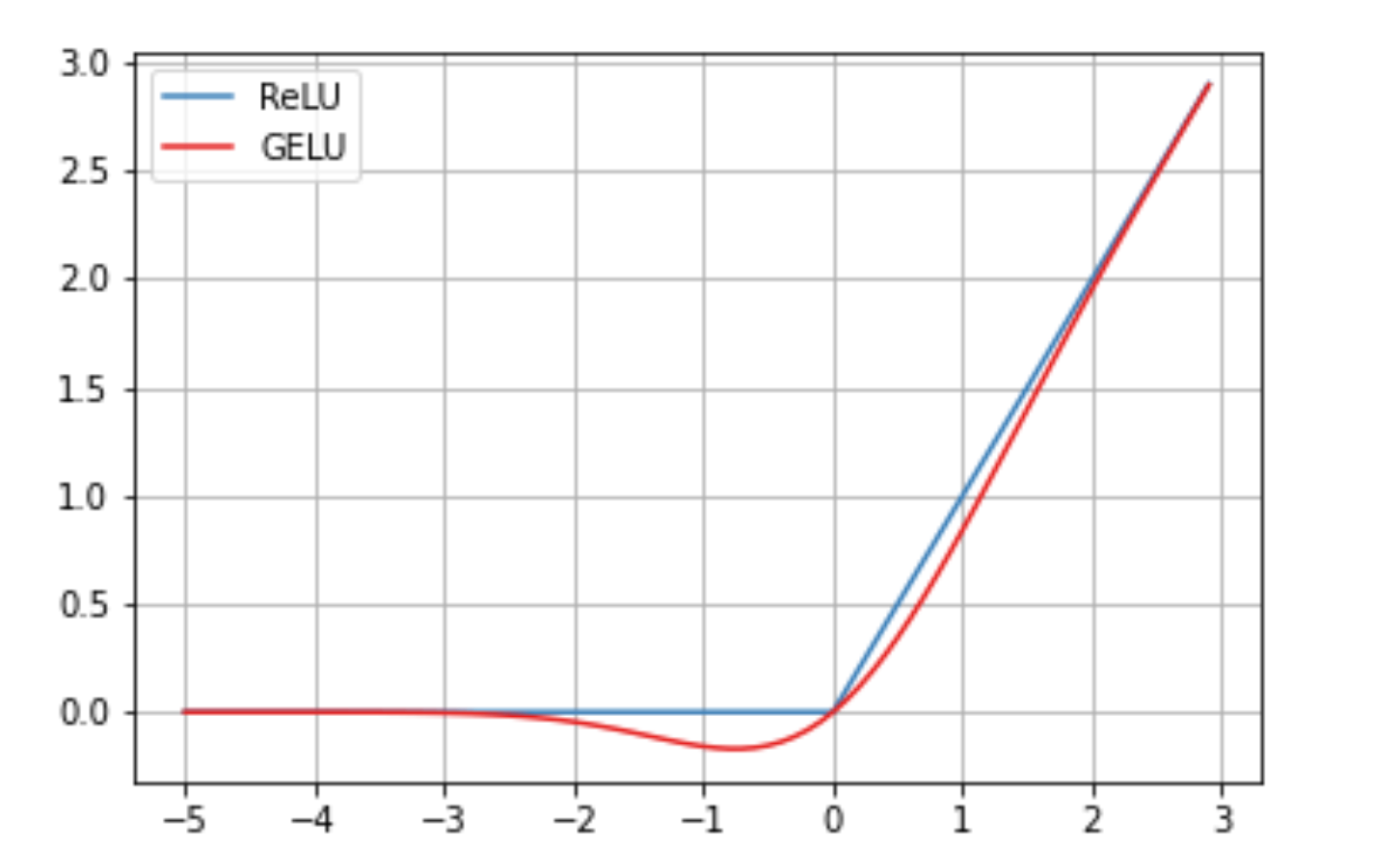


tanh
- -1から1の範囲の値をとる
- シグモイド関数の微分の最大値が0.25であるのに対して tanhの微分の最大値は1→勾配消失しにく
- 偏微分 : tanh'(x) = 1 - tanh^2x

自然言語処理
RNN
- 時系列データを処理することに長けたモデル
- 長い系列データに対する長期的な記憶の保持が難しい
- 勾配消失問題が起こりやすい
- 入力である系列データの長さが違っても、再帰的な処理の回数が変わるだけなので系列データの長さは可変
- RNNでは各時間ステップ時に出力することも、全ての入力を終えてから出力を行うこともできる
- 活性化関数 : tanh (一般的)
- 処理時間はBPTT法の方が長くなる
双方向RNN (Bidirectional RNN)
- 概要
- 順方向と逆方向の2つのRNNを結合したニューラルネットワーク
- 与えられた時点の入力が、過去と未来の両方の情報にアクセスできるようになる

BPTT (Back Propagation Truough Time) → Truncated BPTT
- 時間方向に展開したニューラルネットワークの誤差逆伝播法
- 問題点
- 長い時系列データを学習する際にBPTTで消費するコンピュータリソースが膨大になってしまう点
- 各時刻のRNNレイヤの中間データをメモリに保持しておく必要があるため
- 時間サイズが長くなると、逆伝播時の勾配が不安定になることも問題になる
- 長い時系列データを学習する際にBPTTで消費するコンピュータリソースが膨大になってしまう点
Truncated BPTT
- ネットワークの逆伝播の繋がりだけを断ち切る手法である。 順伝播の流れは途切れることなく伝播させ、逆伝播のつながりは適当な長さで切り取り、その切り取られたネットワーク単位で学習を行う
LSTM (3つのゲート+メモリセル)
-
概要
- 過去の情報を長期記憶しておく記憶セル(memory cell) の導入により,RNNが持っていた「長期記憶の消失」の課題を少し解決
- LSTMはRNNの隠れ状態の代わりに、「記憶セルブロック」を再帰する構造でより「長期の記憶」も短期の記憶に加えて使用できる.記憶セル内では「全結合層 + 活性化関数」の出力値を重み付け係数として利用することで,他経路の値の調整度を学習するゲート機構(gating mechanism)を利用
-
技術のキモ
-
忘却ゲート
- 長期記憶から情報を「忘れる」ための制御
- 忘却率はシグモイドで表現
-
入力ゲート
- 入力Xtと1つ前のセルの隠れ状態ht-1を基に、現在のセルの状態Ctを計算
- この値が新たに長期記憶に追加する情報
- ただ、全ての情報を長期記憶するわけではなく、必要な情報だけ保存する方が効率的
-
出力ゲート
- XXX
-
メモリセル
- メモリセルの更新は、主に入力ゲートと忘却ゲートの組み合わせによって行われる
-
忘却ゲート

GRU (Gated Recurrent Unit)
-
概要
- 元々GRUは、機械翻訳のseq2seqのRNNに、LSTMのブロックの代わりに使用することが提案
- LSTMの簡易版的な存在。LSTMの3つのゲートから、出力ゲートを無くして2ゲート構成にして、計算効率化・軽量化を狙ったLSTMの改善版
- 次時点に渡す状態 = 更新度合い x 前の時刻の状態 + ( 1- 更新度合い) x 現時点での状態
- GRUは,異なる時間スケール間での依存関係について,適応的に「覚える(remember) v.s 忘れる(forget)」の割合を調整する仕組み
- GRUは、シングルレイヤーのRNNよりも、長期的な依存関係を捉えることができるため、自然言語処理や音声認識などのタスクに適している
-
ユースケース
- 動画認識や言語処理などにおいて、中~高次元の特徴ベクトルを使う場合にはGRUの方が計算性効率が良い.
- 1次元の生波形をそのまま特徴化しないで解析する場合など、入力特徴ベクトルが低~中次元ベクトルであり、なおかつ系列長もあまり長くない対象であればLSTMで十分
- GRUは,省略前のLSTMほどの長期記憶性能は持ち合わせいないので、GRUだと性能が出ない場合にはLSTMのほうが予測性能が良くなる場合もある
-
技術のキモ
-
リセットゲート
- 過去の状態からどのくらい情報を捨てるかを決定
-
更新ゲート
- 過去の状態からどのくらい情報を取り入れるかを決定
-
リセットゲート


Seq2Seq
- 概要
- 入力された系列データを別の形式に変換するモデル
- エンコーダーデコーダーモデルとも呼ばれる
- エンコーダからデコーダへの情報伝達が固定次元のベクトルで行われる
Attention
- Seq2Seqモデルは、長い系列データに対しては性能が低下しやすいことが指摘されている
Global Attention機構
- Attention機構を系列データ全体に適用
- デコーダの各タイムステップにおいて、エンコーダのすべての隠れ状態に対してattention機構で重みを計算し、コンテキストベクトルを生成
Local Attention機構
- Attention機構を系列データの一部分に限定して適用
- デコーダの各タイムステップにおいて、エンコーダの隠れ状態の中から特定の「注目位置(alignment position)」をまず推定し、その周辺の一定範囲内の隠れ状態に対してのみattention機構で重みを計算
- 「系列データ内のどの部分に注目すべきか」を特定すること
- 系列データが長いとすべてのデータから適切な注目箇所を選択するのは困難だから、「注目すべき箇所はこの付近である」 というおおよその検討をつける
Transformer
-
概要
- 再帰的な構造を持つRNN系モデルでは並列計算ができない課題
-
技術
-
Self-Attention機構
-
Source Target Attention機構
-
Masked Attention機構
- 単語の先読みを禁止する処理を施したAttention機構
- 対象とする単語の位置より後ろの参照をしないように制約を加える
- 参照したくない部分に対して極端に小さい値を設定することで、softmaxのoutputを0にする
-
Multi-Head Attention機構
- 入力を複数に切り分け変換し、それぞれ異なる重み行列を適用した複数のAttentionを同時に計算し、それを結合するAttention機構
- QKV計算ベースのスケール化ドット積アテンションを構成部品として,アテンションの並列計算を行う
- 初期Transformer論文ではReLUが使用されていたが,BERT/GPTの頃にGELUが代わりに使われて以降,Transformer系ネットワークではGELUの使用が,各論文では一般的となった
-
位置符号化 (Positional Encoding)
- 単語の順序や位置情報を保持するために、三角関数を用いて位置に基づいた値を算出し、各単語の埋め込みに付与する手法
- 三角関数ベースの,周期的関数による位置符号化が,広く使用されるようになったこともあり,「位置符号化」と書いた場合には「Transformerで提案された,サイン関数型のトークン位置符号化」を実質的にさすことが多い
- 「位置符号化 v.s 位置埋め込み層」の2者は,どちらのほうが性能が上になるかは,ネットワーク構造やタスクなどによって異なり,「両者はどちらが良いとは言えず,どちらも使われる」という状況
- https://cvml-expertguide.net/terms/dl/seq2seq-translation/transformer/positional-encoding/
-


汎化性能 Tech
EDA (Easy Data Augmentation)
-
CVにおいて実装されているデータ拡張の手法をNLPに適用した手法
-
ランダムスワップによって拡張された文章は元のラベルの意味合いを保持することが示されている
1. 同義語置換
2. ランダム挿入
3. ランダムスワップ
4. ランダム削除 -
NLPにおけるMixUpは2種類
-
- 単語埋め込みによるベクトル化を行ってMixUp
-
- RNNなどのモデルがエンコーダとなってベクトル化したものにMixUp
※どちらも「ベクトル化されてからの処理」ってのが肝- モデルによるエンコードか単語の埋め込みが必要
-
アンサンブル
- 投票方法
-
ハード投票
- 多数決によって最終的な予測結果を決定
-
ソフト投票
- 各分類器の確率を平均し、最も確率の高いクラスを予測クラス
-
ハード投票

バギング
- 複数の弱学習器を並行して学習させ、その予測結果を統合する方法
- Bootstrap aggregatingから派生した名称
- 訓練用データの部分集合をリサンプリングするためにブートストラップが用いられている
- 利点
- モデルのバリアンスを小さくし、過学習を防ぐ
- 代表例 : ランダムフォレスト
ブースティング
- モデルを直列に並べ、順に学習していくアンサンブル手法
- モデルのバイアスを下げる
- 手法
- AdaBoost、勾配ブースティング、LightGBM
スタッキング
- ブレンディング法
- 複数の分類器の重みつき出力を次のモデル層の入力として使用
- バイアスとバリアンスをバランスよく調整
総合問題
Data Aug
- 画像の不自然な彩度
- v2.ColorJitter 引数の saturation の設定が原因
- 彩度を適切に調整することで、画像はより自然に見え、訓練データとしての質が上がる
- コントラスト、明度、色相の変更では、彩度に関する部分は解決されない


CLIP (Contrastive Language-Image Pretraining)
- テキストと画像の対応関係を学習するモデルであり、画像生成を直接行う拡散モデルではない