AWS Lambda×DuckDBによる軽量ETLの実装
はじめに
個人的にデータエンジニアリングについて考える機会が増えています。
その中でAWS上での小規模ETLの構築ができないかと考えました。
一般的にはGlueやLambdaが候補となりますが、Glueの場合、小規模データだとコストと見合わず、Lambdaだと処理能力や実行時間の上限が課題となります。
とはいえLambdaのサーバレスでの柔軟な処理は大変魅力的です。
そこで今回はLambdaとDuckDBを組み合わせてシンプルで効率的なETLを構築する方法を紹介します。
DuckDBは軽量ですが強力なクエリエンジンを提供してくれるためLambdaでETLを構築する場合に高速かつ効率的なデータ処理が可能となります。
DuckDBとは
DuckDBとは、組み込み型のOLAP(オンライン分散処理)向けデータベースエンジンです。
DuckDBは非常に軽量で、インメモリ処理が可能となるためLambdaのようなシンプルな環境でも効率的に動作させることができます。
特にデータ分析やETL処理のようなバッチ処理において強力なパフォーマンスを発揮すると言われています。
処理イメージ
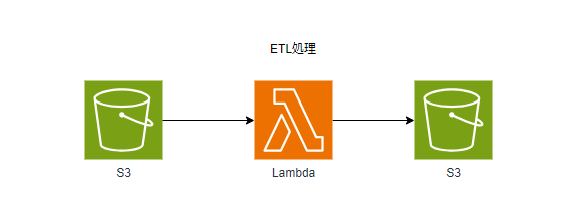
今回はS3に格納したCSVからLambdaでデータを抽出し、抽出したデータをS3に格納するというちょっとしたETLを作成してみます。
CSVはKaggleでおなじみのTitanicのtraining set (train.csv)を活用します。
このデータから年齢が20歳以下のデータを抽出してCSVを作成してみます。
Lambdaへの組み込み
Lambdaへの組み込みはLambda レイヤーを使うのが手っ取り早いです。

サンプルコード
今回は動作確認をしたいだけなのでqueryをハードコーディングしています。
S3トリガーを使用すればバケット名とファイル名が取れるのでパラメータとして渡せば実用できると思います。
import DuckDB from "duckdb";
// Instantiate DuckDB
const duckDB = new DuckDB.Database(":memory:");
// Create connection
const connection = duckDB.connect();
// Promisify query method
const query = (query) => {
return new Promise((resolve, reject) => {
connection.all(query, (err, res) => {
if (err) reject(err);
resolve(res);
});
});
};
// Lambda handler function
export const handler = async (event) => {
try {
// Will show DuckDB version
await query("SET home_directory='/tmp'");
await query(
`COPY (SELECT * FROM read_csv('s3://duckdb-test20240920/train.csv') WHERE Age <= 20) TO 's3://duckdb-test20240920/train2.csv'`
);
return {
statusCode: 200,
body: JSON.stringify({result: "OK" }),
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: error.message }),
};
}
};
実行結果
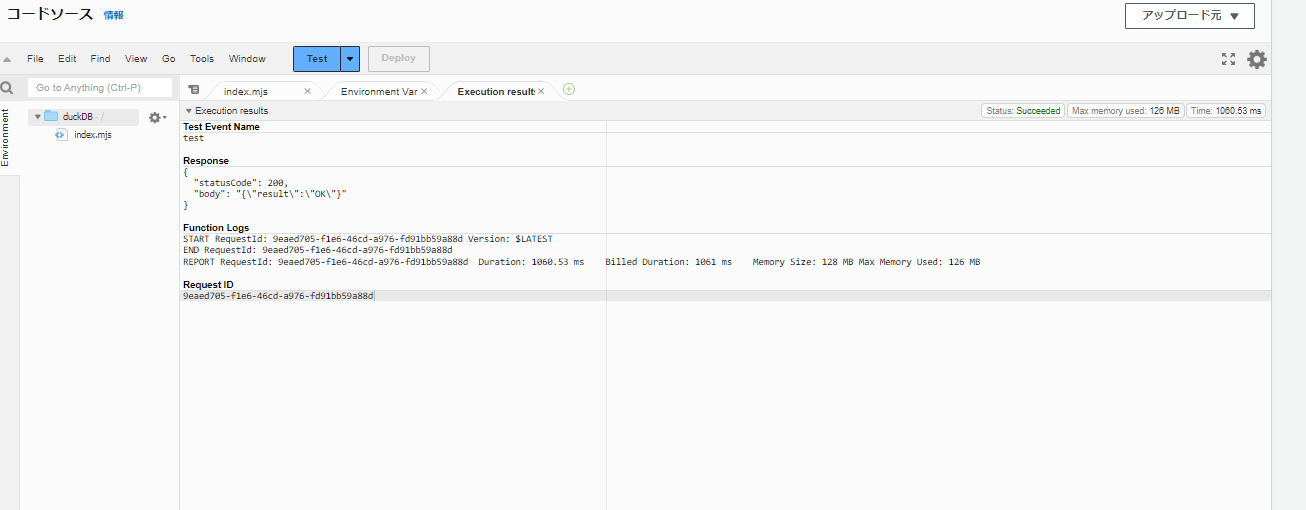
下記のようにtrain2.csvが作成される。

こんな感じにWHERE句の条件でフィルタされたデータが格納されました。

Lambda×DuckDBのメリット・デメリット
メリット
- 導入が簡単:Lambdaレイヤーで簡単に導入可能。
- Lambdaで簡単に開発可能:DuckDBにて提供されている関数を活用することで簡単に開発が可能。
- SQLライクな処理:SQLの構文(PostgreSQL互換)で簡単に操作できる。
- 効率的な処理が可能:Lambda上でもインメモリ処理により効率的なデータ処理が可能。
- S3トリガーでリアルタイムETL処理が可能:S3トリガーを使うことでファイル格納をトリガーにETL処理を即時実行可能。
デメリット
- 最大メモリサイズの制限がある:Lambdaの制限により最大メモリサイズが10240 MBとなる。場合によってはメモリが枯渇する可能性がある。(とはいえ意外と大規模データセットでも耐えられるみたいです。)
- 実行時間の制限がある:Lambdaの制限により実行時間は15分が最大となります。大規模データセットの場合、15分を超えてしまう可能性があるため、場合によってはコンテナサービス等も検討する必要があります。LLRTを活用することで処理を改善できると思います。
まとめ
今回は軽量なデータセットでのお試し程度でしたが、非常に簡単に導入することができました。
AWSでのETLといえばGlueやEMRが候補として考えられますが、小規模なデータセットの場合、コストが見合わないことが考えられます。
そういった場合に今回のLambda×DuckDBはコストパフォーマンスに優れた有力な候補となると考えられます。
また、Lambdaということもあり、S3トリガーで動作させることも可能となりますので、軽量なリアルタイムETLとして活用可能だと思います。
また、ETL以外にもAthenaの代わりに使ったり、様々な用途で活用が期待できます。
Lambda関数URLを使ってqueryの中身をパラメータとして渡して、レスポンスに取得データを設定すればAthenaもどきができそうな気がします。
今回の記事が小規模データ処理の実装の参考になると幸いです。
Discussion