データエンジニアリング関連のおすすめ書籍(随時更新)
はじめに
昨今、「データの価値」に注目が集まり、「データを制するものがビジネスを制す」というようなバズワードもみられるようになりました。
私が所属するSIerでもデータ基盤やデータ分析系の案件が増えてきており、今後より大規模で複雑なデータを扱うようなプロジェクトが増えてくると予想されます。
以前よりデータ基盤系のプロジェクトにかかわることが多かったのですが、前述の状況もあり、改めてデータエンジニアリングについてインプットを行いました。
今回は、データエンジニアリングを学ぶにあたって役立った書籍を紹介したいと思います。
※読んだ本、追加でおすすめの本があれば更新します。
おすすめ書籍
データエンジニアリングの基礎 ―データプロジェクトで失敗しないために
その名の通り、データエンジニアリングに関する必須知識が体系的にまとまっている書籍です。
データアーキテクチャ、パイプライン、データモデリングそしてビジネスとの関わりについて一通り記載されています。
非常に学びのある書籍なのですが、基礎という割には初学者には難しい内容があるので、ある程度の知識があった方がより理解が深まると思います。
とはいえデータエンジニアリング分野での良書となるので、データエンジニアリングのプロジェクトに参入するにあたっては読んでいて損はないものだと思います。
データ指向アプリケーションデザイン ―信頼性、拡張性、保守性の高い分散システム設計の原理
ソフトウェアエンジニアリングの分野でもよく名前の挙がる書籍ですね。
「データ」に関して様々な技術や仕組みが包括的に説明されており、データに関する技術は一通り解説されているのではと思うくらいの網羅性のある書籍です。
データ処理システムの設計原則、パターン、アーキテクチャ等様々な観点でまとめられており、データに関するアプリケーションやシステムを構築するにあたっては必読と言っても過言ではないと思います。
難点としては600ページを超えるボリュームと章によっては参考文献が100を超えてくるので完全に理解しようとするとかなりの時間がかかると思います。
何度も読んで理解を深めたり、実務で触れた技術を深堀する際に利用するのがいいと思います。
ちなみに来年第2版が出るらしいので楽しみですね
大規模データ管理 第2版 ―データ管理と活用のためのモダンなデータアーキテクチャパターン
「データの価値」に着目し、方法論、アーキテクチャやベストプラクティスがAzureでの実例を交えて解説されている書籍です。
特にエンタープライズアーキテクチャのベストプラクティスについて詳細に解説されており、実際のプロジェクトでも課題となるドメイン間でのデータ管理やマスタ管理等についても解説されています。
この書籍を通してデータドメインやエンタープライズアーキテクチャのあるべき姿が理解できるので企業全体のデータ基盤を構築する際に参考になると思います。
あるべき姿として企業内にデータエンジニアやソフトウェアエンジニア、データスチュワードを置くということが述べられているので、SIerとして構築する場合はそのあたり含めたビジネス面や体制をどうするか別観点での検討が必要になると思います。
また、マスタ管理のひとつをとっても実際には様々なベンダにより作成されたシステムが存在したり、システムにより環境が異なる事も多く、マスタ周りの統制に関して様々な検討事項や課題があって、統一管理ができるか、データの伝播が可能か、ガバナンスをどうするか等企業全体のシステムを横断して検討が必要となるので難しい部分が多いと思います。
同様にデータメッシュも難しい部分が多いと考えています。
データメッシュはデータ管理を中央集権型から各ドメインへ分散させ、ドメインチームがデータプロダクトを所有し運用するアプローチとなります。
そのためドメイン駆動設計を前提としたシステムおよび組織が必要となります。
つまり、しっかりと取り組むには組織作りから始める必要があり一筋縄ではいかない事も多いと思います。
ちなみに同じ著者でメダリオンアーキテクチャについての書籍が出るらしいです。
Azure DatabricksとMicrosoft Fabricについても記載があるみたいで楽しみですね。
Apache Spark徹底入門
ビッグデータの処理に使われることの多いApache Sparkの概要からベストプラクティス、パフォーマンス改善まで一通り解説された書籍となります。最適化方法等実際の業務での活用も役立つと思います。
Python(PySpark)とScalaのサンプルコードも記載されており、実際に手を動かしながら学ぶことができます。
前提としてはPythonもしくはScalaである程度のコーディングができることが必要となりますが、構文的には難しくないので環境さえ整えれば問題ないと思います。(環境的にはDatabricksの無料プランを使うのが手っ取り早いかと)
ちなみにApache SparkにおいてPython(PySpark)とScalaのどちらを使うかは論点になることが多いですが、よほど大規模や複雑なデータではなければPySparkを選んだ方が学習コストやライブラリ的な意味で良いのかなと思います。
ちなみにわたしはScalaを使うことが多いです。
クラウドデータレイク ―無限の可能性があるデータを無駄なく活かすアーキテクチャ設計ガイド
クラウド上でデータレイクを扱う際のベストプラクティスについて記載されている書籍。
クラウドデータウェアハウス、モダンデータウェアハウス、データレイクハウス、データメッシュのアーキテクチャの紹介や、Apache Sparkのパフォーマンス、OTFの詳細や使いどころがまとめられています。
さっくり読める内容かつ網羅的にまとめられているので、現時点で知識がなくてもデータレイクについてのイメージをつかむことができます。
逆にある程度知識がある方にとっては少し物足りないかもしれませんが、7章のアーキテクチャに関する意思決定のフレームワークはデータ基盤を構築するにあたり非常に参考になる内容だと思います。
現状評価から定義/設計、実装、リリース(運用)までの各ステップで判断に必要な要素が解説されています。一般的な要素も多いですが、経験を積んだアーキテクトが読んだとしても新たな観点が見つかるのかなと思います。
データレイクを導入するか判断するうえでの指針にもなると思うので、データエンジニアに限らず、データアーキテクトそしてビジネスユーザにもおすすめできるものだと思います。
Deciphering Data Architectures: Choosing Between a Modern Data Warehouse, Data Fabric, Data Lakehouse, and Data Mesh
データアーキテクチャについて包括的に解説しており、基礎的な概念から始まり、従来型のリレーショナルデータウェアハウス(RDW)やモダンデータウェアハウス、さらに最近注目されているデータファブリック、データレイクハウス、データメッシュなどのアーキテクチャを網羅しています。
それぞれのアーキテクチャの特徴や課題、その課題への具体的なアプローチや導入方法について解説されており、非常に参考になる書籍だと思います。
特に印象に残ったのは、データメッシュに関する章です。
データメッシュはその利点が注目されがちですが、この本では課題や重要な論点についても深掘りしており、それらにどう対応すべきかを明確に解説しています。この章だけでも読む価値があると感じました。
欠点を挙げるとすれば、この本はアーキテクチャの説明に焦点を当てているため、実装の技術的な詳細には踏み込んでいない点だと思いますが、他のリソースで補える範囲なので問題ないと思います。
また、Amazon等で購入するには少し高いのでオライリーのサブスクで読んだ方がいいかもしれません。
データアーキテクチャに興味がある方にはおすすめです!
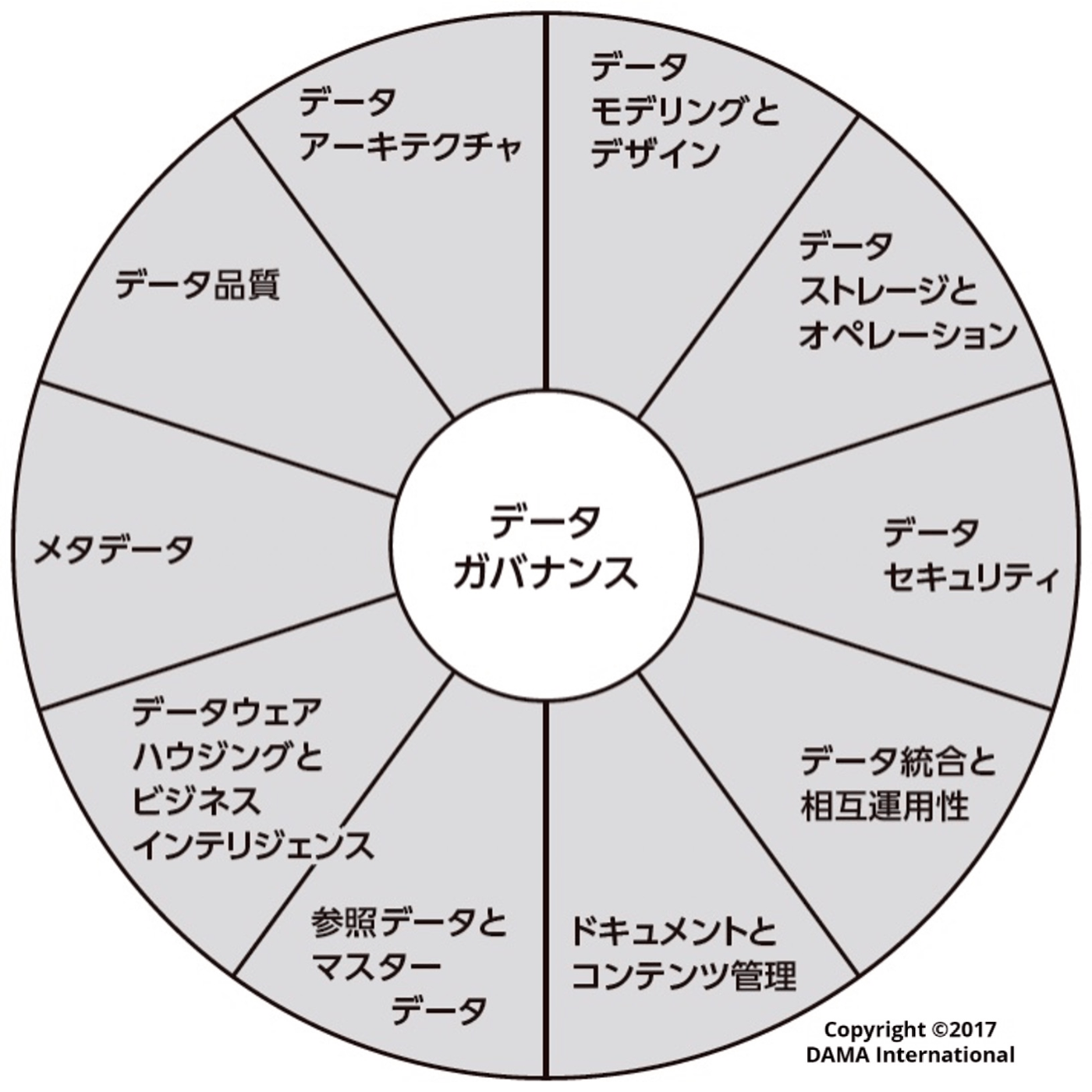
データマネジメント知識体系ガイド
これまで紹介した各書籍でも引用されるDMBOKの知識ガイドとなります。(プロジェクトマネジメントにおけるPMBOKみたいなものです。)
The DAMA Wheelが有名ですね。
「データは企業にとって重要な資産である」という前提に立ち、さまざまな観点からデータをどのようにマネジメントすべきかを体系的に解説している一冊です。
データを適切に管理し、資産として最大限に活用するためには、技術的なアプローチだけでは不十分であり、組織構造や業務プロセス、文化そのものの変革も必要で、データマネジメントを組織に定着させ、成熟させることは一時的に痛みを伴うこともあります。
いかに企業において最適なデータマネジメントを実現するか。そこに正解はなく、各組織が抱える課題や環境に応じて最適解を模索していく必要があります。
だからこそ、DMBOKのような知識体系は、方向性を見失わないためのベースラインとして有効だと思います!
ソフトウェアアーキテクチャの基礎 ―エンジニアリングに基づく体系的アプローチ
こちらは直接データエンジニアリングとは関係ありませんが、データエンジニアリングにおいてソフトウェアエンジニアリングの知識は基礎として必須となります。(こちらは後程解説します。)
この書籍はアーキテクチャを考えるための思考から、代表的なアーキテクチャスタイルの紹介やアーキテクトとしてのソフトスキル(対人スキルやチーム運営、キャリアパス等)まで網羅的にまとめられているものとなります。
「データエンジニアリングの基礎」にて近い将来、データエンジニア、アナリスト、ソフトウェアエンジニア、データサイエンティストの境界は限りなく低いものとなると述べられています。
私自身、本職はバックエンドエンジニアとなり、そこからデータエンジニアリングにかかわるようになっています。
そういった将来的な部分を踏まえて職種の範囲にかかわらず本書籍でアーキテクチャを学ぶことは今後のキャリアで有用だと思います。
詳細はこちらの記事でまとめています。
AWSではじめる実践データマネジメント
DMBOKの基本的な考え方を踏まえ、AWSのサービスを活用しどのようにデータマネジメントを実現するかを解説した書籍となります。
データマネジメントを推進・運用するうえでよくある課題とその解決方法が提示されています。
特に印象的だったのはAmazon DataZoneについて言及されていた点です。
このサービスはデータメッシュを実現するうえで重要なものですが、詳細に扱った書籍は他にほとんどないのでこのサービスを扱う際には参考になると思います。
DataZoneの機能についてはガバナンス統制をはじめ、データポータルの役割やデータメッシュとの親和性についても解説されているので個人的にも非常に勉強になりました。
このAmazon DataZoneは次世代SageMakerのUnified Studioでも活用できるようになっており、今後のAWSにおけるデータマネジメントの主要サービスの一つに位置づけられている印象です。
もちろん、実際にDMBOKに沿ったデータマネジメントを行うには様々な考慮が必要で、本書籍の内容以外にも検討すべきことは多いです。
それを踏まえたとしても、実践的で学びの多い内容で、非常に有用な一冊だと思います!
データプラットフォーム技術バイブル
要素技術の解説から要件分析、改善のアプローチまで、データ基盤に関する多くのトピックが網羅されている一冊です。
様々な技術を扱いながらも、それぞれの「キモ」となる部分はしっかりと押さえられており非常に参考になりました。
現在のデータ基盤では、さまざまな技術やサービスを組み合わせて構築することが一般的であり、こうした網羅的に技術を解説している書籍は、実践時のヒントとして大いに役立つと思います。
全体を通して特定の技術に偏ることなく、全体像を俯瞰できる構成になっており、初心者から経験者まで幅広く参考になる内容だと思います。
データエンジニアリングの基礎と比較されることも多い本書籍ですが、データエンジニアリングの基礎は概念的な記載が多く、こちらの方がより技術にフォーカスしている印象です。
どちらが優れているということもなく、どちらも素晴らしい内容だと思います!
実践Apache Iceberg
Apache Icebergの仕組みや機能、各クエリエンジンでの利用方法、ユースケース、運用、さらに移行戦略まで幅広く網羅的に解説した書籍。
ハンズオンも豊富でApache Icebergを体系的かつ実践的に学ぶための書籍としては現時点で最良な選択肢だと思います。
後述のApache Iceberg: The Definitive Guideより新しいこともあり、こちらの方がいいかもしれません。(日本語で手に入りやすいのもありますしね)
個人的に良かったのはPyIcebergが紹介されていた点です。
ページ数の都合上、概要にとどまってはいるものの、全体像をつかむには十分で、実際に触る際には非常に役立つ内容だと感じました。
また、移行戦略についてはAWS Summitでも紹介されていましたが、本書を通して理解が深まり、大きな学びとなりました。
今後、従来のデータレイクや他のOTFからの移行も増えることが予想されます。こういった移行の戦略や手法に触れられた書籍はなかなか無いと思うので、実務でも参考になりそうです。
前述したとおり、Apache Icebergを理解する上で最適な書籍であり、今後も何度も読み返すことになると思います。
データ基盤に関わるすべての方におすすめできる一冊です!
Apache Iceberg: The Definitive Guide
Apache Icebergの概念やアーキテクチャから、メタデータのバージョン管理、ブランチ管理等の運用ポイントやベストプラクティスまで詳細に解説された一冊。
Open Table Format(OTF)の分野では、Apache Icebergが他と比べて大きくリードしており、AWSなどのクラウドサービスや、DatabricksやSnowflakeなどのデータプラットフォームにも採用され、注目を集めています。
内部の作りからどう運用すべきかまでまとめられているので、Icebergについて学ぶにはベストな一冊だと思います!
Delta Lake: The Definitive Guide
Open Table Format(OTF)の一つであるDelta Lakeを扱った書籍です。
Databricksに採用されていることで有名ですね。
概念やアーキテクチャから運用まで詳細に解説された一冊となっており、パフォーマンスチューニングの章は実際にレイクハウスを運用する上で非常に参考になると思います。
従来、パフォーマンスチューニングには多くの要素を考慮して設計を行う必要がありましたが、最近のアップデートでPredictive OptimizationやAutomatic Liquid Clusteringが利用可能になり、運用負荷が大きく軽減されました。
とはいえ、なぜそういった機能が必要になるのかについては理解する必要があります。
そういったポイント含めて多くの学びがありますのでDelta Lakeを扱う上で読んでおいて損はないと思います!
Apache Hudi: The Definitive Guide
Open Table Formatの一つであるApache Hudiについて概要や特徴、レイクハウスの構築方法まで詳細に解説した書籍です。
これまでIcebergやDelta Lakeを扱う事が多く、Hudiはあまり触れる機会がありませんでしたが、本書籍を通して理解が深まりました。
先に触れた「Apache Iceberg: The Definitive Guide」と「Delta Lake: The Definitive Guide」と比較して読むとその特性や強みが理解できると思います。
Upsertやインクリメンタル処理、リアルタイム性など、他OTFとは異なる強みがハマる要件であればHudiは有力な選択肢だと思います。
とはいえ、IcebergやDelta Lake、特にIcebergのエコシステムや汎用性を踏まえると、今後も第一候補としては Icebergを選ぶ場面が多いのかなと個人的に思います。
現在のOTFの主流であるIceberg、Delta Lake、そしてHudiの特徴やメリデメを理解したうえで、最適なレイクハウスのアーキテクチャを選ぶことが重要だと思います。
本書はそのためのガイドとして十分に有用で、この分野に関わる方は読んでおいて損はない一冊だと思います。
ちなみに、Apache IcebergやDelta Lake、そしてApache Hudiなどそれぞれの強みを活かして複数のレイクハウスを活用し、それをApache XTableで統合管理するアプローチも要件次第ではありなのかなと思います。
Icebergは大規模分析に強く、Delta LakeはSparkとの統合やトランザクション管理に優れ、Hudiはリアルタイム更新やアップサート処理に強いのでそれらを活かすことでより複雑な要件に対応できると思います。
とはいえ、シンプルさや運用効率も重要なので1つのフォーマットに寄せる方が無難な気もします。
Data Engineering Design Patterns
データパイプライン構築における設計パターンが詳細な解説やサンプルコード、トレードオフの考察とともに体系的にまとめられており、非常に実践的な一冊です。
初見のパターンから多くの学びがあったのはもちろん、既知のパターンについても、自分がこれまで意識できていなかった観点や設計意図に気づかされ、理解が深まりました。
巻末にもある通り、データエンジニアリング分野の技術進化は著しいですが、「品質を確保しつつ、鮮度の高いデータをいかに効率よく扱う」という本質的な部分は変わりません。
その本質を見失わずに設計・運用するための指針として、本書は非常に有用なリファレンスになると思います!
Building Medallion Architectures
Medallion Architectureに関する書籍の中では、現時点で最も体系的かつ詳細にまとめられている一冊です。
Microsoft Fabricをベースに解説されていますが、概念は他のクラウドサービスにも応用可能で、非常に多くの学びが得られると思います。
また、課題となりがちなガバナンスやセキュリティへの対応に加え、将来的な拡張としてData MeshやAIとの統合に関する展望にも触れられており、実際にデータ基盤を構築・運用していくうえで大きな参考になる内容です。
Cost-Effective Data Pipelines
クラウドのコストに関する書籍が多い中でもデータパイプラインに特化している点が特徴的な一冊です。
パイプラインの構築、テスト、監視といった観点でのコスト最適化について、著者の経験に基づき詳細に解説されており非常に勉強になりました。
また、潜在的なリスクを理解し、予防戦略をどのように行うか、予測できなかった変化をどのように捉え、対処するかについて新たな視点を得ることがで切ると思います。
データの流れ全体を意識したコスト削減のアプローチは実務に直結する内容で、データエンジニアリングに取り組む上で一読の価値があると思います!
DuckDB: Up and Running
わたしもよく使うDuckDBについての入門書です。
サンプルコードが豊富で、基本的な使い方はもちろん、様々なファイル形式への対応や外部ソースとの連携方法についても具体的な例を交えて解説されています。
初めてDuckDBに触れる場合でも、スムーズに理解する事ができる優れた入門書だと思います!
Data Pipelines Pocket Reference
データパイプラインの概要や具体例がコンパクトにまとまっており、非常に読みやすい一冊です。
短いながらも各フェーズでの重要な要素が抑えられており、サンプルコードも豊富なので、初学者にはおすすめです。
Practical Lakehouse Architecture
Lakehouseの概要やアーキテクチャのポイント、そして「現実的な」アプローチまであらゆる側面が詳細に解説されている書籍です。
Lakehouseを導入するにあたり読んで損はない内容だと思います。
前述した「Deciphering Data Architectures」と組み合わせて読むと、従来のDWHから発展させるアプローチも理解できて良いと思います。
Implementing Data Mesh
技術的なアプローチについては非常に網羅的で、Data Meshの基本原則をどのように実現するかについて多くの示唆が得られる一冊です。
特にData Contactsについて全体を通してその概念や重要性について強調されており非常に理解が進みました。
一方で、組織的および文化的な課題についてはあまり深掘りされておらず、特に大規模な組織での導入において課題となる部分については、別途検討が必要だと思います。
同様に、技術的な側面についても、具体的にどのような技術スタックやプロセスで実現するかについても別途検討する必要があります。
「Deciphering Data Architectures」でも述べられていたように、真のData Meshを実現するには技術的にも、組織や文化的にもまだ難しい部分が多いのかもしれません。
とはいえ、非常に強力なデータアーキテクチャの一つであることは確かなので、読んでおいて損はない一冊だと思います!
The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling
データウェアハウスやデータモデリングにおける書籍のなかで最も有名なものとなります。
ディメンショナルモデリングの思想から詳細な設計手法まで様々な業界・業務の具体例を交えて実践的に解説した書籍
データモデリングに関しては、実務でも悩む場面が多く、その良し悪しによりデータ基盤の品質や性能が決まる重要なポイントとなります。
これまでデータモデリングについて体系的に学ぶ機会がありませんでしたが、本書を通してデータモデリングについて深い学びと新たな気づきが得られました
内容としてはデータモデリングにおける設計上の判断基準や粒度の決め方など、現場で直面しやすい課題に対する具体的な対応方法に示されており、単なる理論書に終わらない「設計のリファレンス」としての価値が非常に高いと思います。
ビッグデータやクラウドが当たり前になった現在でも、根本的なデータモデリングの考え方は変わらないと考えています。
本書で示されるディメンショナルモデルをベースに、データの性質や要件に応じて大福帳モデルやData Vault 2.0などを適用するアプローチが有効だと改めて感じました。
本書籍は新規にデータ基盤を設計する場面だけでなく、既存システムの再設計や運用改善など様々な場面で活用できると思います。
データエンジニア、アナリスト、データアーキテクトだけでなく、ビジネス側などデータに関わるすべての人におすすめできる書籍です!
Fundamentals of Metadata Management
ひとつのITランドスケープを構成する要素でありながらサイロ化してしまうことの多い、メタデータリポジトリをいかに連携させるかについて解説された書籍です。
焦点は方法論であり技術的な解を提示するものではない点に注意が必要となります。
印象的だったのはデータディスカバリチームという考え方です。
これは企業内に散在するメタデータリポジトリを発見・記録・統合し、サイロ化を解消する役割を担うもので、最終的にはメタグリッドと呼ばれる体系的かつ自動化された仕組みの構築を目指すとされています。
このメタグリッドはメタデータを管理するためのアーキテクチャであり、新しい仕組みを導入するのではなく、既存のメタデータリポジトリを前提にそれらを横断的に統合・調和させるアプローチが特徴的なものです。
本書を通してこの概念については深く理解できるとともに、非常に学びとなりました。
とはいえ、日本の企業文化や組織体系ではなかなか難しいなと思う部分もあり、もしこれが実現できればデータの利活用やガバナンス統制、データマネジメントが一つ上の水準に到達できるのではないかという印象を受けました。
全体を通して感じたのは、メタデータマネジメントは単なる技術やツールの話ではなく、組織の文化や役割分担に深く関わるテーマだということです。
実務で応用するには、データカタログやETLなどの技術施策に加えて、こうした組織的な取り組みが欠かせないと改めて認識しました。
エンジニアリングに特化した書籍ではないので万人におすすめできるものではないと思ますが、メタデータ管理のヒントを得られる良い書籍だと思います!
Data Governance with Unity Catalog on Databricks
データとAIを高度なガバナンスで管理するための、Unity Catalogの思想とユースケースを体系的に解説した書籍です。
実践的かつ今後のデータ基盤設計にも参考になる内容で多くの学びが得られました。
さまざまなカタログがある中で、どれを採用するかはデータマネジメントの成否を左右する大きな分岐点となります。
Unity CatalogはOSS化されたとはいえ、依然としてDatabricksとの結びつきが強く、完全なベンダーロックフリーとは言い難い状況です。そして、他の候補であるOpenMetadataやDataHubも運用負荷など様々な考慮が必要となります。
現時点では、各クラウドプラットフォームやデータプラットフォームに備え付けのカタログをベースに検討するのが無難だと思います。
とはいえ、本書籍はUnity Catalogを通じたデータとAIの統合ガバナンスの考え方を体系的に解説しており、読んで損はない一冊だと思います。
特にタイトルにあるようにDatabricksでは必須の知識となるので、Databricksを扱う際には読んでおくと良いのかなと。
Apache Polaris: The Definitive Guide
Apache Iceberg向けに設計されたオープンソースカタログであるApache Polarisについて、その特徴や機能、使い方まで解説された書籍です。
強みであるセキュリティ、ガバナンス、観測性、そして外部カタログなどについて理解が深まりました。
Apache Polarisの特筆すべきはNessie、Gravitino、AWS Glueなどの外部カタログとの相互運用性にあると思います。
現代のデータ基盤においては様々なプラットフォームやサービスを組み合わせることも多いですが、この相互運用性により、各カタログの強みを活かしながら、一貫性のあるガバナンスやセキュリティを担保することが可能となります。
まだまだ発展途上ではあるものの、今後、レイクハウスアーキテクチャがオープンで相互運用可能な方向へ進化する中で、このApache Polarisのような、様々なカタログと相互運用可能なカタログがその中核になると考えられます。
今後、AWS Glue Catalogなど既存のメタデータ管理との共存や、柔軟性と運用のシンプルさを両立するマネージドサービスとしての展開などどう進化していくのか引き続き注視していきたいと思います。
Apache Polarisの特徴だけではなく、オープンなカタログの在り方についても考えさせられる、おすすめの書籍です。
データエンジニアとして成長するために
「データエンジニアリングの基礎」にてデータエンジニアリングには底流となるセキュリティ、データマネジメント、DataOps、データアーキテクチャ、オーケストレーション、ソフトウェアエンジニアリングの底流技術の深い理解が重要と解説されています。
「大規模データ管理」や「ソフトウェアアーキテクチャの基礎」でも同様に「データ」以外の上記の部分の理解が必要と記載されています。
今はこれにプラスしてModern Data StackやLive Data Stackと呼ばれるようなクラウドと機械学習の知識も必要となり、継続的に最新の技術を学ぶことが必要となります。

また、技術面はもちろんですが、データアーキテクトとして必要なスキルに下記のようなものが求められます。
- 事業ドメインの知識
- ファシリテーションやリーダーシップ等卓越した対人スキル
- 社内政治スキル
最適なデータ基盤を構築するためにはビジネスを理解し、ビジネス価値をいかに高めるか、そのためにどういったデータが必要かをデータを活用するビジネスユーザと密に連携してプロジェクトを推進していく必要があります。
技術面、ビジネス面、そしてコンセプチュアルスキルをバランスよく磨くことがデータエンジニア、データアーキテクトとしての成長につながります。
おわりに
データエンジニアリングの概念自体は昔からありましたが、近年データがより大規模になったり、リアルタイムデータが必要になり、データを取り巻く環境や技術が急速に進歩しました。
ビジネス価値を高めるために最適なデータを収集する環境を構築するためには、データエンジニア、データアーキテクトは常に最新の技術をキャッチアップする必要があります。
様々な技術には要素技術と呼ばれる基礎的な技術が存在します。
そういった基礎をしっかり身につけることが最新の技術を理解するうえで大きなアドバンテージとなります。
今回紹介した書籍には基礎的な技術が記載されているものも多く、今後データエンジニアリングを推進する上で多くの学びがあると思いますのでぜひ参考にしていただければと思います。
また、今回紹介したもの以外におすすめの書籍やコンテンツがあればコメントいただけると幸いです。
データエンジニアリング関連の記事もいくつか書いているので読んでいただけるとうれしいです!
Discussion