AWSで実現するLambdaアーキテクチャとKappaアーキテクチャ
はじめに
近年、「データ」の価値に注目が集まり、データ基盤をより効率的かつスケーラブルに実現することが不可欠となっています。
また、IoTの発展に伴い、リアルタイムデータ(ストリーミングデータ)の取り扱いが課題となっています。
そういった中で「Lambdaアーキテクチャ」と「Kappaアーキテクチャ」の2つのデータアーキテクチャが注目されています。
この記事ではこの2つのデータアーキテクチャとAWSでの構成例について紹介したいと思います。
ちなみにここで言うLambdaはAWS Lambdaではないので注意してください。
Lambdaアーキテクチャとは

Lambdaアーキテクチャとはバッチデータとリアルタイムデータの2つを同時に扱うためのアーキテクチャとなります。
Lambdaアーキテクチャは3つのレイヤーで構成されます。
- リアルタイムレイヤー(スピードレイヤー):このレイヤーはストリームデータを扱うレイヤーとなり、可能な限り低いレイテンシでデータを提供することを目的とします。高度な変換や集計を行うことなく最低限の処理を行っただけのデータが格納されるものとなります。
- バッチレイヤー:このレイヤーはバッチデータを扱うレイヤーとなり、データの集約や変換を行ったデータを提供することを目的とします。後続処理で扱えるように意味を持った形に集約されたデータが格納されます。
- サービングレイヤー:このレイヤーはリアルタイムレイヤーとバッチレイヤーの2つのレイヤーを集約したレイヤーとなります。BIツールはこのレイヤーに接続してデータを閲覧することとなります。
リアルタイムデータとバッチデータを同時に扱うことのできるLambdaアーキテクチャですが、いくつかの課題があります。
- 構成が複雑になる:前述したようにバッチレイヤーとリアルタイムレイヤーの2つのシステムを管理する必要があり、データの粒度やタイミングも異なるため複雑になってしまいます。また、保守や維持コストも高くなってしまうことが考えられます。
- データの同期が難しい:リアルタイムレイヤーとバッチレイヤーそれぞれ異なる粒度のデータとなりますが、データソースとしては同じものとなります。同じデータソースから生成されたデータなので理論上は同期がとれたものとなるはずです。ところがデータの取り込みタイミングやバッチ処理のクエリ次第ではデータの整合性に矛盾が発生することがあります。この部分が課題となることが多いと言われています。
Kappaアーキテクチャとは
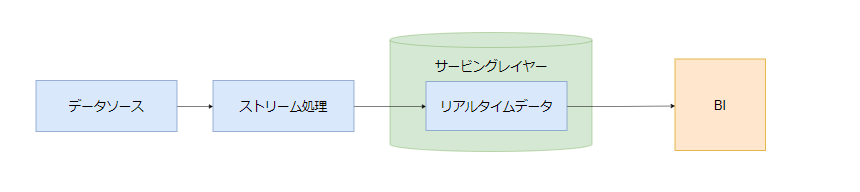
KappaアーキテクチャはLambdaアーキテクチャとは異なり、すべてのデータ処理(取り込み、ストレージ、データ提供)をストリームデータで対応するという発想のアーキテクチャとなります。
これによって真のイベントベースのアーキテクチャが実現できます。
- サービングレイヤー:ストリームデータを扱うレイヤーとなり、BIからはストリームデータはそのまま読み込み、バッチデータは過去のデータセットに対してクエリ実行を行う。バッチ処理を持たないためよりシンプルかつ安価に構成することができる。
Lambdaアーキテクチャの複雑さと同期の難しさを克服したKappaアーキテクチャが、DWHの性能向上やストレージのコスト低下も追い風となり今後の主流になると言われています。
AWSでLambdaアーキテクチャを実現する
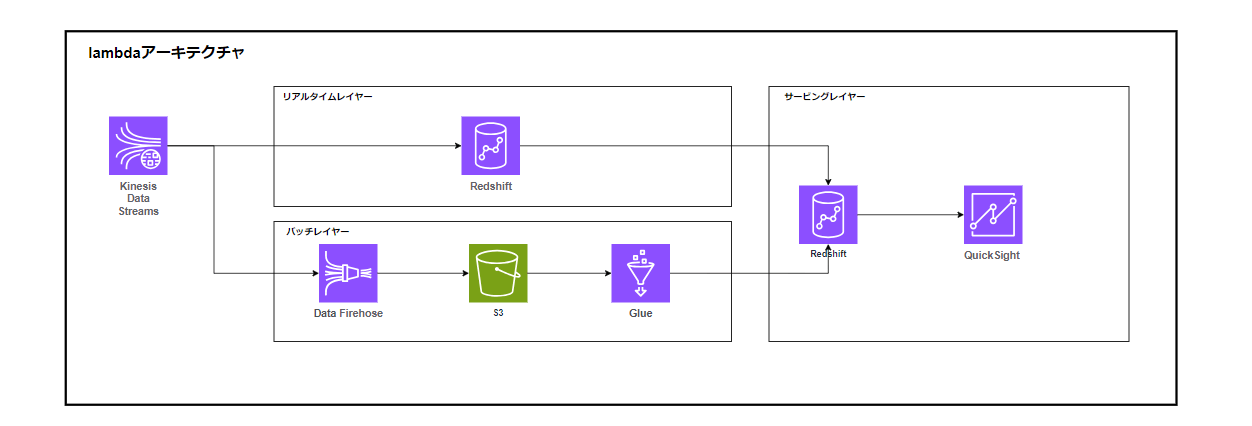
AWSでLambdaアーキテクチャを構成する場合、というよりリアルタイムデータの取り扱いが課題となります。
ストリーミングデータを取り扱う場合の候補としてApache Kafka、Apache Flink、Apache Spark Streaming等強力なツールが存在します。
データエンジニアリングにおいてストリーミングデータの取り扱いは難しく、正解がないと言われています。
どのツールを選択しても欠点は必ず存在するため、要件やトレードオフを加味して選択する必要があります。
今回はAWSということで素直にKinesis Datastreamを選択します。
各レイヤーでどういった処理を行うか解説します。
-
リアルタイムレイヤー(スピードレイヤー)
- Amazon Redshift Serverless:Kinesis Data Streamsからマテリアライズドビュー経由でデータをインジェストします。ここで注意が必要なポイントがマテリアライズビューの更新を伴うため、「ほぼ」リアルタイムの取り込みということになります。
-
バッチレイヤー
-
Data Firehose:Kinesis Data StreamsからData Firehoseを経由してS3にデータを格納します。バッチ処理、変換処理、暗号化も可能なため要件に応じて様々な処理を実施できます。
-
Amazon S3:ここではデータレイクとして活用します。構造化データと非構造化データをまとめて管理します。
-
AWS Glue:S3に格納したデータをGlueで処理します。GlueのSpark処理にて大量データを効率的かつ高速に処理することが可能です。Glueで集計、集約したデータをRedshiftに連携します。
Glueを使わなくてもRedshiftから直接クエリできますが、サービングレイヤーとの分離を考えてGlueで連携することします。
-
-
サービングレイヤー
- Amazon Redshift Serverless:バッチレイヤーからはGlueにて連携、リアルタイムレイヤーからはデータ共有機能を使ってデータを連携します。
- Amazon QuickSight:バッチデータおよびリアルタイムデータに対してクエリを発行し、ダッシュボードを作成します。QuickSightの他、SageMakerで機械学習を行ってもいいと思います。
AWSでKappaアーキテクチャを実現する

比較のため、Lambdaアーキテクチャと同じサービスを活用しました。非常にシンプルですね。
一応各レイヤーでどういった処理を行うか解説します。
-
サービングレイヤー
-
Amazon Redshift Serverless:Kinesis Data Streamsからマテリアライズドビュー経由でデータをインジェストします。ここで注意が必要なポイントがマテリアライズビューの更新を伴うため、「ほぼ」リアルタイムの取り込みということになります。(Lambdaアーキテクチャと同じ)
-
Amazon QuickSight:バッチデータおよびリアルタイムデータに対してクエリを発行し、ダッシュボードを作成します。QuickSightの他、SageMakerで機械学習を行ってもいいと思います。(Lambdaアーキテクチャと同じ)
-
このようにKappaアーキテクチャは非常にシンプルな構成とすることが可能です。
保守工数やランニングコストの点でもこちらの方が優れていると思います。
まとめ
データ活用においてはデータの鮮度が何よりも重要となります。
今回のようにリアルタイムデータを扱う場合、LambdaアーキテクチャとKappaアーキテクチャをもとに構成することでリアルタイムのデータとバッチデータの両方に対応することが可能となります。
今回の構成はあくまでも一例となりますので、もしかするともっと最適な構成があるかもしれません。
とはいえ各アーキテクチャの概念は変わらないと思うのでリアルタイムデータを扱う際に参考にしていただければと思います。
また、こちらの記事でAWSで実現するメダリオンアーキテクチャについてまとめているのでお時間のある時に読んでいただければと思います。
Discussion