LightGBMって本当に強い?決定木と比べて検証してみた
📌はじめに
最近よく「決定木よりLightGBMの方が性能が良い」と耳にしますが、
実際にどれくらい差があるのかはイメージしにくいですよね。
そこで、簡単なサンプルデータを使って
決定木とLightGBMを比べてみることにしました。
📌サンプルデータ

sample_car_data.csv (N=400)
| ID | 説明 | 種別 |
|---|---|---|
customer_id |
ユニークID | - |
family |
同居家族 | 説明変数 |
age |
年齢(18~70歳) | 説明変数 |
gender |
性別(男性=0, 女性=1) | 説明変数 |
income |
世帯収入(万円単位) | 説明変数 |
marital_status |
配偶者の有無(0=未婚, 1=既婚) | 説明変数 |
children |
子供の人数 | 説明変数 |
region |
居住地(都市=0, 郊外=1, 地方=2) | 説明変数 |
employment_type |
雇用形態(正社員=0, 自営業=1, パート=2) | 説明変数 |
hobby |
趣味(0=アウトドア, 1=読書, 2=旅行, 3=スポーツ, 4=映画) | 説明変数 |
car_preference |
欲しい車のボディタイプ(0=SUV, 1=セダン, 2=ミニバン, 3=スポーツ, 4=その他) | 説明変数 |
previous_car_owner |
過去に車を保有していたか(0=なし, 1=あり) | 説明変数 |
previous_manufacturer |
過去の車メーカー(0=A社, 1=B社, 2=C社, 3=D社, 4=E社, 5=F社, 99=保有なし) | 説明変数 |
manufacturer |
現在保有している車のメーカー(1=A社, 2=B社, 3=C社, 4=D社, 5=E社, 6=F社) | 目的変数 |
LightGBMでのラベル数値化と0スタートの重要性
📌1. なぜ目的変数は0スタート必須なのか❓
LightGBMの多クラス分類では、label は内部で配列インデックスとして扱われます。
そのため、ラベルは 0から num_class-1 の連続整数である必要があります。
✅ 正しい例(クラス数6)
[0, 1, 2, 3, 4, 5]
num_class=6- インデックス 0〜5 が正常に利用される
❌ 間違った例(1スタート)
[1, 2, 3, 4, 5, 6]
- LightGBMは「7クラスある」と誤解
- 学習や予測が不安定になる
- 実際に精度が大きく下がることもある(今回の実験でも確認)
📌2. 説明変数は0スタート不要
| 種類 | 0スタート必要? | 備考 |
|---|---|---|
| 目的変数(ラベル) | ✅ 必須 | 多クラス分類は [0, num_class-1] 必須 |
| 説明変数(数値) | ❌ 不要 | そのまま利用可能 |
| 説明変数(カテゴリ) | ❌ 不要 | カテゴリ型に設定すればOK(整数の始点は任意) |
📌3. 今回のサンプルデータ例
- 数値列(そのまま使える)
family, age, children, income
- カテゴリ列(数値ラベルでも文字列でもOK)
gender, region, hobby, previous_manufacturer
→ pandas で astype("category") にしたり、LightGBM の categorical_feature で指定すると精度が安定します。
📌4. 補足図(イメージ)
正しい: 0 1 2 3 4 5
| | | | | |
OK OK OK OK OK OK
間違い: 1 2 3 4 5 6
[ ]OK OK OK OK OK ← クラス0が欠落
📌5. まとめ
- 目的変数は必ず0スタート整数に変換
- 説明変数は数値そのままOK、カテゴリは型を正しく設定
-
LightGBMは内部でインデックス参照するため、目的変数の前処理を忘れると精度が大きく下がることもあります
📌フォルダ構成
├─ 1_flow/
│ └─ tree_s_l.py # 実行スクリプト
├─ 2_data/
│ └─ sample_car_data.csv # サンプルデータ
├─ 3_output/ # 決定木出力画像用(自動作成)
📌環境
python3.x
📌モデル構築と評価指標
- モデル:DecisionTree と LightGBM
- 評価指標:Accuracy(正解率)と F1スコア
❓Accuracy(正解率)とは❓
全体のデータの中で、モデルが正しく予測できた割合のことです。
例えば、100件中72件正しく予測できればAccuracyは0.72(72%)となります。
❓F1スコアとは❓
正解率(Precision)と再現率(Recall)をバランスよくまとめた指標です。
- 正解率:モデルが予測した結果のうち、どれだけ正しかったか
- 再現率:実際の正解をどれだけ漏らさずに見つけられたか
特に、正解データの数に偏りがある場合(例えば「はい」と「いいえ」の件数が大きく違う場合)、Accuracyだけだと誤解が生まれやすいです。
そのため、F1スコアでバランスを確認します。
📌コード解説(tree_s_l.py)
#============================================
# 0. ライブラリと変数設定
#============================================
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score, f1_score, ConfusionMatrixDisplay
from sklearn.tree import DecisionTreeClassifier, plot_tree
import lightgbm as lgb
INPUT_FOLDER = '2_data'
INPUT_FILE = 'sample_car_data.csv'
OUTPUT_FOLDER = '3_output'
ID = 'customer_id'
target_col = 'manufacturer'
numeric_cols = ["family", "age", "children", "income"]
#============================================
# 1. パス設定
#============================================
current_path = os.getcwd()
parent_path = os.path.dirname(current_path)
input_path = os.path.join(parent_path, INPUT_FOLDER, INPUT_FILE)
output_path = os.path.join(parent_path, OUTPUT_FOLDER)
# 出力先フォルダ有無チェック
os.makedirs(output_path, exist_ok=True)
save_tree_path = os.path.join(output_path, "DecisionTree.png")
save_lgb_path = os.path.join(output_path, "LightGBM_Tree.png")
save_matrix_path = os.path.join(output_path, "Confusion_Matrix.png")
# =========================
# 2. CSV読み込み
# =========================
try:
df = pd.read_csv(input_path, encoding="utf-8")
except UnicodeDecodeError:
df = pd.read_csv(input_path, encoding="cp932")
0. ライブラリと変数設定
-
sklearn: 学習用(データ分割、ラベル変換、決定木) -
lightgbm: 高速な勾配ブースティングモデル(LightGBM) -
ID: 顧客のユニークID列 -
target_col: 目的変数(今回は manufacturer=車メーカー) -
numeric_cols: 数値のまま扱う説明変数のリスト
1. パス設定
-
os.makedirs(..., exist_ok=True): フォルダがなければ作成
2. CSV読み込み(文字コード対策付き)
- 最初に
UTF-8でファイルを読み込む - 読み込み失敗した場合は、
Shift-JIS (cp932)で再度試行
# =========================
# 3.カテゴリ列自動判定
# =========================
exclude_cols = [ID, target_col]
categorical_cols = [col for col in df.columns if col not in exclude_cols + numeric_cols]
df[categorical_cols] = df[categorical_cols].astype("category")
# ============================================
# 4.説明変数と目的変数の分離
# ============================================
X_df = df.drop([ID, target_col], axis=1)
y_df = df[target_col]
# ============================================
# 5.ラベル(目的変数)を0始まりの整数に変換(LightGBM対応)
# ============================================
le = LabelEncoder()
y_enc = le.fit_transform(y_df)
class_names = [str(c) for c in le.classes_]
print("クラス:", class_names)
# ============================================
# 6.データ分割(test_size=0.25)
# ============================================
X_train, X_test, y_train, y_test = train_test_split(
X_df, y_enc, test_size=0.25, random_state=0, stratify=y_enc
)
print("訓練データ数:", len(X_train))
print("テストデータ数:", len(X_test))
出力例:
クラス: ['0', '1', '2', '3', '4', '5', '6']
訓練データ数: 300
テストデータ数: 100
3.カテゴリ列自動判定
-
exclude_cols:ID列と目的変数列(カテゴリ変換から除外) -
numeric_cols:数値として扱う列(カテゴリ変換から除外) - それ以外の列は、
astype("category")でカテゴリ型に変換
→ LightGBM に渡すとき自動でカテゴリ扱いされる
4.説明変数と目的変数の分離
-
X_df:説明変数(ID と目的変数を除いた列すべて) -
y_df:目的変数(今回はtarget_col=メーカー名)
5.ラベル(目的変数)を0始まりの整数に変換(LightGBM対応)
-
LightGBM:多クラス分類では ラベルは[0, num_class-1]の連続整数である必要あり -
LabelEncoder:文字列のメーカー名 → 0, 1, 2, ... に変換 -
class_names:元のクラス名も保持(混同行列や木の可視化用)
6.データ分割(test_size=0.25)
-
stratify=y_enc:クラス比率を保ったまま分割 -
test_size: 25%テスト / 75%訓練 -
random_state=0:再現性を確保
❓データ分割の数値・比率の決め方は❓
機械学習では、データセットを 訓練データ(train) と テストデータ(test) に分けます。
「何件使うか/比率は?」という点について詳しく解説します。
出力例:
訓練データ数: 300
テストデータ数: 100
1. 基本ルール
- 訓練データ:モデルを学習するために使う
- テストデータ:学習済みモデルの精度を評価するために使う
- 訓練データ + テストデータ = 元のデータ全体
2. 比率で決める
| データサイズ | 訓練:テスト |
|---|---|
| 小規模(数百件) | 75:25 |
| 中規模(数千件) | 80:20 |
| 大規模(数万件以上) | 90:10 |
3. 件数で決める
-
train_test_split: 整数で件数指定も可能
例:テストデータを 100 件固定
X_train, X_test, y_train, y_test = train_test_split(
X_df, y_enc, test_size=100, random_state=0, stratify=y_enc
)
- メリット:テスト件数を固定でき、比較実験や再現性が明確
- デメリット:データ総数が変わると比率が変わるので注意
4. 比率 vs 件数 の選び方
| 選ぶ基準 | 比率 | 件数固定 |
|---|---|---|
| 再現性 | △(データ数が変わるとテスト件数も変わる) | ◎ |
| データ量が少ない場合 | ○ | △(少なすぎる場合は訓練データが減る) |
| データ量が多い場合 | ◎ | ○ |
| 実験・比較 | △ | ◎(同じ件数で比較できる) |
5. 今回の設定
- データ:400 件
- 決定木・LightGBMの比較が目的
- 安定した学習・評価のために test_size指定なし → デフォルト25%
X_train, X_test, y_train, y_test = train_test_split(
X_df, y_enc, random_state=0, stratify=y_enc
)
- 結果:訓練 300 件 / テスト 100 件
- 訓練データ:300 件でモデル学習は十分
- テストデータ:100 件で精度比較も安定
-
stratify=y_enc:クラス比率も維持
6. まとめ
- 比率で分ける:データサイズに応じて自動調整
- 件数で固定する:比較・実験に便利
- 小〜中規模データ:25~30% をテストデータにするのが無難
# =========================
# 7.決定木モデル定義
# =========================
dt_model = DecisionTreeClassifier(max_depth=5, random_state=42)
# モデル学習
dt_model.fit(X_train, y_train)
# 予測
y_pred_dt = dt_model_all.predict(X_test)
# =========================
# 8.決定木の可視化 → 全データで学習
# =========================
dt_model_all = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_model_all.fit(X_df, y_enc) # 全データで学習
plt.figure(figsize=(20,10))
plot_tree(dt_model_all, filled=True, feature_names=X_df.columns, class_names=class_names)
plt.title("scikit-learn Decision Tree")
plt.savefig(save_tree_path, dpi=300)
plt.show()
7.決定木モデル定義
-
DecisionTreeClassifier:シンプルな分類モデル -
max_depth=5:木の深さを5に制限→ 過学習防止 -
random_state=42:乱数固定で再現性確保 -
(X_df, y_enc):全400人分のデータでモデルを構築
-
dt_model.predict(X_test):テストデータに対して予測を実施(後で精度評価や混同行列で使用)
8.決定木の可視化(全データ400人で学習、可視化用)
-
plot_tree:木構造を可視化 -
filled=True:分類クラスごとに色を付ける -
feature_names:説明変数の列名をノードに表示 -
class_names:0始まり整数に変換したラベルの元の名前を表示
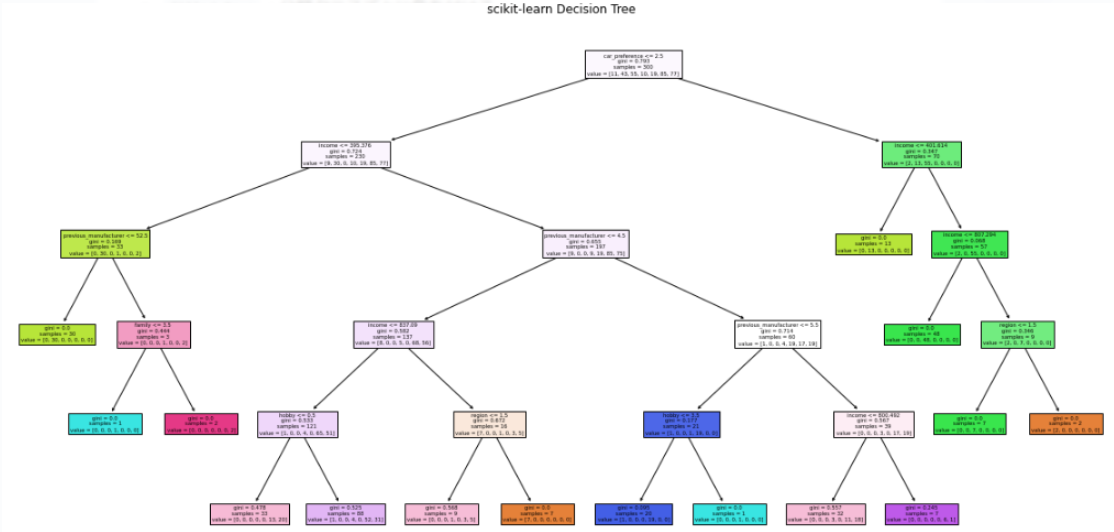
plot_treeについて
-
plot_treeはscikit-learnに標準で含まれる - 高度な描画(ラベル装飾や
Graphviz形式)を使う場合はGraphvizやpydotが必要 - 今回は Matplotlib 描画のみ : 追加インストール不要
# =====================================
# 9.LightGBMモデルの目的とパラメータ設定
# =====================================
objective = 'binary' if len(class_names) == 2 else 'multiclass'
metric = 'binary_error' if objective == 'binary' else 'multi_error'
params = {'objective': objective, 'metric': metric, 'verbose': -1}
if objective == 'multiclass':
params['num_class'] = len(class_names)
# 訓練データで学習
lgb_train = lgb.Dataset(X_train, label=y_train, feature_name=X_df.columns.tolist())
lgb_model = lgb.train(params, lgb_train, num_boost_round=50)
# 予測
y_pred_lgb_prob = lgb_model.predict(X_test)
y_pred_lgb = (y_pred_lgb_prob > 0.5).astype(int) if objective=='binary' else np.argmax(y_pred_lgb_prob, axis=1)
# =====================================
# 10.LightGBM(全データ400人で学習、可視化用)
# =====================================
lgb_all = lgb.Dataset(X_df, label=y_enc, feature_name=X_df.columns.tolist())
lgb_model_all = lgb.train(params, lgb_all, num_boost_round=50)
#木の可視化
ax_all = lgb.plot_tree(
lgb_model_all, tree_index=0, figsize=(20, 10),
show_info=['split_gain', 'internal_value', 'leaf_count']
)
plt.title("LightGBM Tree (All Data)")
plt.savefig(os.path.join(save_lgb_path), dpi=300)
plt.show()
9.LightGBMモデルの目的とパラメータ設定
-
objective: 目的変数のタイプを設定- 2クラス →
'binary' - 3クラス以上 →
'multiclass'
- 2クラス →
-
metric: 評価指標- 2クラス →
'binary_error'(エラー率) - 多クラス →
'multi_error'(エラー率)
- 2クラス →
-
num_class: 多クラス分類の場合はクラス数を明示
-
X_train、y_train:学習データ -
LightGBMのDataset: 特徴量名feature_nameを指定 -
num_boost_round=50: 学習(50回のブースティング) - 予測
- 2クラス → 確率0.5で二値に変換
- 多クラス →
argmaxで最も確率が高いクラスを予測
10.LightGBM(全データ400人で学習、可視化用)
- 学習データ : 全データ (
X_df, y_enc) - 目的 : 可視化のために全員の情報で木を作成
- 精度評価ではなく、分析や意思決定用の木構造確認に使用
-
tree_index=0: 最初の木(1本目)を可視化 -
show_info: ノードに表示する情報-
split_gain: 分割の利得 -
internal_value: ノード内の平均ラベル値 -
leaf_count: ノードに含まれるサンプル数
-

決定木とLightGBMの木の解説
決定木とLightGBMの木の構造は見た目も性質もかなり違いますね。
理由は、それぞれのモデルが木の作り方や使い方に違いがあるためです。
決定木は1本の木だけで分類を行いますが、LightGBMはたくさんの小さな決定木を順番に学習して、少しずつ予測を改善していきます。
この仕組みを「勾配ブースティング(Gradient Boosting)」と呼び、一般的に高い精度が期待できます。
分類について
-
2値分類 (
binary classification):出力が「Yes/No」など2つのクラスに分かれる問題 -
多クラス分類 (
multi-class classification):出力が3つ以上のカテゴリに分かれる問題
例:「A社 / B社 / C社」
# =========================
# 11.精度(Accuracy)と F1 スコアの計算
# =========================
print("【DecisionTree】 Accuracy:", accuracy_score(y_test, y_pred_dt))
print("【DecisionTree】 F1 Score:", f1_score(y_test, y_pred_dt, average='weighted'))
print("【LightGBM】 Accuracy:", accuracy_score(y_test, y_pred_lgb))
print("【LightGBM】 F1 Score:", f1_score(y_test, y_pred_lgb, average='weighted'))
# =========================
# 12.混同行列の表示
# =========================
fig, ax = plt.subplots(1, 2, figsize=(12,5))
ConfusionMatrixDisplay.from_predictions(y_test, y_pred_dt, ax=ax[0])
ax[0].set_title("Decision Tree Confusion Matrix")
ConfusionMatrixDisplay.from_predictions(y_test, y_pred_lgb, ax=ax[1])
ax[1].set_title("LightGBM Confusion Matrix")
plt.tight_layout()
plt.show()
11.精度(Accuracy)と F1 スコアの計算
-
accuracy_score: 正しく予測できたサンプルの割合
例:100件中80件正解 → Accuracy = 0.8 -
f1_score(average='weighted'): クラスごとの F1 スコアの加重平均- 各クラスのサンプル数に基づいて加重されるため、クラス不均衡がある場合でもバランスよく評価できます。
- 0〜1 の範囲で高いほど性能良し
-
比較 :
DecisionTree / LightGBM: 並べて確認- テストデータ上でどちらのモデルが性能良いか分かりやすい
12.混同行列の表示
- 混同行列(
Confusion Matrix)- 行:実際のクラス
- 列:予測クラス
- 対角線上が正しく予測された件数
- 例:対角線上の数字が多いほど、モデルが正しく予測した件数が多いことを意味します
-
from_predictions: 簡単に表示可能 - 1行2列で図を並べるとDecisionTree と LightGBMの違いが一目で分かる
🔍精度結果の解説
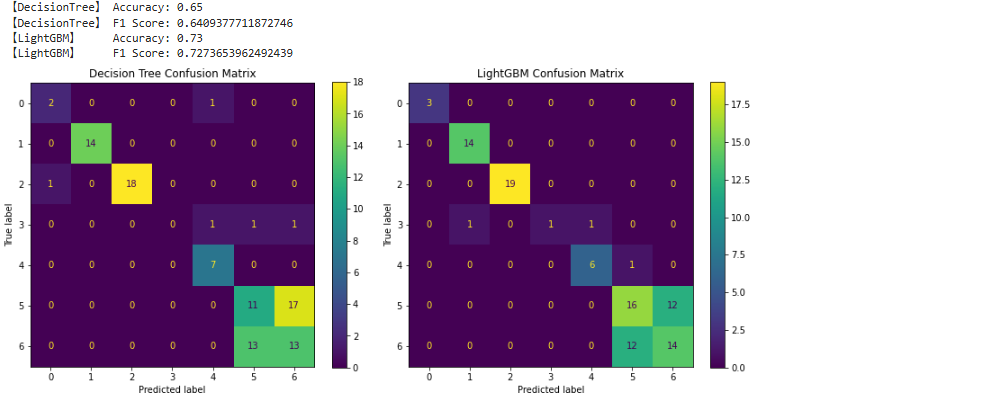
【DecisionTree】 Accuracy: 0.65
【DecisionTree】 F1 Score: F1 Score: 0.641
【LightGBM】 Accuracy: 0.73
【LightGBM】 F1 Score: 0.727
🔍混同行列の解説
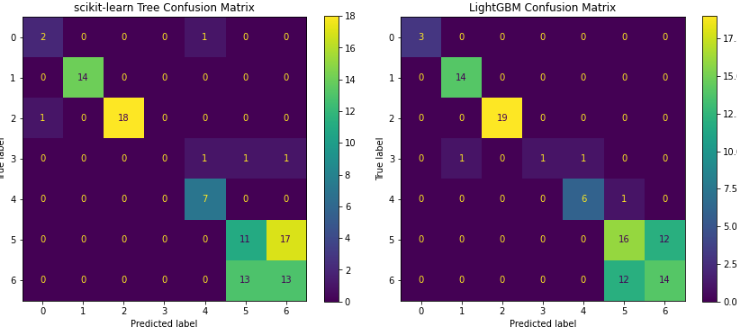
- X軸:モデルが予測したクラス(0〜6)
- Y軸:実際の正しいクラス(正解)
-
対角線上の数字:モデルが正しく分類した件数
例:対角線上の数字が多いほど、モデルが正しく予測した件数が多いことを意味します。
読み取り方例:DecisionTreeで解説
- X=0, Y=0 → クラス0を正しく分類した件数 = 2
- X=6, Y=6 → クラス6を正しく分類した件数 = 13
- X=5, Y=6 → 実際はクラス6だが、モデルはクラス5と予測した件数 = 13(誤分類)
-
誤分類パターン:誤分類が多いクラスを見つけることで、改善点を特定できます。
例えば、クラス3(SUV)をクラス1(セダン)として予測する誤分類が多い場合、その原因を探り、データの追加や特徴量の変更を検討することができます。
検討例
- 特徴量の追加:例えば、車の用途(ファミリー向け、ビジネス向けなど)を追加することで、SUVとセダンの区別がしやすくなるかもしれません。
- データのバランス調整:誤分類されやすいクラスが少数派の場合、そのクラスを多く含むデータを追加することも効果的です。
📌まとめ
決定木と LightGBM を比較してみました。
今回のサンプルデータでは LightGBM の方がやや精度が高い 結果でした。
ただし、データによっては LightGBM の精度が思ったより伸びないケースもあります。
- 少量のデータでは決定木が有効
- 大規模なデータセットでは LightGBM が優れた性能を発揮
モデルは 使ってみてナンボ!
他人の評価や「精度が高い」という情報に頼らず、自分のデータで確認することが大切です。
次回は、LightGBMだけを深掘りした解説をします。 更にアップデートした内容はこちら
参考リンクについて
GitHubリポジトリ
本記事で紹介したコードやサンプルデータはこちらで公開しています。
Discussion