「Graphiti」を試す
2025/04のTechnology Radar Volume 32で、Platforms に "Asssess" として挙がっていたのが「Graphiti」。
実は以前に触ったZepの裏で使用されていた。
Zepは、LLMの会話履歴からユーザに関連する情報を長期記憶として保持するためのライブラリで、ユーザに関連する事実やその関係性などをナレッジグラフとして保持しており、ここにGraphitiが使用されている。
なお、Technology Radar Volume 32では、
- Techniques で、GraphRAG が "Trial"
- Language & Frameworks で、FastGraphRAG が "Assess"
となっており、GraphRAGそのものは導入検討に値し、そして、今後の関心はそれを支援するようなプラットフォーム・ツールなどに移っていくフェーズが近づいているのではないか?と感じる。
ということで、あらためて単体でやってみる。
なお、GraphRAG関連は過去に以下を試している。
他にもナレッジグラフを使用したRAGの実装は色々試してるんだけど、自分の認識では、”GraphRAG”はMicrosoftが提唱した実装であって、単にRAGのバックエンドにナレッジグラフを採用するだけの"Graph(space)RAG" / "Graph+RAG" とは別だと思っている。
GitHubレポジトリ
Graphiti
AIエージェント向けリアルタイム知識グラフの構築
Graphitiは、時間認識型の知識グラフを構築・クエリするためのフレームワークで、動的環境で動作するAIエージェント向けに特別に設計されています。従来の検索拡張生成(RAG)手法とは異なり、Graphitiはユーザーとのインタラクション、構造化・非構造化企業データ、外部情報を一貫性のあるクエリ可能なグラフに継続的に統合します。このフレームワークは、完全なグラフの再計算を必要とせずに、増分データ更新、効率的な検索、正確な履歴クエリをサポートし、インタラクティブでコンテキスト認識型のAIアプリケーションの開発に適しています。
Graphitiの用途:
- 動的なユーザーインタラクションとビジネスデータの統合と維持。
- エージェントのための状態ベースの推論とタスク自動化の促進。
- 複雑で進化するデータを、意味的、キーワード、グラフベースの検索方法でクエリ。
referred from https://github.com/getzep/graphiti知識グラフは相互接続された事実のネットワークです。例えば、「ケンドラはアディダスの靴が好き」などです。各事実は「トリプレット」であり、2つのエンティティ、またはノード(「ケンドラ」、「アディダスの靴」)とその関係、つまりエッジ(「好き」)で表されます。
知識グラフは情報検索に広く活用されてきました。Graphitiの特徴は、変化する関係を処理し、歴史的コンテキストを維持しながら、自律的に知識グラフを構築する能力にあります。GraphitiとZepメモリ
GraphitiはAIエージェント向けのZepのメモリレイヤーの中核を支えています。
Graphitiを使用して、ZepがエージェントメモリのState of the Art(最先端)であることを実証しています。
論文をご覧ください:Zep: A Temporal Knowledge Graph Architecture for Agent Memory。
Graphitiをオープンソース化することに興奮しています。その潜在的な可能性はAIメモリアプリケーションを遥かに超えると信じています。

なぜGraphitiなのか?
従来のRAGアプローチはバッチ処理と静的データ要約に依存することが多く、頻繁に変更されるデータには非効率です。Graphitiはこれらの課題に対処するために以下を提供します:
- リアルタイム増分更新: バッチ再計算なしに新しいデータエピソードを即座に統合。
- 二時間データモデル: イベントの発生時間と取り込み時間を明示的に追跡し、特定時点のクエリを可能に。
- 効率的なハイブリッド検索: 意味的埋め込み、キーワード(BM25)、グラフ探索を組み合わせて、LLMの要約に依存せずに低レイテンシのクエリを実現。
- カスタムエンティティ定義: 柔軟なオントロジー作成と、簡潔なPydanticモデルを通じた開発者定義エンティティのサポート。
- スケーラビリティ: 並列処理で大規模データセットを効率的に管理し、企業環境に適合。
referred from https://github.com/getzep/graphitiGraphitiとGraphRAGの比較
観点 GraphRAG Graphiti 主な用途 静的文書の要約 動的データ管理 データ処理 バッチ指向の処理 継続的、増分的更新 知識構造 エンティティクラスタ&コミュニティ要約 エピソードデータ、意味的エンティティ、コミュニティ 検索方法 順次LLM要約 ハイブリッド意味的、キーワード、グラフベースの検索 適応性 低 高 時間処理 基本的なタイムスタンプ追跡 明示的な二時間追跡 矛盾処理 LLM駆動の要約判断 時間的エッジ無効化 クエリレイテンシ 数秒から数十秒 通常はサブ秒レイテンシ カスタムエンティティタイプ いいえ はい、カスタマイズ可能 スケーラビリティ 中程度 高、大規模データセット向けに最適化 Graphitiは動的かつ頻繁に更新されるデータセットの課題に対処するために特別に設計されており、リアルタイムのインタラクションと正確な履歴クエリを必要とするアプリケーションに特に適しています。

公式ドキュメント
インストールやQuickstartがあるのでこれに従って進める。グラフデータベースのバックエンドにNeo4jが必要になるので、今回はローカルのMacで。
インストール
必要なものは以下
- Python 3.10以上
- Neo4j 5.21以上
- OpenAI APIキー
- LLMの推論とEmbeddingsのため
- AnthropicやGroqなども対応している様子
Neo4j (Desktop) のインストール
で、Neo4jはDockerでインストールしようかなと思ったのだけど、
Neo4jをインストールする最も簡単な方法は、Neo4j Desktopを使用することです。Neo4j Desktopは、Neo4jインスタンスとデータベースを管理するための使いやすいインターフェースを提供します。
Neo4j Desktopとかあるのか、知らなかった。
Homebrewにあったりしないのかなーと思って検索してみたら、FormulaとCaskのそれぞれにある
brew search neo4j
==> Formulae
neo4j neon
==> Casks
neo4j
それぞれ見てみる。
brew info --formula neo4j
==> neo4j: stable 2025.03.0 (bottled)
Robust (fully ACID) transactional property graph database
https://neo4j.com/
Not installed
From: https://github.com/Homebrew/homebrew-core/blob/HEAD/Formula/n/neo4j.rb
License: GPL-3.0-or-later
==> Dependencies
Required: cypher-shell ✘, openjdk@21 ✘
==> Caveats
To start neo4j now and restart at login:
brew services start neo4j
Or, if you don't want/need a background service you can just run:
/opt/homebrew/opt/neo4j/bin/neo4j console
==> Analytics
install: 1,217 (30 days), 3,621 (90 days), 12,179 (365 days)
install-on-request: 1,218 (30 days), 3,622 (90 days), 12,178 (365 days)
build-error: 0 (30 days)
brew info --cask neo4j
==> neo4j: 1.6.1
https://neo4j.com/download/
Not installed
From: https://github.com/Homebrew/homebrew-cask/blob/HEAD/Casks/n/neo4j.rb
==> Name
Neo4j Desktop
==> Description
Developer IDE or Management Environment for Neo4j instances
==> Artifacts
Neo4j Desktop.app (App)
==> Caveats
neo4j is built for Intel macOS and so requires Rosetta 2 to be installed.
You can install Rosetta 2 with:
softwareupdate --install-rosetta --agree-to-license
Note that it is very difficult to remove Rosetta 2 once it is installed.
==> Analytics
install: 116 (30 days), 306 (90 days), 1,083 (365 days)
なるほど、Formulaの方はNeo4j Serverで、CaskにあるのがDesktopの様子。Apple Siliconに対応していないようなので、Rosettaが必要になるみたい。
普通に考えればDockerでインストールするほうが早いと思うけど、自分はDesktopが気になったので今回はDesktopを使ってみる。Rosettaは多分インストールしているはずだけども確認。
sysctl hw.optional.arm64
hw.optional.arm64: 1
有効になっていた。無効の場合は
softwareupdate --install-rosetta --agree-to-license
すれば良い。なお、Rosettaは一度インストールするとアンインストールがかなり難しいらしい。個人的に困ったことは一度もないので気にしないけど。
ではNeo4j Desktopをインストール。
brew install --cask neo4j
インストールされた。(ここにRosettaのアンインストールが難しいと出力されてる。)
==> Downloading https://formulae.brew.sh/api/cask.jws.json
==> Downloading https://formulae.brew.sh/api/cask_tap_migrations.jws.json
==> Downloading https://formulae.brew.sh/api/formula_tap_migrations.jws.json
==> Caveats
neo4j is built for Intel macOS and so requires Rosetta 2 to be installed.
You can install Rosetta 2 with:
softwareupdate --install-rosetta --agree-to-license
Note that it is very difficult to remove Rosetta 2 once it is installed.
==> Downloading https://dist.neo4j.org/neo4j-desktop/mac/Neo4j%20Desktop-1.6.1.dmg
################################################################################################################### 100.0%
==> Installing Cask neo4j
==> Moving App 'Neo4j Desktop.app' to '/Applications/Neo4j Desktop.app'
🍺 neo4j was successfully installed!
Neo4j Desktopを起動。規約へ同意。
どうやらソフトウェアの登録が必要になる様子。適宜実施。今回はとりあえず「Register Later」で。

これでどうやら環境が構築される様子。完了するまで待つ。

使用状況の共有について聞かれる。あとから設定することもできるようなので、とりあえずOKで。

どうやらNeo4jで使用するポートとバッティングしているらしい。多分これAirPlayで使ってるやつだな。Neo4j側で変更してくれるようなので「Fix configuration」する。

なんか警告的なメッセージが表示される。

Neo4j Desktopは、Graph Appsやその他のウェブコンテンツを使用しています。これらの一部はコミュニティによって提供されており、インストールする他のソフトウェアと同様に、データの整合性やセキュリティの問題を引き起こす可能性があります。機密データを取り扱う場合は、使用する前に独自のセキュリティ監査を行うことをお勧めします。
んー、まあ個人レベルのお試しだし、今回は気にしないことにする。
こんな感じで完了。既にサンプルのプロジェクトが用意されているみたい。

まああらためてDockerのほうが簡単だと思う。
Graphitiのインストール
ではGraphitiをインストールしていく。
uvで作業ディレクトリ&Python仮想環境作成
uv init -p 3.12.9 graphiti-work && cd graphiti-work
uv venv
パッケージインストール
uv add graphiti-core
(snip)
+ graphiti-core==0.8.8
(snip)
Quick Start
Quickstartを始める前に、Neo4j Desktopでプロジェクト及びデータベースを作成する。
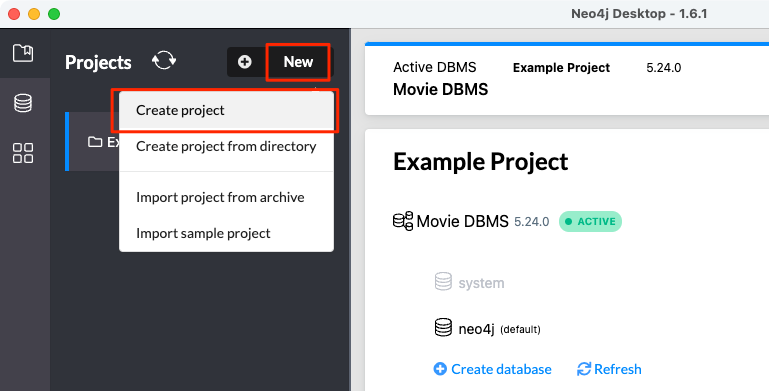
プロジェクトにLocal DMBSを追加

Local DMBSのデータベースの名前とパスワードを入力して作成

作成されたら起動

Local DBMSを起動すると、上のアクティブなDBMSが切り替わる。

インストール時と同じようにポートの衝突が表示されるので修正

これで完了かな。

次に、PythonでGraphitiを使用していく。
まず最初にOpenAI APIキーを環境変数にセットしておく。
export OPENAI_API_KEY=XXXXXXXX
次に、データベースにアクセスして、Graphitiのインデックスを初期化して、データを登録する。なお、この登録するデータのことをGraphitiでは「エピソード」と読んでいる。
from graphiti_core import Graphiti
from graphiti_core.nodes import EpisodeType
from datetime import datetime
import asyncio
async def main():
# Graphitiをメモリレイヤーとして初期化
graphiti = Graphiti("bolt://localhost:7687", "neo4j", "password")
# エピソードの内容
episodes = [
"カマラ・ハリスはカリフォルニア州の司法長官です。",
"彼女は、以前はサンフランシスコの地方検事でした。",
"ハリスは、司法長官として、2011年1月3日から2017年1月3日まで在任していました。"
]
try:
# Graphitiのインデックスを初期化。初回に一度だけ行う必要がある。
await graphiti.build_indices_and_constraints()
# エピソードを追加
for i, episode in enumerate(episodes):
await graphiti.add_episode(
name=f"ヤバい経済学ラジオ {i}",
episode_body=episode,
source=EpisodeType.text,
source_description="ポッドキャスト",
reference_time=datetime.now()
)
except Exception as e:
print(f"エラー: {e}")
finally:
# Graphitiとの接続を閉じる
await graphiti.close()
if __name__ == "__main__":
asyncio.run(main())
この時以下のようなWarningが多数出るのだが、どうやらこれはNeo4j Desktopでだけ起きるものらしく、Dockerでは起きないらしい。おぅ、、ではなぜNeo4j Desktopを紹介したのか、、、という思いもあるが、とりあえず気にしないことにする。
Received notification from DBMS server: {severity: WARNING} {code: Neo.ClientNotification.Statement.UnknownPropertyKeyWarning} {category: UNRECOGNIZED} {title: The provided property key is not in the database} {description: One of the property names in your query is not available in the database, make sure you didn't misspell it or that the label is available when you run this statement in your application (the missing property name is: content)} {position: line: 4, column: 18, offset: 143} for query: '\n MATCH (e:Episodic) WHERE e.valid_at <= $reference_time \n AND ($group_ids IS NULL) OR e.group_id in $group_ids\n RETURN e.content AS content,\n e.created_at AS created_at,\n e.valid_at AS valid_at,\n e.uuid AS uuid,\n e.group_id AS group_id,\n e.name AS name,\n e.source_description AS source_description,\n e.source AS source\n ORDER BY e.created_at DESC\n LIMIT $num_episodes\n '
Neo4j Desktop側で確認してみる。Neo4j Browserを開く。

まるっと検索してみる。以下のCypherクエリを入力して実行。
MATCH (n)-[r]->(m) RETURN n, r, m
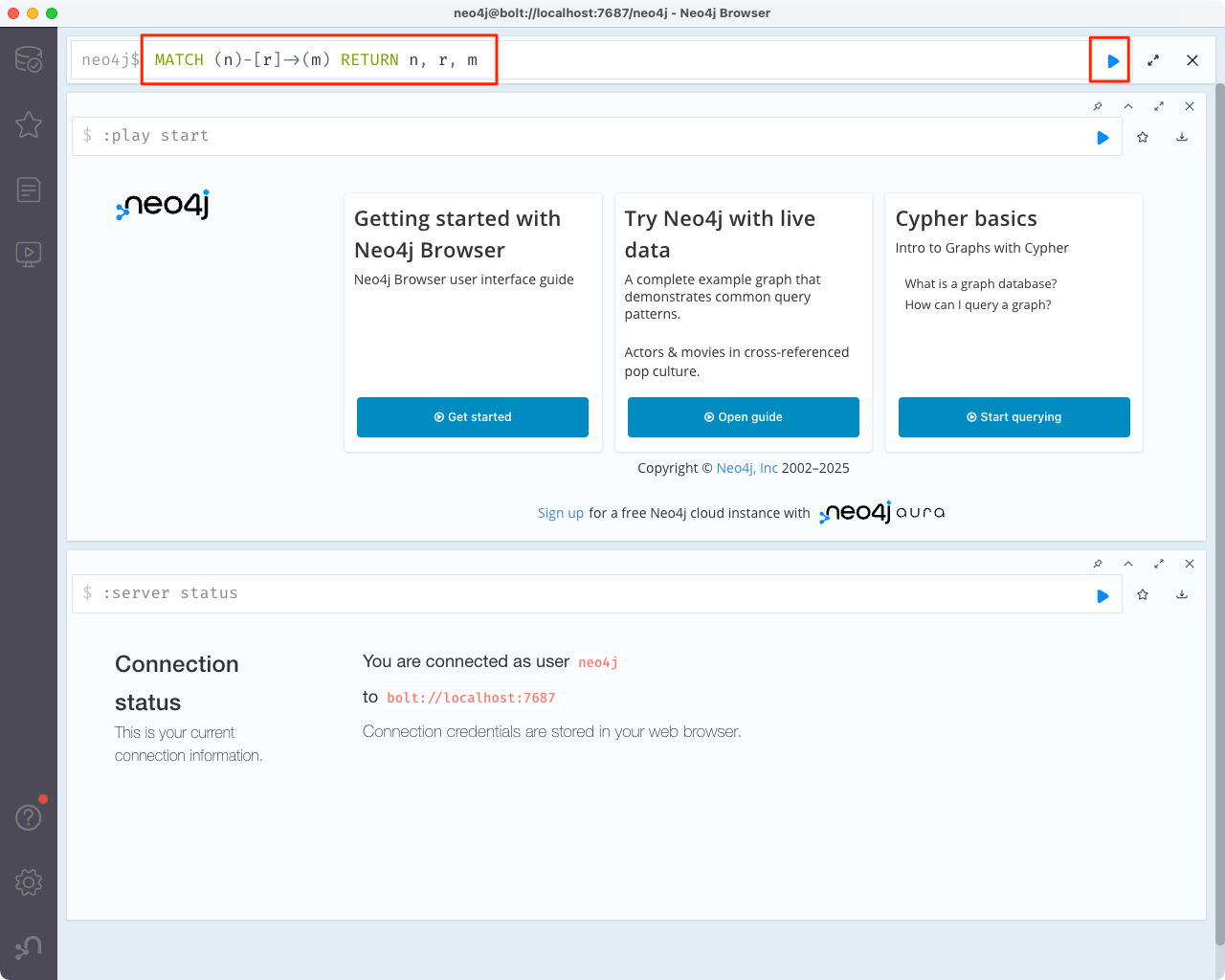


グラフが作成されているのがわかる(このグラフが正しいのかは置いといて)。
次に検索
from graphiti_core import Graphiti
import asyncio
async def main():
graphiti = Graphiti("bolt://localhost:7687", "neo4j", "password")
try:
results = await graphiti.search('カリフォルニア州の司法長官は誰?')
except Exception as e:
print(f"エラー: {e}")
finally:
await graphiti.close()
if results:
for result in results:
print(result.model_dump_json(indent=2))
else:
print("検索結果が見つかりませんでした。")
if __name__ == "__main__":
asyncio.run(main())
uv run search.py
{
"uuid": "4357b7bb-2493-48ef-a278-cabe96c171e6",
"group_id": "",
"source_node_uuid": "5aec0eff-9bfe-4d53-8513-17091626c34f",
"target_node_uuid": "68240f6b-d20b-4329-ae2e-79af86e1f871",
"created_at": "2025-04-06T14:12:32.358359Z",
"name": "IS_IN",
"fact": "カマラ・ハリスはカリフォルニア州の司法長官である。",
"fact_embedding": [
0.03075936809182167,
-0.0012498897267505527,
0.013762726448476315,
(snip)
0.008074338547885418,
-0.018548788502812386,
-0.03398196026682854
],
"episodes": [
"ba804e09-93a8-4355-a88e-53d84bdd4f0e"
],
"expired_at": "2025-04-06T14:12:56.582257Z",
"valid_at": "2011-01-03T00:00:00Z",
"invalid_at": "2017-01-03T00:00:00Z"
}
検索はセマンティック検索とBM25を組み合わせたハイブリッドで行われ、Reciprocal Rank Fusionで理ランキングされているらしい。
BM25で日本語を使う場合にはトークナイザーが必要だと思うのだけど、対応しているのかな?
BM25で日本語を使う場合にはトークナイザーが必要だと思うのだけど、対応しているのかな?
この辺を見る限りは、Neo4j自体がBM25に対応しているみたい。
Neo4jのドキュメントだとこの辺かな
ふむ、Neo4jのデフォルトで日本語に対応しているかはわからないけど、少なくとも対応できる余地がありそう。あとはGraphitiがこれを踏まえているか・・・多分この辺。
んー、現状はそこまでは考慮されていないかも。とはいえ、ベクトル検索なら問題ないだろうし、ある程度は動く気はする。
いかにもコメントあるけど、きっちり多言語対応ってのはこれからかなと感じる。
ここまでの所感
GraphitiはGraphRAGそのものではないと思うけども、GraphRAGのエッセンスはなんとなく含まれているように思えるし、GraphRAGが苦手とする「更新」に強いってのがウリだと思う。
自分は以前から、ナレッジグラフはドキュメント検索よりもメモリ検索のほうが向いていると思っていて、長期記憶としてZepのようなライブラリ・プラットフォームでGraphitiが使われるのは納得感がある。
現状、日本語でどこまできちんと使えるか?は厳しそうな気はするが、大いに期待したいところ。
そうそう、GraphitiはMCPサーバを提供している。
Graphiti MCP サーバー
Graphiti は、時間認識型の知識グラフを構築および照会するためのフレームワークで、動的環境で動作するAIエージェント向けに特別に調整されています。従来の検索拡張生成(RAG)手法とは異なり、Graphitiはユーザーとの対話、構造化および非構造化企業データ、外部情報を一貫性のある照会可能なグラフに継続的に統合します。このフレームワークは、増分データ更新、効率的な検索、および精密な履歴クエリをグラフの完全な再計算を必要とせずにサポートし、インタラクティブでコンテキスト認識型AIアプリケーションの開発に適しています。
これは実験的なモデルコンテキストプロトコル(MCP)サーバーのGraphiti実装です。MCPサーバーはGraphitiのキーとなるAI機能をMCPプロトコルを通じて公開し、AIアシスタントがGraphitiの知識グラフ機能と対話できるようにします。
特徴
Graphiti MCPサーバーは、Graphitiの以下の主要な高レベル機能を公開しています:
- エピソード管理:エピソード(テキスト、メッセージ、またはJSONデータ)の追加、取得、削除
- エンティティ管理:知識グラフ内のエンティティノードと関係の検索および管理
- 検索機能:意味的およびハイブリッド検索を使用した事実(エッジ)とノードの要約の検索
- グループ管理:group_idフィルタリングによる関連データのグループの整理と管理
- グラフメンテナンス:グラフのクリアとインデックスの再構築
Dockerでセットアップすれば簡単に長期メモリの機能を追加できそう。ということでやってみる。SSEで。
レポジトリをクローン
git clone https://github.com/getzep/graphiti && cd graphiti
mcp_serverディレクトリに移動
cd mcp_server
.envを雛形から作成。
cp -pi .env.local .env
色々書いてあるけど、以下だけ修正すればOK。
OPENAI_API_KEY=XXXXXXXXXXX
MODEL_NAME=gpt-4.1-mini
docker composeで起動
docker compose up -d
MCPクライアントに以下の設定を追加。今回はDiveを使った。Claude DesktopだとJSONのエラーになる。。。
{
"mcpServers": {
"graphiti": {
"transport": "sse",
"url": "http://localhost:8000/sse"
}
}
}
こんな感じでやりとり。もっとこういい感じに記憶してほしいんだけど、Diveだと明示的に言わないとMCPサーバを使ってくれない印象がある。他のMCPクライアントだと変わるかも。

こういうグラフになっていた。

まとめ
前回Zep経由でGraphitiを触っていたのだけども、今回Graphitiを単体で触ってみて、なんでZepって必要なんだっけー?とか思ってしまった。改めて見てみると、LLMチャットというところによりインテグレーションされてるのがZepなのかな?という印象。ただGraphiti単体で触ってみた感じだと、記憶バックエンドとしてGraphitiを使って、LLMチャット周りは自分で実装してもいいんじゃないか?という気もするね。あまりZepを使う利点を見いだせなかった。
MCPで使うのは良さそうに思う。ただ自分は以前Zepを試したあとに、Neo4jを色々触ったり、ナレッジグラフベースのRAGフレームワークをいくつかいじったりしたものの、まだこう腹落ち感がないというか・・・。ナレッジグラフ、片手間でやるには難しすぎて、かつ、運用も大変そう、そして日本語でちゃんとできるのか?という懸念が今も自分の中にはあって。MCPで使うならあまりそういう事は考えずに手放しで使いたい感じなので、ちょっとモヤモヤしながら使う感じになりそう・・・・