説明可能なAI(Explainable AI:XAI)の各手法調査(1)
機械学習モデルは基本的にブラックボックスになっているものが多く、予測の根拠が分かりづらい。そこで、XAI(Explainable AI)と呼ばれる説明可能性の高い機械学習モデル・手法を用いることで、モデルの判断基準や根拠などを可視化することが出来る。
調査の足掛かりとしてXAIについてのサーベイ論文を使用し、それぞれの手法を個別に調べていく。
XAI(Explainable AI)とは
XAIとは、その名の通り「説明可能なAI」のことで、主に機械学習モデルやそれに対する手法のことを指す。「○○なAI」と付いているが、既存の機械学習モデルに何かしらの手法で説明性を向上させるような手法もXAIと呼ばれる。
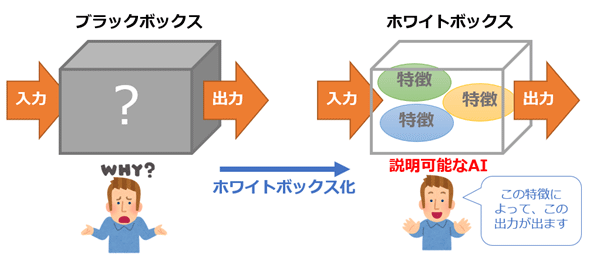
(https://atmarkit.itmedia.co.jp/ait/articles/1908/19/news022.html より引用)
上の図の左側のように機械学習モデルは内部構造がブラックボックスになっていることが多い。例えば、ニューラルネットワークなどは複雑なモデル構造に加えて多数の重みを持つため、各層の計算の様子を見てもどうやってモデルが出力値を生成しているのか人間には判断しづらい。そのため、「ほとんどの場合は出力値が正しいんだけど、たまにおかしな値が出る」というようなことが良く起こるが、その原因を探ることが非常に難しい。
そこで、機械学習モデルの内部構造を可視化し、「どうしてこの出力値になったのか」というのを”人間に分かるように”してあげること(手法・モデルなど)をXAIと言い、それによって以下のような恩恵を受けることが出来る。
- 機械学習モデルのデバックがしやすい
- 予測結果を信頼することが出来る
- 判断基準自体に価値があることもある
各手法
この記事で紹介する各手法は以下のような時系列で発表されている。
時系列順に一つずつ、調べていったことのメモを書いていこうと思う。
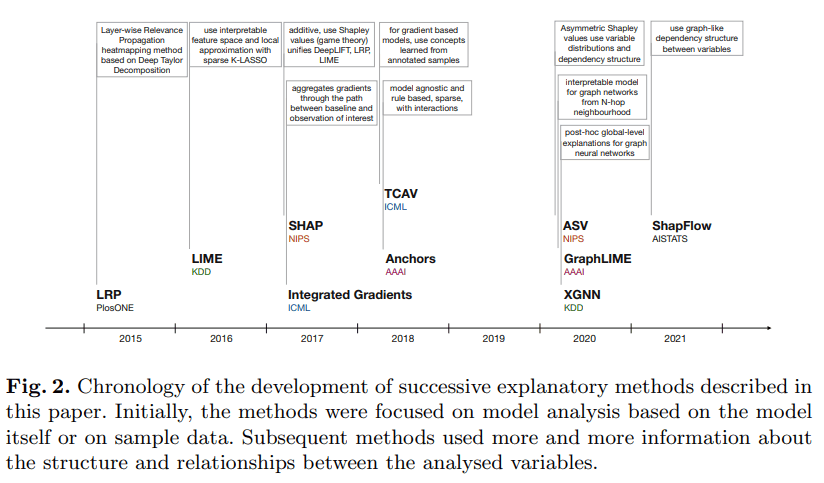
(https://link.springer.com/chapter/10.1007/978-3-031-04083-2_2 より引用)
それぞれの手法の論文を読むと結構時間かかりそうなので、二回に分けて記事を作ろうと思う。今回はIntegrated Gradientsまで書く。
LRP(Layer-Wise Relevance Propagation)
日興証券の研究組織が株式リターン予測モデルの解釈にLRPを使用している。
LRPの説明として以下のようなことが書いてある。
LRP(Layer-Wise Relevance Propagation)は深層学習の解釈手法の一つである。出力に対する各 入力の貢献度合いの総和は各レイヤー間で等しく、伝搬する中でその配分を変動させているという仮定 のもと、一度通常通りに深層学習にデータを入力し出力層まで順伝搬させた後に、レイヤー間の関係性 を出力層から入力層まで層ごとに逆伝搬することで、最終的に各入力値の出力値に対する関係性を貢献 度として計算することができる。図表 4 がその順伝搬と逆伝搬のイメージを示し、(式 10)、(式 11)は 一つの層のあるユニットにおける出力値に対する貢献度の逆伝搬の計算式を示している。これを出力層 から入力層まで遡って計算することにより、深層学習の予測において予測サンプルごとにその出力値に 対する各入力値の貢献度を算出することができる。
かみ砕いて説明すると、ニューラルネットワークモデルの一つの入力を順伝搬させ予測をし、それに対して逆伝搬を行って各セルの重みの”勾配”を求める。その勾配は、言い換えると、「重みを動かすとどれくらい予測値が動くか」を意味するため各入力値に対応する”貢献度”とすることができる。そのため、LRPでは勾配を各入力値の重要度としている。
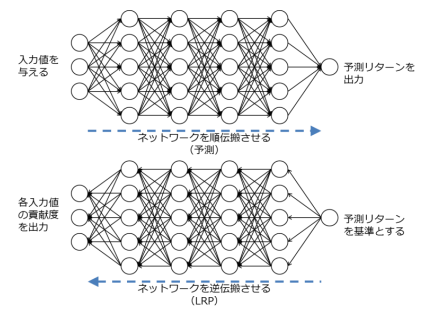
(https://www.nikko-research.co.jp/wp-content/uploads/2019/10/rr_202003_iit01.pdf より引用)
以下のような特徴を持っている。
- 深層学習モデルに依存している
- 一つの入力に対して解釈を出力できる
- 一度の予測で貢献度(重要度)も算出できる
- 貢献の正負を判別できる
また、pytorchの実装などがgithubで公開されているが、ライブラリ自体には組み込まれていないと思う(よく探したらあるかもしれないが...)。
LIME
論文
上記論文のabstractを一部抜粋すると、
In this work, we propose LIME, a novel explanation technique that explains the predictions of any classifier in an interpretable and faithful manner, by learning an interpretable model locally varound the prediction. We also propose a method to explain models by presenting representative individual predictions and their explanations in a non-redundant way, framing the task as a submodular optimization problem. We demonstrate the flexibility of these methods by explaining different models for text (e.g. random forests) and image classification (e.g. neural networks). We show the utility of explanations via novel experiments, both simulated and with human subjects, on various scenarios that require trust: deciding if one should trust a prediction, choosing between models, improving an untrustworthy classifier, and identifying why a classifier should not be trusted.
"LIMEはブラックボックスとなっているモデルの入出力関係を局所的に解釈可能なモデルで学習を行う。これらは自然言語や画像などさまざまなモデルに対して適用可能。"というようなことが書いてある。
あまり詳しく読んでいないので仕組みが良く分かっていないが、論文の説明と下記の図をみると、「特定の入出力の付近でいくつか入出力関係をサンプリングし、その周辺のみの情報を考慮した線形モデルで入出力の関係を学習させる。線形モデルなので各入力値の貢献度は容易に測れるため、それをもとのモデルの解釈性として扱う。」といった感じだと思う。
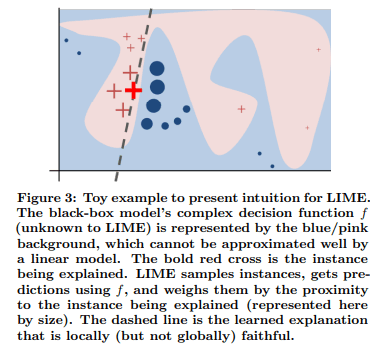
(https://arxiv.org/pdf/1602.04938.pdf より引用)
ただし以下の注意が必要。
- ”局所的な学習”を行っているため、全体をみると元のモデルと判断基準が異なっている
- そもそも別のモデルで入出力の関係を学習しているためモデル性能が異なっている
また、自然言語や画像は単語、スーパーピクセルを一つの単位として扱い同様に線形モデルで学習を行うらしい。そのため、画像などでは以下のように重要と思われるスーパーピクセルが抜き出される。(※スーパーピクセルとは、色、テクスチャなどが似ている部分をまとめた小さい領域のこと。)

(https://arxiv.org/pdf/1602.04938.pdf より引用)
LIMEはpythonでの実装がされており、下記のリポジトリに詳細な使い方や出力例が記されている。
(あと、リポジトリに分かりやすい説明が書いてあったのを論文読んでから見つけた...)
Intuitively, an explanation is a local linear approximation of the model's behaviour. While the model may be very complex globally, it is easier to approximate it around the vicinity of a particular instance. While treating the model as a black box, we perturb the instance we want to explain and learn a sparse linear model around it, as an explanation. The figure below illustrates the intuition for this procedure. The model's decision function is represented by the blue/pink background, and is clearly nonlinear. The bright red cross is the instance being explained (let's call it X). We sample instances around X, and weight them according to their proximity to X (weight here is indicated by size). We then learn a linear model (dashed line) that approximates the model well in the vicinity of X, but not necessarily globally. For more information, read our paper, or take a look at this blog post.
SHAP
論文
分かりやすい解説記事
上記論文で提案されているフレームワークであるSHAPは解説記事内で以下のように説明されている。
SHAP(SHapley Additive exPlanations)は、協力ゲーム理論のシャープレイ値(Shapley Value)を機械学習に応用したオープンソースのライブラリです。シャープレイ値をそのまま算出するには、変数の数が増えると組み合わせが増えて計算量が膨大になってしまいます。そこで算出方法を工夫することで現実的な計算時間でシャープレイ値を機械学習で扱えるようにしたものが SHAP です。
SHAPに用いられるシャープレイ値は複数のプレイヤーの協力によって得た利得を上手く各プレイヤーに分配する手段で、それぞれのプレイヤーによって貢献度を算出し、それに基づいて利得の配分を行う。解説記事に分かりやすい説明が書いてあった。
SHAPではそのシャープレイ値を近似して求める方法が提案されており、下記の実装されている。
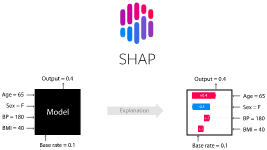
(https://github.com/slundberg/shap より引用)
また、SHAPには以下のようにいくつかの種類がある。
- モデル依存型
- Linear SHAP
- Low-Order SHAP
- Max SHAP
- Deep SHAP(DeepLIFT + Shapley values)
- モデル非依存型
- Kernel SHAP(Linear LIME + Shapley values)
代表的なのはKernel SHAPだと思う。LIMEを用いて特定の入出力の局所的な学習を行ったあと、特徴量のサブセットごとの予測値・貢献度を使ってシャープレイ値を計算する(特徴量サブセットが膨大な場合はおそらくランダムにサンプリングしてきているはず)。
SHAPとLIMEの違いは、シャープレイ値を用いることでより正確な(前後関係なども考慮した)貢献度を出せるところだと思う。LIMEでは線形モデルで近似してそれをL1回帰などで特徴量重要度を可視化していたりするが、SHAPはその特徴量がある/ない場合にどう貢献度が変わるかを複数のパターンで計測し、総合的な貢献度を算出する。
ただし、SHAPはLIMEの学習以外にも複数回モデルの予測を行う必要があるため(複数パターンの貢献度算出のため)、LIMEよりも貢献度の算出に時間がかかるというデメリットがある。これは元のモデルの推論が重ければ重いほど顕著に差が表れる。(でもそもそも大きいモデルをLIMEで近似するのは無理があるような気がするけど...)
これらを加味して特徴を書いてみる。
- LIMEよりも正確な貢献度の算出だが、遅い
- 自然言語、画像などさまざまな入力に対応
- データ・モデルによっていくつか種類がある
IG(Integrated Gradients)
論文
※論文を軽く読んでみたが、もしかしたら間違った理解をしているかもしれない。(なんかあんまり理解できている気がしない...)
IG(Integrated Gradients)はニューラルネットワークモデルの解釈性を上げる手法の一つで、原理としてはLRPと似ている。LRPではニューラルネットワークの出力から入力へ逆伝搬させ単一のレイヤの勾配をそのまま特徴量の重要度としていた。しかし、IGでは入力から出力までのパス上にあるすべての勾配を足し合わせ(論文中では勾配の積分を求める、と書いてあった)、総合的な勾配を特徴量の重要度としている。
上はIGを算出する式を表している。右辺の第二項は先ほど説明した通りの総合的な勾配を求めるための積分となっている。また、勾配だけでは特徴量間でスケールが違うために範囲の大きい特徴量が小さい勾配になる傾向があり、正しくそれぞれの重要度を比較することが出来ない。そのため、右辺の第一項に基準入力から与えられた入力の差をそれぞれの特徴量でかけてあげることで、特徴量間で重要度が比較できるようになる(各特徴量を正規化しているような感じ)。
IGの実装はTensorFlow、pytorch(Captum)などがサポートしている。
この例では画像の入力データを使っているが、IG自体はニューラルネットワークモデルであれば特にモデル構造を問わないため自然言語や表形式のデータにも用いることが出来る。
この手法の特徴は以下のような感じ。
- LRPよりも正確な貢献度の算出
- TensorFlow, pytorchの実装がある
- ニューラルネットワークモデルに依存するが、データ形式は依存しない
Discussion