AWSで実現するメダリオンアーキテクチャとSparkを活用した効率的なデータ変換
はじめに
近年、「データ」の価値に注目が集まり、データ基盤をより効率的かつスケーラブルに実現することが不可欠となっています。
そういった中で「メダリオンアーキテクチャ」とよばれるレイクハウスのデータをよりシンプルかつ論理的に整理するデータアーキテクチャが注目されています。
この記事では「メダリオンアーキテクチャ」の概要とAWSでの構成例について紹介したいと思います。
メダリオンアーキテクチャとは

メダリオンアーキテクチャとはデータを論理的に整理するためのデータアーキテクチャで、データのレイヤー(ブロンズ⇒シルバー⇒ゴールド)を遷移するごとにデータの構造と品質を洗練・向上させることを目的にしています。
データが順次処理されることからマルチホップアーキテクチャとも呼ばれています。
オリンピックのメダルのように銅⇒銀⇒金の順に品質や価値が向上していくようなイメージですね。
ゴールドレイヤーまで来るとビジネス価値により直結したものになります。
メダリオンアーキテクチャの3つの層の役割
前述したようにメダリオンアーキテクチャでは3つの層が存在し、それぞれのレイヤーでデータを品質に応じて階層化し保存します。
-
ブロンズ層:様々なデータソースから取り込んだデータそのもの(生のデータ)が保存されるレイヤーとなります。データとしてはノイズが含まれており、データの欠損がある場合があります。
ここで重要なのがデータの完全性を維持するということです。生のデータを加工せずに保存しておくことがなにより重要となります。
ちなみに完全性が維持されたデータになるので監査にも対応できるデータとなります。 - シルバー層:ブロンズ層に保存された生のデータに対してクレンジングやフィルタリングを行い、分析に対応できる形式で保存するレイヤーとなります。このレイヤーに格納するタイミングで後続処理で不要なフィールドの削除、データ欠損の補完や整合性チェックを行う必要があります。
- ゴールド層:BIや機械学習等で使用されるある特定の目的向けに加工されたデータが格納されたレイヤーとなります。つまり最終目的のためにデータの集計や結合、場合によっては追加でクレンジングが行われ、ビジネスに直結するデータとなります。
このようにブロンズ⇒シルバー⇒ゴールドと遷移する中でデータがより洗練され、ビジネス価値に直結したものとなります。
ちなみにデータエンジニアリングにおいてビジネスの価値を意識することは非常に大事です。
ビッグデータという言葉に踊らされ、ビジネスにつながらないようなデータを溜め込むことで、価値のあるデータが埋もれてしまい、貴重なデータを活かしきれていない企業も多いのではないでしょうか。
Apache Spark
今回のようなメダリオンアーキテクチャでは大量のデータを扱います。この時にいかに効率的にデータを処理するかがポイントになります。
このデータ処理においてよく使用されるものが「Apache Spark」です。
Apache Spark は、ビッグデータのワークロード処理に使用されているオープンソースの分散処理システムです。インメモリキャッシュを使用し、どのようなサイズのデータにも高速な分析クエリを実行できるよう最適化されています。Java、Scala、Python、R の開発 API を提供し、バッチ処理、インタラクティブクエリ、リアルタイム分析、機械学習、グラフ処理といった複数のワークロードでのコードの再利用をサポートします。FINRA、Yelp、Zillow、DataXU、Urban Institute、CrowdStrike など、あらゆる業界の組織で使用されていることがわかります。
ちなみにSparkを扱う場合、Python(PySpark)とScalaのどちらを使うかは論点になることが多いですが、よほど大規模や複雑なデータではなければPySparkを選んだ方が学習コストやライブラリ的な意味で良いのかなと思います。(ちなみにわたしはScalaを使うことが多かったりします。)
メダリオンアーキテクチャでのSpark活用
前述したようにメダリオンアーキテクチャの各レイヤーでSparkはデータ処理エンジンとして機能します。
各レイヤーで以下のような処理を行います。
- ブロンズ層:Sparkを使って様々なデータソースからデータを高速かつ効率的に取り込みます。このとき、Sparkの並列処理が効果的に働き、大規模なデータに対応することが可能となります。
- シルバー層:ブロンズ層に格納してある生のデータに対してクレンジングやフィルタリングを行います。欠損値の補完、データの正規化や重複データの除去などを行います。ここでもSparkが効果的に働き、効率的かつ高速にデータを処理することが可能となります。
- ゴールド層:ここではシルバー層のデータに対して、さらに高度なデータ集計や統計的処理が行われます。ビジネスユーザが利用可能でビジネス価値の高いデータを作成するため、データの集計や結合さらに複雑な変換が行われます。ここでもシルバー層と同様にSparkが効果的に働き、効率的かつ高速にデータを処理することが可能となります。
このようにメダリオンアーキテクチャでは生データを取り込むブロンズ層からビジネス価値の高いデータを生成するゴールド層まで、一連のプロセスでSparkを活用することで大規模データをより高速かつ効率的に処理することが可能となります。
ちなみにオンプレ環境からAWSにデータを連携する方法は色々ありますが、ちゃんと考えないと事故が起きがちなので気を付けて行いたいですね。(過去の自戒)
AWSでのメダリオンアーキテクチャ
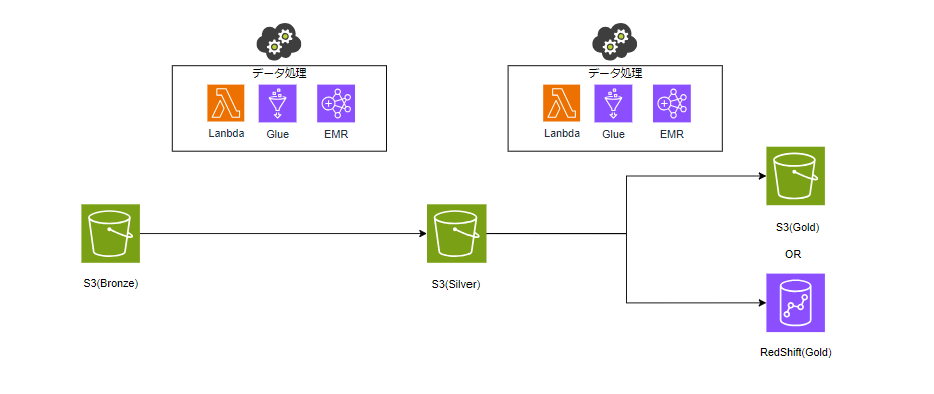
AWSでメダリオンアーキテクチャを実現する場合、ストレージの各レイヤーはS3を使用します。
S3を活用することで様々なデータを格納することができ、さらにコスト的にも低く抑えることが可能となります。
ここでポイントとなるのがゴールド層のストレージです。ゴールド層についてはS3のほかRedshiftも候補として考えられます。
詳細は割愛しますが、Redshiftは強力なDWHとなりますので、要件によってはこちらが適している場合もあります。(Redshiftは以前案件で使用した際にパフォーマンス改善に苦労した思い出があります…)
また、データ処理(ETL)に関してはLambda、Glue、EMRが候補になります。以下のメリット・デメリットを考慮したうえで選択していただければと思います。
ETLにLambda、Glue、EMRを使った場合のメリット・デメリット
AWS Lambda
- メリット:サーバレスで自動でスケーリングが可能となります。また設定や管理の手間が比較的少なくコスト効率に優れた構成とすることができます。
- デメリット:実行時間の上限が最大15分になるので大規模データを扱う場合、タイムアウトとなってしまう可能性があります。またメモリやCPU等の処理性能的に複雑なデータを扱う場合には注意が必要となります。
- ユースケース:小規模なデータ変換を行うETLに適しています。また、S3トリガーを活用することでリアルタイムで処理を実行することができます。
AWS Glue
- メリット:サーバレスで自動でスケーリングが可能となります。Sparkをベースにしたジョブを構成することができるため、高速かつ効率的に大規模データを処理することが可能となります。データカタログによるスキーマ管理や様々なデータソースと連携が比較的に容易に実施できます。
- デメリット:チューニングできる範囲が限られるため、用途によってはマッチしない可能性があります。
- ユースケース:大規模データのバッチ処理やメダリオンアーキテクチャの各レイヤーの処理に最適なサービスとなります。
Amazon EMR
- メリット:SparkのほかHadoop等のデータ処理エンジンを選択することができます。他のサービスと同様にスケールアウトも可能で、さらにカスタマイズ性も高いため様々なユースケースに対応することが可能となります。
- デメリット:他のサービスと比較するとクラスターのセットアップや管理が煩雑となるため、運用・保守コストが高くなる可能性があります。
- ユースケース:複雑なデータ処理や大規模なバッチ処理が必要な場合に適したサービスとなります。より特定業務向けに高度な処理を行いたい場合にはGlueよりも優れた性能となる可能性があります。
このようにETL処理はLambda、Glue、EMRが候補となります。
基本的にはETLに特化したGlueをベースに検討して、データ量や処理時間を考慮しながら適切なサービスを選定していただければと思います。
※アプリエンジニアは馴染みのあるLambdaを選びがちですが、ここはしっかり検討すべき部分だと思います。
AWS GlueでのSpark活用とメダリオンアーキテクチャの実践例
AWS Glueはメダリオンアーキテクチャの各層におけるETL処理をサーバーレスで効率的に実行できるサービスです。
GlueはSparkエンジンをベースにしており、大規模なデータ処理を高速かつ効率的に行うことができ、データの取り込みから分析データの生成までデータパイプラインのすべてをカバーすることができます。
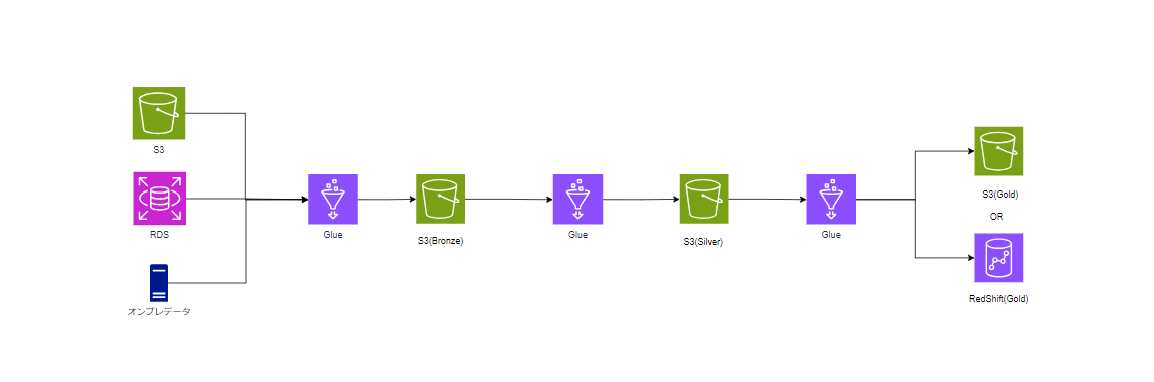
各レイヤーにおけるGlueの役割
ブロンズ層
ブロンズ層では生データをそのまま保存します。GlueでETLジョブを構成することでS3やRDS等様々なデータソースからブロンズ層にデータを取り込むことができます。
クローラー機能で各データソースのデータを検出し、データカタログにメタデータを登録することで後続の処理で効率的にデータを扱うことが可能となります。
シルバー層
シルバー層ではブロンズ層の生データに対して、データのクレンジングやフィルタリングを行ったデータを保存します。
ここで力を発揮するのがGlueのSparkジョブです。大量のデータに対して欠損補完やノイズ除去、データ型の正規化等の処理を高速に実施できます。
ゴールド層
ゴールド層ではシルバー層で加工したデータを高度な分析や集計に向けてさらに加工したデータを保存します。
特定の目的向けのBIデータや機械学習モデル用の高度なデータセットを生成します。
ここでも大量のデータに対して結合や集計処理を行う必要があるためSparkの性能が発揮されるプロセスとなります。
Glueは比較的シンプルに構築が可能ですが、非常に強力なサービスとなります。
なんでもLambdaやEC2でやるのではなく、それに特化したサービスを使うことが重要になると思います。
※古のシステムだとEC2が乱立していたりするのでリアーキテクチャが捗りますね…
まとめ
今回、データ分析基盤でデータをシンプルかつ効率的に扱うためのアーキテクチャである「メダリオンアーキテクチャ」を紹介しました。
AWSではこの記事に記載したような構成が考えられますが、ETL処理にはLambda、Glue、EMRなどのいくつかの候補があります。
プロジェクト要件や様々な要素を踏まえて、適切なサービスを選定していただければと思います。
また、データエンジニアリングとSparkに関しては以下の書籍が非常に参考になりました。
前者はデータエンジニアリングに携わる場合は必読と言っていいほど良書だと思います。
後者はDatabricksを扱う場合にも知識として役立つのでおすすめです。
- データエンジニアリングの基礎 ―データプロジェクトで失敗しないために
- Apache Spark徹底入門
Discussion