Core ML版Stable DiffusionをiOSで快適に動かす
概要
Stable Diffusionとは
- 画像生成AI
- 入力テキストに応じて画像を自動生成するtext-to-imageモデル

プロンプト: sadhu man in Rishikesh, India meditating near the Ganges river
- 2022.8 オープンソースとして公開
Core ML Stable Diffusion とは
Core ML フォーマットに変換された Stable Diffusion のモデル
- 従来のモデルをAppleハードウェアで動かす => CPUのみ利用
- Core MLモデル => CPU, GPU, Neural Engineを利用
→ Appleのハードウェアを最大限活かせるのがCore MLモデル
詳細な最適化の解説:
Core ML Stable Diffusion のリポジトリ
- Apple謹製
- モデル変換コード、macOS/iOSで動かすためのSwiftコード等を含む
- 公式ブログ記事:
初登場時以降の進化
2022年12月の初公開時以降あまり話題になっていないが、着々と進化している
Core ML Stable Diffusion の何が嬉しいのか?
- 手元のMacで、無料かつオフラインで使いまくれる
- 自前のmacOS/iOSアプリに組み込める
- For me: 様々なノウハウが詰まったCore MLの公式サンプル
使い方
CLIから動かす
Swiftで書かれたCLIサンプル StableDiffusionSampleを利用する
swift run StableDiffusionSample \
"a photo of an astronaut riding a horse on mars" \
--resource-path </path/to/models> --seed 93 \
--output-path </path/to/output/image>
-
--resource-path- コンパイル済みCore MLモデルファイル
.mlmodelcが入ったディレクトリのパスを指定
- コンパイル済みCore MLモデルファイル
自作アプリに組み込む
Package.swift が存在することからも分かる通り、Swift Package Manager から自分のアプリにSwift Packageとして組み込むことができる。

Package Productとしては StableDiffusion ライブラリと StableDiffusionSample のコマンドラインツールがあり、
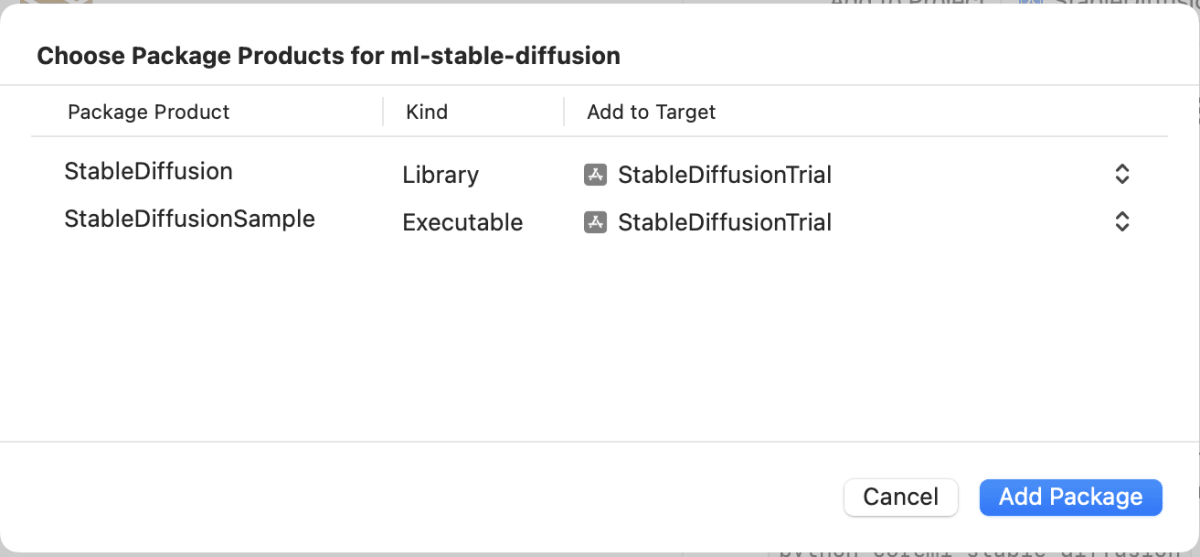
アプリに組み込む際には StableDiffusion の方をターゲットに追加する。
最小実装としてはこんな感じ:
import StableDiffusion
...
// パイプラインの初期化
let pipeline = try StableDiffusionPipeline(resourcesAt: resourceURL)
// リソースの読み込み
pipeline.loadResources()
// 画像生成
let image = try pipeline.generateImages(prompt: prompt, seed: seed).first
詳細な組み込み手順は下記記事にまとめた:
Hugging Faceによるサンプルアプリ「Diffusers」
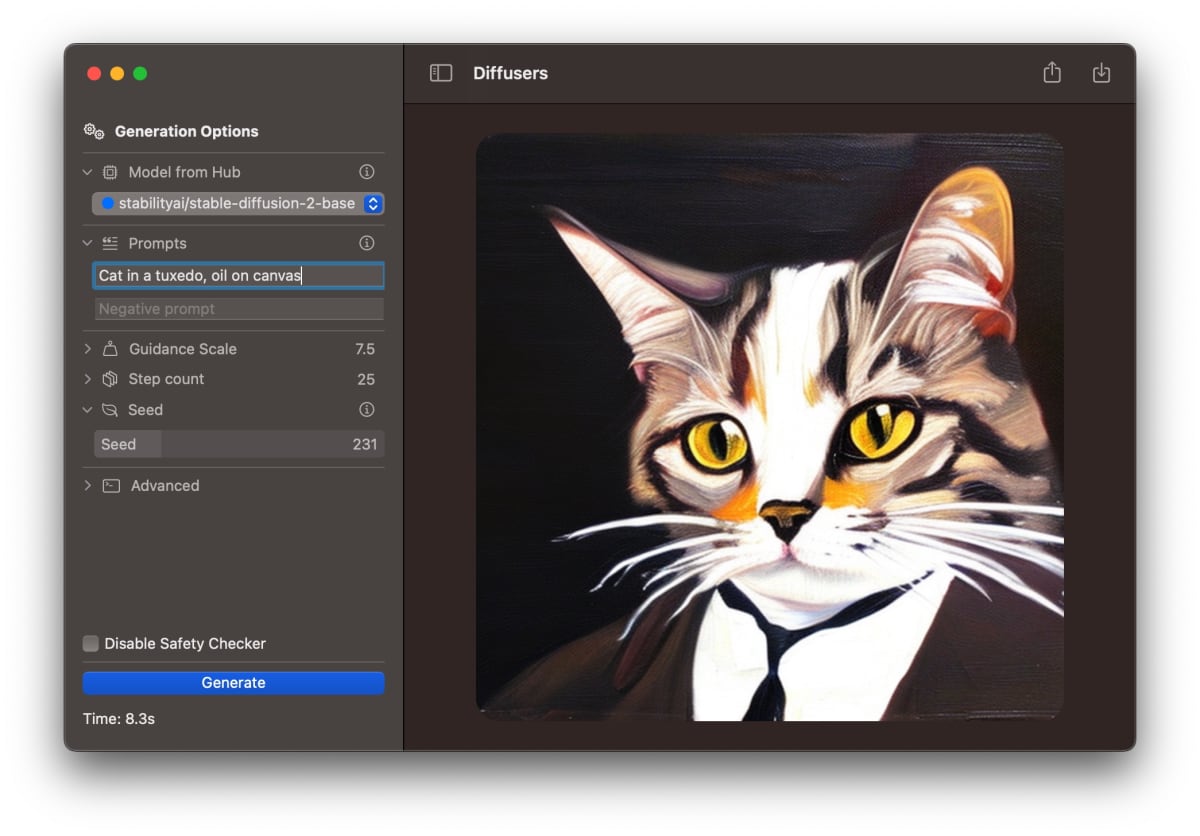
Diffusers を iPhone 15 Pro で動かしてみる
モデルのダウンロード
サイズが大きいので非常に時間がかかるが、必要なのは初回のみ

モデルのロード
こちらは起動毎に必要

起動状態
プロンプト入力用のテキストフィールドがあり、
"Generate"ボタンを押すと画像生成が開始する。

⚠️ ローディングがとてつもなく長い
起動する度に 5分
(モデルのダウンロードが完了した状態からの起動)
Pipeline loaded in 293.2635090351105
⚠️ 画像生成時に必ずクラッシュ
使用メモリ量のスパイク(iPhone 15 Pro利用)
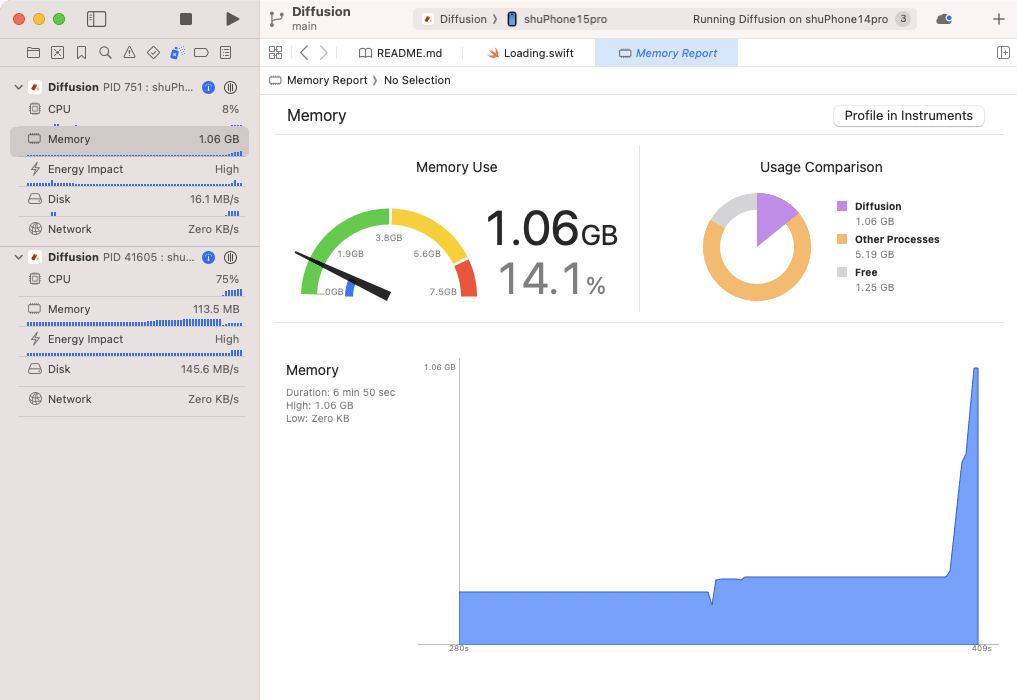
iOSで「まともに」動かす
- 使用メモリ量を小さくする
- 起動時間を短くする
- 画像生成時間を短くする
使用メモリ量を小さくする
使用メモリ量を小さくする方法
-
reduceMemoryオプションを有効にする - サイズの小さいモデルに変更する
→ まずは 「reduceMemory オプションを有効にする」をやってみる
reduceMemory を強制的に有効にする
ModelInfo.swift の reduceMemory プロパティを決定する処理を書き換える
以下の現行実装ではiPhone 15 Proの場合は必ず無効化されてしまう:
var reduceMemory: Bool {
// Enable on iOS devices, except when using quantization
if runningOnMac { return false }
if isXL { return !deviceHas8GBOrMore }
return !(quantized && deviceHas6GBOrMore)
}
いったんこうする:
var reduceMemory: Bool {
return true
}
reduceMemory を有効にするとどうなるか?
- 必要なときにモデルをロードし、すぐにアンロードする
- 画像生成処理のオーバーヘッドを増やすことになる
- ドキュメントでは解説されていないが、ソースコードを見ると起動時に
prewarmResourcesという処理を行っている
public func loadResources() throws {
if reduceMemory {
try prewarmResources()
} ...
prewarmResourcesは、loadResources 後すぐに unloadResources を行う、ということをやっている。
func prewarmResources() throws {
try loadResources()
unloadResources()
}
これは、apple/ml-stable-diffusionリポジトリのREADMEに書かれている、コンパイルされたアセットがキャッシュされる仕組みを利用しており、一度ロードしておくとその後アンロードしても、初回と同様のコンパイルは発生しない。
Both
.mlpackageand.mlmodelcmodels are compiled upon first load. (中略).mlmodelcfiles do cache this compiled asset and non-first load times are reduced to just a few seconds.
デモ
画像生成時にクラッシュしなくなった
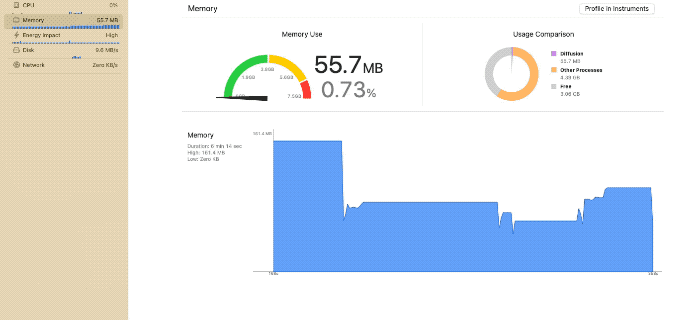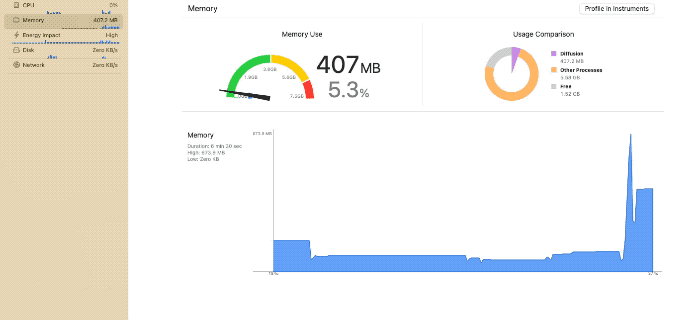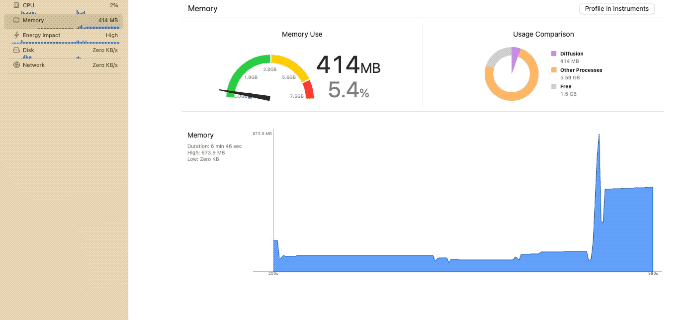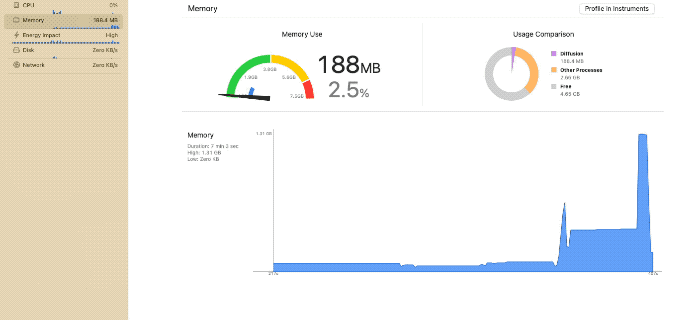
都度アンロードが発生し、メモリ使用量のピークが抑えられている
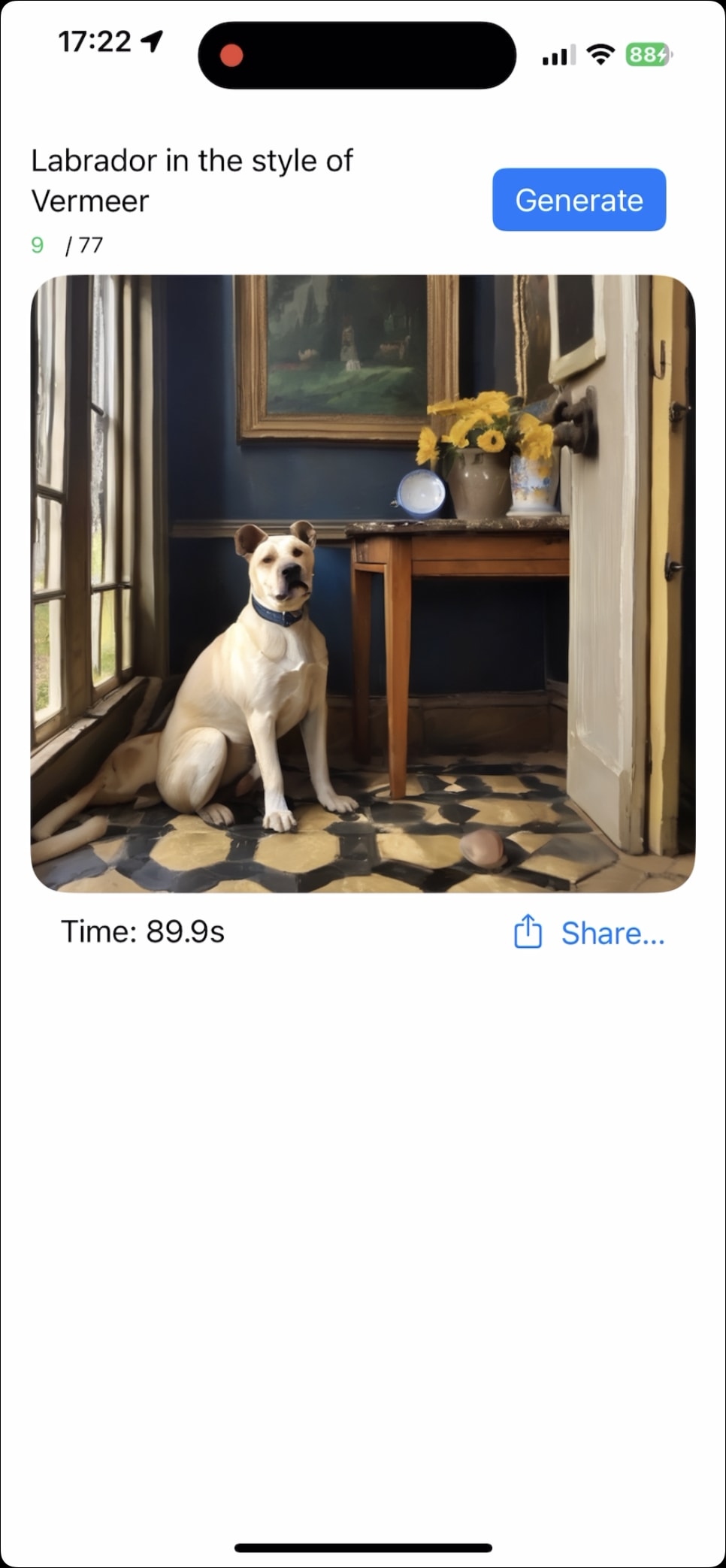
画像生成結果
⚠️ 画像生成に時間がかかりすぎる
画像生成の処理時間
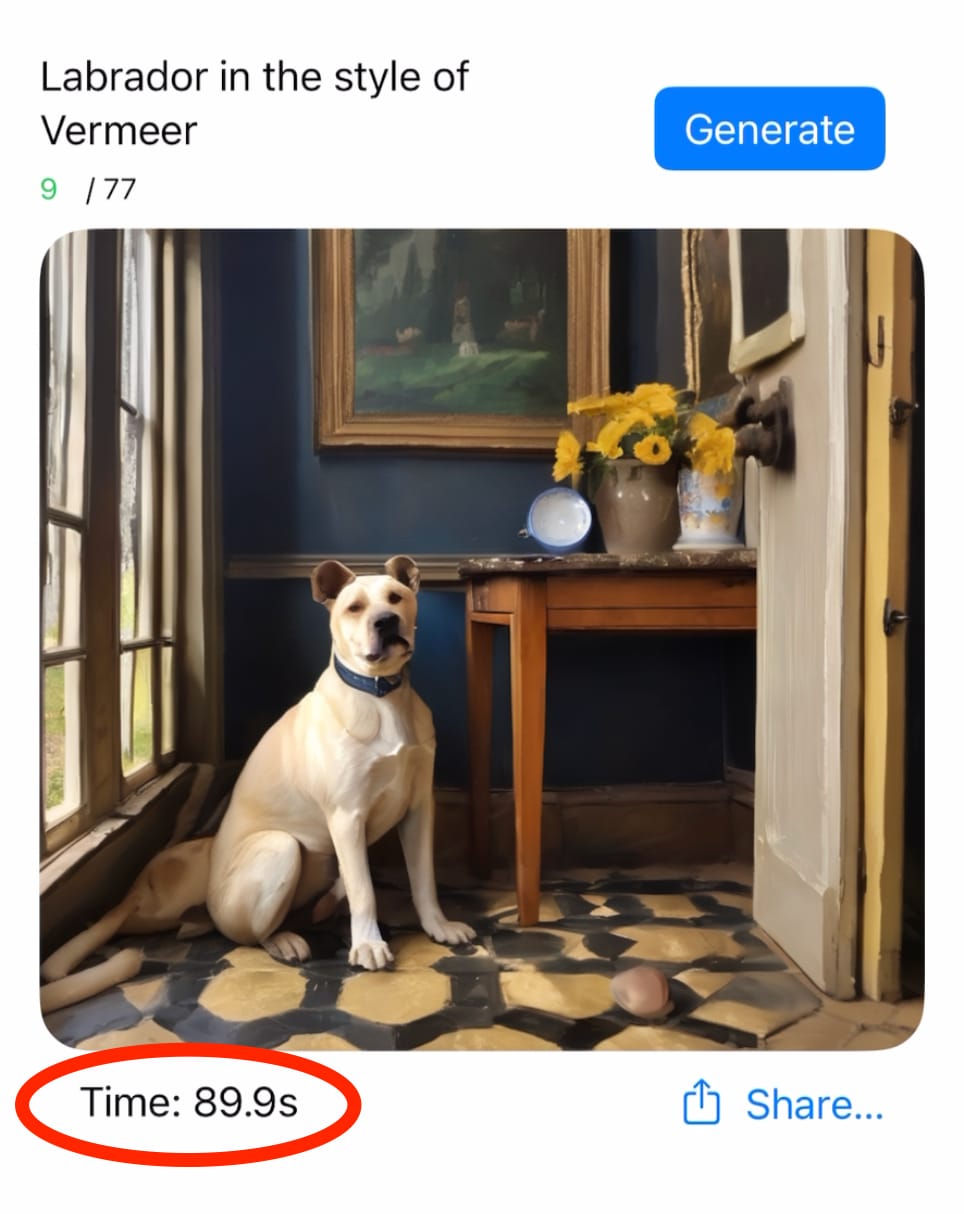
1枚あたり90秒
起動時間も依然として5分かかっている
起動時間と画像生成時間を短くする
起動時間を短くする方法
起動時間のほとんどが、モデルのロード(ライブラリ内の loadResources メソッド。実態としては MLModel の初期化)に時間がかかっている
→ サイズの小さいモデルに変更する
画像生成時間を短くする方法
サイズの小さいモデルに変更する
The Neural Engine is capable of accelerating models with low-bit palettization: 1, 2, 4, 6 or 8 bits. (ニューラル・エンジンは、低ビットのパレタイズでモデルを高速化できる)
compressed weights are faster to fetch from memory ... (圧縮されたウェイトはメモリからのフェッチが高速になり、)
( apple/ml-stable-diffusion のREADMEより)
(再掲)使用メモリ量を小さくする方法
-
reduceMemoryオプションを有効にする - ⭕ サイズの小さいモデルに変更する
→ とにかくモデルの圧縮が重要
現在の使用モデルを調べる
let loader = PipelineLoader(model: iosModel())
iosModel() によるモデルの決定ロジック:
func iosModel() -> ModelInfo {
guard deviceSupportsQuantization else { return ModelInfo.v21Base }
if deviceHas6GBOrMore { return ModelInfo.xlmbpChunked }
return ModelInfo.v21Palettized
}
→ iPhone 15 Proでは ModelInfo.xlmbpChunked を利用( deviceSupportsQuantization が true かつ deviceHas6GBOrMore が true )
xlmbpChunked の定義:
static let xlmbpChunked = ModelInfo(
modelId: "apple/coreml-stable-diffusion-xl-base-ios",
modelVersion: "SDXL base (768, iOS) [4 bit]",
supportsEncoder: false,
quantized: true,
isXL: true
)
→ apple/coreml-stable-diffusion-xl-base-ios を利用している
- iOS向けに 4.04 混合ビット量子化(mixed-bit palettization)したもの
- ・・・ではあるが、もともとがSDXLモデルなのでクソでかい
- Unetだけで 1.3 GB以上
モデルを圧縮する or モデルの圧縮版を探す
Hugging Face で公開されている Core ML Stable Diffusion モデル
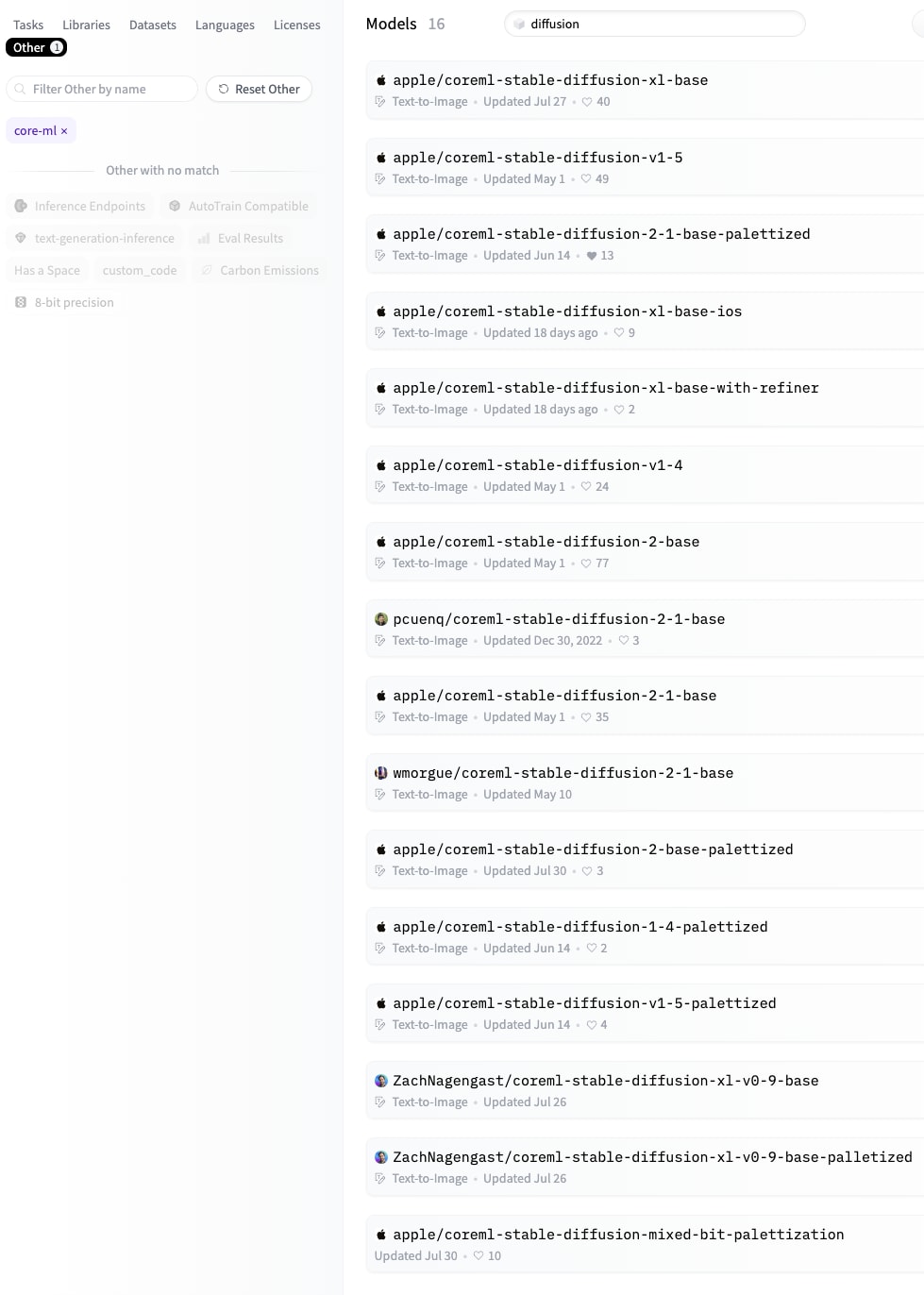
→ 2023年10月現在で16種類
🤷🏻♀️ どれを選べばいいのか 🤷🏻♂️
軽いCore ML Stable Diffusionモデルを選ぶポイント
-
SDXLではないもの・・・XLは最新の高画質版であり、デカい
-
palletized とついているもの・・・圧縮されていることを示す
- 16bit -> 6-bit
-
SDバージョンの違いによるサイズの違いはあまりない
→ "apple/coreml-stable-diffusion-2-1-base-palettized"
最終デモ

各種パフォーマンス
さらなる起動時間の短縮
モデルのロード(MLModelの初期化)が90%以上を占める
time to load unet: 57.41793203353882
time to load textEncoder: 30.462964057922363
time to load decoder: 3.1042929887771606
time to load encoder: 2.146523952484131
Pipeline resources loaded in 106.28662097454071
さらなるモデル圧縮
Mixed-Bit Palettization
公式リポジトリREADME の "Advanced Weight Compression (Lower than 6-bits)" に詳細あり
coremltools 8 / iOS 18〜の新しい圧縮方法
coremltools 8では粒度の高いPalettizationが可能となり、4ビットまで圧縮しても破綻せず画像生成が行えるようになった。
詳細はこちらの記事 の「新しいモデル圧縮手法」という節にまとめた。
more
- ControlNet
- Multilingual text encoder
- 関連記事: [iOS 17] 多言語BERT埋め込みモデルのサポート
まとめ
Stable DiffusionのようなクソデカCore MLモデルをiOSで動かす
-
キャッシュ機構を利用して都度ロード & アンロード
- → メモリ使用量を抑える
-
モデルサイズを小さくする
-
→ 起動時間・メモリ使用量・画像生成時間すべて改善
- Hugging Face探す/coremltoolsで自前圧縮/Mixed-Bit Palettization
-
Discussion