機械学習モデルの予測根拠を可視化:LightGBM × SHAP入門
📌はじめに
前回記事 では、LightGBMと決定木モデルの精度差を確認しました。
今回はその続きとして、LightGBMをもう少し深掘りしてみたいと思います。
📌サンプルデータ
今回も前回と同じデータを使用します。

sample_car_data.csv`(N = 400)
詳細な説明は 前回記事 を参照ください。
📌フォルダ構成
├─ 1_flow/
│ └─ shap_analysis.py # 実行スクリプト
├─ 2_data/
│ └─ sample_car_data.csv # サンプルデータ
├─ 3_output/ # 出力用(自動作成)
📌環境
python3.x
📌コード解説(shap_analysis.py)
#============================================
# 0. ライブラリと変数設定
#============================================
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語対応
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score, f1_score, ConfusionMatrixDisplay
from sklearn.tree import DecisionTreeClassifier, plot_tree
import lightgbm as lgb
import shap
import sys
# 変数
INPUT_FOLDER = '2_data'
OUTPUT_FOLDER = '3_output'
# カラム名設定
ID = 'customer_id'
# 目的変数(予測したい項目)
target_col = 'manufacturer'
# 説明変数(モデルの入力に使う数値カラム)
numeric_cols = ["family", "age", "children", "income"]
# パス設定
parent_path = os.path.dirname(os.getcwd())
input_path = os.path.join(parent_path, INPUT_FOLDER, 'sample_car_data.csv')
output_path = os.path.join(parent_path, OUTPUT_FOLDER)
# フォルダがなければ作成
os.makedirs(output_path, exist_ok=True)
save_Fe_path = os.path.join(output_path, "比較用_LightGBM_Feature.png")
save_lgb_path = os.path.join(output_path, "正解クラスの予測順位.png")
save_Matrix_path = os.path.join(output_path, "Confusion_Matrix.png")
save_name = os.path.join(output_path, "メーカー別_SHAP_特徴ランキング.csv")
save_name_3 = os.path.join(output_path, "predictions_with_top3.csv")
#============================================
# 1.CSV読み込み
#============================================
try:
df = pd.read_csv(input_path, encoding="utf-8")
except UnicodeDecodeError:
df = pd.read_csv(input_path, encoding="cp932")
0. ライブラリと変数設定
-
lightgbm: 高速で精度の良い勾配ブースティングモデル -
shap: モデルの特徴量の重要度(解釈)分析 -
japanize_matplotlib: Matplotlibのグラフ内に日本語を正しく表示するためのライブラリ -
ID: 顧客ごとの識別用 -
target_col: 予測したい目的変数(manufacturer) -
numeric_cols: モデルの説明変数として利用する数値データの列名リスト -
os.makedirs(output_path, exist_ok=True): 出力フォルダが存在しない場合、自動で作成
1. CSV読み込み
-
UTF-8で読めなければ、Windows日本語(cp932)で再読み込み - これにより文字化けを防ぎ、異なる環境でも同じコードが動くようになる
#============================================
# 2.カテゴリ列自動判定
#============================================
exclude_cols = [ID, target_col]
categorical_cols = [col for col in df.columns if col not in exclude_cols + numeric_cols]
df[categorical_cols] = df[categorical_cols].astype("category")
#============================================
# 3.説明変数と目的変数
#============================================
X_df = df.drop([ID, target_col], axis=1)
y_df = df[target_col]
#============================================
# 4.ラベルを0始まりに変換(LightGBM対応)
#============================================
le = LabelEncoder()
y_enc = le.fit_transform(y_df)
class_names = [str(c) for c in le.classes_]
# クラス数(カテゴリーの種類)を確認
classes = np.unique(y_df)
print("クラス:", classes)
#============================================
# 5.データ分割(test_size指定なし → デフォルト25%)
#============================================
X_train, X_test, y_train, y_test = train_test_split(
X_df, y_enc, random_state=0, stratify=y_enc
)
print("訓練データ数:", len(X_train))
print("テストデータ数:", len(X_test))
2.カテゴリ列自動判定
-
exclude_cols: 「customer_id」と「manufacturer(目的変数)」はカテゴリ判定から除外 -
categorical_cols: 数値カラム以外の残りの列をカテゴリ列として抽出 -
astype("category"): Pandasのカテゴリ型に変換
→ メモリ使用量を削減し、LightGBMなどのアルゴリズムで学習が高速化される場合があります
3.説明変数と目的変数
-
X_df:説明変数(ID と目的変数を除いた列すべて) -
y_df: 目的変数(manufacturer=メーカー名)
4.ラベルを0始まりに変換(LightGBM対応)
- LightGBMでは、クラスラベルが
0から始まる整数であることが推奨されます -
LabelEncoder: 文字列や任意のラベルを0,1,2…の整数に変換 -
class_names: 元のクラス名を保持しておき、予測結果の解釈に利用 -
np.unique(y_enc):実際に変換されたクラス値を確認
5.データ分割(test_size指定なし → デフォルト25%)
- 訓練データ: モデルの学習に使用
- テストデータ: 精度評価に使用
-
stratify=y_enc: クラスの比率が元データと同じになるよう分割 -
random_state=0: 再実行しても同じ分割結果になるよう乱数シードを固定
出力例
クラス: [0 1 2 3 4 5 6]
訓練データ数: 300
テストデータ数: 100
#============================================
# 6.LghtGBMモデル(訓練/テスト分割で学習)
#============================================
objective = `binary` if len(class_names) == 2 else `multiclass`
metric = `binary_error` if objective == `binary` else `multi_error'`
params = {`objective': objective, 'metric': metric, 'verbose`: -1}
if objective == `multiclass`:
params[`num_class`] = len(class_names)
# 訓練データで学習
lgb_train = lgb.Dataset(X_train, label=y_train, feature_name=X_df.columns.tolist())
lgb_model = lgb.train(params, lgb_train, num_boost_round=50)
# 予測
y_pred_lgb_prob = lgb_model.predict(X_test)
y_pred_lgb = (y_pred_lgb_prob > 0.5).astype(int) if objective==`binary` else np.argmax(y_pred_lgb_prob, axis=1)
if objective == 'binary':
y_pred_lgb = (y_pred_lgb_prob > 0.5).astype(int)
else:
y_pred_lgb = np.argmax(y_pred_lgb_prob, axis=1)
#============================================
# 7.SHAP値計算
#============================================
# TreeExplainerを使う場合
explainer = shap.TreeExplainer(lgb_model)
shap_values = explainer.shap_values(X_df) # これでNumPy配列が返る
# binary / multiclassで形状が変わる
if objective == "binary":
print("SHAP values shape:", shap_values.shape) # (n_samples, n_features)
else:
print("SHAP values shape:", [v.shape for v in shap_values]) # クラスごとの配列
6.LghtGBMモデル(訓練/テスト分割で学習)
-
objective:- クラス数が2 →
binary(二値分類) - クラス数が3以上 →
multiclass(多クラス分類)
- クラス数が2 →
-
metric: 分類間違い率(error)を評価指標として設定 -
num_class: 多クラスの場合はクラス数を指定 -
verbose=-1:学習中のログを非表示
データセット作成 & 学習
-
lgb.Dataset: LightGBMが効率的に扱える専用データ形式に変換 -
num_boost_round=50: 決定木を50回生やして学習(ブースティング回数) -
lgb.train: モデル学習を実行
予測
- 二値分類: 予測確率が 0.5 を超えればクラス1、以下ならクラス0
- 多クラス分類: 各クラスの予測確率の最大値を持つクラスを予測結果とする
7.SHAP値計算
-
SHAP(TreeExplainer): 木構造モデル(LightGBMやXGBoost)向けの高速SHAP計算クラス -
explainer.shap_values(X_df): 各サンプル × 特徴量の寄与度を計算 -
形状の違い
-
binary:(n_samples, n_features)の2次元配列 -
multiclass: クラスごとのSHAP配列のリスト(例:クラス7個なら7配列)
-
出力例
SHAP values shape: [(400, 13), (400, 13), (400, 13), (400, 13), (400, 13), (400, 13), (400, 13)]
❓SHAP値とは❓
特徴量が「予測をそのクラスに寄せた度合い」を数値化したもの
- 正の値 : 予測クラスに寄与
- 負の値 : 他クラスに寄せる方向に作用
❓SHAP values shape とは❓
1. 多クラス分類ではクラスごとにSHAP値が計算される
- shap_values は「配列のリスト」になり、要素数はクラス数と同じです。
2. 今回のケース
- クラス数:7(メーカー7種類)
-
shap_valuesの要素数:7(クラス0〜クラス6)
3. 各要素の形状 (400, 13) の意味
- 400 … データサンプル数(今回の例では全データで計算しているので400行)
- 13 … 特徴量の数(numeric_cols と categorical_cols を合わせた数)
4. 対応関係の例
-
shap_values[0]→ クラス0(メーカーA)の寄与度行列(400行×13列) -
shap_values[1]→ クラス1(メーカーB)の寄与度行列 - …
-
shap_values[6]→ クラス6(メーカーG)の寄与度行列
#============================================
# 8.精度評価
#============================================
print("【LightGBM】 Accuracy:", accuracy_score(y_test, y_pred_lgb))
print("【LightGBM】 F1 Score:", f1_score(y_test, y_pred_lgb, average='weighted'))
#============================================
# 9.混同行列
#============================================
fig, ax = plt.subplots(figsize=(6, 5))
ConfusionMatrixDisplay.from_predictions(y_test, y_pred_lgb, ax=ax)
ax.set_title("LightGBM Confusion Matrix")
plt.tight_layout()
plt.savefig(os.path.join(save_Matrix_path), dpi=300)
plt.show()
8.精度評価
出力例
【LightGBM】 Accuracy: 0.73
【LightGBM】 F1 Score: 0.7273653962492439
-
Accuracy(正解率)
- 予測が正解だった割合
- 例:100件中73件正解 → 0.73(73%)
-
F1 Score
- 適合率(Precision)と再現率(Recall)の調和平均
- average=
weighted: クラスごとの件数に応じて平均を取るため、多クラス分類でも偏りを抑えて評価可能
9.混同行列(Confusion Matrix)
-
ConfusionMatrixDisplay.from_predictions: 可視化- 行: 実際のクラス
- 列: 予測されたクラス
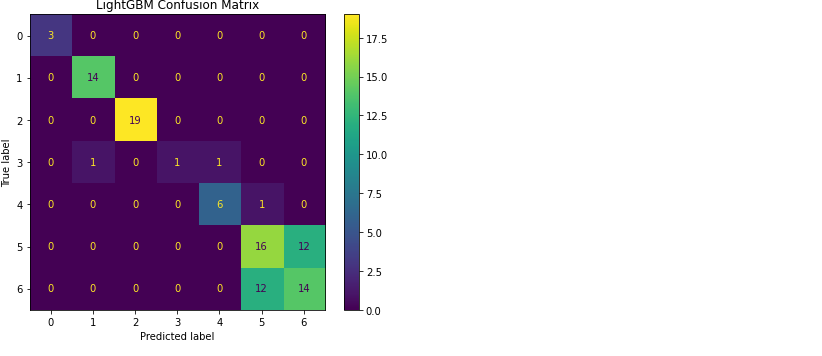
解読方法は 前回記事 を参照ください。
今回の結果の解釈
- Accuracy ≈ 0.73、F1 ≈ 0.73 → Precision と Recall のバランスは比較的良い
- とはいえ精度は「まずまず」レベルで、さらなる特徴量追加やモデル改善で向上の余地あり
- 今回はサンプルデータを使用しているため、この程度の精度でも自然な結果
#============================================
# 10.特徴量重要度
#============================================
ax = lgb.plot_importance(lgb_model, max_num_features=10)
plt.title("LightGBM Feature Importance")
plt.savefig(os.path.join(save_Fe_path), dpi=300)
10.特徴量重要度(Feature Importance)
-
lgb.plot_importance
- 学習したLightGBMモデルから、予測にどの特徴量がどれだけ貢献したかを可視化
-
max_num_features=10: 上位10個の特徴量を表示

❓特徴量重要度とは❓
モデルが学習中に「どの特徴量をどれだけ使ったか」「予測にどの程度影響を与えたか」を数値化した指標です。
LightGBMではデフォルトで importance_type='split' が使われ、分割に使われた回数で重要度を計算します。
❓なぜX軸が「400件」を超えるの❓
データ数ではなく分割回数をカウントしているためです。
- LightGBMは複数本の決定木を作る
- 1本の木には多くの分岐(ノード)がある
- ある特徴量が分岐条件に使われるたびに1回カウント
- その合計回数がX軸に表示される
例
- データ数: 400件
- 木の本数: 100本
- 特徴量「income」が分岐条件に使われた回数 → 合計2,507回
#============================================
# 11.LightGBMパラメータ設定
#============================================
params = {
'objective': 'multiclass',
'metric': 'multi_error',
'num_class': len(classes),
'verbose': -1
}
#============================================
# 12.学習(100回で学習)
#============================================
lgb_model = lgb.train(params, lgb_train, num_boost_round=100)
#============================================
# 13.全データに対する予測
#============================================
y_all_pred_prob = lgb_model.predict(X_df.values) # 予測確率
y_all_pred = np.argmax(y_all_pred_prob, axis=1) # 予測クラスラベル
#============================================
# 14.上位3候補の抽出
#============================================
top3_classes = np.argsort(y_all_pred_prob, axis=1)[:, ::-1][:, :3]
top3_probs = np.sort(y_all_pred_prob, axis=1)[:, ::-1][:, :3]
#============================================
# 15.元データに結果を追加
#============================================
df["predicted_manufacturer"] = y_all_pred
for i in range(y_all_pred_prob.shape[1]):
df[f"prob_class_{i}"] = y_all_pred_prob[:, i]
-
# 上位3クラスと確率の列を追加
for i in range(3):
df[f"top{i+1}_class"] = top3_classes[:, i]
df[f"top{i+1}_prob"] = top3_probs[:, i]
print(df[[
target_col, # 正解ラベル
"predicted_manufacturer", # モデルの予測
"top1_class", "top1_prob", # 1位予測と確率
"top2_class", "top2_prob", # 2位予測と確率
"top3_class", "top3_prob" # 3位予測と確率
]].head())
11.LightGBMパラメータ設定
- 多クラス分類用に設定
-
num_class: クラス数
verbose = -1: 学習中のログ非表示
12.学習(100回で学習)
- 決定木を100回更新してモデル学習
- 先ほどの50回より学習回数を増やし、精度向上を狙う
13.全データに対する予測
-
predict: 各クラスの確率を返す -
argmax: 一番高い確率のクラスを予測ラベルとして採用
14.上位3候補の抽出
- 各サンプルの上位3クラスを抽出
-
[:, ::-1]: 降順に並べ替え -
top3_classes: 上位3クラスのラベル -
top3_probs: 上位3クラスの確率
15.元データに結果を追加
- 予測ラベル・確率・Top3を元のデータに追加
- 分析や出力がしやすくなる
出力例と解説
出力例
manufacturer predicted_manufacturer top1_class top1_prob top2_class \
0 5 5 5 0.971966 6
1 6 5 5 0.956341 6
2 6 6 6 0.993789 5
3 2 2 2 0.972603 5
4 6 6 6 0.924216 5
top2_prob top3_class top3_prob
0 0.024234 4 0.002167
1 0.039477 2 0.003261
2 0.005478 4 0.000453
3 0.026781 6 0.000562
4 0.069732 2 0.002905
Top-3 Accuracy: 0.998
1.0 369
2.0 26
3.0 4
Name: correct_rank, dtype: int64
解説
| 列 | 説明 |
|---|---|
| manufacturer | 正解ラベル(実際のクラス) |
| predicted_manufacturer | モデルが予測したクラス(top1_classと同じ) |
| top1_class, top1_prob | 最も確率が高かったクラスとその確率 |
| top2_class, top2_prob | 2番目に確率が高かったクラスとその確率 |
| top3_class, top3_prob | 3番目に確率が高かったクラスとその確率 |
例)1行目:
- 正解 :'manufacturer = 5'
- 予測 :'predicted_manufacturer = 5'(= top1_class)
- 確率 :'top1_prob = 0.97'(高信頼)
- top3 :'[5, 6, 4]'
#============================================
# 16.正解割合(Top-3 Accuracy)
#============================================
top3_accuracy = np.mean([
y_true in top3 for y_true, top3 in zip(df["manufacturer"], top3_classes)
])
print(f"Top-3 Accuracy: {top3_accuracy:.3f}")
#============================================
# 17.正解が topN の何番目
#============================================
def top_rank(row):
true_class = row["manufacturer"]
top_classes = [row["top1_class"], row["top2_class"], row["top3_class"]]
return top_classes.index(true_class) + 1 if true_class in top_classes else None
# 件数と割合の計算
df["correct_rank"] = df.apply(top_rank, axis=1)
print(df["correct_rank"].value_counts())
rank_counts = df["correct_rank"].value_counts().sort_index()
rank_percent = (rank_counts / rank_counts.sum()) * 100
#============================================
# 18.棒グラフの作成
#============================================
fig, ax = plt.subplots(figsize=(6, 4))
bars = ax.bar(rank_percent.index.astype(str), rank_percent.values, color='skyblue')
for bar in bars:
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2, height + 1,
f"{height:.1f}%", ha='center', va='bottom')
ax.set_title("正解クラスの予測順位(Top-k Accuracy)", fontsize=14)
ax.set_xlabel("予測順位")
ax.set_ylabel("割合(%)")
plt.ylim(0, 105)
plt.tight_layout()
plt.savefig(os.path.join(save_lgb_path), dpi=300)
plt.show()
16.正解割合(Top-3 Accuracy)
出力例
Top-3 Accuracy: 0.998
-
Top-3 Accuracy: 0.998
→ 全体のほぼ 99.8% のサンプルで、正解ラベルが Top-3 に含まれている
→ 推薦や候補提示型タスクでは非常に高い精度と評価できる
17.正解が topN の何番目(Top-3 Accuracy計算)
-
correct_rank列に、正解ラベルが Top-1/Top-2/Top-3 のどの順位に入ったかを記録 -
Noneの場合は Top-3 に入っていない(今回はほぼ存在しない) -
rank_counts: Top1, Top2, Top3 などの件数 -
rank_percent: 件数を全体で割って割合(%)に変換
出力例
1.0 369
2.0 26
3.0 4
- Top-1 正解: 369 件 → 大半が 1位予測で当たっている
- Top-2 正解: 26 件 → 2位予測で正解
- Top-3 正解: 4 件 → 2位予測で正解
18.棒グラフの作成
- 棒グラフで各順位の割合を表示
- 棒の上にパーセンテージを表示
- Top1に集中していれば、モデルの予測精度が高いことを直感的に把握可能

❓Top-k 精度(Top-k accuracy)とは❓
予測上位k個のうち、少なくとも1つが正解である確率。
#============================================
# 19.上位3寄与特徴量抽出
#============================================
results_top3 = []
for i in range(len(df)):
pred_class = df.loc[i, "predicted_manufacturer"]
# 多クラス対応
if isinstance(shap_values, list):
shap_vals = shap_values[pred_class][i, :] # 予測クラスのSHAP値を使用
features = X_df.columns.tolist()
else:
shap_vals = shap_values[i, :]
features = X_df.columns.tolist()
#============================================
# 20.上位3特徴量の抽出
#============================================
top_idx = np.argsort(np.abs(shap_vals))[::-1][:3]
top_features = [features[j] for j in top_idx]
top_values = [shap_vals[j] for j in top_idx]
# 結果をまとめる
tmp = {
"customer_id": df.loc[i, "customer_id"],
"predicted_class": pred_class,
"top1_feature": top_features[0],
"top1_value": top_values[0],
"top2_feature": top_features[1],
"top2_value": top_values[1],
"top3_feature": top_features[2],
"top3_value": top_values[2]
}
results_top3.append(tmp)
top3_df = pd.DataFrame(results_top3)
19.上位3寄与特徴量抽出(SHAP)
- 各サンプル(顧客)ごとにループ
-
pred_class:そのサンプルの予測クラス -
binary: shap_values は2次元 (サンプル数, 特徴量数) -
multiclass: shap_values はクラスごとに配列が分かれる - 予測クラスのSHAP値を取り出して使用
❓2値分類/多クラス分類とは❓
2値分類(binary classification)
- 出力(目的変数)が 2つのクラス のいずれかに分類される問題
例)Yes / No、True / False、スパム / 非スパム、購入する / 購入しない
多クラス分類(multi-class classification)
- 出力が 3つ以上のクラス に分類される問題
例)トヨタ / ホンダ / 日産、A / B / C / D(テスト評価)、動物分類
20.上位3特徴量の抽出
-
np.abs:SHAP値の絶対値で大きさ順に並べ替え -
[:3]:上位3特徴量を抽出 -
top_features:特徴量名 -
top_values:SHAP値(貢献度) -
顧客ID・予測クラス・上位3特徴量・SHAP値を辞書にまとめ、リストに追加
-
top3_dfに変換してデータフレーム形式で扱える

出力例の解説
| 列名 | 説明 |
|---|---|
| customer_id | 顧客ID |
| predicted_class | モデルが予測したクラス |
| top1_feature / top1_value | 予測に最も影響を与えた特徴量とそのSHAP値 |
| top2_feature / top2_value | 2番目に影響力のある特徴量と値 |
| top3_feature / top3_value | 3番目に影響力のある特徴量と値 |
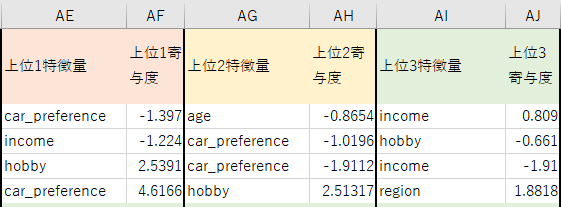
顧客ID:1で解説
| customer_id | predicted_class | 上位1特徴量 | 上位1寄与度(SHAP値) | 上位2特徴量 | 上位2寄与度(SHAP値) | 上位3特徴量 | 上位3寄与度(SHAP値) |
|---|---|---|---|---|---|---|---|
| 1 | 5 | car_preference | -2.71 | income | 1.78 | age | -1.39 |
-
上位1寄与度(SHAP値) = -2.71→ クラス「5」に対してマイナス方向に影響 -
上位2寄与度(SHAP値) = 1.78→ クラス「5」にプラス方向に影響 -
上位3寄与度(SHAP値) = -1.39→ クラス「5」にマイナス方向に影響
#============================================
# 21.重複列を削除して安全化
#============================================
df = df.loc[:, ~df.columns.duplicated()]
top3_df = top3_df.loc[:, ~top3_df.columns.duplicated()]
# 列名を統一
df = df.rename(columns={"predicted_manufacturer": "predicted_class"})
# 安全にマージ
df_merged = pd.merge(
df,
top3_df,
on=["customer_id", "predicted_class"],
how="left",
suffixes=("", "_top3") # 同名列が残っても自動で _top3 が付く
)
# 列名リネーム
rename_dict = {
"top1_feature": "上位1特徴量",
"top1_value": "上位1寄与度",
"top2_feature": "上位2特徴量",
"top2_value": "上位2寄与度",
"top3_feature": "上位3特徴量",
"top3_value": "上位3寄与度",
"prob_class_0": "メーカー0の確率",
"prob_class_1": "メーカー1の確率",
"prob_class_2": "メーカー2の確率",
"prob_class_3": "メーカー3の確率",
"prob_class_4": "メーカー4の確率",
"prob_class_5": "メーカー5の確率",
"prob_class_6": "メーカー6の確率",
"top1_class": "トップ1候補メーカー",
"top1_prob": "トップ1確率",
"top2_class": "トップ2候補メーカー",
"top2_prob": "トップ2確率",
"top3_class": "トップ3候補メーカー",
"top3_prob": "トップ3確率"
}
df_merged = df_merged.rename(columns=rename_dict)
# CSV出力
df_merged.to_csv("predictions_with_top3.csv", index=False, encoding="utf-8-sig")
21.重複列を削除して安全化
-
データフレームに重複した列がある場合は削除
-
~df.columns.duplicated():重複していない列だけを残す -
predicted_manufacturer→ 列名をpredicted_classに変更
Top3寄与特徴量とマージしやすくするため -
顧客IDと予測クラスをキーに
dfとtop3_dfを結合 -
how="left": 左側(df)を基準に結合 -
suffixes: 同名列が残る場合に_top3が自動で付く
SHAPによる可視化の意義
-
各ユーザー・サンプルごとに どの特徴量がどれくらい予測に影響したか を数値で可視化可能
→ 例:なぜこの顧客にクラス5を予測したのか? が定量的に説明できる -
特徴量ごとの プラス / マイナスの寄与度 が明示される
→ モデルの判断理由が明確になり、透明性・信頼性 が向上 -
医療・金融・レコメンドなど、説明責任が必要な領域で特に重要
→ モデル全体の重要特徴量も確認可能(グローバル解釈)
→ 重要ユーザーの要因分析や予測の根拠を社内・クライアント向けに説得力を持って提示可能
#============================================
# 22. multiclass / binary 両対応で DataFrame化
#============================================
if isinstance(shap_values, list): # multiclass
# 予測クラスに対応する SHAP 値を抽出
shap_array = np.array([shap_values[pred][i, :]
for i, pred in enumerate(df["predicted_class"].values)])
else: # binary
shap_array = shap_values
# DataFrameに変換
shap_df = pd.DataFrame(shap_array, columns=X_df.columns)
shap_df["predicted_class"] = df["predicted_class"].values
#============================================
# 23.クラスごとの SHAP値平均(特徴量別)
#============================================
summary_list = []
for cls in sorted(df["predicted_class"].unique()):
shap_mean = shap_df[shap_df["predicted_class"] == cls].drop(columns="predicted_class").mean().abs()
shap_mean_sorted = shap_mean.sort_values(ascending=False)
for feature, value in shap_mean_sorted.items():
summary_list.append({
"メーカー": cls,
"特徴量": feature,
"平均SHAP値": round(value, 5)
})
shap_summary_df = pd.DataFrame(summary_list)
# 上位N個
topN = 5
display_df = shap_summary_df.groupby("メーカー").head(topN)
# CSV保存
display_df.to_csv(save_name, index=False, encoding="utf-8-sig")
#display_df
# OS別で出力フォルダを開く
if sys.platform.startswith(`win`):
os.startfile(output_path)
`elif sys.platform.startswith(`darwin`):
subprocess.run([`open`, output_path])
else:
subprocess.run([`xdg-open`, output_path])
print(" 完了")
22.multiclass / binary 両対応で DataFrame化
- 多クラス分類(
shap_valuesがリスト):予測クラスごとのSHAP値を抽出 - 2値分類(
shap_valuesが配列):そのままSHAP値を使用 - DataFrame化:特徴量名とSHAP値を整然と管理し、集計や並べ替えを簡単に
23.クラスごとの SHAP値平均(特徴量別)
モデルの予測に影響を与える特徴量を特定し、解釈を深めます。
- 各クラスごとにSHAP値の平均を計算し、寄与度を把握
-
abs():正負を考慮せず、影響の大きさだけを評価 - 上位N個の特徴量を抽出し、予測に強く寄与する要素を特定
📌出力ファイルとSHAP解説
1️⃣ モデル予測結果と上位3寄与特徴量
predictions_with_top3.csv

| 列 | 内容 | 備考 |
|---|---|---|
| O列 | 現在の保有メーカー | 正解ラベル |
| P列 | 予測されたメーカー | モデルの予測結果 |
| Q列〜W列 | 各メーカーごとの予測確率 | 例: メーカー0の確率 = 0.0123 → 1.23% |
| X列〜AC列 | 確率上位3位までの予測クラスとその確率 | トップ1/2/3メーカーとトップ1/2/3確率 |
| AD列 | 正解のランク | 1=Top1、2=Top2、3=Top3、NaN=Top3に含まれず |
| AE列、AG列、AI列 | 上位1/2/3位の特徴量 | SHAP値の説明変数名 |
| AF列、AH列、AJ列 | 上位1/2/3位の寄与度 | SHAP値の絶対値・プラス/マイナス寄与 |
1行目の特徴量で解説
✅ car_preference(車のボディタイプ)
・ 値 = -1.397 → マイナス寄与
・ 車のボディタイプの好みが、そのメーカーを選ぶ確率を下げている
✅ age(年齢)
・ 2番目に影響、マイナス寄与
・ 年齢的嗜好やライフステージにより、そのメーカーを選ぶ確率が下がる
✅ income(収入)
・ 3番目に影響、値 = 0.808 → プラス寄与
・ 収入により、そのメーカーを選ぶ確率が高くなる
💮 結論
-
incomeがプラス寄与で選択を後押し -
car_preferenceとageはマイナス寄与で選択を抑制 - 結果、モデルは「メーカー5」を予測
2️⃣ メーカー毎の特徴量重要度(平均SHAP値)
メーカー別_SHAP_特徴ランキング.csv

| 列 | 内容 | 備考 |
|---|---|---|
| A列 | メーカー | 予測対象のクラス(0〜6) |
| B列 | 特徴量 | どの説明変数か |
| C列 | 平均SHAP値 | その特徴量がどれだけ予測に寄与したか(絶対値ベース) 値が大きいほど、その特徴量が予測に強く影響 |
メーカー0で解説
・ 影響が大きい特徴量: region, income
・ region の平均SHAP値 = 5.35 → 最も強い影響を持つ
・ 年齢や趣味といった特徴量は影響が小さい
💮 結論(メーカー0)
・ 居住地(region) と 収入(income)が購買に強く影響
・ 年齢や趣味は影響が小さく、ターゲット選定にはあまり影響しない
・ 特にregion の寄与が最も大きい(平均SHAP値 5.35)
📌ビジネス応用アイデア
この分析では、SHAP値から「特徴量ごとの寄与」を把握した上で、ターゲット層をセグメント化できます。
セグメント例と施策
| セグメント名 | 特徴 | 施策例 |
|---|---|---|
| 20代SUV好き層 | 20代、SUV、SHAPで car_preference 強 |
若者向けSUV新モデルのDM送付、SNS広告 |
| 高収入×セダン志向 | 高収入、セダン、SHAPで income が正方向 |
高級感あるセダンを訴求、ローンシミュレーション提案 |
| ファミリー層(ミニバン好き) | 同居家族多、子どもあり、ミニバン | チャイルドシート搭載可能な車紹介、家族割引 |
📌まとめ
LightGBM × SHAPはとても強力な手法だと思いますが、
他のシンプルなモデルでも十分な予測精度が得られることも多く、
無理に複雑な方法を使う必要はないな、というのが私の感想です。
個人的には、複雑すぎるアプローチに時間をかけるより、
解釈がしやすく実用的な方法を選ぶ方が現実的だと改めて感じました。
参考リンクについて
GitHubリポジトリ
本記事で紹介したコードやサンプルデータはこちらで公開しています。
👇 LightGBM vs XGBoostを比較してみました
👇 5-fold クロスバリデーションについて解説してます
Discussion