【Core ML】coremltoolsのモデル圧縮手法まとめ
coremltools を用いてCore MLモデルを最適化し、ファイルサイズやメモリフットプリントを削減する手段をまとめていきます。
coremltools とは
- PyTorch等で作成したモデルをCore ML形式に変換するツール
- モデルを圧縮する機能も持っている
- オープンソース

coremltoolsとCore MLフレームワークのバージョン
| Core ML | coremltools |
|---|---|
| iOS 18, macOS 15 (Sequoia), visionOS 2, watchOS 11 | 8 |
| iOS 17, macOS 14 (Sonoma), visionOS 1, watchOS 10 | 7 |
| iOS 16, macOS 13 (Ventura), visionOS 1, watchOS 9 | 6 |
| iOS 15, macOS 12 (Monterey), visionOS 1, watchOS 8 | 5 |
| iOS 14, macOS 11 (Big Sur), visionOS 1, watchOS 7 | 4 |
| iOS 13, macOS 10.15 (Catalina), visionOS 1, watchOS 6 | 3 |
| iOS 12, macOS 10.14 (Mojave), visionOS 1, watchOS 5 | 2 |
| iOS 11, macOS 10.13 (High Sierra), visionOS 1, watchOS 4 | 1 |
2024年12月現在の最新はcoremltools 8.1
既存のモデル圧縮手法
coremltools 7以前から利用可能な圧縮手法
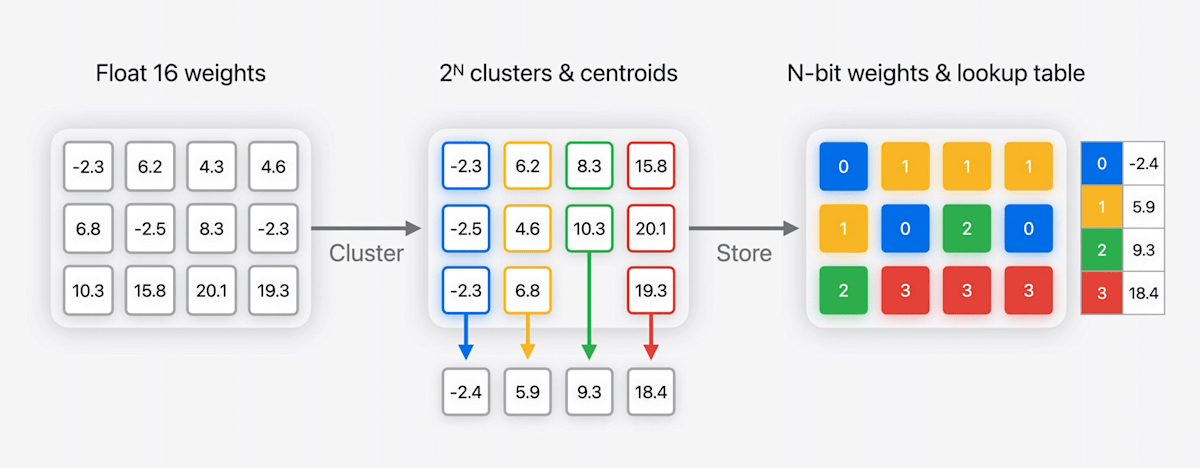
Palettization(パレット化)

- 似たような値を持つ重みをクラスタ化
- クラスタのセントロイドをLUTに格納
→ LUTへのNビットのインデックスマップが圧縮後の重みとなる(例では2ビットに圧縮)
公式ガイドの実装例
精度はfloat16 、UNetモデルのサイズが4.8 GBのStable Diffusion SDXLモデルを圧縮:
import coremltools as ct
import coremltools.optimize as cto
model = ct.models.MLModel(
"output-xl-512/Stable_Diffusion_version_stabilityai_stable-diffusion-xl-base-1.0_unet.mlpackage"
)
config = cto.coreml.OptimizationConfig(
global_config=cto.coreml.OpPalettizerConfig(nbits=4),
)
compressed_model = cto.coreml.palettize_weights(model, config)
nbits を 8, 6, 4 にして試した結果:
| Config | Model Size | Image |
|---|---|---|
| 8-bit (per tensor) | 2.40 GB |  |
| 6-bit (per-tensor) | 1.80 GB |  |
| 4-bit (per-tensor) | 1.21 GB |  |
- 8ビットのパレット化を適用すると、モデルサイズはfloat16モデルの約半分に削減できるが、それでもまだiOSで扱うには大きすぎる
- 6ビットにすると、ようやくこのモデルをiPadで実行できるようになる
- 4ビット圧縮では、画像出力が明確に劣化する(後述)
Quantization(量子化)
量子化は、重みの値の精度を下げてモデルサイズを縮小する手法。

- Floatの重みを整数の範囲に線形にマッピング
→ Nビット整数重みとスケールとバイアスのペアが格納される
実装例:
import coremltools.optimize as cto
op_config = cto.coreml.OpLinearQuantizerConfig(
mode="linear_symmetric", weight_threshold=512
)
config = cto.coreml.OptimizationConfig(global_config=op_config)
compressed_8_bit_model = cto.coreml.linear_quantize_weights(model, config=config)
Pruning(枝刈り)

- 小さい重みを0にする
- ビットマスクと0でない値だけを保存する
実装例:
from coremltools.optimize.coreml import (
OpThresholdPrunerConfig,
OptimizationConfig,
prune_weights,
)
config = OptimizationConfig(global_config=OpThresholdPrunerConfig(
threshold=0.03
))
model_compressed = prune_weights(model, config=config)
新しいモデル圧縮手法
coremltools 8で可能になったモデル圧縮手法
既存の圧縮手法の限界
5GBのモデルを16 → 4ビットまで圧縮すると生成結果が破綻

何が問題なのか?
4ビットPalettization→ 16個のセントロイドだけで大きなモデルの重みすべてを表現しようとして破綻している
Core ML × 生成AIの問題
サイズがでかすぎる(数GB〜10GB以上もザラ)
- アプリバイナリに含められない/DLさせるにもデカすぎる
- メモリを食うので落ちる
- 推論(生成)時間もかかる
詳細はこちら:
→ 強力なモデル圧縮手段が必要
新しいPalettization
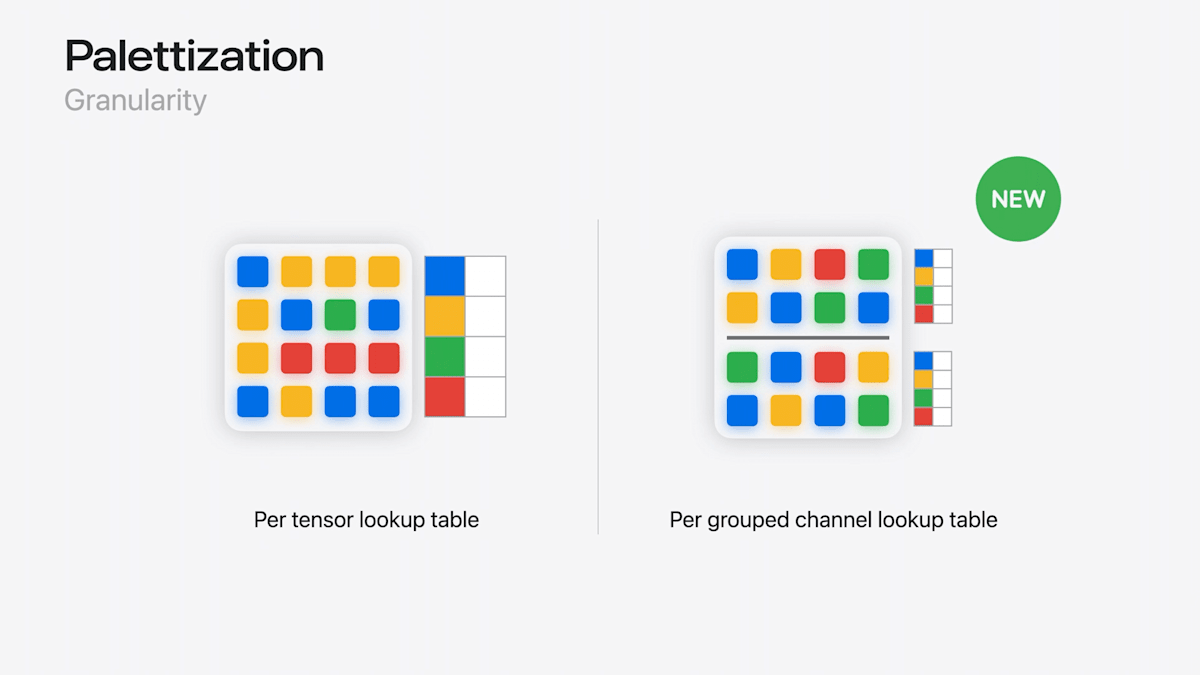
- 複数のLUTを保存できるように
→ 低ビットに圧縮しつつも精度を維持
新しいLinear quantization
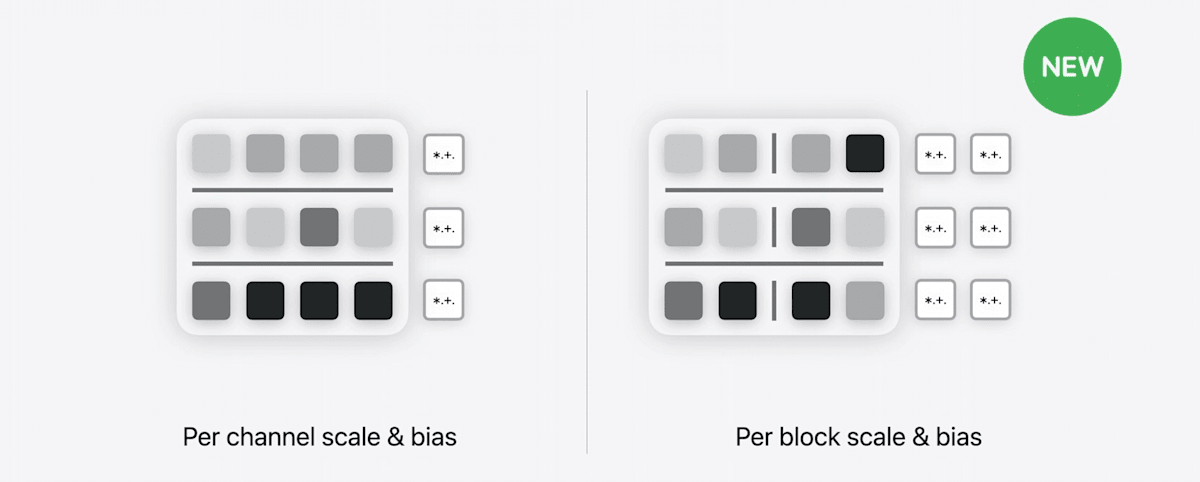
iOS 17ではチャンネルごとにスケールとバイアスを設定
→ iOS 18ではこれらをブロックごとに設定可能に
Pruning後のさらなる圧縮が可能に

- Pruning + Palettization
- Pruning + Quantization
Stable Diffusionモデルを新しいPalettizationで圧縮してみる
Stable Diffusion v2.1 (非XL) [1] のCore MLモデルを新Palettizationで圧縮する
圧縮前
(iOS 18 @iPhone 15 Proで実行)

Palettizationのコード
グループ化されたチャンネルごとのPalettizationを適用
import coremltools.optimize.coreml as cto_coreml
op_config = cto_coreml.OpPalettizerConfig(
nbits=4, # 4ビットに圧縮
mode="kmeans", # クラスタリング手法
granularity="per_grouped_channel", # 粒度
group_size=16, # グループサイズ
)
config = cto_coreml.OptimizationConfig(op_config)
compressed_mimodel = cto_coreml.palettize_weights(mlmodel, config)
圧縮後
- モデルサイズ:1.73 → 0.44 GB
- 約4分の1に圧縮!
- 画像生成時間:13秒 → 10秒
- 23%高速化! [4]
(iOS 18 @iPhone 15 Proで実行)

[Deprecated] mlmodel向けの圧縮手法
Quantization(量子化)
neuralnetwork タイプのモデル向けには、quantization_utils を利用する。
This page describes the API to compress the weights of a Core ML model that is of type
neuralnetwork. For themlprogrammodel type, see the Optimize API Overview.
現行は mlprogram タイプの利用が推奨されているが、
現在でも .mlmodel フォーマット(neuralnetwork タイプ)のモデルを利用しているプロジェクトもあると思われるので記載しておく。
coremltools.models.neural_network.quantization_utilsにクオンタイズに関連する関数やクラスが用意されています。
こちらはCore MLモデルのSpecification Version 3(iOS 12.0/macOS 10.14)より利用可能となりました。
量子化ビット数としては1〜8ビットまたは16ビットがサポートされています。
quantize_weights関数を使用します。
from coremltools.models.neural_network import quantization_utils
quantized_model = quantization_utils.quantize_weights(model,
nbits,
'linear')
第1引数にはフル精度(32ビット)のMLModelオブジェクトを、第2引数には量子化ビット数を、第3引数にはクォンタイゼーションモードを文字列で指定します。モードはいくつか種類があるのですが、上のサンプルでは線形に量子化を行う'linear'を指定しています。
関数を次のように呼ぶと16ビット化されたMLModelオブジェクトが返され、
model_fp16 = quantization_utils.quantize_weights(model, 16, 'linear')
次のように呼ぶと8ビット化されたMLModelオブジェクトが返されます。
model_fp8 = quantization_utils.quantize_weights(model, 8, 'linear')
`quantization_utils` を用いた量子化の実行結果
CNNEmotion.mlmodelを16ビット化したモデルを.mlmodelに保存してファイルサイズを見てみると、249MBでconvert_neural_network_spec_weights_to_fp16で変換した場合と完全に同じサイズとなり、またSpecのspecificationVersionを出力しても結果は2となり、異なる関数を使用しても16ビット化の実行結果は同じということが言えそうです。
また8ビット版のサイズは124.6MBでした。元のサイズの約4分の1となっています。こちらのモデルのSpecのspecificationVersionを出力してみると3となっており、_MINIMUM_QUANTIZED_MODEL_SPEC_VERSION定数の以下の定義と一致しています。
_MINIMUM_QUANTIZED_MODEL_SPEC_VERSION = 3
16ビット化が推論結果の精度に与える影響
重みのビット数をフル精度(32ビット)から半精度(16ビット)に減らすと、推論結果の精度にも当然影響が出そうです。しかし実はGPUで処理している場合には影響がありません。モデルが32ビットでも16ビットでも、GPUでは16ビットで処理するからです。
逆に、CPUで処理する際には16ビットの場合でも32ビットで処理されます。つまりこのケースでは半精度化は推論結果の精度に影響します。
Core MLモデルとCPU, GPU
Core MLモデルがiOSやmacOSにおいてどういったケースでCPUで処理されるかという話については、usesCPUOnlyの公式リファレンスに少し記述があります。このページによると、以下の場合にはCPUでの処理に制限されます。
- アプリがバックグラウンドにある状態で処理を実行する場合
- アプリが他の負荷の高いGPUタスクを実行している場合
なお、このusesCPUOnlyを指定するとCore MLの処理にCPUだけを使用するようになりますが、
MLPredictionOptionsクラスにGPUだけを使用するためのプロパティはありません。またMLModelConfigurationクラスのcomputeUnitsプロパティに設定できるMLComputeUnits型にはall, cpuOnly, cpuAndGPUの3種類しかないので、結論としてCore MLの処理をGPUだけに限定することはできません。
ルックアップテーブルを利用した量子化
前述の通り、quantize_weights関数の第2引数に指定する量子化ビット数には、1以上の8よりさらに小さい整数が渡せます。4ビット(サイズはフル精度の8分の1)、1ビット(サイズは32分の1)まで量子化することが可能というわけです。しかしもともとひとつの値につき32ビットもあった情報を4ビットまで落とすと、さすがに推論結果の精度にも影響を及ぼす可能性があります。
そこで試してみると良いのが、ルックアップテーブルを使用する方法です。quantize_weightsの第3引数にlinearを指定すると単純に等間隔で値が丸められていくだけですが、他に以下の3種類のルックアップテーブルを指定する量子化方法(クォンタイゼーションモード)が指定できます。
-
linear_lut: 線形なクオンタイズをルックアップテーブルベースで行う(linearと比較してややサイズが小さくなる場合がある) -
kmeans_lut: K-Meansによるクラスタリングで生成したルックアップテーブルを用いて量子化を行う -
custom_lut: カスタムルックアップテーブルを用いて量子化を行う
linear_lutとkmeans_lutは自分でLUTを用意する必要はなく、関数の中で勝手にやってくれる。つまり引数に指定するだけでOK。(ちなみにカスタムLUTを指定する用にはcustom_lutというモードが用意されている)
こういう関数を用意して、
from coremltools.models.neural_network import quantization_utils
def quantize_model(nbits, output_model_path, mode='linear'):
quantized_model = quantization_utils.quantize_weights(model,
nbits,
mode)
spec = quantized_model.get_spec()
coremltools.utils.save_spec(spec, output_model_path)
8ビットよりも小さい4, 2, 1ビットでの量子化を、linear, linear_lut, kmeans_lutの3種類のquantization_modeを用いてクオンタイズを行ってみた。
ルックアップテーブルを利用した量子化の実行結果
linear の4, 2, 1ビット
quantize_model(4, 'hoge_4.mlmodel')
quantize_model(2, 'hoge_2.mlmodel')
quantize_model(1, 'hoge_1.mlmodel')
本に書いたのと同様に、CNNEmotion.mlmodelで試した。iOSアプリに組み込んでいくつかの画像で顔の感情認識をさせた結果:
・4ビット版はほぼフル精度と同等の結果を返してきた
・2ビット版は半分以上のケースで(5/16)フル精度版と違う結果を返した
・1ビット版はずっと同じクラスを返し続けており、ちゃんと動作していないようだった
linear_lut
次に線形量子化のLUT利用モード。
quantize_model(4, 'hoge_4_lut.mlmodel', 'linear_lut')
quantize_model(2, 'hoge_2_lut.mlmodel', 'linear_lut')
quantize_model(1, 'hoge_1_lut.mlmodel', 'linear_lut')
量子化後のサイズはほんの少しだけ(linearモード版と比較して)linear_lut版の方が小さい。とはいっても100kBも変わらないぐらい。
kmeans_lut
LUT版はこちらが本命。linear_lutは量子化の結果自体はlinearと変わらないからだ。
quantize_model(4, 'hoge_4_kmeanslut.mlmodel', 'kmeans_lut')
quantize_model(2, 'hoge_2_kmeanslut.mlmodel', 'kmeans_lut')
quantize_model(1, 'hoge_1_kmeanslut.mlmodel', 'kmeans_lut')
リファレンス
公式ガイド
最適化の目次:
- Overview
- What’s New
- Examples
- Optimization Workflow
- Palettization
- Linear Quantization
- Pruning
- Combining Compression Types
- Conversion
- Compressing Neural Network Weights
APIリファレンス
WWDC
- Bring your machine learning and AI models to Apple silicon - WWDC24 - Videos - Apple Developer
- Deploy machine learning and AI models on-device with Core ML - WWDC24 - Videos - Apple Developer
Discussion