多言語BERT埋め込みモデルのサポート - NLContextualEmbedding
自然言語処理周りの処理を担うNatural Languageフレームワークのアップデートについて解説してくれているWWDC23の「Explore Natural Language multilingual models」というセッションを見たメモ。
Natural Language関連のセッションとしてはWWDC20以来の実に3年ぶり。
概要をざっくりいうと「多言語の BERT embedding をサポートしました」という話。
(以下、引用表記と画像は基本的に "Explore Natural Language multilingual models" セッションより引用)
埋め込み(embedding)とは何か
LLMの隆盛もあり、自然言語処理を専門としていない人でも "embedding" という単語は耳にしたことがあるかもしれない。セッションではまずはここの解説があった。
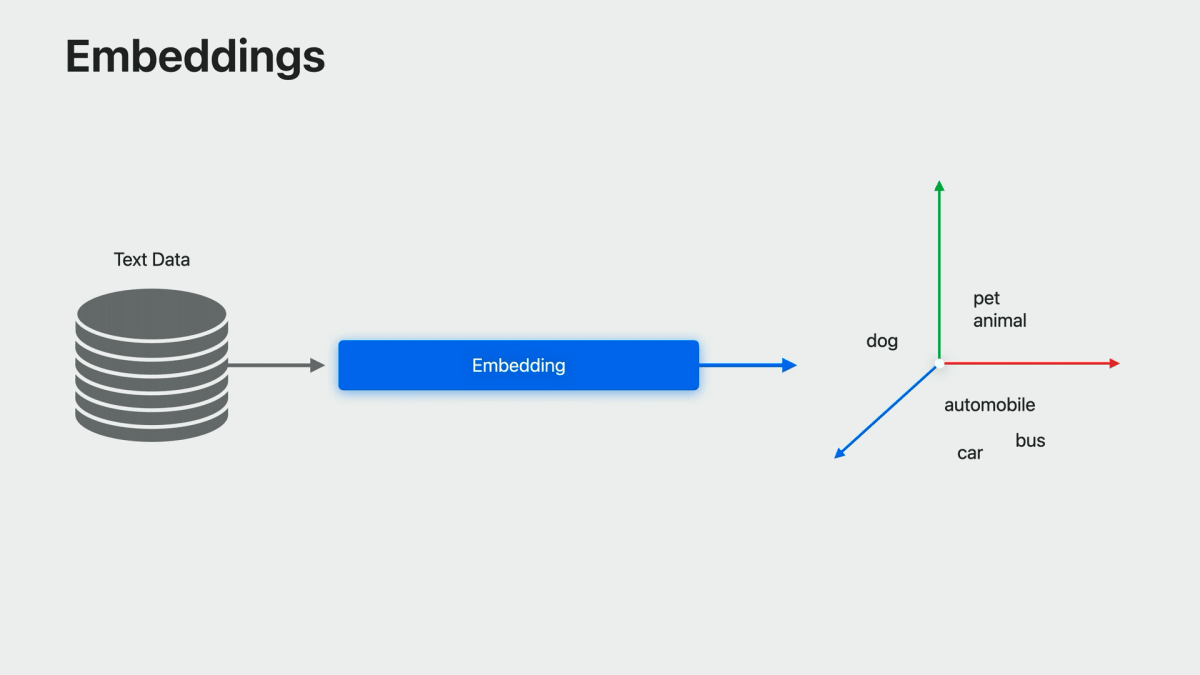
In the simplest form, it’s just a map from words in a language to vectors in some abstract vector space, but trained as a machine learning model such that words with similar meaning are close together in vector space.
(最も単純な形は、言語内の単語から抽象的なベクトル空間のベクトルへの写像に過ぎないが、機械学習モデルとして、似たような意味を持つ単語がベクトル空間内で近接するように学習させる。)This allows it to incorporate linguistic knowledge.
(これによって、言語的な知識を取り込むことができる。)
Contextual embedding
続いて、今回新たにサポートされた contextual embedding について解説があった。
Static embeddings と Contextual embeddings の違い

Static embeddings are just a simple map from words to vectors.
(静的埋め込みは、単語からベクトルへの単純な写像に過ぎません。)Pass in a word, the model looks it up in a table and provides a vector.
(単語を入力すると、モデルがその単語を表で調べてベクトルを提供します。)These are trained such that words with similar meaning are close together in vector space.
(このモデルは、似たような意味を持つ単語がベクトル空間上で近接するように学習されます。)This is quite useful for understanding individual words.
(これは、個々の単語を理解するのに非常に便利です。)
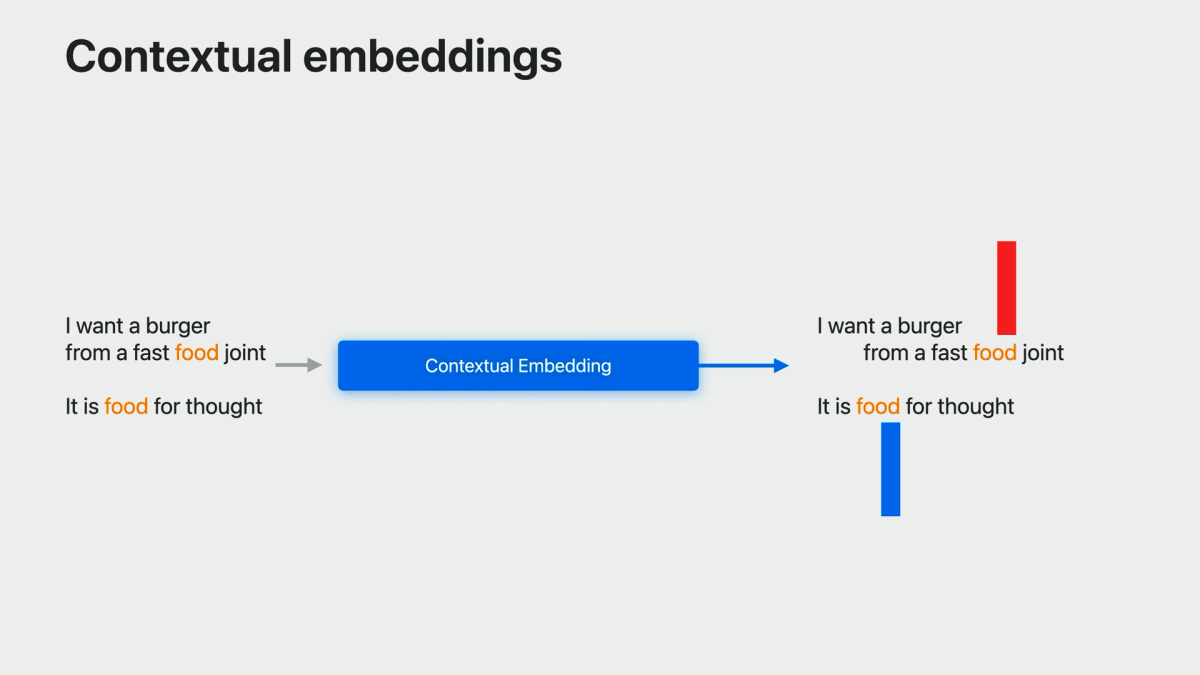
More sophisticated embeddings are dynamic and contextual such that each word in a sentence is mapped to a different vector depending on its use in the sentence.
(より洗練された埋め込みは、動的かつ文脈的で、文中の各単語が文中での使用状況に応じて異なるベクトルにマップされます。)For example, “food” in “fast food joint” has a different meaning than “food” in “food for thought,” so they will get different embedding vectors.
(例えば、「fast food joint」の「food」と「food for thought」の「food」は意味が異なるので、異なる埋め込みベクトルを得ることになります。)
Contextual embeddingを入力層に持つ意味
これも重要なので引用:
Now, the point of having a powerful embedding as an input layer is to allow for transfer learning. (さて、強力な埋め込みを入力層として持つ意味は、転移学習を可能にするためです。)
The embedding is trained on large amounts of data and encapsulates general knowledge of the language, which can be transferred to your specific task without requiring huge amounts of task-specific training data. (embeddingは、大量のデータで学習され、言語の一般的な知識をカプセル化しているので、タスク固有の膨大な学習データを必要とせず、あなたの特定のタスクに転送することができます。)
Create MLにおけるELMoモデルのサポート
なお、Create MLの新しいバージョンでは、ELMoモデルによる Contextual Embedding の生成をサポートしているとのこと。

Currently, Create ML supports embeddings of this sort using ELMo models.
(現在、Create MLはELMoモデルを使ってこの種の埋め込みをサポートしています。)These models are based on LSTMs whose outputs are combined to produce the embedding vector.
(このモデルはLSTMをベースとしており、その出力を組み合わせて埋め込みベクトルを生成します。)These can be used via Create ML for training classification and tagging models.
(このモデルは、Create MLで分類モデルやタグ付けモデルを学習する際に利用することができます。)
Multilingual embeddings
ここからがBERTを用いたMultilingualなembeddingの話。
今回から Transformerベースの文脈埋め込み、BERT embeddings を提供するようになったとのこと。(BERTは "Bidirectional Encoder Representations from Transformers" の略)

These are embedding models that are trained on large amounts of text using a masked language model style of training.
(これは埋め込みモデルで、大量のテキストをマスク言語モデルで学習させるスタイルです。)This means that the model is given a sentence with one word masked out and asked to suggest the word, for example, “food” in “food for thought,” and trained to do better and better at this.
(つまり、ある単語がマスクされた文章を与えて、例えば「food for thought」の「food」のように、その単語を示唆するようにモデルを学習させ、どんどん上手にできるようにするのです。)
「多言語」であることのポイント
Transformerのアテンションメカニズム(具体的にはmulti-headed self-attentionと呼ばれるもの)により、モデルは、一度に複数の異なる方法で、異なる重みでテキストの異なる部分を考慮することができる。
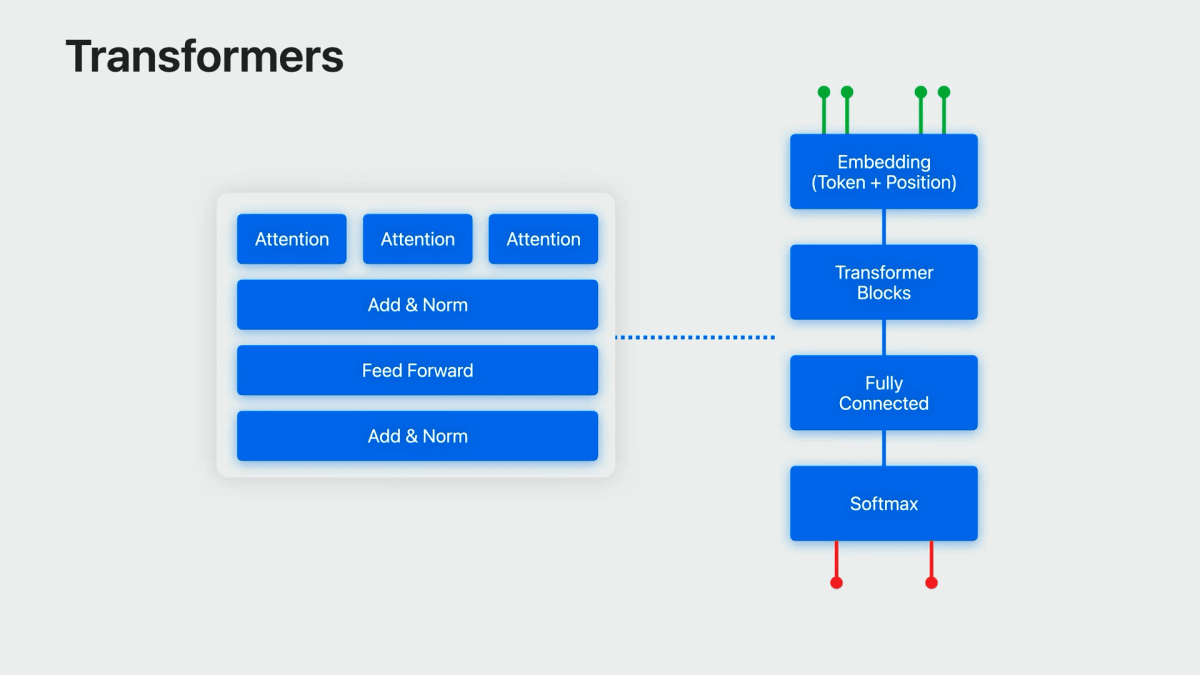
これにより、一度の複数の言語で学習することができる。
Transformers at their heart are based on what’s called an attention mechanism, specifically, multi-headed self-attention, which allows the model to take into account different portions of the text with different weights, in multiple different ways at once.
(トランスフォーマーの根幹は、アテンションメカニズム、具体的にはマルチヘッド自己アテンションと呼ばれるもので、これによってThe multi-headed self-attention mechanism is wrapped up with multiple other layers, then repeated several times, which altogether provides a powerful and flexible model that can take advantage of large amounts of textual data.
(この多頭式自己注意機構は、他の複数のレイヤーで包まれ、何度も繰り返されることで、大量のテキストデータを活用できる強力で柔軟なモデルとなっています。)So much so in fact that it can be trained on multiple languages at once, leading to a multilingual model.
(そのため、一度に複数の言語で学習させることができ、多言語モデルとして利用することができます。)
で、そのミソは「多言語対応」というところではなくて、言語間の類似性から、ある言語のデータが他の言語のデータに役立つという相乗効果にあるらしい。
This has several advantages. (これにはいくつかの利点があります。)
It makes it possible to support many languages immediately and even multiple languages at once. (すぐに多言語に対応でき、さらに一度に多言語に対応できる。)
But even more than that, because of similarities between languages, there's some synergy such that data for one language helps with others. (しかしそれ以上に、言語間の類似性から、ある言語のデータが他の言語のデータに役立つという相乗効果もあります。)
日本語を含む27言語をサポート
以下の27言語をサポートしているとのこと。

これらを3つの言語グループに分けて、3つの別々のモデルで実現しているとのこと。
So we’ve gone immediately to supporting 27 different languages across a wide variety of language families.
(そこで私たちは、さまざまな語族にまたがる27の言語をサポートするために、すぐに着手しました。)This is done with three separate models, one each for groups of languages that share related writing systems.
(これは、関連する文字体系を共有する言語グループに対して、それぞれ1つずつ、3つの別々のモデルで実現しています。)So there's one model for Latin-script languages, one for languages that use Cyrillic, and one for Chinese, Japanese, and Korean.
(ラテン文字系の言語、キリル文字系の言語、そして中国語、日本語、韓国語の3つのモデルです。)
Create MLにおけるサポート
このBert Embeddings は Create ML の新バージョンで入力エンコーディング層として利用可能。
 [Algorithm] で "Transfer Learning BERT Embeddings" を選択できる
[Algorithm] で "Transfer Learning BERT Embeddings" を選択できる
学習データは、すべて単一の言語である必要はない。
NLContextualEmbedding APIs
Natural Languageフレームワークにも、同埋め込みモデルを利用するAPIが追加されている。
もちろんiOSでも利用可能で、何ならwatchOSでも利用可能。iOS 17.0, macOS 14.0, watchOS 10.0, tvOS 17.0以降。
具体的には NLContextualEmbedding という新クラスを使って、必要な埋め込みモデルを取得することができる。

embeddingResult(for:language:) メソッドを用いて埋め込み表現を得られる。
func embeddingResult(
for string: String,
language: NLLanguage?
) throws -> NLContextualEmbeddingResult
返り値の型は NLContextualEmbeddingResult で、ここから埋め込み表現のベクトルが得られる。
PyTorchやTensorFlowで学習したモデルの利用
セッションでは、Create MLで学習したモデルではなく、PyTorchやTensorFlowで学習したモデルに対してこの新しいBERT embeddingを利用する方法についても解説されている。
NLContextualEmbeddingを使って学習データの埋め込みベクトルを取得し、これを入力としてPyTorchやTensorFlowを使ったトレーニングを行えばよい、とのこと。
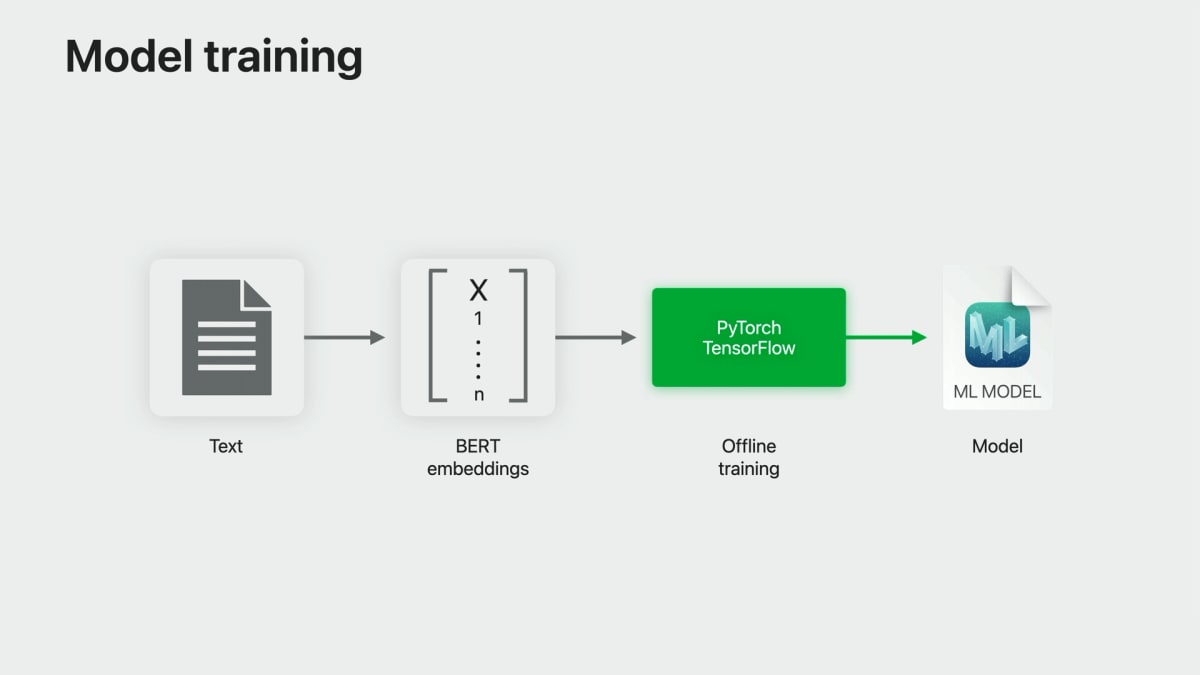
エッジデバイスでの推論時には、NLContextualEmbedding を使って、入力データの埋め込みベクトルを取得し、それをCore MLモデルに渡して出力を得る。

なお、セッション内では事例として、多言語入力に対応したStable Diffusionのデモが示されている。


関連記事・スライド
Stable Diffusion with Core MLについて
NLContextualEmbedding について
Discussion