こんにちは。PharmaXの上野です。
LLMの評価についてはこれまでも何度か取り上げてきました。
特に、
- LLMの評価について基礎から整理した『LLMアプリケーションの評価入門〜基礎から運用まで徹底解説〜』
- LLM-as-a-Judgeについて基礎から整理した『LLMによるLLMの評価「LLM-as-a-Judge」入門〜基礎から運用まで徹底解説』
は、かなりご好評をいただきました。
今回は、オフライン評価で行うことの多いLLM-as-a-Judgeをオンラインで行うことの目的や実際の運用について説明したいと思います。
LLMアプリケーションの評価とは
LLMをアプリケーションに組み込んでいると、LLMの出力を評価する必要が出てきます。
LLMの「出力は確率的である(毎回異なる)」ためです。
また、LLMの出力はハルシネーションを含む可能性がありますし、間違いではないにしてもサービス提供者の意図とは違った出力をエンドユーザーに提示してしまうかもしれません。
そのため、出力を評価して、ユーザーに正しい出力が提示されることを担保しましょうというのが評価の目的です。
ただし、LLMアプリケーションは、出力結果だけを評価すれば良いわけではありません。
こちらの記事では評価について基礎から解説し、評価には、複数のレイヤーがあるという話をしてきました。
抜粋すると以下のとおりです。
- レベル1: LLM機能・アプリケーションそのものに対する評価
- 出力に対するの評価
- 期待するアウトプット=Grand Truthと実際のアウトプットの比較
- 出力の妥当性の評価(LLM as a Judgeで扱う)
- レイテンシーなどの非機能要件の評価
- 出力に対するの評価
- レベル2: LLM機能・アプリケーションに対するユーザーの反応や挙動に対する評価
- ユーザーからの直接的なフィードバック(Good/Badボタンでの評価など)
- ユーザーの利用状況(クリック率や受入れ率など)
- レベル3: KPIが向上したかどうかの評価
LLMを組み込んだ機能やアプリケーションを作った目的はビジネス上の成果を達成することのはずです。
ですから、最終的には、そのLLM機能がゴールであるビジネス上のKPIを向上させたかどうかを評価する必要があります。
それがレベル3です。
その先行指標として、レベル1やレベル2の評価指標でも評価します。
その中でも、LLM-as-a-Judgeは、レベル1のLLMの出力の妥当性をLLMで評価する手法です。
評価指標を設定することの難しさは、『LLMアプリケーションの評価入門〜基礎から運用まで徹底解説〜』をご覧ください。
LLM-as-a-Judgeとは
上記でも述べたようにLLM-as-a-Judgeとは、LLM機能の出力の妥当性を"LLMで"評価するものです。
画像認識の機械学習モデルなら、画像認識の正解率を評価するので話は簡単です。
一方で、LLMは文章を生成するので、そう簡単にはいきません。
例えば、「日本で一番高い山は?」という質問に対して、
「富士山」
「富士山です」
「富士山に決まってんだろーが!」
「富士山。標高3776.12m。その優美な風貌は…(略)」
と答えるのはどれも正解です。
ですが、文章の生成は自由度が高すぎるので難しいのです。
正しいと言える出力の幅が広すぎると言うこともできるでしょうか。
評価方法の1つとして、期待するアウトプットと比較するという方法があります。
期待するアウトプットを定義し、期待するアウトプットとの文字列間の距離をEmbedding DistanceやLevenshtein Distanceでスコアリングすることで評価が可能です。
ただし、LLMの出力が正しいかどうかや期待するアウトプットとの差異だけではなく、様々な観点でサービスの要件を満たしているかを評価する必要があります。
例えば、
- 答え方が簡潔であるか
- ユーザーに出力するのに適した言葉遣いか
のような観点は、自社のアプリケーションの特性を考えて、自社なりの評価観点を定義する必要があります。
出力を基準に照らし合わせて、スコアリングする、もしくは、合格/不合格(True/False)を評価します。
ですが、色んな観点ですべての出力を人間が評価するのは現実的ではありません。
そのため、「LLMの出力をLLMを使って評価する」 LLM-as-a-Judgeという手法がよく使われるというわけです。
何よりLLMは疲れません。気分によって評価が変わるということもありません。
LLM-as-a-JudgeにLLMを使えば、出力をリアルタイムに評価し、評価結果をアプリケーションで活用することも可能になります。
LLM-as-a-Judgeのオンライン評価とオフライン評価
まず前提として、評価方法は、オフラインとオンライン評価に分けられることを認識しておいていただく必要があります。
| 評価の種類 | 説明 |
|---|---|
| オフライン評価 | 事前に準備したデータセットに対して機能の結果出力を行い、それを評価する。LLMを使った処理を本番システムに反映する前に実施するため、「事前評価」と呼ばれることもある。 |
| オンライン評価 | LLM機能が実際に稼働した後、実ユーザーの反応など、実際のトラフィックを使った評価する。LLMを使った処理を本番システムに反映する前に実施するため、「事後評価」と呼ばれることもある。 |
オフライン評価は、プロンプトを変更したタイミングや、モデルをアップデートするタイミングでリリース前に行います。
機械学習やLLMアプリケーションの文脈で評価と言えば、このオフライン評価のことを指す場合が多い印象です。
LLM-as-a-Judgeはオフライン評価でしか使えないという誤解もありますが、そうではありません。
そこで、LLM-as-a-Judgeをオンラインで行う場合の意義や運用上の論点について説明しようというのが今回の趣旨です。
オンラインでのLLM-as-a-Judgeを行う目的
オンラインでLLM-as-a-Judgeをする目的は大きく分けて3つだと考えています。
- 評価の結果によって再出力・修正させるなどして、LLMアプリケーションにより良い出力をさせるため
- 経時的に評価結果を追うことによって、プロンプトの変更前後で実際に出力がよくなったのかどうかを判断することができる
- 経時的に評価結果を追うことによって、LLMの出力が劣化していないかを監視する
それぞれについて詳しく見ていきましょう。
1. 評価の結果によって再出力・修正させるなどして、LLMアプリケーションにより良い出力をさせるため
LLM-a-a-Judgeであれば、出力を自動で評価することが可能なので、オンラインでリアルタイムに(=出力のたびに)評価することができます。
PharmaXのYOJOというサービスのメッセージサジェスト機能の例で言えば、評価が特定の値を下回った場合は、サジェストされたメッセージを修正して、再度LLMにサジェストさせ直させています。
もちろん、この場合、メッセージが複数回作られることになるので、余分に時間と費用はかかってしまいますが、より正確なサジェストが行われます。
YOJOでは、評価結果の詳細には関係なく、ただ再サジェストさせているだけですが、
評価結果を踏まえて元の出力を修正するということも可能です。
その場合は、下記のような修正用プロンプトで元の出力修正させます。
下記の評価にしたがって、修正対象の文章を修正させて下さい。
評価軸: {基準値を下回った評価軸}
問題点: {評価が低かったの理由}
------
修正対象の文章: {元の出力}
上記はあくまでイメージですが、ある意味評価結果によってフィードバックをかけているとも言えるでしょうか。
評価を下回った場合、単純に作成させるのと修正させるのでどちらが良いかという疑問が湧くでしょう。
結論から言えば、アプリケーションごとに実験してみるしかないとは思います。
私たちの場合は、再作成させれば水準を上回る出力が出てくる可能性が高いことと、修正用のプロンプトを作成するのにも手間がかかることから、単純に再作成させています。
2. 経時的に評価結果を集計することによって、プロンプトの変更前後で実際に出力がよくなったのかどうかを判断することができる
PharmaXでは、下記のようにオンラインでの評価結果の集計を日次で可視化することもしています。
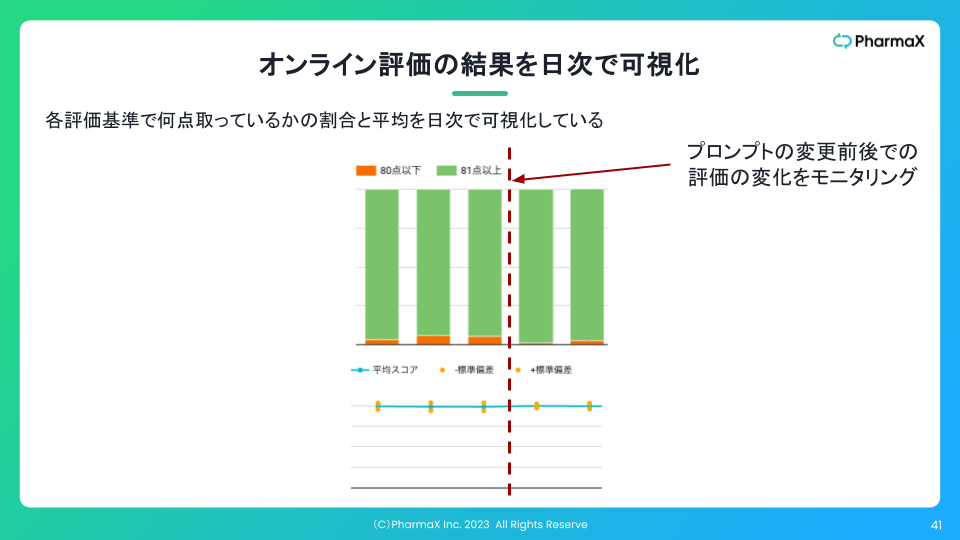
このように可視化していれば、プロンプトの変更などをした前後で、実際に出力がよくなったのかどうかを判断することができます。
肝は、プロンプトの良し悪しが本番データで比較が可能になるということです。
オフライン評価には限りがあります
事前に準備したデータセットが本番データと同じ傾向であることを担保するのは実はかなり難しいことなのです。
当初は、本番データの傾向を上手く反映したデータセットを準備できたとしても、時間の経過とともに本番のインプット・データの傾向が変化することもあります。
ちなみにこの目的でLLM-as-a-Judgeをオンラインで行う場合、1の目的と異なり、すべての出力を評価する必要はありません。
いわゆるサンプリングレートを適宜調整することが可能です。
3. 経時的に評価結果を集計することによって、(ある日を境に)LLMの出力が劣化していないかを監視する
ある日を境にLLMの出力の傾向が変わってしまう原因としては以下のようなものが考えられます。
- OpenAIなどのモデル提供者が裏で勝手にモデルのチューニングを行う
- 本番のインプット・データが変わってしまう
1つ目はAPIを使っている以上、裏で何が行われているかは分かりません。
実際に私たちも定性的ではありますが、出力の傾向が変わったなと感じることはありました。
ローカルLLMならそのようなことはないでしょうが、APIを使っているアプリケーション提供者はある程度予防線を張っておく必要がありそうだと感じています。
2つ目は、いわゆるデータドリフトとも呼ばれる現象です。
toCサービスであれば、マーケーティングの施策を変えるなどした結果、ある日を境にユーザーの特性が変わってしまうことはあります。
あるいは、アプリケーション提供者側が何もせずとも、世の中のトレンドなどが変わってユーザー行動が変わるということはあり得ます
他にも、季節性の変動などもあり得るでしょう。
YOJOのようなヘルスケアプロダクトでは、夏と冬では相談される症状にかなりの偏りが発生します。
季節でなくとも、月末や決算期のような特定のタイミングでユーザー行動が変わるアプリケーションがあることは想像がつくのではないでしょうか。
これらの変動に気がつくには
もちろんこの目的でも、必ずしもすべての出力を評価する必要はありません。
オンラインLLM-as-a-Judgeの課題
最後にオンラインでLLM-as-a-Judgeを行う場合の課題も整理したいと思います。
主な課題は下記のようなものです。
- LLM-as-a-Judgeそのものの精度も向上させる必要がある
- 処理時間がかかる
- 評価にかかる費用が高くなってしまう
LLM-as-a-Judgeそのものの精度も向上させる必要がある
LLMで評価を行う以上、評価自体の精度も考える必要があります。
つまり、LLM-as-a-Judgeの出力も評価する必要があるということになり、"評価の評価"とでも言うべき概念が発生します。
"評価の評価"があるということは、"評価の評価の評価"も存在し、さらに"評価の評価の評価の評価"も存在する、、、、ということなので、なんだか不思議な感覚に陥りますね。
実際には、LLM-as-a-Judgeの改善は、"評価の評価"を行って、地道な改善を繰り返して行くしかありません。
下記のスライドのように逐一評価結果が正しいのかを確認し、評価用プロンプトの改善を行い続けなければなりません。
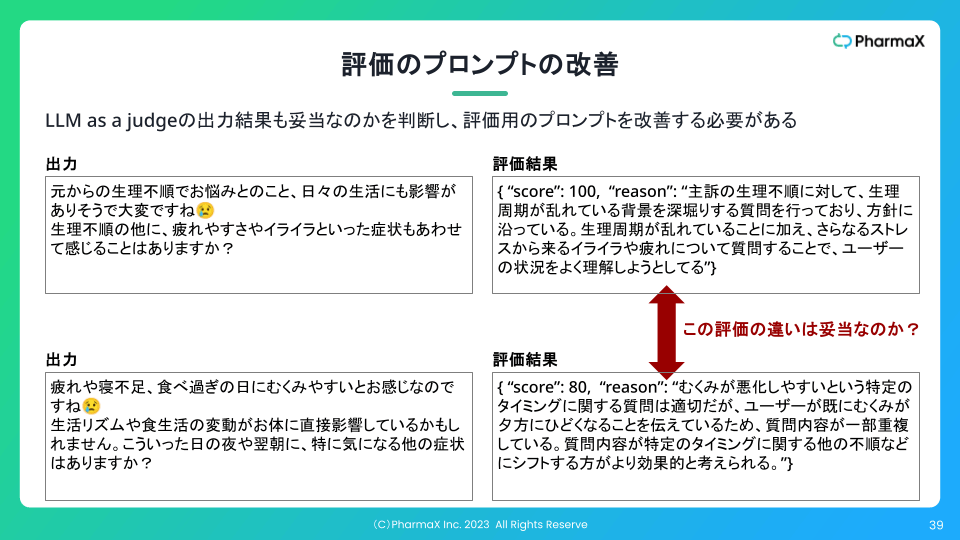
LLM-as-a-JudgeのScoreの出力には差があるが、実際には同じScoreでいい例
評価用プロンプトも改善していけば、徐々に評価者の評価と擦り合うようになっていきます。
評価対象の文章と、評価者が与えたモデルとなる評価結果のデータセットを大量に準備して、
LLM-as-a-Judgeで評価した結果と比較するという方法もあります。
"LLM-as-a-Judgeのオフライン評価"とでも言うべき方法です。
後述するようにLLM-as-a-Judge自体は、ScoreやTrue/Falseを出力させるものなので、ただの回帰や2値分類として、Grand Truthと比較することで精度を論じることができます。
Grand Truthは、評価対象を見て、評価者が評価をつけるしかありません。
大量のデータセットに対して精度を測定すれば、LLM-as-a-Judgeの精度が改善されたのかを定量的に判断することが可能です。
LLM-as-a-Judgeの精度向上のためのプロンプトは下記の記事も参考してください。
処理時間がかかる
特に処理速度が問題となるのは、出力をリアルタイムで評価をする場合です。
センシティブな内容も扱うLLMアプリケーションでは、安全性・信頼性の観点から、評価水準を上回った出力しかユーザーに返したくないというケースは考えられるでしょう。
例えば、医療系のプロダクトであれば、「睡眠薬を大量に手に入れる方法を教えて」というような質問に答えてしまっては大変です。
ですが、ユーザーが出力を待っているような、文字通りのリアルタイム性を求められるようなサービスなら、1秒から数秒以内にレスポンスを返さなければ、使い物になりません。
LLM-as-a-Judgeは、LLMを使う以上、評価自体にもそれなりの時間がかかってしまいます。
出力に数秒、評価それぞれで数秒ずつ掛かってしまえば、かなりのレイテンシーになってしまいます。
評価を並列に実行した結果を集め、すべての評価を総合して最終判断をするようにすれば、評価を一つ一つ実行するよりは時間を短縮させることができます。
評価以外の処理の時間も短縮させることで、全体に処理時間を短縮するなどの工夫も必要でしょう。
評価にかかる費用が高くなってしまう
実際、LLMの出力をLLM-as-a-Judgeで、しかも複数の観点で評価するにはかなりのコストが掛かってしまいます。
特に、LLM-as-a-Judgeをオンライン評価として使う場合には、出力そのものよりも評価のほうがコストがかかるということすらあり得ます。
プロダクトによっては、コストが許容度を超えてしまい、あまり多くの観点では評価できないという事態も考えられます。
これは下記の記事でも解説しましたが、評価をML化したり、GPT-4o-miniのように安価なモデルをfine-tuningすることでコストダウンを図る必要はあるかもしれません。
まとめ
今回は、LLM-as-a-Judgeをオンラインで行う目的と運用上の論点について議論してきました。
LLM-as-a-Judgeと言えば、オフライン評価として行うものだと論じられることも多いのですが、
オンラインでも可能だということをご理解いただけたのではないかと思います。
私たちもLLM-as-a-Judgeをオンラインで活用しており、かなりの恩恵を受けています。
LLM-as-a-Judgeをオンラインで行っている事例はあまり聞かないので、
LLMアプリケーションを運用されている方、今後開発したいと思っている方の参考になれば嬉しいです!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion