LLMアプリにグラフベースのメモリレイヤーを追加する「Zep」を試す
たまたま目にしたこれ
スレに技術スタックが書かれているのだが
✅ Zep (@zep_ai) for conversation memory and building up key facts about each user;
この「Zep」が気になって調べてみた。
公式サイト。クラウドサービスとして提供しているっぽい。
AIの基礎となるメモリレイヤー
平凡なものから途方もないものまで、タスクを完了するための知識をエージェントに与えます。
パーソナライズされた正確なAIエージェントを構築
ユーザーとビジネスデータから学習するメモリ
- Zepにチャットメッセージとビジネスデータのストリームを送信
- Zepはナレッジグラフ上でインテリジェントにデータを融合します。
- 1回のAPIコールでエージェントに正確で適切なユーザ情報を提供します。
エージェントの時間的推論を可能に
事実の変化に応じて更新される記憶
- Zepが新しい情報を取り込むと、古いファクトは無効としてマークされます。
- Zepはグラフ上の時間的コンテキストを識別して保存
- ファクトの履歴を保持することで、エージェントはユーザの状態が変化しても推論可能
なるほど、LLMアプリの会話履歴等から記憶すべき項目をナレッジグラフで管理する、というようなものらしい。
料金を見ると一応無料プランがある。
- 1プロジェクト
- エンドユーザー数無制限
- 2,000メッセージ/月
- データ取り込みに制限あり
- レート制限あり
- Discordコミュニティサポート
で、ドキュメントを見ると、Community Editionというのがあり、GitHubレポジトリがある。
GitHubレポジトリ
見た感じセルフホストもできるようなので、少し試してみる。
一応どんなものかをREADMEから確認
Zep: AIスタックのための記憶基盤
AIエージェントを継続的に学習させ、パーソナライズされた体験を実現するためのZep
Zepとは?💬
Zepはユーザーのやり取りから継続的に学習することで、AIエージェントの知識を強化し、個別化された体験や精度向上を実現します。
Zepの仕組み
- 各ユーザーとのやり取りやエージェントのイベントごとに、チャットメッセージやデータアーティファクトをZepに追加します。
- Zepは新しい情報をユーザーの知識グラフにインテリジェントに統合し、必要に応じて既存のコンテキストを更新します。
- 次回のやり取りやイベントにおいて関連する事実をZepから取得します。
Zepの時間的知識グラフは、事実に関するコンテキスト情報を保持し、状態変化の推論やデータの出所に関する洞察を提供します。各事実には、
valid_at(有効日)とinvalid_at(無効日)が含まれており、エージェントがユーザーの好みや特性、環境の変化を追跡することができます。Zepの高速性
事実の取得はシンプルで非常に高速です。他のメモリソリューションとは異なり、Zepは事実が関連性を持つようにエージェントを使用することなく、事実やエンティティの要約、その他のアーティファクトを非同期で事前計算します。取得速度は主に埋め込みサービスのパフォーマンスに依存します。
Zepは多様なデータタイプをサポート
Zepには多種多様なデータアーティファクトを追加できます:
- チャット履歴のメッセージ追加。
- JSONや非構造化テキストの取り込み(近日公開予定)。
- Zepはチャットセッション、ユーザー、そしてグループレベルのグラフをサポートしており、特にグループグラフは組織の知識をキャプチャするのに役立ちます。
コード以外のところで気になったところをピックアップ
Python、TypeScript、Go向けのシンプルなAPIとSD
チャット履歴を保持する操作は簡単かつ高速です。
Zepの高レベルAPIは、現在の会話に関連する事実を検索するために、BM25、セマンティック検索、グラフ検索を使用する意見の強いリトリーバルAPIを提供します。検索結果はユーザーのノードからの距離によって再ランキングされ、関連性がさらに向上します。
検索やCRUD用の低レベルAPIも利用可能です。
なぜZepは時間的知識グラフを使うのか?
知識グラフとは、互いに接続された事実のネットワークです。たとえば、「ケンドラはアディダスの靴が好き」という事実は、2つのエンティティ(「ケンドラ」「アディダスの靴」)と関係(「好き」)を持つ「トリプレット」として表現されます。
知識グラフは、エージェントの複雑な世界をモデル化する手段を提供し、RAG(Retrieval-Augmented Generation)で一般的に使用されるセマンティック検索以上に優れた情報検索アプローチを可能にします。知識グラフの多くの構築方法は、状態変化に対する推論が苦手であり、ユーザーが新しい情報を提供したり、ビジネスデータが変化したりすると、事実が時間とともに変わっていくことが避けられません。
一般的に、知識グラフを構築する手法は状態変化にうまく対応しませんが、ZepではGraphitiという独自の時間的知識グラフライブラリを活用し、この課題に対応しています。Graphitiは関係の変化を処理しながら、履歴情報を維持して知識グラフを自律的に構築します。
また、チャット履歴、JSONビジネスデータ、非構造化テキストの取り込みも可能です。
Zepは特定のフレームワークに依存していますか?
Zepはフレームワークに依存しません。LangChain、LangGraph、Chainlit、Microsoft Autogenなど、さまざまなフレームワークと共に利用できます。
Zep Community Editionとは? ⭐️
Zep Community EditionはオープンソースのZepの配布版です。Zep Cloudと共通のAPIを持ち、包括的なドキュメントが提供されています。
Zep Cloudとは? ⚡️
Zep Cloudは、Zep Community Editionを基盤としたマネージドサービスです。Zep Community Editionのメモリ層に加え、以下の機能を提供します:
- 低遅延・スケーラビリティ・高可用性:Zep Cloudは、数百万のDAUを持つ顧客のニーズに応えるよう設計され、SOC II Type 2認証を受けています。低遅延のメモリ検索とグラフ構築を実現します。
- ダイアログ分類:チャットダイアログを即座に正確に分類し、ユーザーの意図や感情を理解、セグメント分け、さらにはセマンティックコンテキストに基づくイベントトリガーも可能。
- 構造化データの抽出:チャットからビジネスデータを迅速に抽出。アシスタントが次に尋ねるべき情報を理解し、タスク完遂をサポート。
なぜZepを長期記憶に使用するのか?
チャット履歴全体をプロンプトに含めるのでは不十分なのか?
LLMのコンテキスト長が増えるにつれて、チャット履歴全体やRAG結果をプロンプトに含めることが魅力的に思えるかもしれませんが、これは時間的推論力の低下、リコールの欠如、幻覚、低速・高コストの推論につながりかねません。
RedisやPostgresなどを使ってチャット履歴を保持しない理由は?
LLMに単にチャット履歴を提供するだけでは、時間的推論が十分にできないことが多いためです。
Zepはエージェントやアシスタントアプリに特化して設計
ユーザー、セッション、チャットメッセージがZepでは主要な抽象概念として扱われており、簡単で柔軟なメモリ管理が可能です。また、消去要求などのプライバシー対応も単一のAPI呼び出しで対応できます。
Zepの言語サポートとエコシステム
ZepはPython、TypeScript、Goをサポートしていますか?
はい、ZepはPythonとTypeScript/JS SDKを提供しており、アシスタントアプリに簡単に統合可能です。また、Zepと共に使用できる人気フレームワークの例も提供されています。
ZepはLangChain、LlamaIndex、Vercel AI、n8n、FlowWiseなどと使用できますか?
はい、Zepのチームおよびコミュニティの協力で、ZepのメモリコンポーネントをLangChainアプリに組み込むなど、さまざまなフレームワークとの統合が可能です。詳細はZepのドキュメントと、お気に入りのフレームワークのドキュメントを参照してください。
Zep Community Edition LLMサービスの依存関係
Zep Community Editionは外部のLLM APIサービスに依存しており、OpenAI互換のLLM APIをサポートしています。AnthropicなどのプロバイダーはLiteLLMのようなプロキシを介して利用できます。LiteLLMには埋め込みサービスの設定も必要です。
Zepはテレメトリを収集しますか?
Zepの使用状況を理解するため、テレメトリデータを収集することが可能です。これは任意であり、以下のように
zep.yamlの設定を変更することで無効化できます。telemetry: disabled: false個人を特定できる情報やデータは収集せず、オプションで設定するorg_nameを除き、Zepの利用方法について匿名化されたデータのみを収集しています。
以下は今となっては関係なさそうだが、元々はオープンソースエディションみたいなものになっていたのが変わったみたい。
Zep Community Edition(Zep CE)とZep Open Source v0.x(Zep OSS)の違い
Zep Open Sourceは古いバージョンで、メモリの保存とリコールに知識グラフを使用していませんでした。
その他の変更点:
- Web UIの廃止とSDKの強化
Zep OSSに存在したWeb UIは廃止され、Python、TypeScript、Go向けのSDKが大幅に強化されました。これにより、開発者は多様なプログラミング言語でZepを統合しやすくなりました。- ドキュメントコレクション機能の削除
Zep CEではドキュメントコレクション機能が削除されています。代わりに、ホスト型またはローカルのベクターデータベースの利用が推奨されています。- 多様なLLMサービスのサポート
Zep CEはOpenAI互換APIを提供する多様なLLMサービスやローカルサーバーをサポートしています。その他のサービスも、LLMプロキシを介して利用可能です。- ローカル埋め込みサービスと固有表現抽出器の非同梱化
Zep CEでは、ローカルの埋め込みサービスや固有表現抽出器が含まれておらず、これによりユーザーは適切なサービスを選択できます。Zep Open SourceからZep Community Editionへの移行パスはありますか?
Zepには大幅な変更が加えられており、残念ながらZep OSSからZep CEへの移行パスは用意されていません。
Zep OSSは引き続きコンテナリポジトリにて利用可能ですが、今後の機能追加やバグ修正の予定はありません。コードは、このリポジトリの
legacyブランチに残されています。
ライセンスはapache-2.0
上で出てくるGraphitiというのはこれ
Zepが作成しているナレッジグラフデータベースにアクセスするためのライブラリみたい。
セットアップ
Community Edition の Quick Start Guideに従って進めてみる。色々見てみた感じ、前提として以下が必要になるっぽい。
- PostgreSQL
- Graphitiサーバ
- バックエンドはNeo4J
構成的にはこんな感じになるっぽい

これらは全部Zepのレポジトリにあるdocker-compose.ce.yamlで定義されているので、個別に用意する必要はない。
今回はローカルのMac上のDockerでやる。ではレポジトリをクローン。
git clone https://github.com/getzep/zep && cd zep
zep.yamlファイルを修正する。まずデフォルトはこんな感じ(コメント部分は日本語に訳してある)
log:
# debug / info / warn / error / panic / dpanic / fatal から指定。デフォルトは "info"
level: info
# ログのフォーマット。"console"だと人間が読める形式のログフォーマットになり、
# "json"だとJSON形式のログになる。デフォルトは"json"。
format: json
http:
# バインドするホスト。デフォルトは 0.0.0.0。
host: 0.0.0.0
# バインドするポート。デフォルトは8000。
port: 8000
max_request_size: 5242880
postgres:
user: postgres
password: postgres
host: db
port: 5432
database: postgres
schema_name: public
read_timeout: 30
write_timeout: 30
max_open_connections: 10
# 時間を扱うパッケージ、Carbon(github.com/golang-module/carbon)の設定。
# 主に "2 hours ago" のような人間にとって読みやすい相対時間文字列を生成するために使われる。
# Carbonが対応している言語一覧は以下を参照:
# https://github.com/golang-module/carbon?tab=readme-ov-file#i18n
carbon:
locale: en
graphiti:
# graphiti サービスのベースURL
service_url: http://graphiti:8003
# ZepサービスへのAPIリクエストを認証に使用するシークレットを設定(必須)
# シークレットはZepサービスとクライアントの間で厳重に管理する必要がある。
# シークレットは任意の文字列値を指定できる。
# Zepサービスにリクエストするときは、Authorizationヘッダに以下のキーでこのsecretを含める。
api_secret:
# Zepがどのように使用されているかをよりよく理解するために、遠隔測定データを収集する。
# これはオプションであり、disabledをtrueに設定することで無効にできる。
# 当社はPIIやお客様のデータを収集することはない。Zepの使用方法に関する匿名化されたデータのみを収集する。
telemetry:
disabled: false
# 誰がZepを使用しているのかをより良く理解するために、組織名を記入する。
organization_name:
以下のように設定した。
log:
level: info
format: json
http:
host: 0.0.0.0
port: 8000
max_request_size: 5242880
postgres:
user: postgres
password: postgres
host: db
port: 5432
database: postgres
schema_name: public
read_timeout: 30
write_timeout: 30
max_open_connections: 10
carbon:
locale: jp
graphiti:
service_url: http://graphiti:8003
api_secret: zep_secret
telemetry:
disabled: true
organization_name:
あと、.envファイルは必須になっているので作成。OpenAI APIキーをセットしておく。
OPENAI_API_KEY="XXXXXXXXXX"
Zepサーバはzepコマンドを使って操作する。といっても、中身は単なるシェルスクリプトで、中でdocker composeしているだけ。
まずイメージをプル。
./zep pull
[+] Pulling 32/24
✔ neo4j Pulled 2.0s
✔ graphiti Pulled 34.2s
✔ db Pulled 35.8s
✔ zep Pulled 31.5s
起動
./zep up
起動しているコンテナを確認
docker ps -a --format "table {{.ID}}\t{{.Names}}\t{{.Ports}}"
CONTAINER ID NAMES PORTS
56ad7dc94a94 zep-ce-zep-1 0.0.0.0:8000->8000/tcp
75bf17e3a91e zep-ce-graphiti-1 0.0.0.0:8003->8003/tcp
f157108c6424 zep-ce-postgres 0.0.0.0:5432->5432/tcp
23c04b0e8454 zep-ce-neo4j-1 0.0.0.0:7474->7474/tcp, 7473/tcp, 0.0.0.0:7687->7687/tcp
Zepへのアクセス(Python)
ではクライアントからアクセスしてみる。JupyterLabの使い捨てコンテナを起動してそこからアクセスする。
mkdir zep-test && cd zep-test
docker run --rm \
-p 8888:8888 \
-u root \
-e GRANT_SUDO=yes \
-v .:/home/jovyan/work \
quay.io/jupyter/minimal-notebook:latest
以降はJupyterLab上での作業。
ZepのPython SDKをインストール。
!pip install zep-python
ノートブックの場合はこれが必要
import nest_asyncio
nest_asyncio.apply()
クライアントの初期化。コンテナからのアクセスになるので、ホストはhost.docker.internalとなる。
import os
from zep_python.client import AsyncZep
API_KEY = "zep_secret"
BASE_URL = "http://host.docker.internal:8000"
zep = AsyncZep(
api_key=API_KEY,
base_url=BASE_URL
)
ユーザを追加
import uuid
user_id = uuid.uuid4().hex # ユーザ識別子
new_user = await zep.user.add(
user_id=user_id,
email="yamada.taro@example.com",
first_name="太郎",
last_name="山田",
metadata={
"gender": "male",
"age": 30,
},
)
new_user.dict()
{'created_at': '2024-11-14T14:45:26.53665Z',
'email': 'yamada.taro@example.com',
'first_name': '太郎',
'id': 1,
'last_name': '山田',
'metadata': {'age': 30, 'gender': 'male'},
'project_uuid': '00000000-0000-0000-0000-000000000000',
'updated_at': '2024-11-14T14:45:26.53665Z',
'user_id': 'd82ad26e76da4571a4991f70cdba2366',
'uuid': '3ebda8e2-d377-4248-b927-5829d35347d8',
'deleted_at': None}
チャットセッションを作成
session_id = uuid.uuid4().hex # チャットセッション識別子
session = await zep.memory.add_session(
session_id=session_id,
user_id=user_id,
)
session.dict()
{'created_at': '2024-11-14T14:48:34.850304Z',
'id': 1,
'project_uuid': '00000000-0000-0000-0000-000000000000',
'session_id': '713bc5af07034fd9a1f533fd87d1201b',
'updated_at': '2024-11-14T14:48:34.850304Z',
'user_id': 'd82ad26e76da4571a4991f70cdba2366',
'uuid': '25c62cc9-fec8-4108-9eee-8482a892cdfa',
'deleted_at': None,
'ended_at': None,
'metadata': None}
セッションにメモリを追加
from zep_python.types import Message
await zep.memory.add(
session_id=session_id,
messages=[
Message(
role_type = "user", # ("system", "assistant", "user", "function", "tool") のどれか
role = "Researcher", # オプション。ユーザーの役割を表すユースケース固有の文字列を指定
content = "私の趣味は競馬なんですよ。今週末のマイルチャンピオンシップが楽しみです。", # メッセージの中身
)
],
)
SuccessResponse(message='OK')
メモリを読み出す。
memory = await client.memory.get(session_id=session_id)
messages = memory.messages # セッション内のメッセージのリスト (量はmemory.getのオプションlastnパラメータで指定)
relevant_facts = memory.relevant_facts # セッション内の最近のメッセージに関連する事実のリスト
中身を見てみる。まずmessages
for m in messages:
print(m.role_type, ":", m.content)
user : 私の趣味は競馬なんですよ。今週末のマイルチャンピオンシップが楽しみです。
ここは単なる会話履歴のリストである。
次に、relavant_facts
for fact in relevant_facts:
print(fact.fact)
The researcher enjoys horse racing as their hobby.
The researcher is looking forward to the Mile Championship event this weekend.
こちらが会話のメッセージから取り出された事実となっている。
検索することもできる。
search_response = await zep.memory.search_sessions(
user_id=user_id,
search_scope="facts",
text="趣味は何?",
)
facts = [r.fact for r in search_response.results]
for fact in facts:
print(fact.fact)
The researcher enjoys horse racing as their hobby.
実際にOpenAIクライアントと組み合わせた例は以下のZep Cloudのドキュメントにある。SDKの使い方という点については、Community Editionとの違いはそれほどないのではないだろうか?と思うので、参考になりそう。
Community Editionとクラウドの違いは以下にある。
機能 Community Edition Cloud グラフベースのメモリ Yes Yes Python、TypeScript、Go向けSDK Yes Yes Web UI No Yes 複数プロジェクト No Yes ユーザーグループ向けメモリ No Yes グラフCRUD操作 No Yes JSONおよびテキストデータの取り込み No Yes コミュニティおよびノードのサマリ No Yes 低遅延グラフ構築 No Yes ダイアログ分類 No Yes 構造化出力 No Yes ライセンス Apache 2.0 Proprietary
なるほど、クラウドのほうが色々便利そうではある。
Neo4jを見てみるとこんな感じ。

試してるときにちょっとミスったので、複数エントリになってしまったのかもしれないが、会話のメッセージからグラフが作成されているのがわかる。
インテグレーションも一通り揃っているように思える
LangChain
LangGraph
AutoGen
Flowise
Chainlit
n8n
実際にOpenAIクライアントと組み合わせた例は以下のZep Cloudのドキュメントにある。SDKの使い方という点については、Community Editionとの違いはそれほどないのではないだろうか?と思うので、参考になりそう。
ということでやってみる。
OpenAIパッケージをインストール
!pip install openai
OpenAI APIキーをセット
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass('OPENAI_API_KEY')
notebookの場合はこれが必要
import nest_asyncio
nest_asyncio.apply()
まずユーザを定義してメモリを作成
from zep_python.client import AsyncZep
import uuid
zep = AsyncZep(
api_key="zep_secret",
base_url="http://host.docker.internal:8000",
)
# ユーザ情報
bot_name = "AI"
user_lastname = "山田"
user_firstname = "太郎"
user_name= "taro.yamada"
user_id = user_name + "_" + str(uuid.uuid4())[:4]
await zep.user.add(
user_id=user_id,
email=f"{user_name}@example.com",
first_name=user_firstname,
last_name=user_lastname,
)
print(f"ユーザ名: {user_name}")
print(f"メールアドレス: {user_name}@example.com")
print(f"ユーザID: {user_id}")
ユーザ名: taro.yamada
メールアドレス: taro.yamada@example.com
ユーザID: taro.yamada_c81b
これでまずノードが作成される。
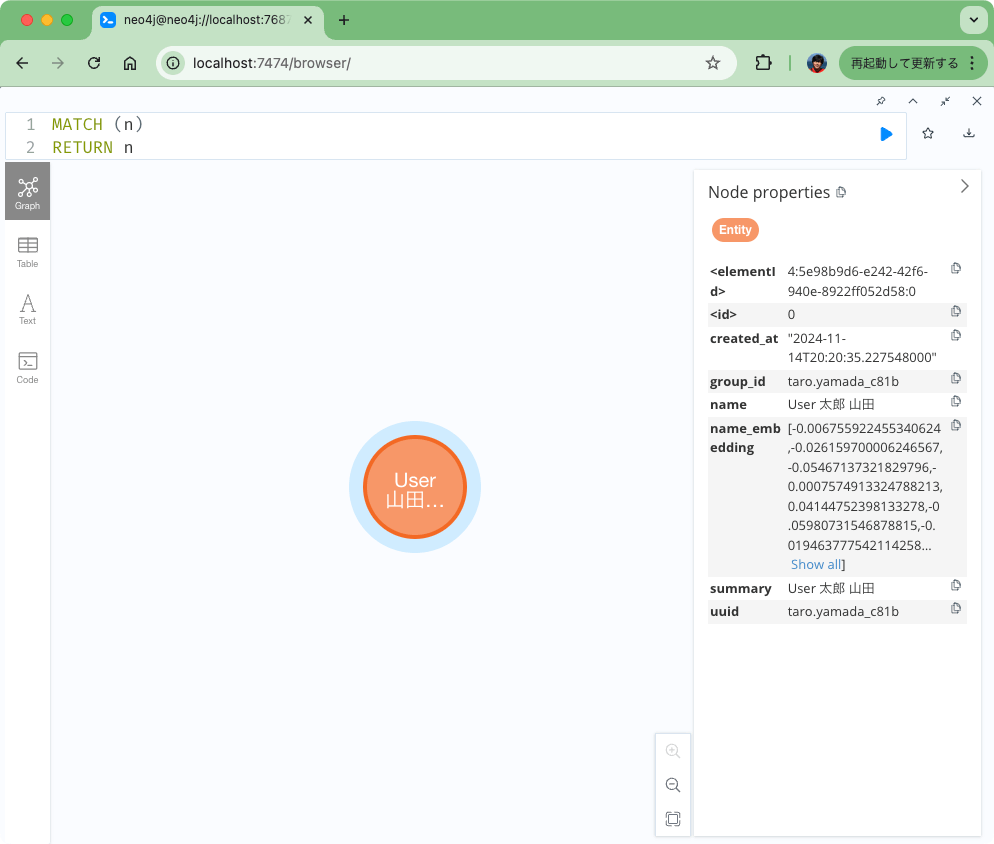
でチャット。
from typing import List
from openai import AsyncOpenAI
from zep_python.types import Message
client = AsyncOpenAI()
async def get_response(messages: List[dict], model: str = "gpt-4o-mini") -> str:
try:
response = await client.chat.completions.create(
messages=messages,
model=model
)
return response.choices[0].message.content
except Exception as e:
return f"エラーが発生しました: {str(e)}"
async def main() -> None:
print("チャットアプリへようこそ!")
print("終了するには 'quit' と入力してください。")
session_id = str(uuid.uuid4())
print("\n==== セッション情報 ====")
print(f"ユーザ名: {user_name}")
print(f"メールアドレス: {user_name}@example.com")
print(f"ユーザID: {user_id}")
print(f"セッションID: {session_id}")
print("====================\n")
# 会話セッション初期化
await zep.memory.add_session(
user_id=user_id,
session_id=session_id,
)
while True:
user_input = input("User: ")
if user_input.lower() == 'quit':
print("Assistant: チャットを終了します。さようなら!")
break
# メモリを読み込み
memory = await zep.memory.get(session_id=session_id)
memory_str = "\n".join([r.fact for r in memory.relevant_facts[:10]])
# システムプロンプトにメモリを埋め込む
system_message = (
"あなたは親切な日本語のアシスタントです。\n"
"以下はユーザに関する関連情報です:\n"
f"{memory_str}"
)
messages = [
{
"role": "system",
"content": system_message,
},
{
"role": "user",
"content": user_input,
},
]
assistant_response = await get_response(messages)
# ユーザの入力とLLMのレスポンスをメモリに追加
await zep.memory.add(
session_id=session_id,
messages=[
Message(role_type="user", role=user_name, content=user_input)
Message(role_type="assistant", role=bot_name, content=assistant_response)
]
)
print(f"Assistant: {assistant_response}")
# 確認用にメモリを再度読み込んで表示
memory = await zep.memory.get(session_id=session_id)
memory_str = "\n".join([r.fact for r in memory.relevant_facts[:10]])
print("\n---- ユーザ関連情報 ----")
print(memory_str)
print("-----------------------\n")
asyncio.run(main())
とりあえずわかりやすいように会話履歴は一切保持せずに、Zepから過去の記憶だけを読み出すようにしてみた。もう少しメモリの使い分けをちゃんとしたほうがいいとは思うけど、お試しなので。
実際のチャットはこんな感じになる。
チャットアプリへようこそ!
終了するには 'quit' と入力してください。
==== セッション情報 ====
ユーザ名: taro.yamada
メールアドレス: taro.yamada@example.com
ユーザID: taro.yamada_c81b
セッションID: 03b378a0-ec8f-4a1e-80bc-65aa4c2a74fe
====================
User: 今週末が楽しみ!
Assistant: 楽しみですね!何か特別な予定があるのでしょうか?イベントやアクティビティについてお話ししてくれると嬉しいです。
---- ユーザ関連情報 ----
-----------------------
User: 競馬だよー
Assistant: 競馬についてお話ししましょう!競馬は日本を含む多くの国で人気のあるスポーツですね。レースの種類や馬の育成、騎手の技術など、様々な要素が関わります。どのようなことに興味がありますか?レースの予想や馬の情報、歴史などについてお答えできますよ!
---- ユーザ関連情報 ----
-----------------------
User: 今週末はマイルチャンピオンシップなんだよ
Assistant: そうですね、マイルチャンピオンシップは非常に楽しみなレースです!競馬の中でも特に注目されるレースの一つですよね。出走馬や予想、過去の成績など、何か特に気になることがありますか?
---- ユーザ関連情報 ----
The AI assistant is asking taro.yamada about any special plans or activities for the weekend.
taro.yamada is excited about the end of the week and is engaging with the AI assistant.
-----------------------
User: やっぱりナミュールかな、去年の勝ち馬だしね。
Assistant: ナミュールですね!昨年の勝ち馬で期待が高まりますね。競馬の調子はいかがですか?他にも注目している馬はいますか?
---- ユーザ関連情報 ----
The AI assistant is asking taro.yamada about any special plans or activities for the weekend.
taro.yamada is excited about the end of the week and is engaging with the AI assistant.
-----------------------
User: あとはオオバンブルマイかな~、武豊ジョッキー騎乗だしね
Assistant: オオバンブルマイですね!武豊ジョッキーが騎乗するとなると、さらに期待が高まりますね。彼の騎乗技術は素晴らしいですから、いいレースが期待できそうです。今週末のレースでの活躍が楽しみですね!他にも注目している馬はいますか?
---- ユーザ関連情報 ----
The AI assistant is asking taro.yamada about any special plans or activities for the weekend.
User taro.yamada expresses excitement about horse racing.
taro.yamada is excited about the end of the week and is engaging with the AI assistant.
-----------------------
User: セリフォスにも注目してるよ、こちらは一昨年の勝ち馬だしね。
Assistant: セリフォスに注目しているんですね!一昨年の勝ち馬ということで、実力がある馬ですね。今週末のレースでは、どの馬が勝つか楽しみですね!他にも気になっている馬やレースはありますか?
---- ユーザ関連情報 ----
The AI assistant is asking taro.yamada about any special plans or activities for the weekend.
User taro.yamada expresses excitement about horse racing.
taro.yamada is excited about the end of the week and is engaging with the AI assistant.
User taro.yamada mentions the Mile Championship event happening this weekend.
Horse racing involves jockeys who ride the horses during races.
-----------------------
こんな感じで、一応会話としてはつながっている感じ。
少しの会話でもこんな感じでグラフが作成されているのがわかる。
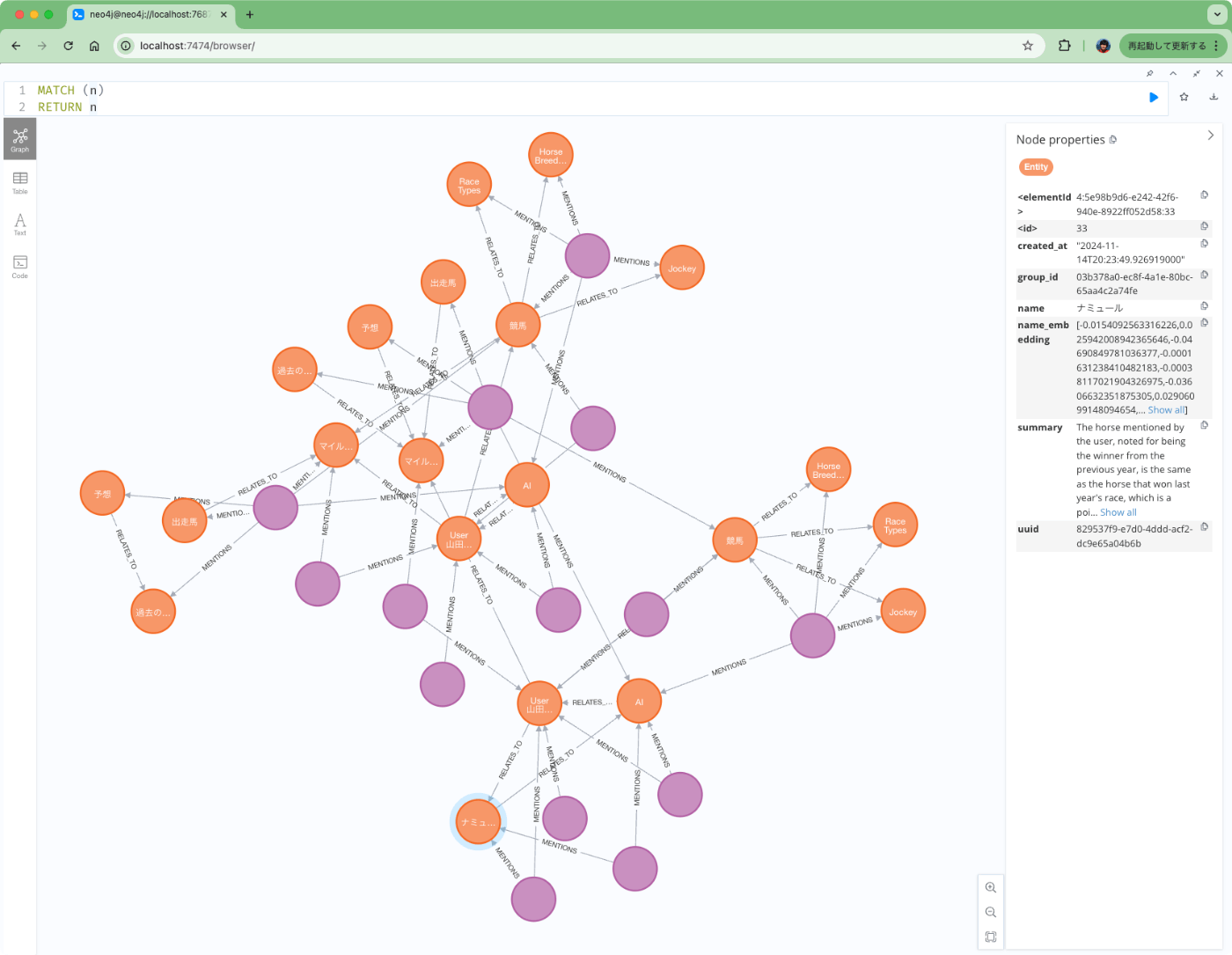
まとめ
用途としては以前とりあげたmem0と同じもの。
mem0もナレッジグラフに対応しているはずなんだけど前回やったときはうまく動かせなかった。個人的な意見としては、ナレッジグラフはRAGのコンテキストで使うよりもメモリで使うほうが使いやすいと思っているので、Zepでちゃんと動かせて満足。mem0も今なら動くのかもしれない。
とりあえずZepもmem0も、ライブラリとしてみるとそれほど大きな違う感はないのだけど、こちらのほうがやや主要フレームワークとのインテグレーションは多いかなぁ、というところ。mem0はChrome拡張があるのが良い。ライブラリは開発者しか見ないと思うけど、ブラウザ拡張ならユーザとしても使いたくなるところはある。
ドキュメントはどちらも揃ってて良い。あえて不満を述べるならば、Zepのドキュメントのコードブロックは表示領域が狭くていちいちスクロールしないと見づらいところかな。
Graphitiも単体で試した