ローカルLLMをCore MLモデルに変換する - 🤗 Exporters の使い方
Exporters とは
Hugging Faceが公開している Exporters というツールがある。
TransformersのモデルをCore MLにエクスポートするためのツールで、coremltoolsをラップしたものではあるが、変換に伴う色々な問題をツール側で吸収してくれている。要はこのツールを使えばcoremltoolsをそのまま使うよりも簡単にTransformersモデルをCore MLモデルに変換できる。
モチベーション
Exporters は以下の公式ブログで紹介されていたもので、
Llama 2などのLLMモデルもこれを用いて変換されたようだ(あるいは、その変換の過程で得られた知見がこのツールに盛り込まれている)
公開されている変換済みモデルは、試してみたもののまだモバイル端末には大きすぎたので、
もっと小さいモデルを自前で変換したらよいかもしれない、と思い本ツールを使ってみることにした。
インストール
git clone してきて、
$ cd exporters
$ pip install -e .
だけでOK。(venvで仮想環境は作った)
とりあえず変換してみる
READMEに載っている
python -m exporters.coreml --model=distilbert-base-uncased exported/
を実行してみた。
コマンドの意味:
-
exporters.coremlパッケージを実行- 同パッケージを使うと、モデルのチェックポイントをCore MLモデルに変換することができる
-
--model引数に変換元モデルのチェックポイントを指定- Hugging Face Hub 上のチェックポイントでも、ローカルに保存されているチェックポイントでもOK
-
exportedディレクトリに変換後の Core ML ファイルが保存される- デフォルトのファイル名は
Model.mlpackage
- デフォルトのファイル名は
"ValueError: Output values do not match between reference model and Core ML exported model" エラー
ここまで進んだが、
コンソール出力
Torch version 2.2.1 has not been tested with coremltools. You may run into unexpected errors. Torch 2.1.0 is the most recent version that has been tested.
tokenizer_config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 28.0/28.0 [00:00<00:00, 53.4kB/s]
config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 483/483 [00:00<00:00, 1.17MB/s]
vocab.txt: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 232k/232k [00:00<00:00, 662kB/s]
tokenizer.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 466k/466k [00:00<00:00, 2.50MB/s]
model.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 268M/268M [00:40<00:00, 6.68MB/s]
Using framework PyTorch: 2.2.1
(略)
Validating Core ML model...
-[✓] Core ML model output names match reference model ({'last_hidden_state'})
- Validating Core ML model output "last_hidden_state":
-[✓] (1, 128, 768) matches (1, 128, 768)
-[x] values not close enough (atol: 0.0001)
こういうエラーが出た:
Validating Core ML model...
-[✓] Core ML model output names match reference model ({'last_hidden_state'})
- Validating Core ML model output "last_hidden_state":
-[✓] (1, 128, 768) matches (1, 128, 768)
-[x] values not close enough (atol: 0.0001)
Traceback (most recent call last):
(略)
ValueError: Output values do not match between reference model and Core ML exported model: Got max absolute difference of: 0.004475116729736328
生成まではうまくいったが、バリデーションで失敗している。
READMEによると本来はこういうログが出るらしい
Validating Core ML model...
-[✓] Core ML model output names match reference model ({'last_hidden_state'})
- Validating Core ML model output "last_hidden_state":
-[✓] (1, 128, 768) matches (1, 128, 768)
-[✓] all values close (atol: 0.0001)
All good, model saved at: exported/Model.mlpackage
しかし、READMEの別パートには次のように書かれており、この最後のバリデーションでの失敗は許容範囲のようだ。
If validation fails with an error such as the following, it doesn't necessarily mean the model is broken:(以下のようなエラーで検証が失敗しても、必ずしもモデルが壊れているとは限りません)
ValueError: Output values do not match between reference model and Core ML exported model: Got max absolute difference of: 0.12345
The comparison is done using an absolute difference value, which in this example is 0.12345. That is much larger than the default tolerance value of 1e-4, hence the reported error. However, the magnitude of the activations also matters. For a model whose activations are on the order of 1e+3, a maximum absolute difference of 0.12345 would usually be acceptable.
(比較は差の絶対値で行われ、この例では0.12345です。これはデフォルトの許容値である1e-4よりはるかに大きく、そのためエラーが報告されています。しかし、アクティブ度の大きさも重要です。アクティブ度が1e+3程度のモデルであれば、最大差の絶対値が0.12345であれば通常は許容範囲でしょう。)If validation fails with this error and you're not entirely sure if this is a true problem, call
mlmodel.predict()on a dummy input tensor and look at the largest absolute magnitude in the output tensor.
(もしこのエラーで検証が失敗し、これが本当に問題なのか全くわからない場合は、ダミーの入力テンソルでmlmodel.predict()を呼び出し、出力テンソルの最大の絶対値の大きさを調べてください。)
いったん成功とする。
LLMの変換
Calm2 7B Chat
https://huggingface.co/cyberagent/calm2-7b-chat
を変換してみる。
python -m exporters.coreml --model=cyberagent/calm2-7b-chat exported/
"Converting PyTorch Frontend ==> MIL Ops"のところで、
Converting PyTorch Frontend ==> MIL Ops: 1%|██ | 48/3707 [00:02<03:13, 18.88 ops/s]
次のようなエラーになった:
ValueError: The updates tensor should have shape [1, 1, 32768, 32768]. Got (1, 1, 32768, 128)
テンソルのシェイプ云々の問題に自分が立ち向かってもハマりそうなのでいったん諦め、まずはオフィシャルに変換実績のある(と思われる)Llama 2のモデルを試してみることにした。
Llama 2 7B Chat
のオリジナルはこれらしい。
以下を実行してみたところ、
python -m exporters.coreml --model=meta-llama/Llama-2-7b-chat-hf exported/
次のようなエラーが速攻で返ってきた:
Cannot access gated repo for url https://huggingface.co/meta-llama/Llama-2-7b-chat-hf/resolve/main/config.json.Repo model meta-llama/Llama-2-7b-chat-hf is gated. You must be authenticated to access it.
当該ページを見に行ってみたところ、アクセス許可がいるらしい。
agreeしてSubmitしたところ、承認待ちになった。いったん終了。
Falcon 7B
同じく公式で変換済みモデルが公開されているFalconの変換を試してみる。
もともとのモデルがでかすぎて量子化なりしない限りはiOSで動かすのは無理なのはわかっているが、exporters を使った変換成功例が欲しいのでやってみた。
python -m exporters.coreml --model=tiiuae/falcon-7b-instruct exported/
どうせ何かしらのエラーで終わるんだろうな、と思っていたのだが、
コンソール出力
Running MIL default pipeline: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 71/71 [02:36<00:00, 2.20s/ passes]
Running MIL backend_mlprogram pipeline: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 242.98 passes/s]
Restoring PyTorch conversion op 'to' to <function to at 0x175bc3100>
Validating Core ML model...
-[✓] Core ML model output names match reference model ({'last_hidden_state'})
- Validating Core ML model output "last_hidden_state":
-[✓] (1, 128, 4544) matches (1, 128, 4544)
-[✓] all values close (atol: 0.1)
All good, model saved at: exported/Model.mlpackage
なんと成功した。
生成されたモデルは13.84GB。
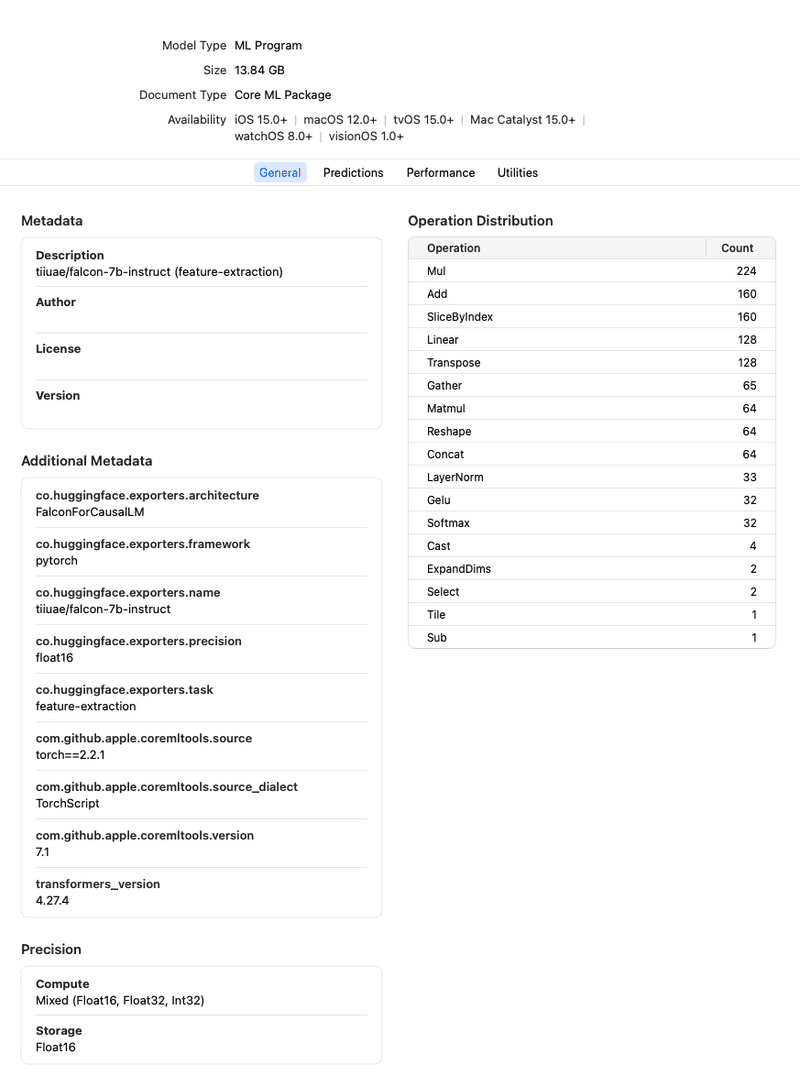
exportersで変換したFalcon 7BのCore MLモデルをXcodeでプレビュー
macOSで動かしてみたところ、ちゃんと動いた🎉
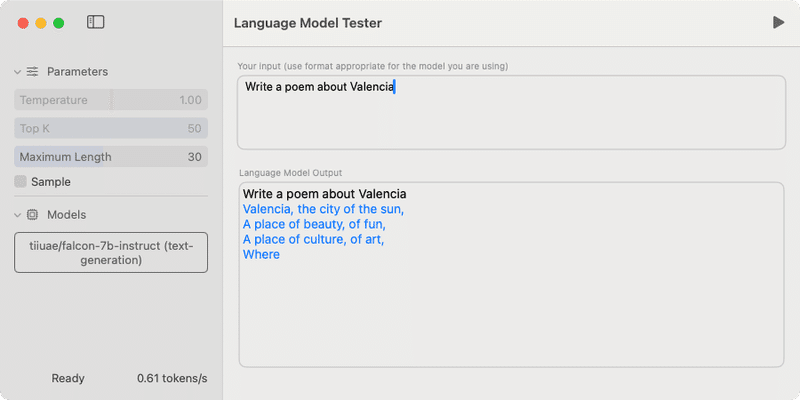
exportersで変換したCore ML版LLMの試し方はこちら:
Mistral 7B
llama.cpp版で試していい感じだった Mistral 7B v0.1 の変換を試してみた。
コマンド:
python -m exporters.coreml --model=mistralai/Mistral-7B-v0.1 exported/mistral-7b.mlpackage
コンソール出力
tokenizer_config.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 967/967 [00:00<00:00, 1.91MB/s]
config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 571/571 [00:00<00:00, 1.63MB/s]
tokenizer.model: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 493k/493k [00:00<00:00, 3.11MB/s]
tokenizer.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.80M/1.80M [00:00<00:00, 2.85MB/s]
special_tokens_map.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 72.0/72.0 [00:00<00:00, 190kB/s]
model.safetensors.index.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 25.1k/25.1k [00:00<00:00, 49.1MB/s]
model-00001-of-00002.safetensors: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 9.94G/9.94G [35:18<00:00, 4.69MB/s]
model-00002-of-00002.safetensors: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.54G/4.54G [16:05<00:00, 4.70MB/s]
Downloading shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [51:25<00:00, 1542.64s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:19<00:00, 9.79s/it]
Using framework PyTorch: 2.0.1
(中略)
Converting PyTorch Frontend ==> MIL Ops: 0%| | 0/4506 [00:00<?, ? ops/s]Saving value type of int64 into a builtin type of int32, might lose precision!
Saving value type of int64 into a builtin type of int32, might lose precision!
Converting PyTorch Frontend ==> MIL Ops: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉| 4505/4506 [00:00<00:00, 6301.16 ops/s]
Running MIL frontend_pytorch pipeline: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 10.55 passes/s]
Running MIL default pipeline: 14%|███████████████████████▋ | (中略)
Running MIL default pipeline: 73%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ |
(中略)
Running MIL default pipeline: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 71/71 [02:44<00:00, 2.32s/ passes]
Running MIL backend_mlprogram pipeline: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 185.18 passes/s]
Restoring PyTorch conversion op 'log' to <function log at 0x2811a2160>
Validating Core ML model...
-[✓] Core ML model output names match reference model ({'last_hidden_state'})
- Validating Core ML model output "last_hidden_state":
-[✓] (1, 128, 4096) matches (1, 128, 4096)
-[x] values not close enough (atol: 0.0001)
(中略)
ValueError: Output values do not match between reference model and Core ML exported model: Got max absolute difference of: 0.9574127197265625
エラーで止まったか…と思いきや、上述のバリデーションでのエラーだった。
というわけで無事変換成功。別記事で書くが、モデルの圧縮(palettize)もうまくいった。
Output が"logits"ではなく "last_hidden_state" になってしまう問題
python -m exporters.coreml --model=xxxx exported
で変換自体は成功するのだが、Core MLモデルの Output が "last_hidden_state" となってしまう。

swift-transformers パッケージで動くCore ML版LLMの Output は "logits" となるべきで、そうでないと LanguageModel クラスの predictNextTokenScores メソッド内での推論処理( model.prediction )の直後に置かれている assert に引っかかってしまう。
assert(output.featureNames.first! == "logits")
比較対象として、Hugging Faceが公式ブログで言及しているCore ML変換済みモデル(この記事で試したモデル)の Output を見てみると、

ちゃんと "logits" になっている。
swift-transformers パッケージをローカルに置いてその assert の行をコメントアウトし無理やり処理を進めてみたが、正しい推論結果がでない。
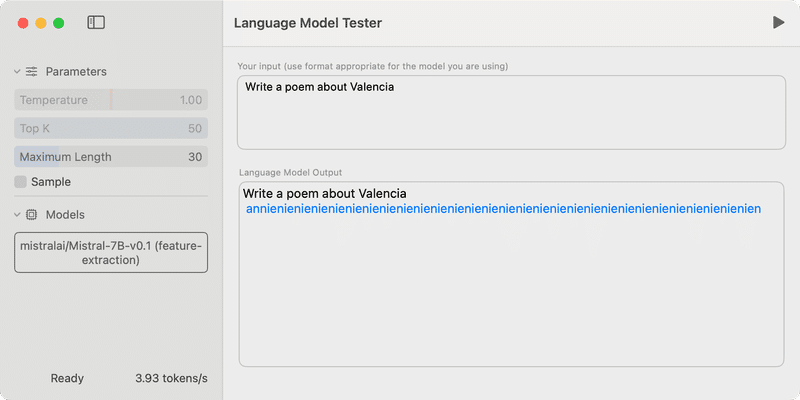
あと、Metadata を見ると
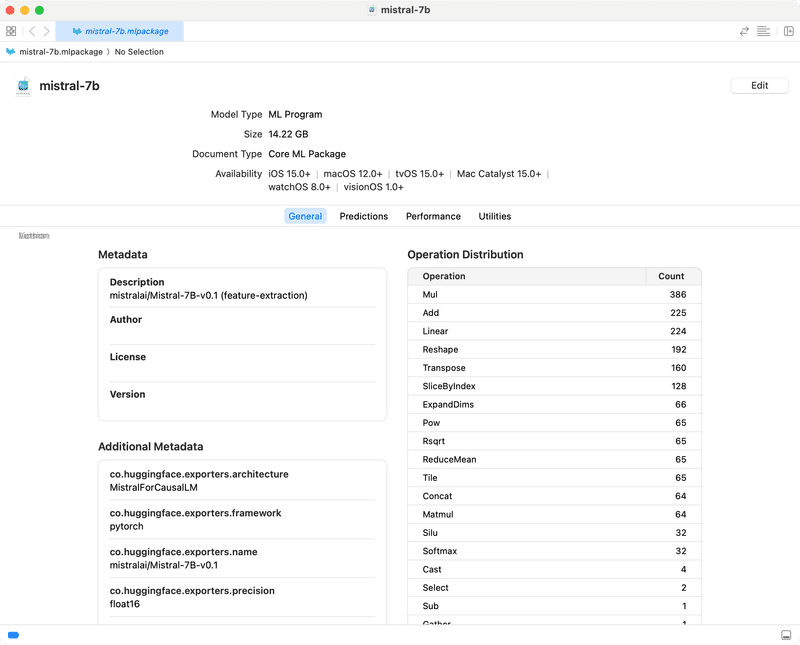
そもそも Description が
mistralai/Mistral-7B-v0.1 (feature-extraction)
となっていて、"feature-extraction" モデルとして変換されてしまっている。
解決法
--feature オプションに text-generation を指定する:
python -m exporters.coreml --model=mistralai/Mistral-7B-v0.1 --feature=text-generation exported/mistral-7b.mlpackage
詳しい解説はこっちの記事に書いた:
まとめ
-
READMEに書いてあった変換は成功
-
LLMモデルの変換も成功
本ツールを試した動機は
公開されている変換済みモデルは、試してみたもののまだモバイル端末には大きすぎたので、もっと小さいモデルを自前で変換したらよいかもしれない、と思い exporters ツールを使ってみることにした。
というところにあったので、今後はいかにモデルを圧縮するかが課題。
exportersには quantize オプションが用意されているが、float32 と float16 しか選べないようだ。
Hugging Face HubのTheBlokeアカウントで公開されているローカルLLMのGGUFモデル群も、モバイルで動くものは3-bitや4-bit量子化されたものだ。
coremltools自体には色々な圧縮機能が備わっているので、やりようはあると思う。
今後はこのあたりを検討していく。
Discussion