【iOS 18】Core MLのアップデート
2024年7月12日に開催された「try! Swift Tokyo WWDC Recap 2024」で発表した内容です。
スライドはこちら:
以下、発表資料を記事として再構成したものになります。登壇後に調査した内容も追記しています。
前段の話
Core MLについてキャッチアップする意味あるの?
WWDC24といえば

開発者とApple Intelligence
- App Intentsでアプリの機能をexposeしておけば、賢くなったSiriがよしなに呼び出してくれる
→ 受動的/間接的
- Writing Tools, Image Playground, Genmoji等のAPIも利用可能
→ 標準UIを利用
こういう感じで使えるAPIではない

ビルトインMLフレームワーク

→ かなり充実してきた

とはいえ、標準MLフレームワークがサポートしてない分野はまだまだたくさんある
- 汎用のセグメンテーション
- デプス推定
- 高速な音声認識
- etc...
Core MLを使えば自前でMLモデルを用意できる
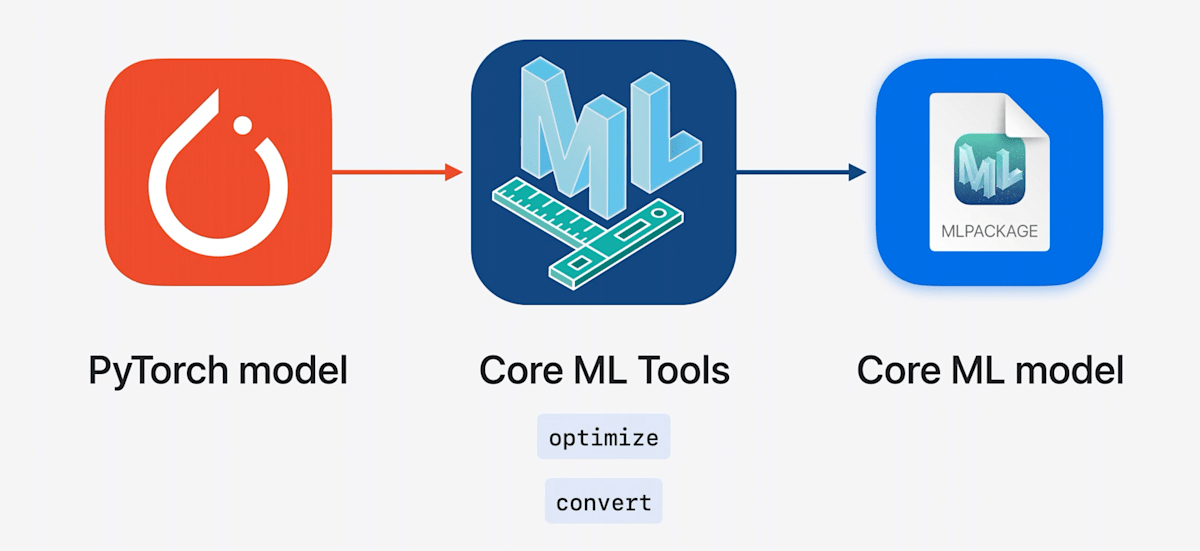
最新のMLモデルもアプリに組み込める

ここまでのまとめ
(Apple IntelligenceやビルトインMLフレームワーク群は非常に魅力的な機能ではあるが、)
Core MLを使うと標準サポートされてないMLモデルをiOS/macOS/watchOS/visionOSアプリに持ってこれて楽しい!
アジェンダ
- 新しい公式配布モデル
- 推論スタックの改善
- 新しいモデル圧縮手法
- パフォーマンスレポート
新しい公式配布モデル
AppleのCore MLモデル配布ページ
developer.apple.com/machine-learning/models/
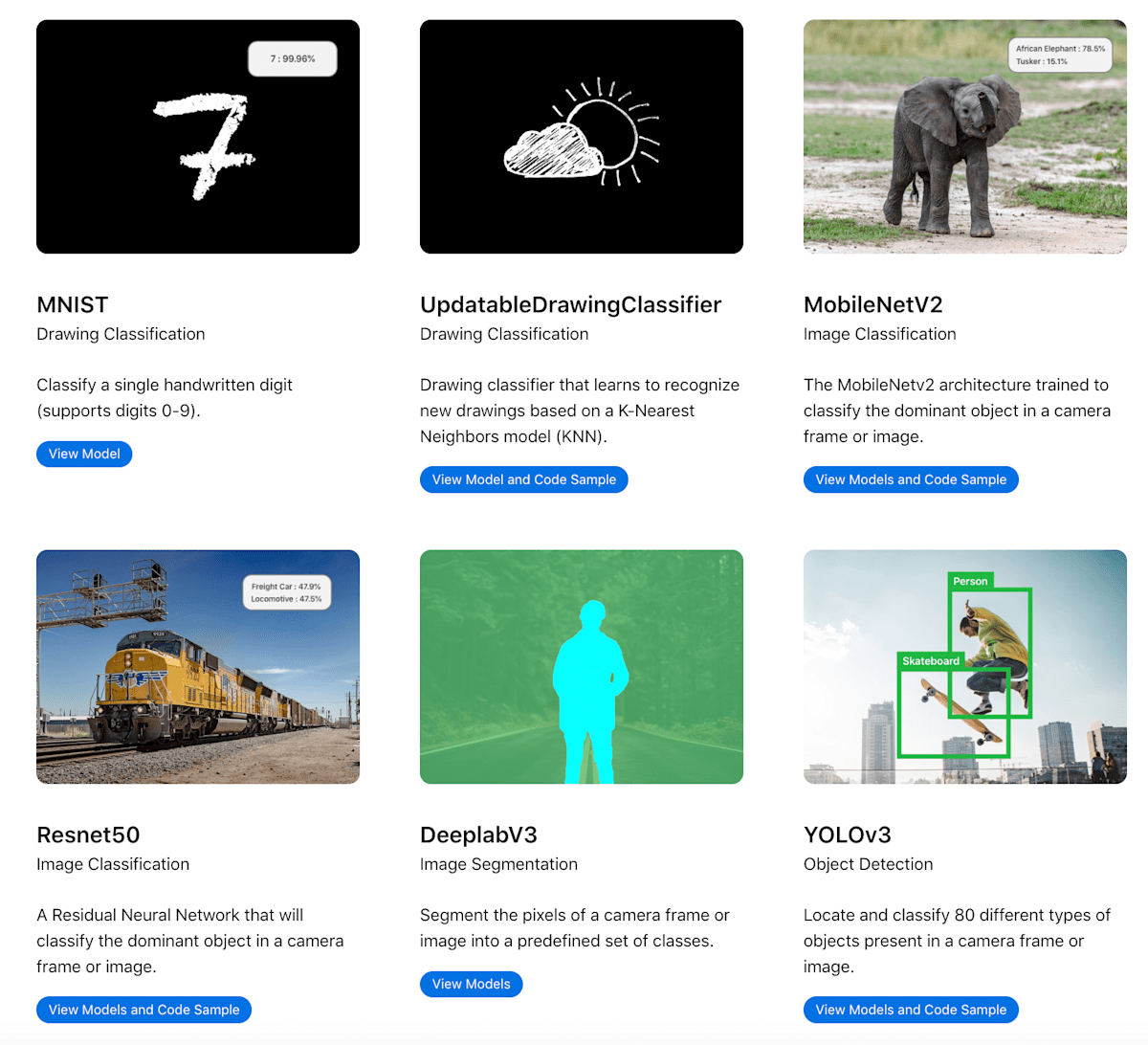
- ここ数年追加されていないなかった
- 久々の追加 🎉
Hugging Face Hubで公開されるように
- WWDC24会期中に公開されたもよう
- おそらくこっちの方がモデル配布ページより更新が早い
新公式配布モデル1: セグメンテーション
既存のセグメンテーション手法
VisionやARKitにも人・髪・肌・歯・空をセグメンテーションするAPIはある

- iOSDC 2018のトーク: 「Depth in Depth」
- ARKitのPeople Occlusion
- Portrait Matteで背景分離/セグメンテーション
- iOSで「髪」「肌」「歯」「空」をセグメンテーションする
一般物体のセグメンテーションCore MLモデルも2019年から公式配布されている
新しい公式配布セグメンテーションモデル「DETR Resnet50 Semantic Segmentation」
huggingface.co/apple/coreml-detr-semantic-segmentation
- iOS 17以降で利用可能
| Device | OS | 推論時間 (ms) |
|---|---|---|
| iPhone 15 Pro Max | 17.5 | 40 |
| iPhone 12 Pro Max | 18.0 | 52 |
デモ

→ 速度も精度も良さげ
新公式配布モデル2: デプス推定
デプス推定とは
複眼レンズの視差、TrueDepthカメラ、LiDARをいずれも使用せず、RGB写真から機械学習で深度を推定
→ 「奥行き」の情報が得られる

デプスマップを用いた3D表現。iOS-Depth-Samplerより
既存のデプス推定モデル
- デプス推定Core MLモデル「FCRN」が2019年から公式配布されている [1]

新しい公式配布デプス推定モデル「Depth Anything V2」
huggingface.co/apple/coreml-detr-semantic-segmentation
- デプス推定のState-of-the-art(最先端)モデル
- iOS 17以降で利用可能
| Device | OS | Inference time (ms) |
|---|---|---|
| iPhone 12 Pro Max | 18.0 | 31.10 |
| iPhone 15 Pro Max | 17.4 | 33.90 |
デモ

→ めちゃくちゃ良さげ
- 速度も精度も非常に良い
- 出力デプスマップの解像度も(FCRNと比較して)大幅アップ
- 128 × 160 → 518 × 392
(余談)visionOSでも同モデルを利用?
visionOSは、先進的な機械学習を活用して、2D画像をVision Proで真に生き生きと映し出される美しい空間写真に変換します。 (visionOS 2、Apple Vision Proに新しい空間コンピューティング体験を提供 - Apple)
推論スタック全体の改善
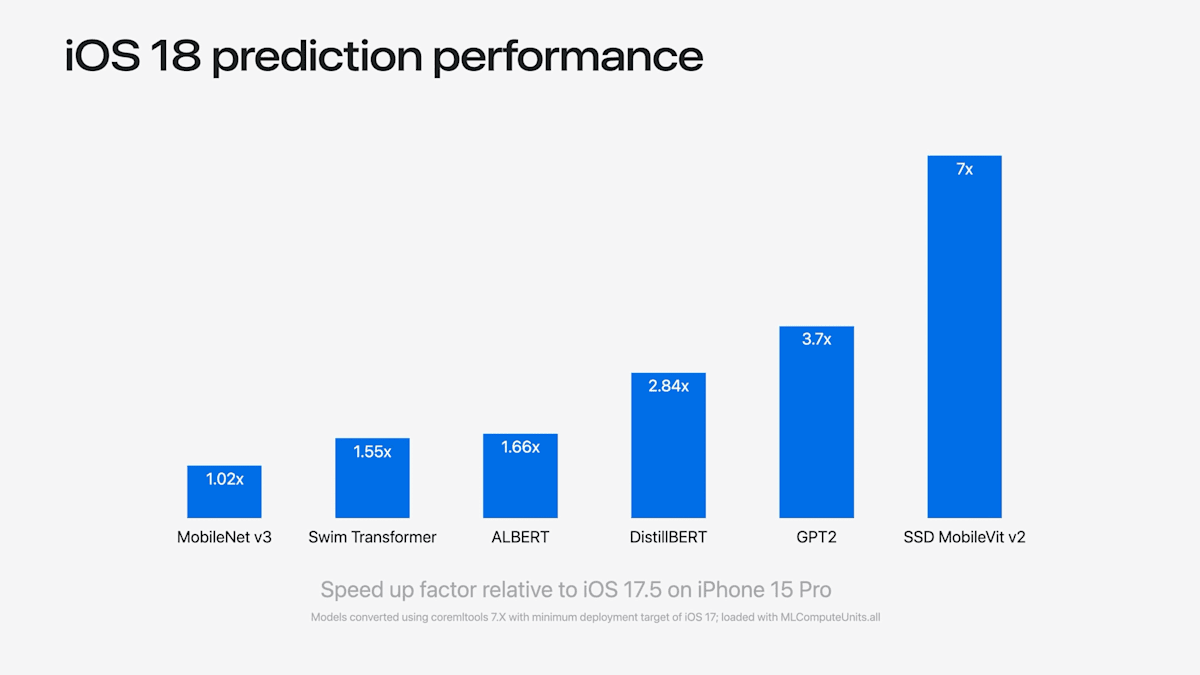
パフォーマンスが大幅に向上
- 図はiOS 17と18の推論時間の比較
- OS内での改善なので、モデルを再コンパイルしたり、コードを変更せずとも恩恵を受けられる
試してみる
Core ML Stable Diffusion XL @iOS 17
Hugging Face製アプリ「Diffusers」で Core ML版Stable Diffusion XLモデル がiOSで動くか検証した
(iPhone 15 Pro 使用)
- モデルのロード
- 起動毎に5分
- 画像生成
- 必ずクラッシュ

メモリ使用量のスパイクにより必ずクラッシュ
詳細はこちら:
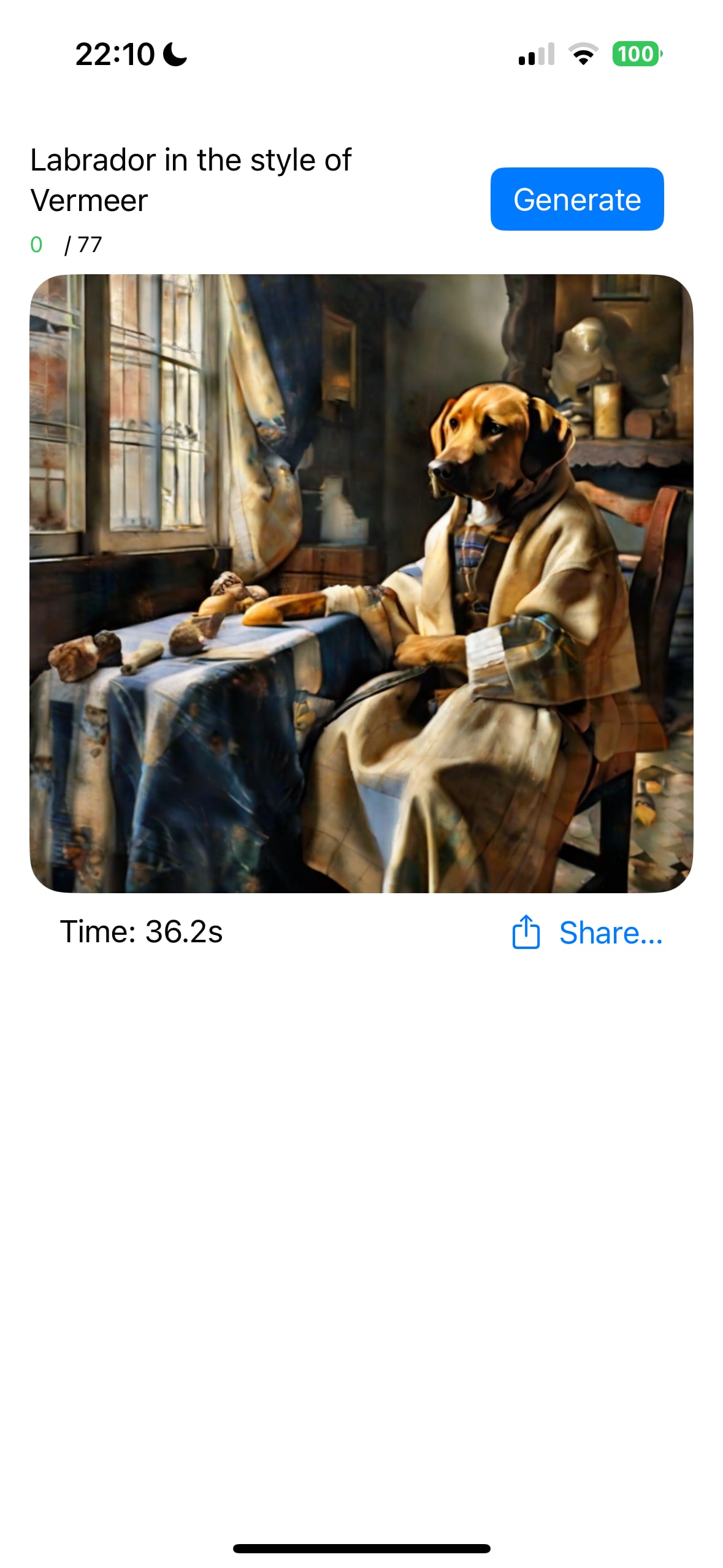
Core ML Stable Diffusion XL @iOS 18
同モデルをiOS 18で動かしてみた
- 起動毎のローディング
- iOS 17では5分 → 3分(2回目以降20〜40秒)
- 画像生成
- iOS 17では不可 → 40秒前後 [2]
→ iOS 17では動かなかったStable Diffusion XLモデルがiOS 18ではiPhoneオンデバイスで推論(画像生成)できるように 🎉
新しいモデル圧縮手法
Core ML × 生成AIの問題
サイズがでかすぎる(数GB〜10GB以上もザラ)
- アプリバイナリに含められない/DLさせるにもデカすぎる
- メモリを食うので落ちる
- 推論(生成)時間もかかる
詳細はこちら:
→ 強力なモデル圧縮手段が必要
coremltools とは
- PyTorch等で作成したモデルをCore ML形式に変換するツール
- モデルを圧縮する機能も持っている
- オープンソース

coremltoolsとCore MLフレームワークのバージョン
| Core ML | coremltools |
|---|---|
| iOS 18, macOS 15, visionOS 2, watchOS 11 | 8 |
| iOS 17, macOS 14, visionOS 1, watchOS 10 | 7 |
| iOS 16, macOS 13, visionOS 1, watchOS 9 | 6 |
| ... | ... |
| iOS 11, macOS 10.13, visionOS 1, watchOS 4 | 1 |
今回は coremltools 8 (現時点の最新は 8.0b1)の話
既存のモデル圧縮手法
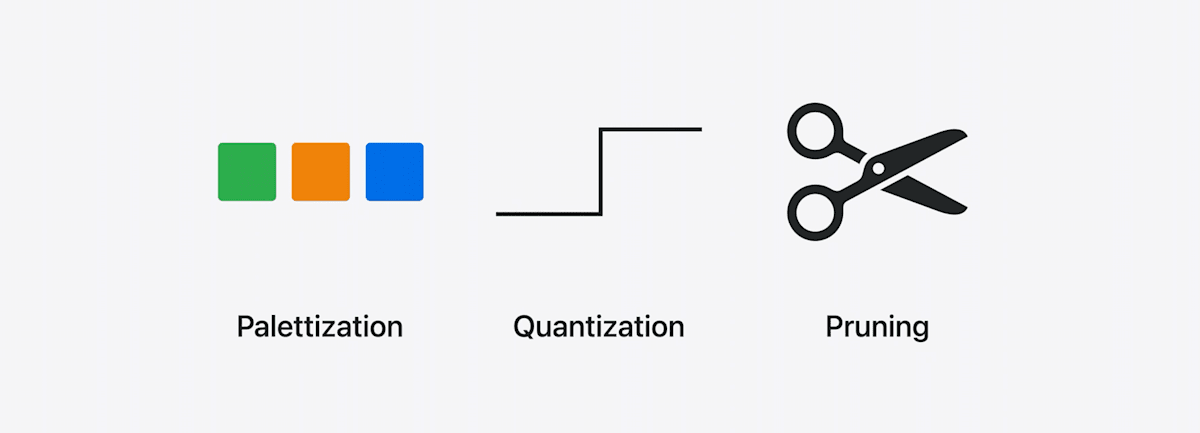
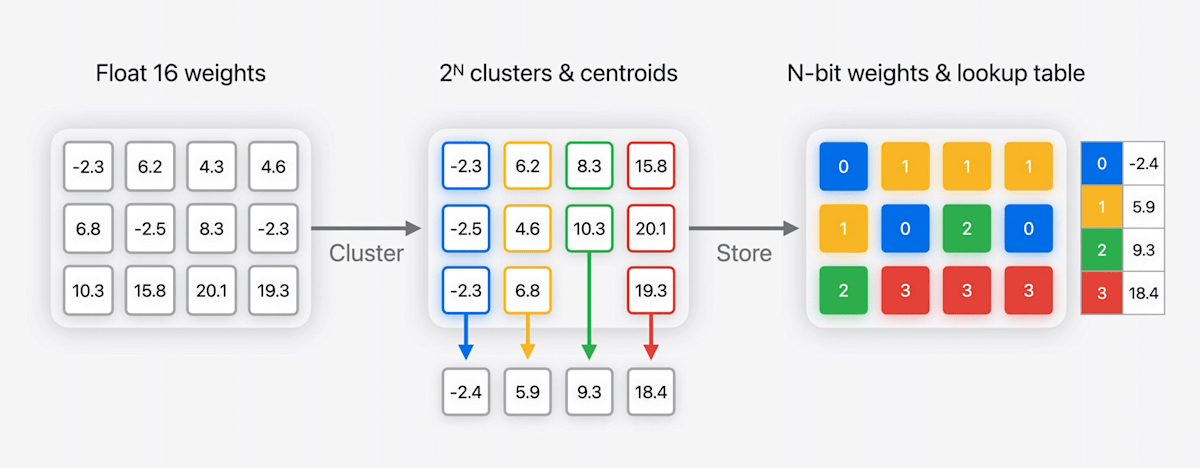
Palettization(パレット化)

- 似たような値を持つ重みをクラスタ化
- クラスタのセントロイドをLUTに格納
→ LUTへのNビットのインデックスマップが圧縮後の重みとなる(例では2ビットに圧縮)
Quantization(量子化)
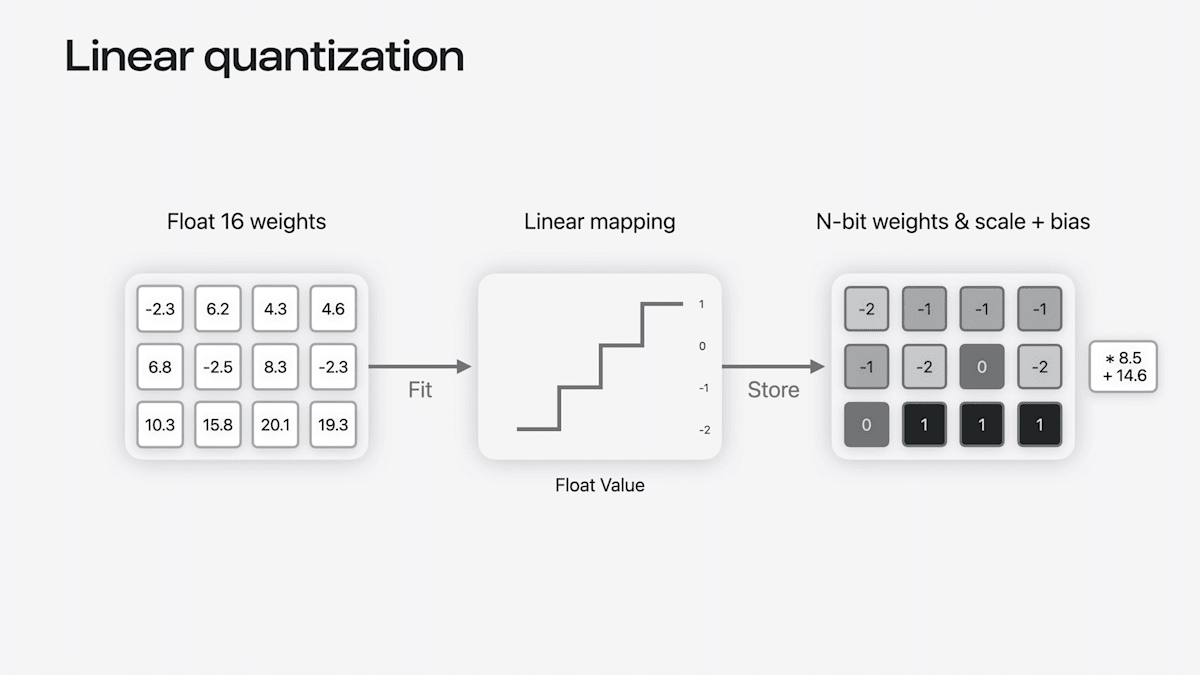
- Floatの重みを整数の範囲に線形にマッピング
→ Nビット整数重みとスケールとバイアスのペアが格納される
Pruning(枝刈り)
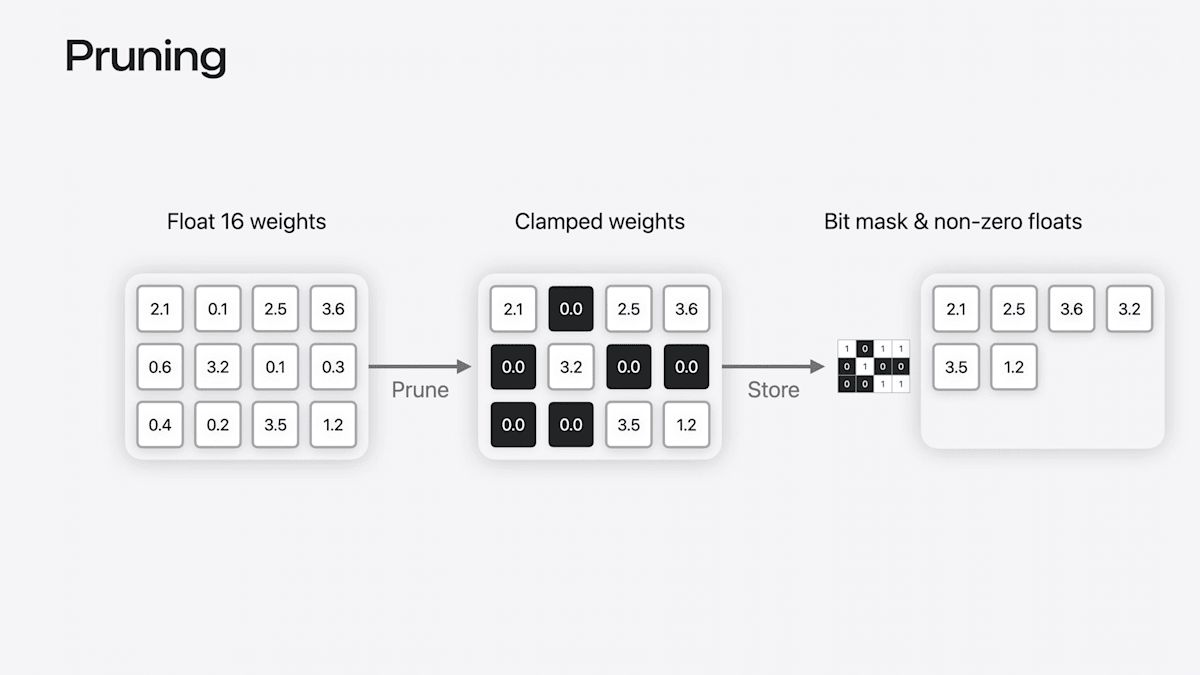
- 小さい重みを0にする
- ビットマスクと0でない値だけを保存する
既存の圧縮手法の限界
5GBのモデルを16 → 4ビットまで圧縮すると生成結果が破綻

何が問題なのか?
4ビットPalettization→ 16個のセントロイドだけで大きなモデルの重みすべてを表現しようとして破綻している
coremltools 8で可能になったモデル圧縮手法
新しいPalettization
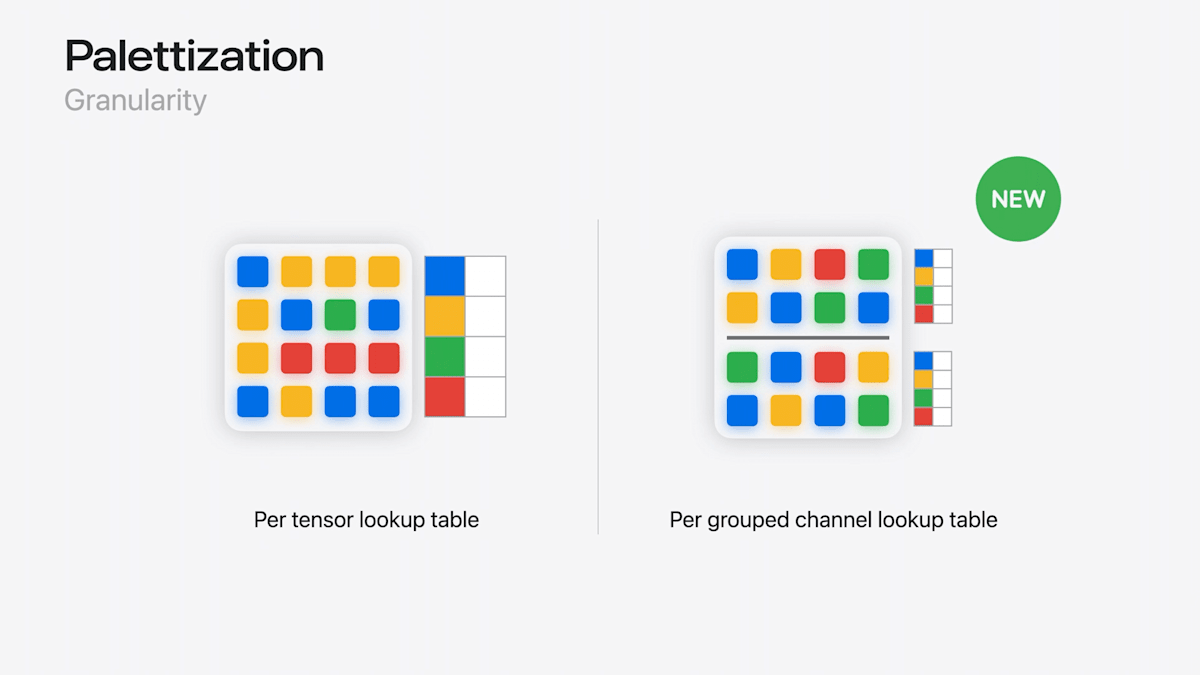
- 複数のLUTを保存できるように
→ 低ビットに圧縮しつつも精度を維持
新しいLinear quantization
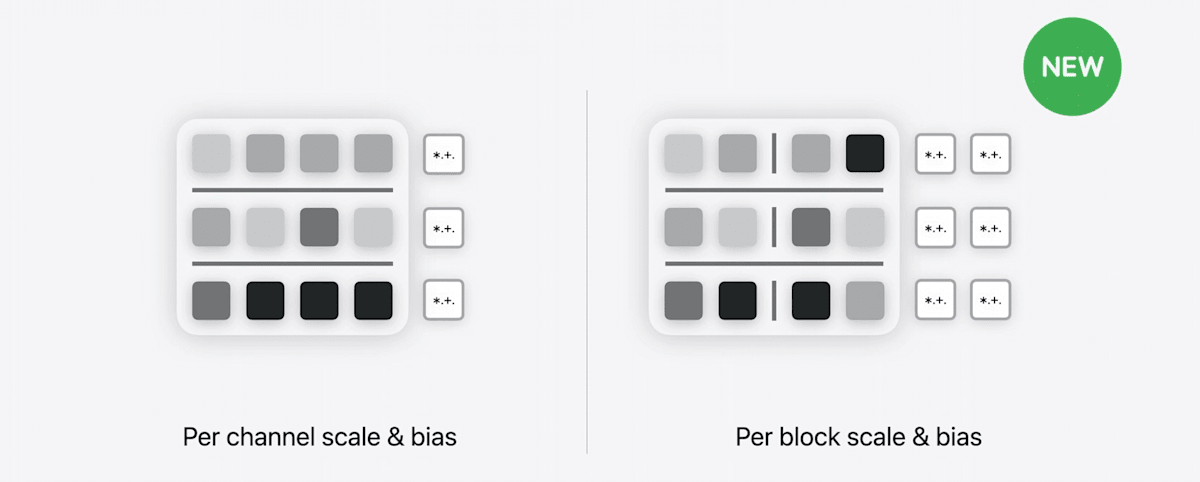
iOS 17ではチャンネルごとにスケールとバイアスを設定
→ iOS 18ではこれらをブロックごとに設定可能に
Pruning後のさらなる圧縮が可能に

- Pruning + Palettization
- Pruning + Quantization
試してみる
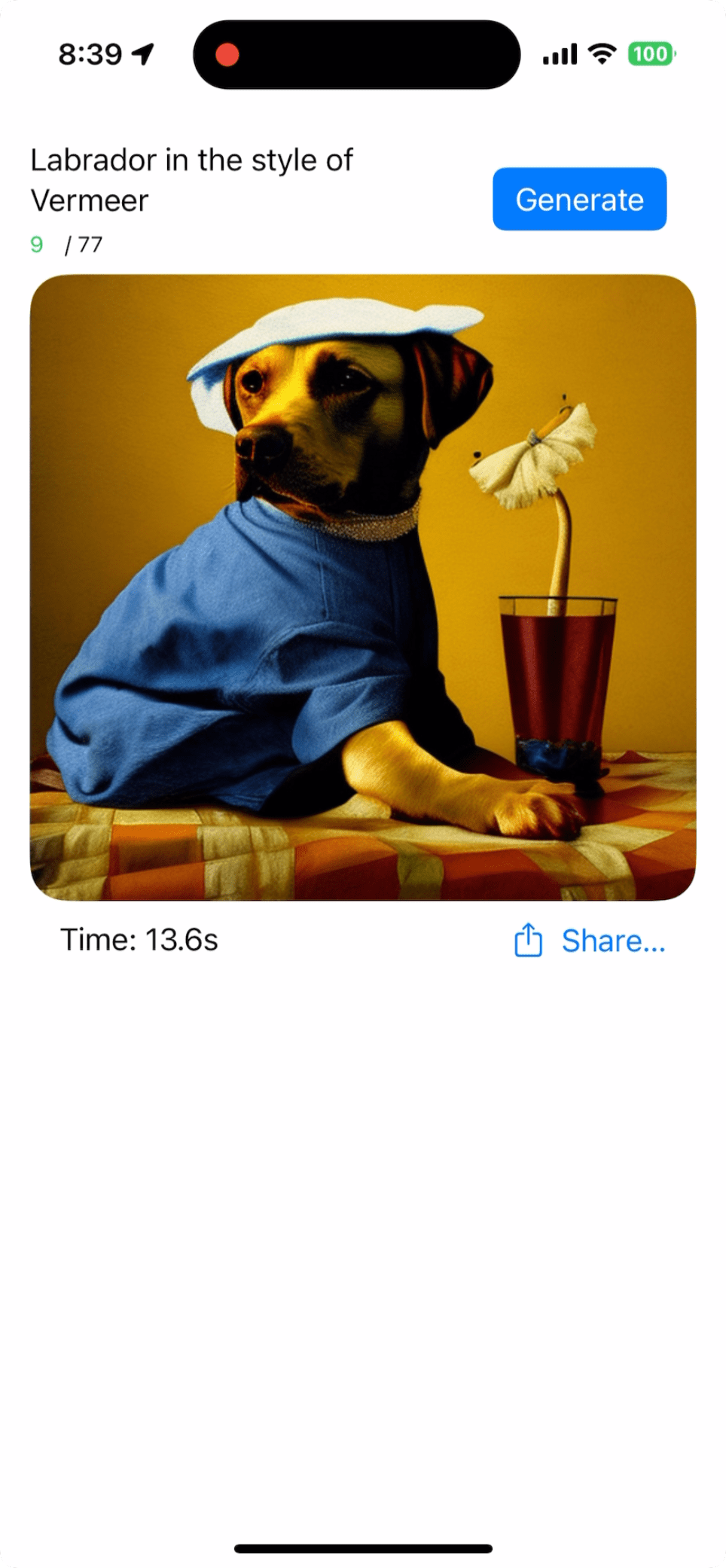
Stable Diffusionモデルを新しいPalettizationで圧縮
Stable Diffusion v2.1 (非XL) [3] のCore MLモデルを新Palettizationで圧縮する
圧縮前
(iOS 18 @iPhone 15 Proで実行)
Palettizationのコード
グループ化されたチャンネルごとのPalettizationを適用
import coremltools.optimize.coreml as cto_coreml
op_config = cto_coreml.OpPalettizerConfig(
nbits=4, # 4ビットに圧縮
mode="kmeans", # クラスタリング手法
granularity="per_grouped_channel", # 粒度
group_size=16, # グループサイズ
)
config = cto_coreml.OptimizationConfig(op_config)
compressed_mimodel = cto_coreml.palettize_weights(mlmodel, config)
圧縮後
- モデルサイズ:1.73 → 0.44 GB
- 75%削減!
- 画像生成時間:13秒 → 10秒
- 23%高速化! [6]
(iOS 18 @iPhone 15 Proで実行)

パフォーマンスレポート
パフォーマンスレポートのアップデート
- さらに多くの情報を提供するようになった [7]
- 各オペレーションの推定時間
- コンピュートデバイスのサポート
- サポートされていない理由のヒント
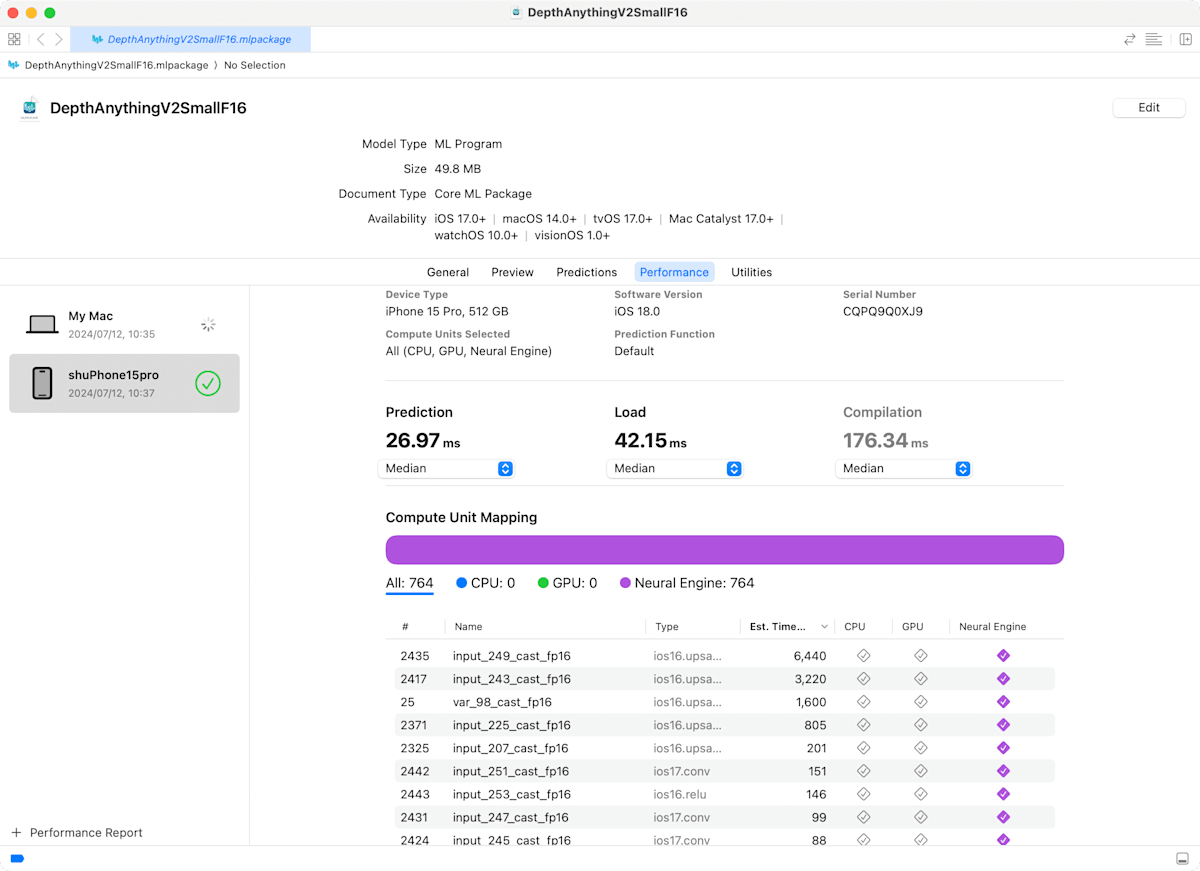
デモ:DepthAnythingV2SmallF16のレポート
MLComputePlan API
- パフォーマンスレポートのAPI版
- MLOps for Core MLが捗りそう
// Load the compute plan of an ML Program model.
let computePlan = try await MLComputePlan.load(contentsOf: modelURL, configuration: configuration)
guard case let .program(program) = computePlan.modelStructure else { ... }
// Get the main function.
guard let mainFunction = program.functions["main"] else { ... }
let operations = mainFunction.block.operations
for operation in operations {
// コンピュートデバイスのサポート情報を取得
let computeDeviceUsage = computePlan.deviceUsage(for: operation)
// 推定コストを取得
let estimatedCost = computePlan.estimatedCost(of: operation)
}
まとめ
- Core MLのアップデート
- 新しい公式配布モデル
- 推論スタックの改善
- 新しいモデル圧縮手法
- パフォーマンスレポート
リファレンス
- Bring your machine learning and AI models to Apple silicon - WWDC24 - Videos - Apple Developer
- Deploy machine learning and AI models on-device with Core ML - WWDC24 - Videos - Apple Developer
- coremltools API — coremltools API Reference 8.0b1 documentation
Discussion