【ネットワークの中心性】vol.7 PageRank
シリーズの目次
虎の威を借る狐
前回の記事では, Katz 中心性は固有ベクトル中心性の欠点を補完する一方で,高い中心性を持つノードに隣接するノードに同等のスコアが流入してしまうという問題があることを指摘しました.Katz 中心性の定義だと,自身のフォロワーは少ないのにインフルエンサーからフォローされることで中心性が高くなるという「虎の威を借る狐」のような状況が生まれてしまいます.もちろん,インフルエンサーがそのユーザーだけをフォローしている場合はその限りではありません.しかし多くの場合,インフルエンサーは多数のユーザーをフォローしているため,フォローされている個々のユーザーは "one of them" であることは珍しくないでしょう.Katz 中心性に対して,中心性の高いノードの近傍にあるノードは "one of them" であるという性質を組み込んだのが PageRank (ページランク)です[1].
Google の検索技術 PageRank
PageRank は,Google の共同創設者であるラリー・ペイジ (Larry Page) とセルゲイ・ブリン (Sergey Brin) が World Wide Web (WWW) を対象とする検索エンジンが直面していた問題を解決するために開発したウェブページのスコアリング指標です [Brin and Page, 1998].ユーザがクエリを入力すると,クエリに関係のある膨大な数のページが見つかりますが,どのページがユーザにとって有益な情報なのかを特定することは困難でした.ペイジとブリンはこの問題を解決するべく,WWW のハイパーリンク構造を利用してウェブページの重要性をスコアリングするアルゴリズム PageRank を考案しました.PageRank は Google の初期の成功の一因となったとされています.
PageRank はたくさんのウェブページからリンクされているページほど重要であるとみなすオーソリティ中心性です.ですので,Katz 中心性から PageRank への拡張を行うにあたって,オーソリティベース Katz 中心性を拡張することを考えます.復習ですが,ノード
ただし,
PageRank の定義
以下,有向グラフ
先ほど中心性の高いノードの近傍にあるノードは "one of them" であるという話をしました.インフルエンサーである
WWW 上のウェブページにも全く同じことが言えます.ページ
Katz 中心性の拡張
では Katz 中心性をどのように拡張すれば,相手は自分の出次数によって "one of them" にも "only one" にもなりえるという性質を反映できるでしょうか.ノード
となります.
これは一見良さそうな定義ですが,
と定義されます.こうすることで
となります.ただし,
と変形できます.
で与えられます.
証明
が成り立つ.したがって,線形システム
で与えられる.
減衰係数の導入
Katz 中心性の拡張としての PageRank は
ランダムサーファーモデルでは,ユーザーがネットサーフィンに飽きて別のページにランダムにジャンプするため,どのページからもリンクが張られていないページに飛ぶ可能性があります.つまり,どのページも確率的なスコアが与えられるということです.Katz 中心性では皆に等しく
となります.両辺の
左辺の和の添え字を
となり,PageRank が確率として定義できていることが確認できます.先ほどと同様に,
を減衰係数
で与えられます.
Pythonでの実装
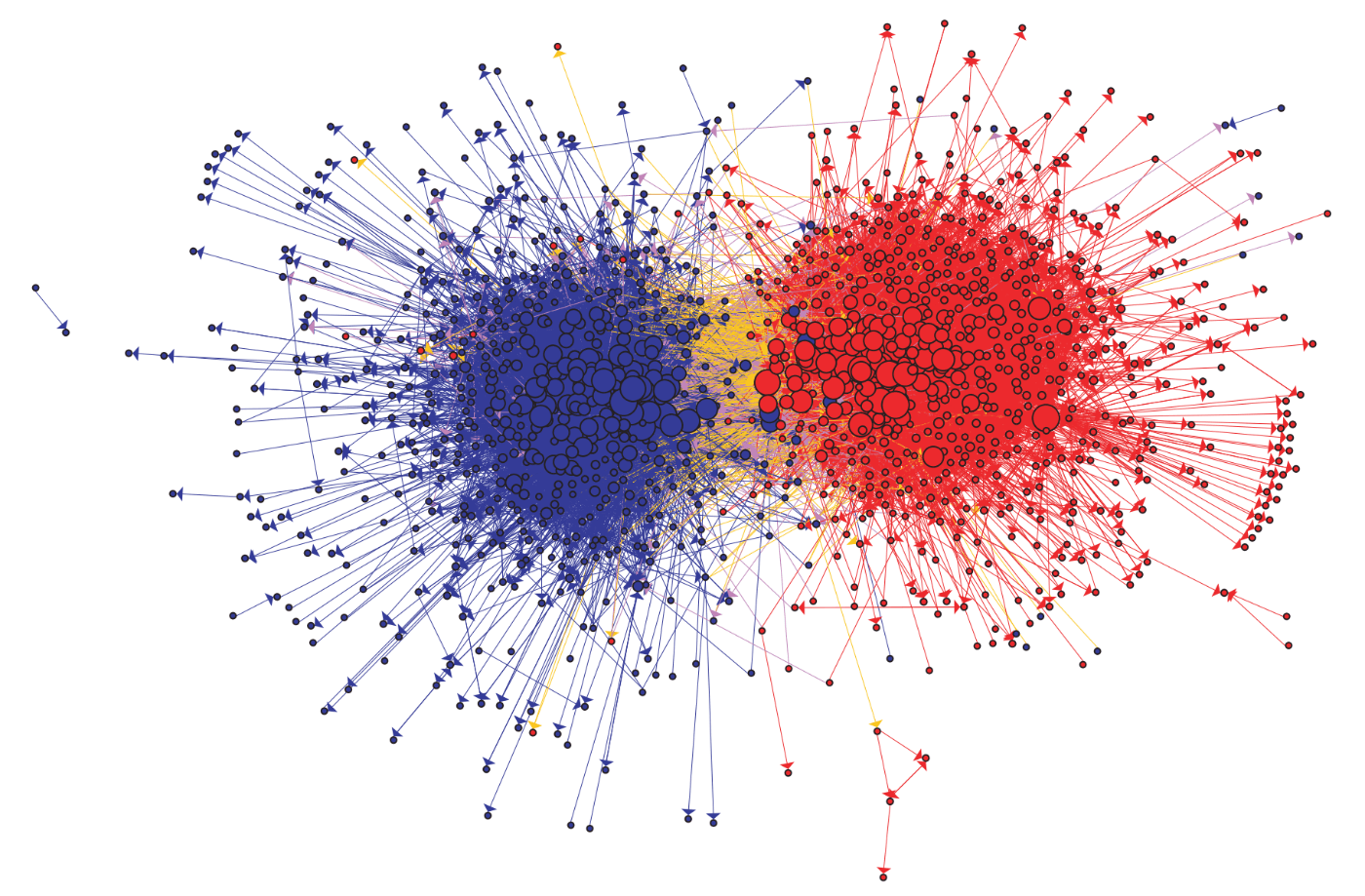
図1:Adamic and Glance (2005) が提示したアメリカの政治をテーマにしたブログの引用関係ネットワーク.赤色のノードは保守的なブログ,青色はリベラルなブログをそれぞれ表しており,リベラルから保守へのハイパーリンクは黄色で,保守からリベラルへのリンクは紫色で可視化されている.
出所)Adamic and Glance (2005)
PageRank を計算する PageRank() 関数を作り,図1で可視化されたアメリカの政治をテーマにしたブログの関係性を示す有向ネットワークの中心性を求めます[2].これまで実装した関数と違って,PageRank はオーソリティ中心性として定義されるので,隣接行列の転置を取ってから計算します.また,Brin and Page (1998) に合わせて,減衰係数はデフォルトで
まず,引数に出次数の配列を受け取って各要素を MAX() 関数を定義します.
def MAX(degree):
"""
Returns the array of max(1, out-degree of i)
"""
return np.array([i if i > 1 else 1 for i in degree])
MAX() 関数を使用して PageRank() 関数を定義します.ここでは
def PageRank(A, alpha=0.85):
"""
Computes the PageRank of A, defined as the x solving
x = (1-alpha)/N1 + alpha A.T D x (N = # nodes, 1 = vector of ones, D = diag(1 / max(1, out-degree)))
Parameters
----------
A : NumPy ndarray
Adjacency matrix representation of graph.
alpha : int or float (default: 0.85)
Damping factor.
Returns
-------
k : NumPy ndarray
PageRank of A.
"""
A_temp = A.T
N = len(A_temp) # ノード数
I = np.identity(N) # 単位行列
out_degree = A @ np.ones(N) # 出次数ベクトル
D = np.diag(1 / MAX(out_degree)) # 出次数の逆数を取った対角行列
M = A_temp @ D # 行列Mを定義
IA_inv = np.linalg.inv(I - alpha * M) # 逆行列
return (1-alpha)*IA_inv @ np.ones(N) / N # (9)式
図1の有向ネットワークを graph-tool で生成し,まずは graph-tool で実装されている組み込み関数 graph_tool.centrality.pagerank() を使って中心性を計算し,中心性を反映する形で可視化します.
import graph_tool.all as gt
import matplotlib
g = gt.collection.data["polblogs"] # データの読み込み
g = gt.GraphView(g, vfilt=gt.label_largest_component(g)) # 孤立したネットワークを除去
pr = gt.pagerank(g) # graph-tool の組み込み関数で PageRank を計算
# ネットワークの可視化
gt.graph_draw(g, pos=g.vp["pos"], vertex_fill_color=pr,
vertex_size=gt.prop_to_size(pr, mi=5, ma=15),
vorder=pr, vcmap=matplotlib.cm.hot,
vertex_shape="square");
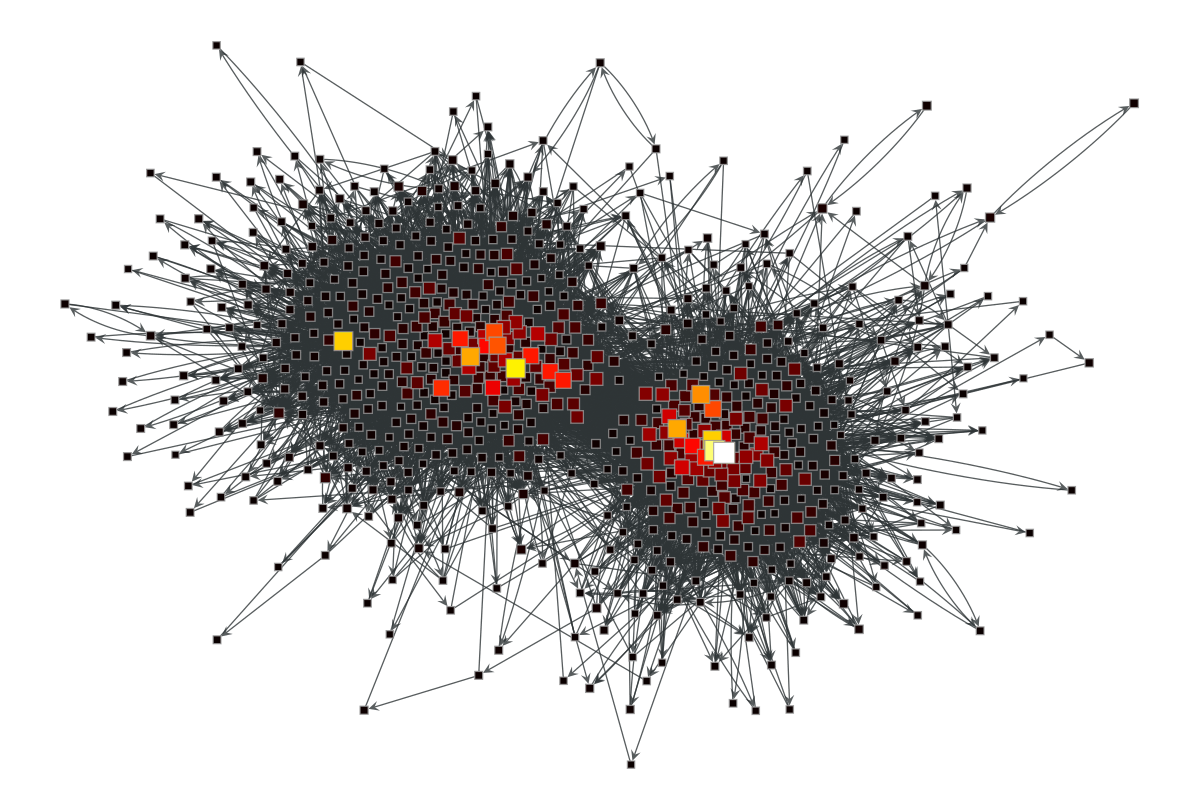
図2:graph-tool の関数で計算した PageRank.ノードの大きさは中心性の大きさに比例しており,明るいほど高い PageRank を持つ.
次に実装した PageRank() 関数を使って中心性を計算し,中心性を反映するようにネットワークを可視化します.今回は組み込み関数ではないため,可視化のために個々のノードの PageRank を VertexPropertyMap というノードの属性を管理するクラスに格納する必要があります.
## 自作の PageRank() で計算
# グラフを隣接行列に変換
A = gt.adjacency(g).toarray().T # graph-tool の隣接行列の定義は j --> i で a_{ij} = 1
pagerank = PageRank(A) # 自作関数で PageRank を計算
# PageRank を VertexPropertyMap に登録する
PR = g.new_vertex_property("double")
for i, v in enumerate(g.vertices()):
PR[v] = pagerank[i]
# ネットワークの可視化
gt.graph_draw(g, pos=g.vp["pos"], vertex_fill_color=PR,
vertex_size=gt.prop_to_size(PR, mi=5, ma=15),
vorder=PR, vcmap=matplotlib.cm.hot,
vertex_shape="square");
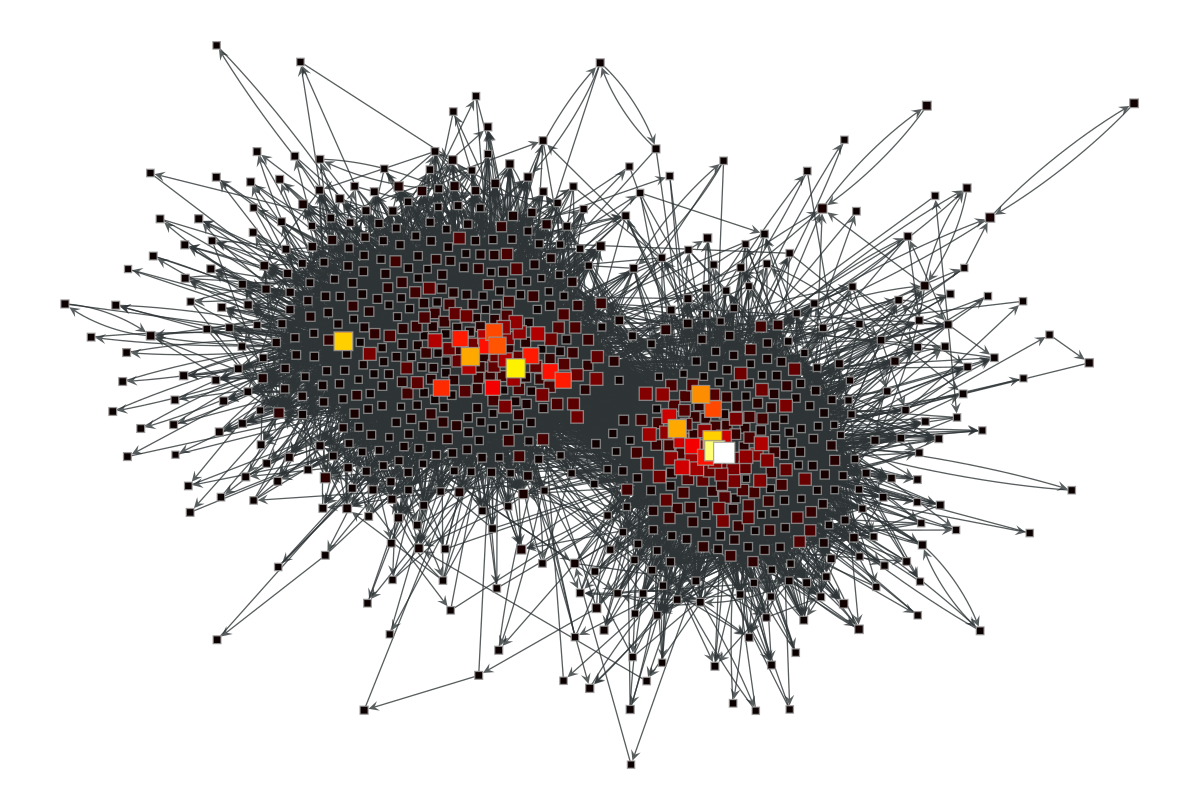
図3:実装した PageRank() 関数の計算結果.ノードの大きさは中心性の大きさに比例しており,明るいほど高い PageRank を持つ.
図2と図3を比べると,実装した PageRank() 関数でもしっかりランク付けできていることが確認できます.個々のノードの PageRank 同士を比べてみても,すべての値が近いことが確認できます.
## 要素同士の比較
gt_pagerank = np.array(list(pr)) # graph-tool の計算結果 pr を配列に変換
# 要素同士を参照して, PageRank() の浮動小数点演算の結果が graph-tool と近いか比較
np.allclose(gt_pagerank, pagerank) # >>> True
【おまけ】 PageRank とマルコフ連鎖
ここまで Katz 中心性の拡張として PageRank を定義し,さらに元論文 Brin and Page (1998) で導入されている減衰係数を加味した定義も確認しました.最後に,PageRank をマルコフ連鎖の定常分布というまた別の視点から眺めてみたいと思います.
PageRank のエッセンスは,ノードのリンク元の出次数による相対的な重要性の変化に対処することにありました.ですので,ここでは
と定数項
となります.ノード
と書けます.さらに,
となります.ただし,
と書けます.つまり,ベクトル
ところで,
このように,任意の行和が
PageRank
おわりに
本記事では,相手にとって自分が "one of them" なのか,それとも "only one" なのかを考慮した Katz 中心性の拡張としての PageRank を見た後,Brin and Page (1998) の減衰係数を導入した定義も紹介しました.その定義に基づいて Python で PageRank() を実装し,実際のネットワークデータを使って中心性指標として機能していることを確認しました.
本連載では,次数中心性を拡張していく形で固有ベクトル中心性や Katz 中心性を紹介してきたため,この記事でも同様に PageRank を次数中心性の拡張の流れの中で紹介しました.しかし,PageRank は元論文 Brin and Page (1998) においては,ネットワーク上のランダムウォークとして導入されているので,最後に PageRank はランダムウォークの定常分布というもう一つの顔を持つことを説明しました.
最後に,Newman (2018) に倣って,今まで取り上げてきた中心性指標を表にまとめておきます.どの中心性も隣接行列に基づいて計算されますが,定数項があるかどうか,出次数で割り引くかどうかで区別できます.
| 定数項あり | 定数項なし | |
|---|---|---|
| 出次数で割り引く | PageRank | 次数中心性 |
| 割り引かない | Katz 中心性 | 固有ベクトル中心性 |
参考文献
- Adamic, L. A., & Glance, N. (2005, August). The political blogosphere and the 2004 US election: divided they blog. In Proceedings of the 3rd international workshop on Link discovery (pp. 36-43).
- Brin, S., & Page, L. (1998). The anatomy of a large-scale hypertextual web search engine. Computer networks and ISDN systems, 30(1-7), 107-117.
- John Stachurski and Thomas J. Sargent. Economic Networks: Theory and Computation (QuantEcon, 2022). URL https://networks.quantecon.org/ .
- Newman, M. (2018). Networks. Oxford university press.
-
元論文 Brin and Page (1998) では,PageRank はグラフ上のランダムウォークとして導入されていますが,本連載はまず Katz 中心性を拡張する形で議論を進めていきます. ↩︎
-
Adamic and Glance (2005) は,2004年のアメリカ大統領選挙に先立つ2ヶ月の間に投稿されたブログを分析し,リベラルと保守の両コミュニティ内外のブログの参照関係を明らかにしました.彼らによるとリベラルと保守の振る舞いには違いが見られ,リベラルなブログは保守のブログも参照するのに対して,保守のブログの方がより頻繁に,保守同士で参照し合う傾向があったということです.ネットワークの構造に政治的な分断が反映されているのは興味深いですね ↩︎
Discussion