Core MLの新しいモデルタイプ、ML Programとは何なのか
coremltools 5.0より、ML Programなるものがサポートされた。
Added a new kind of Core ML model type, called ML Program.
What's Newの1行目に書かれるぐらい重要なアップデートだが、これが何であるかの情報は少ない。「Core ML Survival Guide」のMatthijs Hollemans氏(CoreMLHelpersの方が知っている人は多いかもしれない)もこの大幅アップデートをもってCore ML周りに関して発信すること/本の更新を止めてしまった…
WWDCでは、WWDC22の「Optimize your Core ML usage」とWWDC21の「Tune your Core ML models」の2セッションでML Programsについて触れられている。
WWDC22のセッションではML Programのモデルタイプに関する新機能についての紹介はあるものの、「ML Programとは何なのか」については解説がない。
WWDC21の上述のセッションでは、ML Program登場年ということもあり、ML Programの基本的な解説があった。というわけでそのセッションの当該パートをベースに「ML Programとは何なのか」についてまとめる。
ML Programとはどのようなものか?
機械学習は数式やグラフ、ネットワークの形で表されたり、またコードで表現されたりするが、
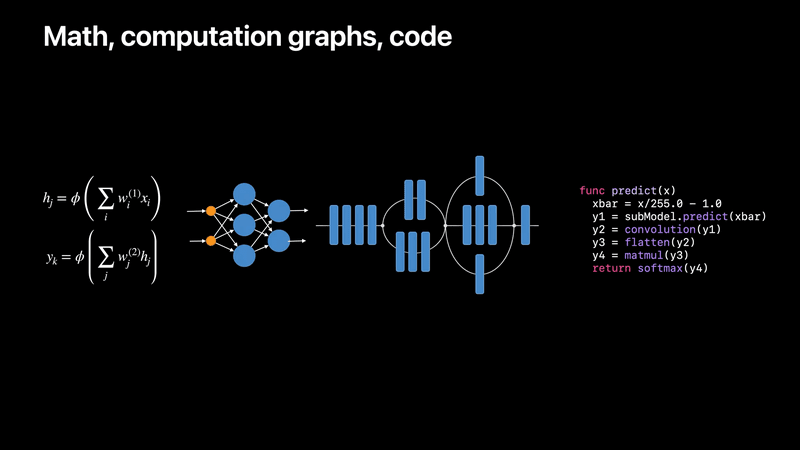
数式、グラフ、ネットワーク、コードでの表現
ML Programというモデルタイプは、この最後のコード表現に沿うものである。
こちらがML Programの例:
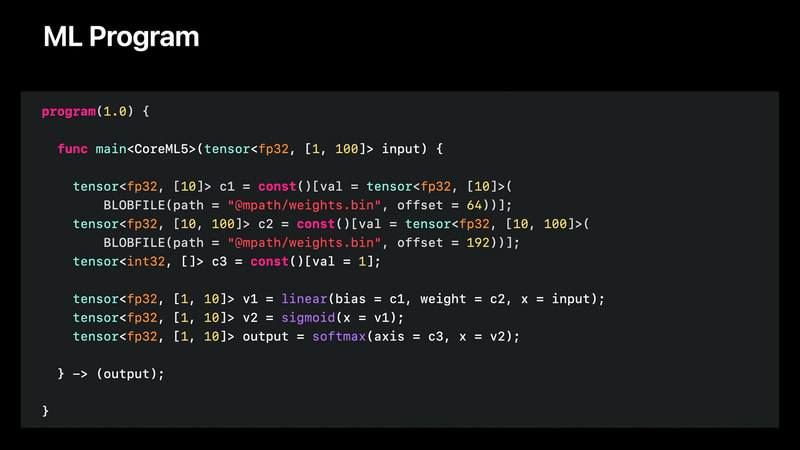
これはCore MLのコンバーター(coremltools)が自動生成するので自分で書く必要はないのだが、人間が読めるテキスト形式になっている。
MLプログラムはひとつのmain関数を持ち、このmain関数は、操作シーケンス(ops)から構成される。各opは変数を生成し、この変数は強く型付けされる。
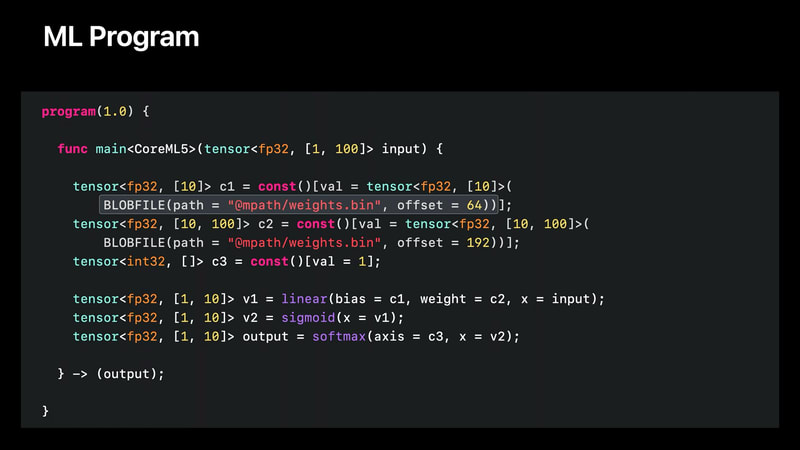
線形演算や畳み込み演算のように重みを持つ演算は、別のバイナリファイルにシリアライズされる。
従来のモデルタイプとの違い
ML Program以前の、従来のCore MLモデル内における表現(公式ではこれをNeural Networkと呼んでいる。文脈によって単に一般的な意味でのニューラルネットワークのことを言っているのか、ML Programに相当するモデル表現手段のことを言っているのかが変わるのでややこしい)との違いを表にまとめたのがこちら:

-
Neural Networkはレイヤーを持ち,ML Programは演算を持つ
-
Neural Networkでは重みはレイヤーに埋め込まれるが、ML Programでは重みは別個にシリアライズされる
-
Neural Networkは中間テンソル型を指定しない
- 計算ユニットが実行時にその型を決定する
-
一方、MLプログラムはテンソルを強く型付けする
ML Programの中間テンソル型付けと、そのメリット
従来のモデル表現における中間テンソルの型付け
従来のモデル表現(Neural Network)では、入力・出力の型に Float32, Double, Int32を指定できる。

したがって、入力・出力テンソルは強く型付けする。
しかし、中間テンソルは強く型付けしない。
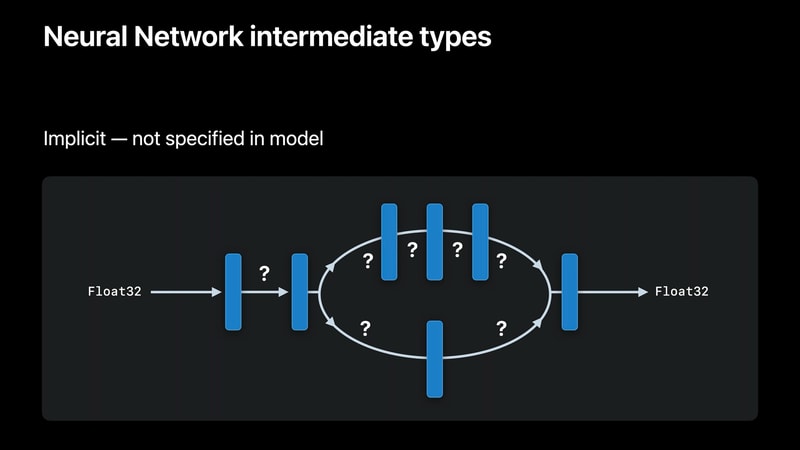
モデルにはこれらの中間テンソルの方に関する情報がないので、代わりに、Core MLがモデルをロードした後、モデルを実行する計算ユニットがテンソルの型を推測する。
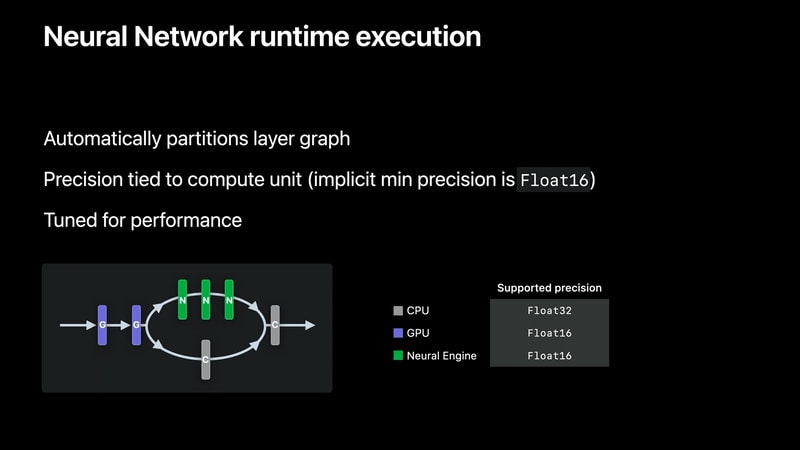
Core MLのランタイムは、ニューラルネットワークをロードする際に、ネットワークグラフを自動的かつ動的にセクション(Neural Engineフレンドリー、GPUフレンドリー、CPUフレンドリー)に分割する。
各コンピュートユニットは、そのパフォーマンスとモデル全体のパフォーマンスを最大化するために、ネイティブタイプを使用してネットワークのセクションを実行する。GPU と Neural Engine は Float16 を、CPU は Float32 を使用する。
開発者は、モデルの computeUnits プロパティで .all, .cpuAndGPU, または .cpuOnly を選択することにより、この実行スキームをある程度制御することができる。
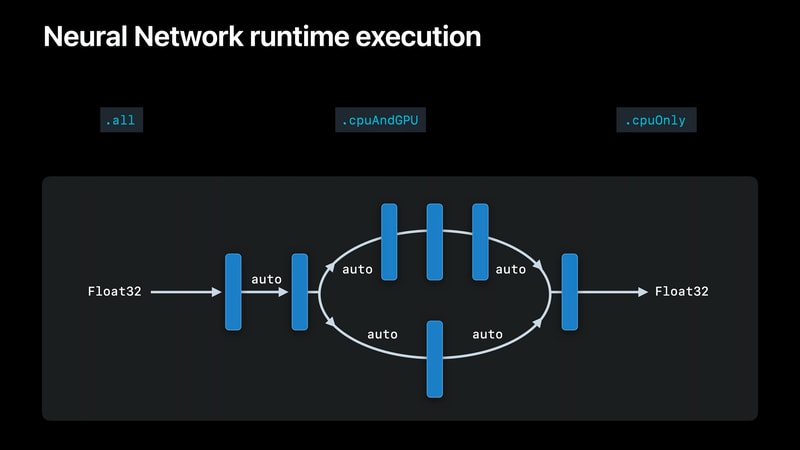
このプロパティはデフォルトで.allとなっており、Core MLに実行時にニューラルエンジン、GPU、CPUに渡ってモデルを分割し、アプリに最高のパフォーマンスを与えるように指示する。
また、.cpuOnly に設定すると、Core MLはニューラルエンジンもGPUも使用せず、CPU上でFloat32の精度のモデルのみを実行することを保証する。
まとめると、既存のモデル表現(ニューラルネットワーク)は中間テンソルを持ち、それを生成するコンピュートユニットによって、実行時に自動的に型付けされる。
computeUnits を設定することで、その精度をある程度制御することができるが、これはモデルに対するグローバルな設定であり、性能の低下を招く可能性がある。
ML Programの中間テンソル型付け
ML Programでは、入力と出力のテンソルが強く型付けされ、さらにプログラムのすべての中間テンソルも強く型付けされる。

CPUやGPUといった単一のcompute unitでの精度のサポートを混在させることもできる。
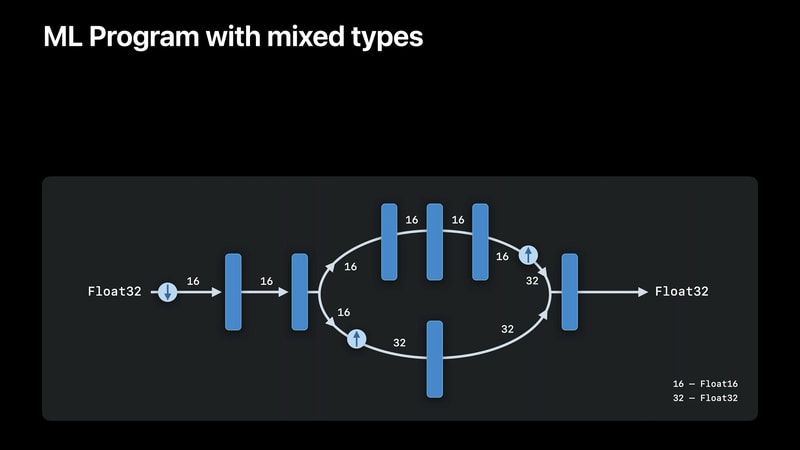
これらの型はモデル変換時に定義される。従来モデルではモデルをロードし、実行時に型が推定されていたのが、それよりずっと前の段階で決定されることになる。
ML Programは、従来と同じ(Neural Engine、GPU、CPUに処理を分配する)自動パーティショニングスキームを使用する。が、型の制約が加わる。
Core MLはテンソルをより高い精度に昇格させる機能を持つが、Core MLランタイムは中間テンソルをML Programで指定された精度より低い精度にキャストすることはない。
この型付き実行の新しいサポートは,GPUとCPUの両方で,特にGPUではFloat32の演算を,CPUではFloat16の一部の演算を拡張することで実現された。この拡張サポートにより,ML Programが Float32 精度を指定する場合でも、GPU の性能上の利点を享受することができる。
ML Programのその他のメリット
WWDC21時点ではこの「型付けされた中間テンソル」とそれによるパフォーマンス面でのメリットが、唯一のML Programの利点だった。
が、今後の機能追加はML Programモデルタイプに対してのみ行われることになる。
そしてWWDC22ではいくつかのML Program(をモデルタイプとして持つCore MLモデル)に対しての機能追加が発表された。それらについてはまた別記事にて紹介する。
ML Programの生成方法
Unified converter APIを利用することで、モデルタイプがML ProgramなCore MLモデルを生成できる。
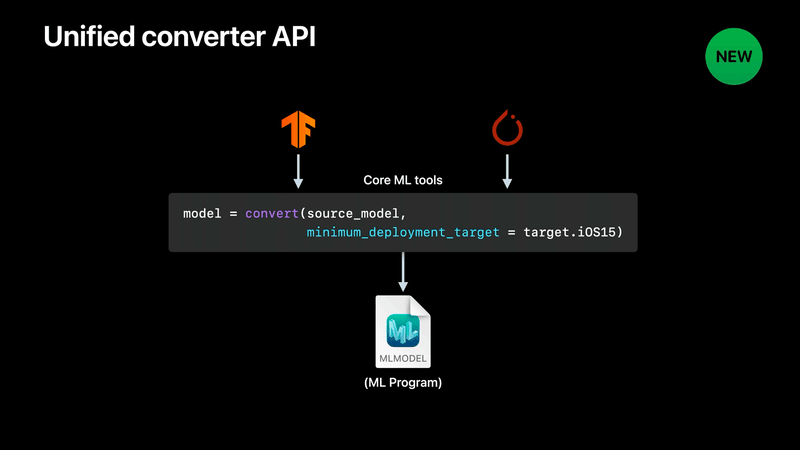
最小デプロイメントターゲットにiOS 15を指定するだけ。
iOSアドベントカレンダー
本記事はiOS Advent Calendar 2023 シリーズ2の1日目 [1]の記事です。
-
12/12時点で空いていたので書きました。 ↩︎
Discussion