決定木 vs LightGBM を再検証!5-fold クロスバリデーションがすごい
📌はじめに
LightGBMって本当に強い?決定木と比べて検証してみた を投稿したあとに、
師匠から5-fold クロスバリデーション を教えてもらいました。
…え、クロスバリデーション?知らなかった…😇
ということで、今回は 5-fold クロスバリデーション を取り入れてコードをバージョンアップしてみました。
❓5-fold クロスバリデーションとは❓
「1回だけの分割に頼らず、何回もデータを分けて学習→評価して平均を取る」 という方法です。
例: 5-fold クロスバリデーション
データを5つに分けた場合のイメージです
データ: [D1 D2 D3 D4 D5] (5 fold)
1回目: 訓練=[D2,D3,D4,D5], テスト=[D1]
2回目: 訓練=[D1,D3,D4,D5], テスト=[D2]
3回目: 訓練=[D1,D2,D4,D5], テスト=[D3]
4回目: 訓練=[D1,D2,D3,D5], テスト=[D4]
5回目: 訓練=[D1,D2,D3,D4], テスト=[D5]
📌5-fold クロスバリデーションを使うと何が良いの❓
1️⃣ モデルの性能をしっかり評価できる
データを5つに分けて順番にテストするので、1回の分割に左右されずに、モデルの本当の性能がわかります。
2️⃣ 評価のばらつきが少なくなる
AccuracyやF1スコアを複数回計算して平均するので、数値が安定して「だいたいこれくらい」と安心して見られます。
- さらに、各 fold ごとの結果のばらつきは 標準偏差(±の値) で確認できます。
± の値が小さいほど、モデルの精度は安定していることを示します。
3️⃣ データをムダなく使える
少ないデータでも、全部のデータを訓練とテストで活用できるので、学習効率がアップします
📌コード
1️⃣ 前回コードのおさらい
# train_test_split で 1回だけ分割して評価
X_train, X_test, y_train, y_test = train_test_split(
X_df, y_enc, test_size=0.25, random_state=42, stratify=y_enc
)
dt_model = DecisionTreeClassifier(random_state=42)
dt_model.fit(X_train, y_train)
y_pred_dt = dt_model.predict(X_test)
lgb_model = LGBMClassifier(random_state=42)
lgb_model.fit(X_train, y_train)
y_pred_lgb = lgb_model.predict(X_test)
print("【DecisionTree】 Accuracy:", accuracy_score(y_test, y_pred_dt))
print("【DecisionTree】 F1 Score:", f1_score(y_test, y_pred_dt, average="weighted"))
print("【LightGBM】 Accuracy:", accuracy_score(y_test, y_pred_lgb))
print("【LightGBM】 F1 Score:", f1_score(y_test, y_pred_lgb, average="weighted"))
2️⃣ 5-fold クロスバリデーション に書き換えてみます
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
dt_acc, dt_f1 = [], []
lgb_acc, lgb_f1 = [], []
for train_idx, test_idx in skf.split(X_df, y_enc):
X_train, X_test = X_df.iloc[train_idx], X_df.iloc[test_idx]
y_train, y_test = y_enc[train_idx], y_enc[test_idx]
# DecisionTree
dt_model = DecisionTreeClassifier(random_state=42)
dt_model.fit(X_train, y_train)
y_pred_dt = dt_model.predict(X_test)
dt_acc.append(accuracy_score(y_test, y_pred_dt))
dt_f1.append(f1_score(y_test, y_pred_dt, average="weighted"))
# LightGBM
lgb_model = LGBMClassifier(random_state=42)
lgb_model.fit(X_train, y_train)
y_pred_lgb = lgb_model.predict(X_test)
lgb_acc.append(accuracy_score(y_test, y_pred_lgb))
lgb_f1.append(f1_score(y_test, y_pred_lgb, average="weighted"))
print(f"【DecisionTree】 Accuracy: {np.mean(dt_acc):.3f} ± {np.std(dt_acc):.3f}")
print(f"【DecisionTree】 F1 Score: {np.mean(dt_f1):.3f} ± {np.std(dt_f1):.3f}")
print(f"【LightGBM】 Accuracy: {np.mean(lgb_acc):.3f} ± {np.std(lgb_acc):.3f}")
print(f"【LightGBM】 F1 Score: {np.mean(lgb_f1):.3f} ± {np.std(lgb_f1):.3f}")
評価方法の部分だけで、データ前処理やモデルの宣言などは前回記事と同じです。
📌実行結果の比較
1️⃣ 単一分割(train_test_split)👈前回の
【DecisionTree】 Accuracy: 0.65
【DecisionTree】 F1 Score: 0.641
【LightGBM】 Accuracy: 0.73
【LightGBM】 F1 Score: 0.727

- 1回だけの分割で評価
- データの分け方によって結果が左右されやすい
2️⃣ 5-fold クロスバリデーション
【DecisionTree】 Accuracy: 0.680 ± 0.032
【DecisionTree】 F1 Score: 0.666 ± 0.034
【LightGBM】 Accuracy: 0.710 ± 0.024
【LightGBM】 F1 Score: 0.706 ± 0.026
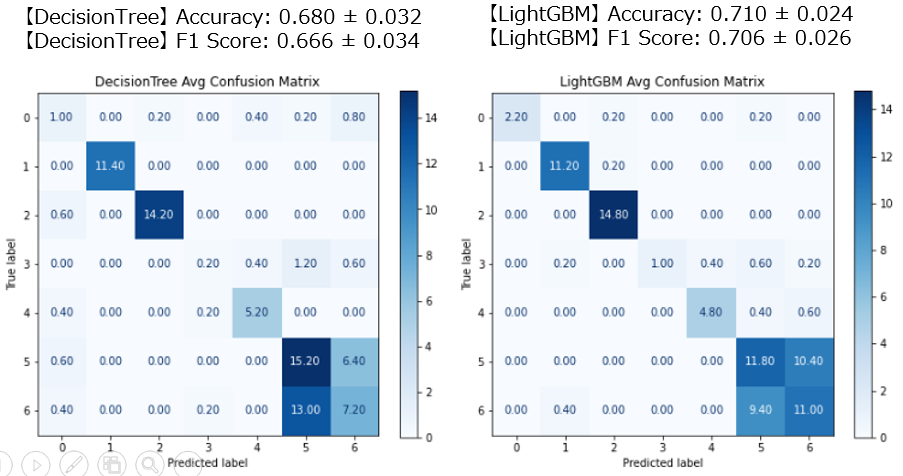
- データを5分割して5回評価 → 平均値を算出
- ± の値は fold ごとの標準偏差
- DecisionTree は平均的に少し改善(0.65 → 0.68)
- LightGBM は平均的に少し低下(0.73 → 0.71)
❓なんで数字が微妙に変わるの❓
単一分割(train_test_split)では、テストデータと訓練データを1回だけ分けて評価 しています。
だから、その1回の結果次第で精度がちょっと高くなったり低くなったりすることがあります。
一方、5-fold クロスバリデーションでは次のように評価します
- データを5つの fold に分ける
- それぞれを順番にテストデータにして学習&評価
- 5回分の精度を平均 → CV 平均
このとき fold の分け方や、LightGBM の初期値など 学習のちょっとしたランダム性 によって、各 fold の精度は少しずつ変わることがあります。
だから、平均値も単一分割のときとは少し違うのが普通なんです。
❓foldってなに❓
クロスバリデーションでデータを分割した「ひと区切り(グループ)」 のことです。
-
fold= データを分割した1グループ -
k-fold CVならk個に分けて順番にテストします
例:5-fold CV の場合、5つのグループを順番にテストに使うイメージです。
❓CV 平均ってなに❓
CV 平均 = クロスバリデーションでの評価値の平均 です。
❓なんで平均を使うの❓
1回の train_test_split だと、データの分け方次第で結果が変わる ため信頼性が低くなっちゃいます。
でも CV 平均 を使うと、複数回の評価結果を平均するので、ばらつきが慣らされてより安定した値 を得られるんです。
📌まとめ
- 単一分割の評価は 分割方法によって結果が変わりやすく 評価が安定しません
- 5-fold クロスバリデーションを使うと、より安定した推定値 を得られます
- 標準偏差を確認することで、モデルの精度の安定性 も把握できます
今回の検証では、LightGBM が必ずしも圧倒的に強いわけではないことがわかりました。
参考リンクについて
GitHubリポジトリ
本記事で紹介したコードやサンプルデータはこちらで公開しています。
Discussion