ローカルLLM on iOS の現状まとめ
2024年3月5日に開催されたイベントで発表した内容です。
スライドはこちら:
またLTで全然時間が足りなかったので、イベント終了後にひとりで撮ったプレゼン動画がこちら:
サンプルコードはこちら:
以下、発表資料を記事として再構成したものになります。登壇後に調査した内容も追記しています。
「ローカルLLM on iOS」のデモ
-
オンデバイスで [1]処理してます
- APIは叩いていません
-
倍速再生していません
- 8.6 tokens/sec
iOSローカルでLLMを動かすメリット
オフラインでも動くプライバシーが守られる(データがどこにもアップされない)どれだけ使っても無料
モバイル端末スタンドアローンで最先端の機能が動作することには常にロマンがある
iOSでローカルLLMを動かす方法
大きく分けて2つ
- llama.cpp
- Core ML
llama.cpp
- LLMが高速に動くランタイム
- C/C++製
- Georgi Gerganov (GG) さんが開発
- GGML → GGUFフォーマット

llama.cpp と Apple Silicon
-
Apple Silicon向けにはARM NEON、Accelerate、Metalフレームワークで最適化
-
「ローカルLLMを動かせるmacOSアプリ」の多くがllama.cppを内部で利用
- Ollama, LM Studio, LLMFarm, etc...
- GGUFフォーマットのモデルを使用する
llama.cpp と iOS
- "Apple Slicon向け最適化" はMシリーズだけでなく、iPhoneのAシリーズも対象
Core ML
Core MLとは
- 機械学習モデルをiOS, macOS, etc. に組み込むためのApple製のフレームワーク, モデルフォーマット

- CPU・GPU・Neural Engineを利用し、メモリ占有量と電力消費量を最小限に抑えつつパフォーマンスを最大限に高めるように設計されている
Neural EngineはAPIがない
- Core MLを利用した場合のみNeural Engineを利用できる
- → Apple Sillicon(iPhoneのAシリーズも含む)の性能を最も活かせるのはCore ML!
Core ML vs llama.cpp
Neural Engine を活かせる分、Core MLが有利?
→ そうともいい難い
LLMモデルをCore MLに変換する方法
-
coremltoolsを使う
-
Hugging Faceが公開している変換ツール exporters を使う
🤗 exporters
- TransformersモデルをCore MLに変換するツール
- coremltoolsをラップしたものではあるが、変換に伴う色々な問題をツール側で吸収してくれている
- 要はこのツールを使えばcoremltoolsをそのまま使うよりも簡単にTransformersモデルをCore MLモデルに変換できる
(補足資料) 🤗 exporters の使い方
-
記事: ローカルLLMをCore MLモデルに変換する - huggingface/exporters の使い方
- LLMモデルをCore MLに変換することには成功
-
関連:
(長くなってきたので中略)
この流れで言いたいこと: Core MLモデルへの変換ツールはあるが、変換済みモデルはほとんど公開されておらず、量子化等自分で色々がんばる必要がある
llama.cpp 向けのモデルはどうか?
ほとんどのローカルLLMが色々なパターンで量子化されGGUFフォーマットで公開されている(TheBloke が有名)

Core ML vs llama.cpp
- Neural Engine を活かせる点ではCore MLが有利
- 各種ローカルLLMを「すぐに試せる」点では圧倒的にllama.cpp
ここまでのまとめ
- iOSでローカルLLMを動かす手段としてはllama.cppとCore MLがある
- どちらもApple Siliconに最適化されているが、Neural Engineを活かせるのはCore MLのみ
- llama.cppは量子化済み・変換済みのモデルの選択肢が豊富にある
自分のアプリに組み込む
llama.cpp
- 手軽にアプリに組み込めるように本家リポジトリにSwift Packageが用意されている
- そのSwift Packageの使い方を示すサンプルも同リポジトリに用意されている
- examples/llama.swiftui
Core ML
- 🤗 exporters で変換したCore MLモデルをアプリで動かすためのラッパーライブラリとして
swift-transformersというSwift Packageが用意されている - そのサンプルアプリも公開されている
iOSオンデバイスで動くLLMモデルの現状
モデルの探し方
-
Hugging Face Hubで探す(
GGUF/Core ML) - LLMFarm のここ ・・・動作検証済みモデルがサイズと共にリストアップされている
- llama.cpp の README の "Supported models" や、ここ・・・各種モデルのiPhoneでのベンチマーク
試してみたモデルの例
-
Mistral 7B v0.1 (比較的小さなサイズで優秀)
-
Q3_K_S(3.16GB) -
Q4_K_S(4.14GB)
-
-
Calm 2 7B Chat (日本語LLM)
-
Q3_K_S(3.47GB) -
Q4_K_S(3.12GB) -
Q4_K_M(3.47GB)・・・iPhone 15 Proでクラッシュ
-
デモ
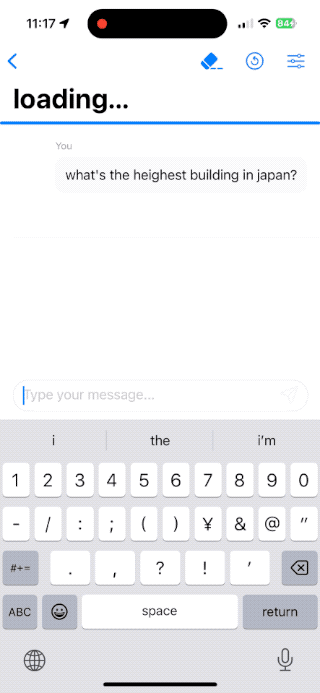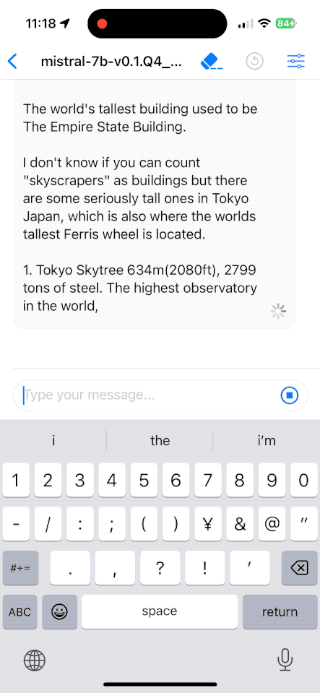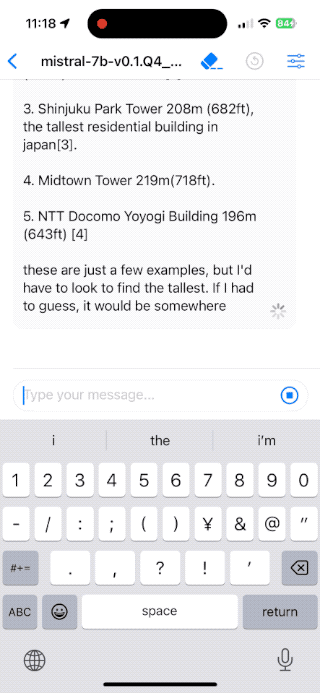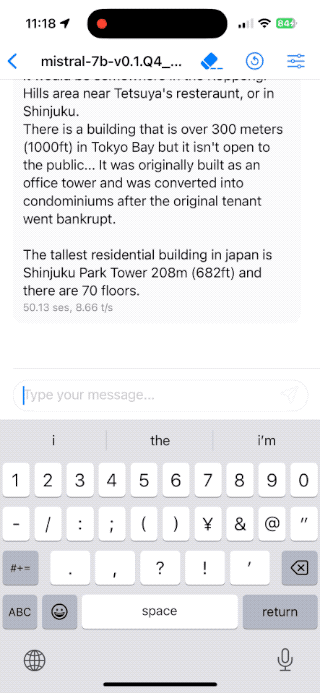
Mistral 7B v0.1
-
Q4_K_S- 4-bit量子化
- 4.14GB
- ローディング 約15秒
- テキスト生成速度 8.66 t/s
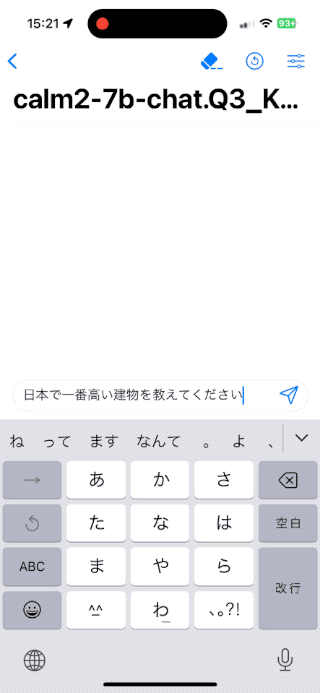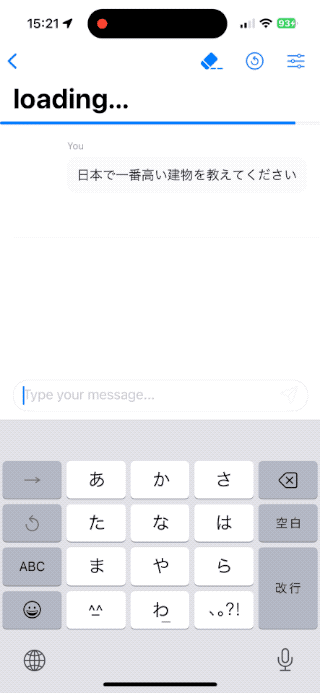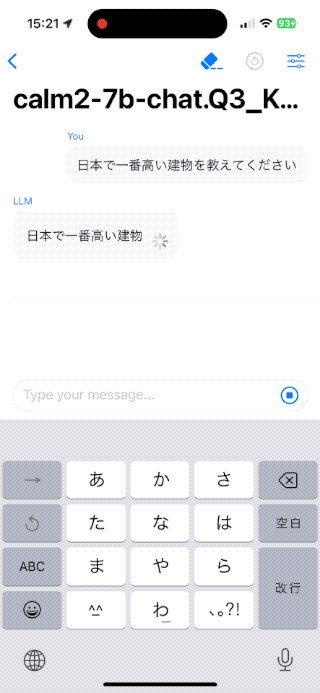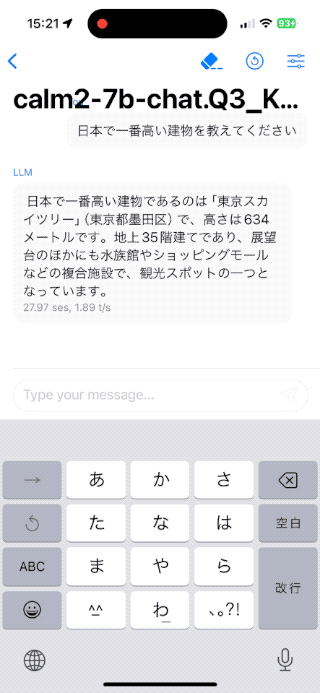
Calm2 7B Chat
-
Q3_K_S- 3-bit量子化
- 3.12GB
- ローディング 約25秒
- テキスト生成速度 1.89 t/s
現状の所感
※1,2回試しただけの所感です
- 回答内容は 👍
- 推論速度も 👍
・・・とはいえ
現状ではプロダクトでの実用は厳しそう
- サイズの問題: 3-bit or 4-bit 量子化したモデルでも3GB〜
- アプリに組み込むわけにはいかない/ユーザーにダウンロードさせるわけにもいかない
- 処理速度の問題: モデルのロードに時間がかかる/推論速度もまだ厳しい → APIを叩いた方が速い
- 使用メモリ量の問題: 数GB必要
今後の展望
ワクワクしかない
- モデル性能: より少ないパラメータ数で高性能なモデルが日々生まれている
- 量子化手法: 年々進化、BitNetなるものも登場
- デバイス性能: メモリ容量もGPU・Neural Engineの性能も年々進化
- 変換済みモデルの多様性・・・Core ML変換済みのLLMも充実してくる(はず)
→ オンデバイスでLLMがサクサク動く日も近い!
Wrap up
-
iOSでローカルLLMを動かす手段は大きく2通り
- llama.cpp: 量子化済み・変換済みモデルの選択肢が豊富
- Core ML: Neural Engine使う
-
iOSデバイスで動かすには「現状では」デカすぎるし重すぎる
- が、大いに希望はある!
追記: MLX
発表では『iOSでローカルLLMを動かす手段は大きく分けて2つ』として llama.cpp と Core ML を紹介しましたが、MLXという選択肢もあります。
MLX版ローカルLLMをiOSで動かす方法についてはこちらにまとめました:
追記: iOSビルトインのローカルLLM?
前述した通りローカルLLMはモバイルアプリに同梱したりユーザーにダウンロードさせたりするにはサイズ的にまだまだ厳しいため、OS自体にビルトインされることが期待されます。
ツイート内容
この記事、斜め読みして「なんだ、SiriがOpenAIのAPI叩いて要約するようになるだけか」と一瞬思ったんだけど、
しかしよく読むと全然違った。
iOS 18に搭載予定のAppleのAIはChatGPTを用いて動作するのではなく、プロンプトに対するSiriSummarizationとChatGPTの回答を比較し、開発に活用する目的でしょう
Appleが4つのAIモデルのテストを行っていると指摘しています。そのうち2つはApple独自の大規模言語モデル「Ajax」と呼ばれるモデルを用いたチャットボット「AjaxGPT」で、iPhone上でローカルに動作するオフライン版とオンライン版の2つのバージョンが存在するとのこと。残りの2つはChatGPTと、Googleの大規模言語モデルである「FLAN-T5」です。
iOSビルトインのローカルLLMが入ったらめちゃくちゃ熱い。今年のWWDCが楽しみ。
もし実現されれば、ローカルLLM on iOSの大本命は確実にこれ。今年のWWDCが楽しみです。
iOSビルトインのMLモデルに関連する記事:
-
iPhone 15 Pro使用 ↩︎
Discussion