オープンソースのRAG UI「kotaemon」を試す
ここで知った。
GitHubレポジトリ
kotaemon
ドキュメントとのチャット用にカスタマイズ可能なオープンソースのクリーンなRAG UIです。エンドユーザーと開発者の両方を念頭に置いて構築されています。
referred from https://github.com/Cinnamon/kotaemonはじめに
このプロジェクトは、ドキュメントのQAを行いたいエンドユーザーと、独自のRAGパイプラインを構築したい開発者の両方にとって、機能的なRAG UIとして役立ちます。
- エンドユーザー向け:
- RAGベースのQA用のクリーンでミニマルなUIです。
- LLM API プロバイダー(OpenAI、AzureOpenAI、Cohere など)とローカルLLM(ollama および llama-cpp-python 経由)をサポートしています。
- インストールスクリプトも簡単です。
- 開発者向け:
- 独自のRAGベースの文書品質保証パイプラインを構築するためのフレームワーク。
- 提供されるUI(Gradioで構築)で、カスタマイズしたRAGパイプラインを実行できます。
主な機能
- 独自の文書QA(RAG)ウェブUIをホストします。マルチユーザーログインをサポートし、プライベート/パブリックコレクションでファイルを整理し、お気に入りのチャットを他のユーザーと共同編集および共有できます。
- LLMと埋め込みモデルを整理します。ローカルLLMと人気のAPIプロバイダー(OpenAI、Azure、Ollama、Groq)の両方をサポートします。
- ハイブリッドRAGパイプライン。ハイブリッド(フルテキストおよびベクトル)検索エンジンと再ランキングによる、最適な検索品質を確保する標準的なRAGパイプライン。
- マルチモーダルQAサポート。図表サポート付きの複数の文書で質問回答を実行します。マルチモーダル文書解析をサポート(UI上で選択可能なオプション)。
- 文書プレビューによる高度な引用。デフォルトでは、LLMの回答の正確性を確保するために、システムが詳細な引用を提供します。引用(関連スコアを含む)は、ハイライト表示とともに、ブラウザ内のPDFビューアで直接確認できます。関連性の低い記事が検索パイプラインから返された場合、警告が表示されます。
- 複雑な推論方法をサポートします。質問分解を使用して、複雑な質問や複数段階の質問に回答します。ReAct、ReWOO、その他のエージェントを使用したエージェントベースの推論をサポートします。
- 設定可能なUI。UI上で、検索および生成プロセスの最も重要な側面を調整することができます(プロンプトを含む)。
- 拡張性があります。Gradioをベースに構築されているため、UI要素を自由にカスタマイズ/追加することができます。また、文書インデックス作成および検索のための複数の戦略をサポートすることを目指しています。GraphRAGインデックスパイプラインが例として提供されています。

日本語で紹介されている方の記事
ドキュメントも用意されている。シンプルに動かしたいだけなら以下の"Getting Started with Kotaemon"にしたがえば良さそう。
上の日本語記事の手順が参考になると思う。
インストール
GitHubの開発者向けのインストール手順に従ってやってみる。
セットアップはLAN内のUbuntu 22.04で。ollamaはすでにインストール済&LLM/Embeddingの両方のモデルも追加済とする。
$ ollama ps
NAME ID SIZE PROCESSOR UNTIL
ezo-humanities-9b-gemma-2-it-imatrix:q8_0 94aa670fc7a5 18 GB 100% GPU Forever
bge-m3:latest 790764642607 1.9 GB 100% GPU Forever
インストール方法としては2つ。
- Dockerイメージから起動
- Dockerなしでpython仮想環境を作成してクローンしたレポジトリから起動
カスタマイズ等をやろうと思うと後者になるのかな?とりあえずDockerイメージから起動してみる。
Dockerでコンテナ起動。Docker for DesktopではないLinuxの場合は--add-host host.docker.internal:host-gatewayが必要になる。また公式の手順では--rmオプションがついているので、コンテナを落とすと設定等も削除される。消したくない場合はこのオプションを外しておく。
$ docker run \
-e GRADIO_SERVER_NAME=0.0.0.0 \
-e GRADIO_SERVER_PORT=7860 \
-p 7860:7860 -it --rm \
--add-host host.docker.internal:host-gateway \
taprosoft/kotaemon:v1.0
ブラウザで7860番ポートにアクセスするとログイン画面が出てくる。admin/adminでログインする。
ログイン後の画面。
Ollamaを使用する設定
デフォルトではどうやらOpenAIを使用するようになっているみたいなので、これをOllamaを使用するように設定していく。
タブメニューは5つあるが、初期はChatタブが選択されている。で画面中央に以下のように表示されている。
This is the beginning of a new conversation.
Make sure to have added a LLM by following the instructions in the Help tab.
Helpタブの手順に従ってLLMの設定を行う必要がある様子だが、Ollamaを含むローカルモデルを使う場合はこちらを見た方が良い。
まず、ResourceタブからLLMの設定。
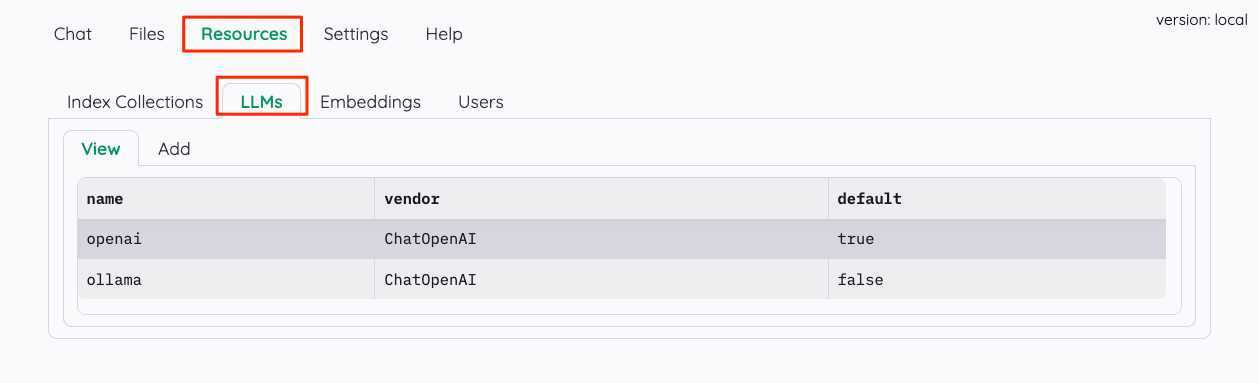
すでにOpenAIとollamaの設定が入っている。今回は最初からあるOllamaの設定を書き換えることにする。"Ollama"をクリックすると設定が表示されるので書き換える。
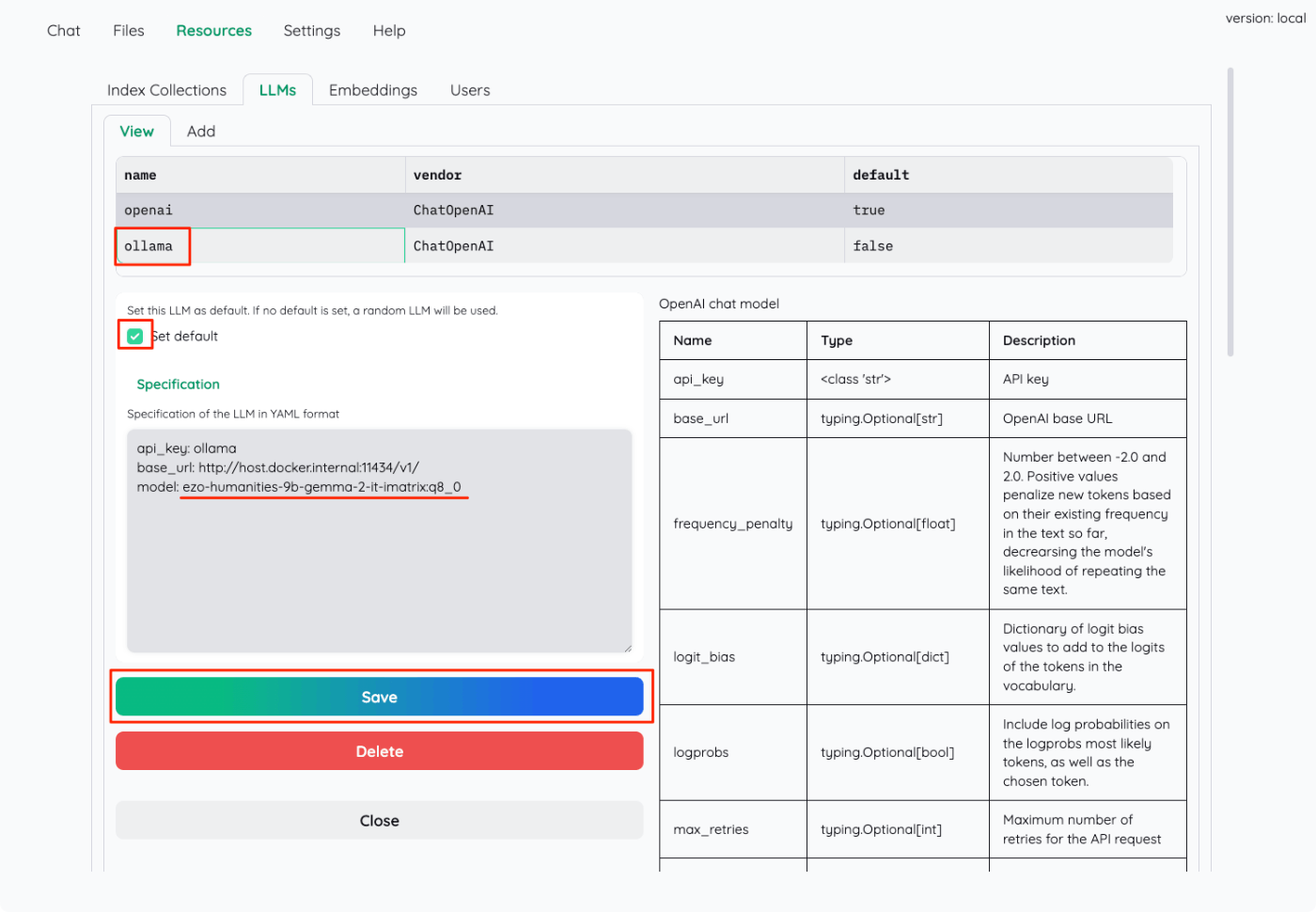
- Specification内の"model"を自分が使用したいモデルに書き換える。今回は
ezo-humanities-9b-gemma-2-it-imatrix:q8_0。 - "Set default"にチェックを入れてデフォルトにする。
- "Save"で保存
同様にしてEmbeddingも設定変更を行う。
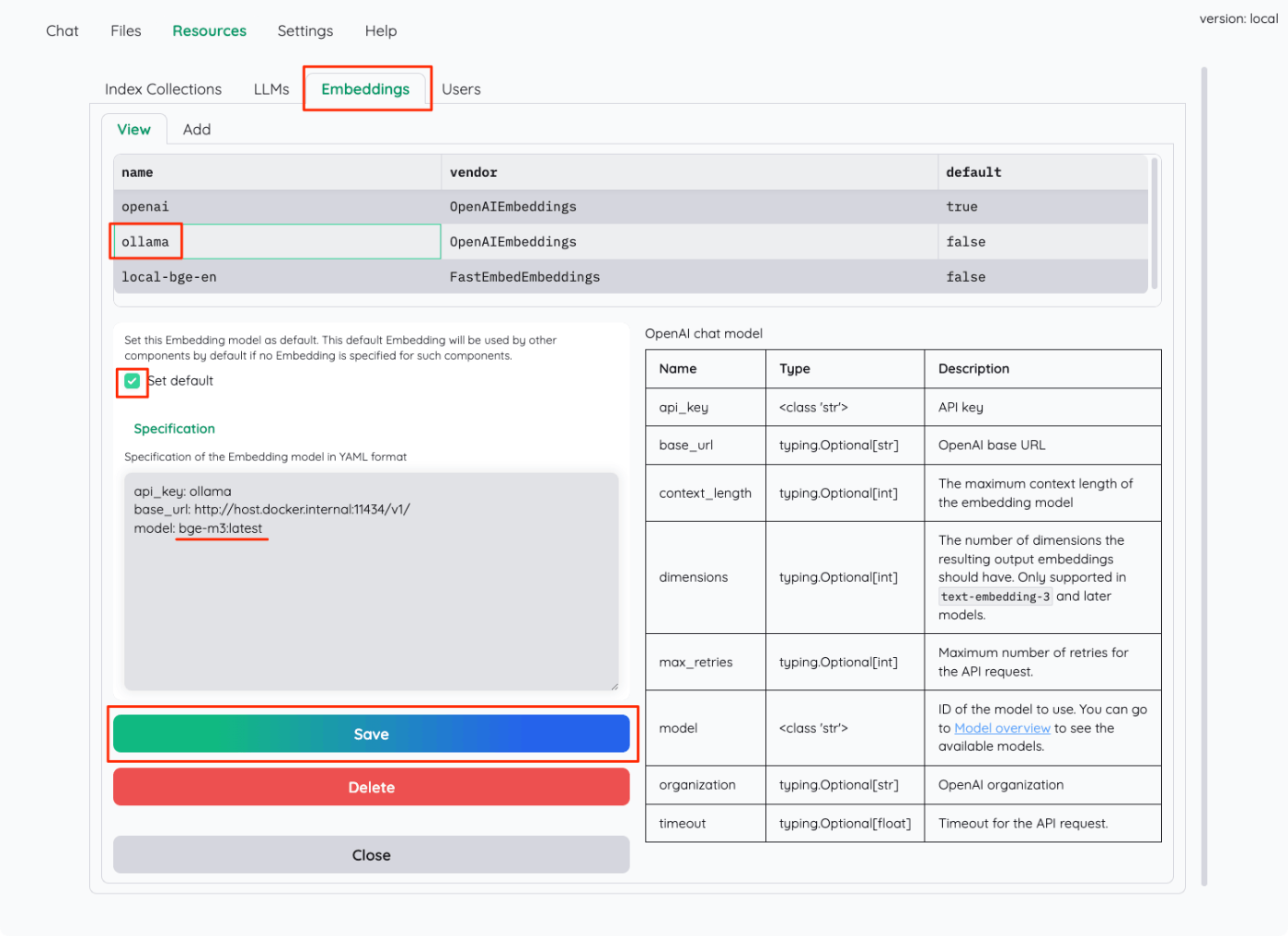
- Specification内の"model"を自分が使用したいモデルに書き換える。今回は
bge-m3:latest。 - "Set default"にチェックを入れてデフォルトにする。
- "Save"で保存
次にインデックスの設定。デフォルトではインデックス作成時のEmbeddingモデルはOpenAIを使用するようになっているので、これを先ほど設定したollamaの設定を使うように変更していく。
Resoucesタブ→Index Collectionsタブを開くと、2つのインデックスタイプが表示されている。
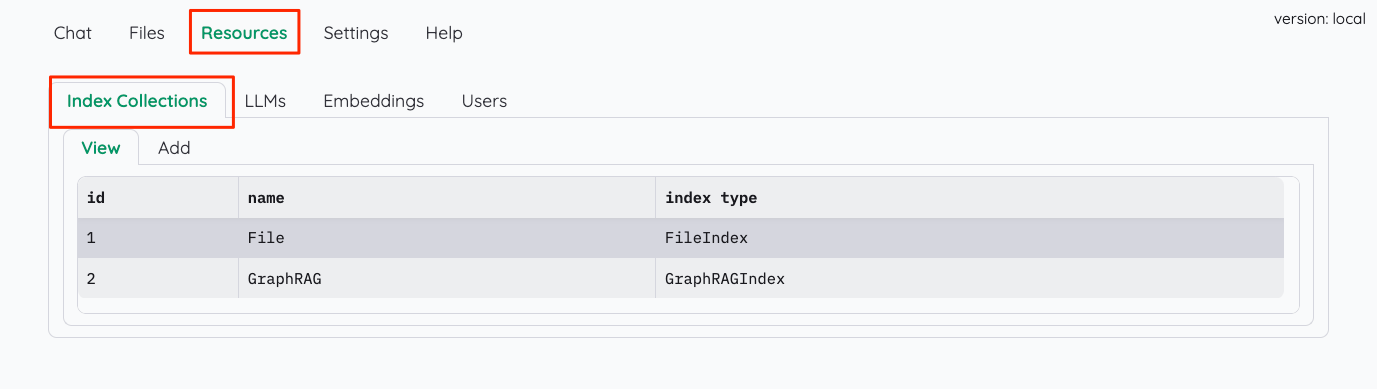
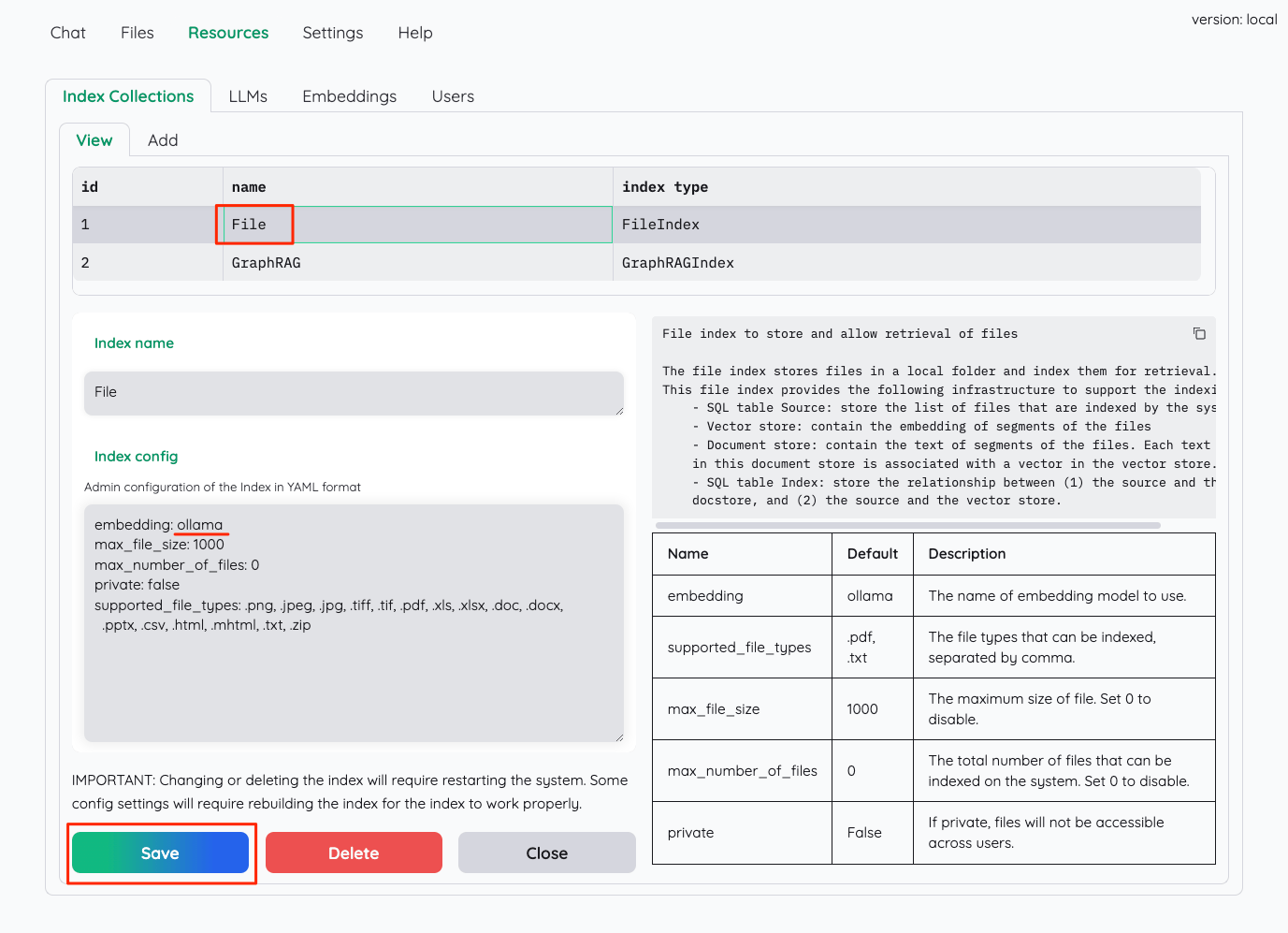
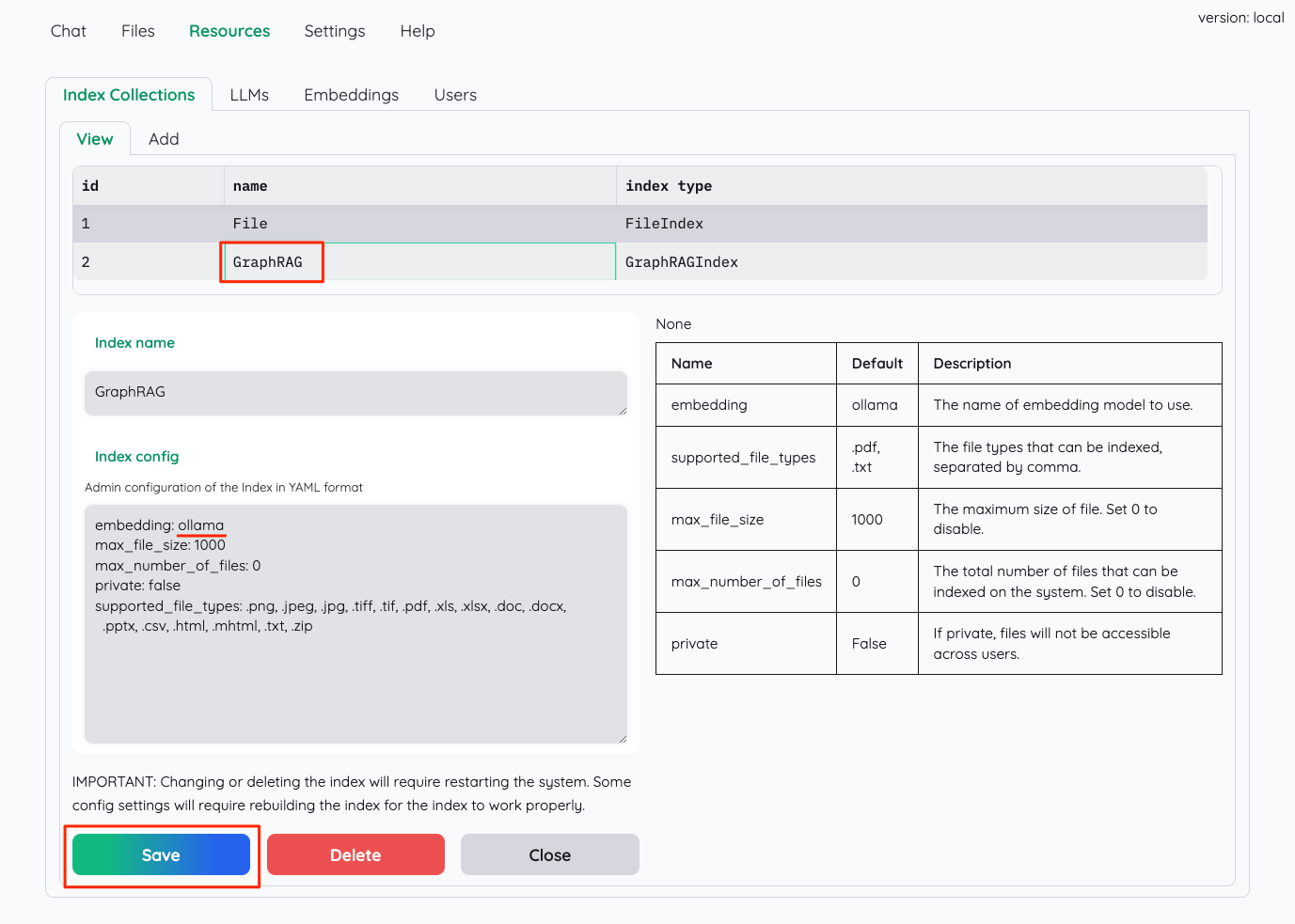
おそらくだが、Fileが一般的なベクトルストアを使うインデックスで、GraphRAGはその名の通りGraphRAGによるインデックスだと思われる。それぞれの設定にはインデックス作成で使用するEmbeddingモデルの指定があるので、これを"ollama"に書き換える。
次にSettingsタブを開いて、検索および推論時に使用するLLMの設定を全てollamaを使用するように変更する。ここはもしかするとすでに書き換わっているかもしれないが、自分が試した感じだと書き換わっていない場合もあるので一通り確認しておくと良い。
Retrieval settingsタブ→File Collectionタブ→LLM for relavant scoringで "ollama(default)"が選択されていること。
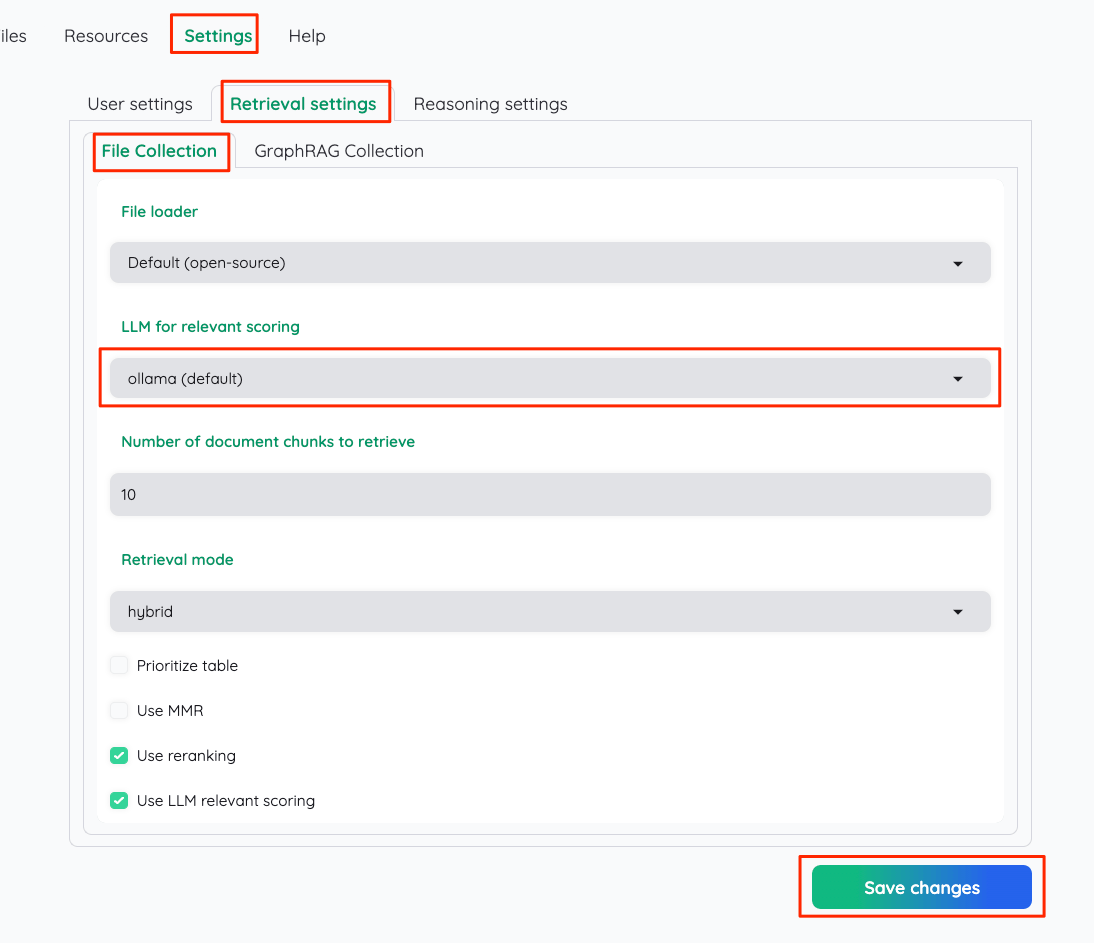
Reasoning settings ではまずLanguageを"Japanese"にする
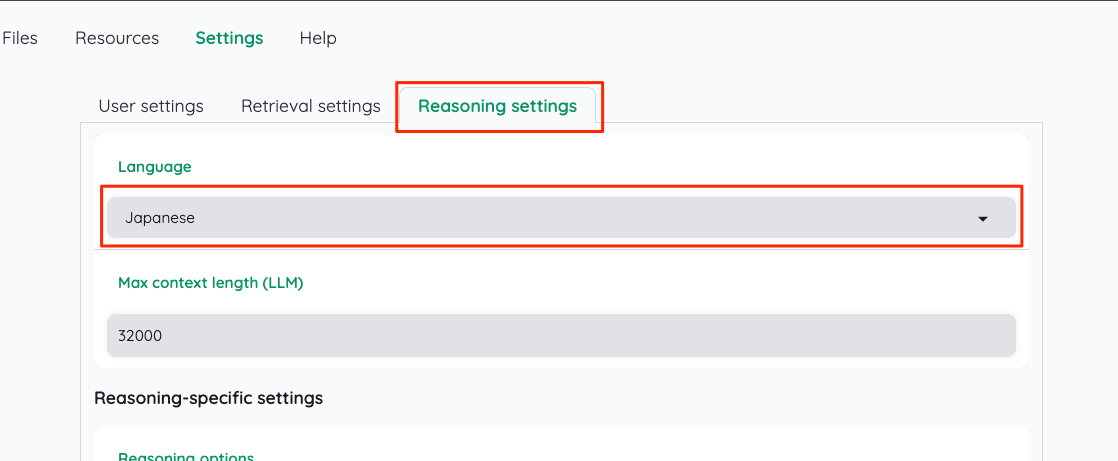
そして推論時のオプションが4つ用意されているが、それぞれで使用するモデル設定があるので、これを順に書き換えていく。推論オプションの説明は以下。
-
simple(Simpel QA)- シンプルなRAGベースの質問応答パイプライン。
- キーワード検索と類似検索の両方を実行して文脈を取得し、その文脈を含めて回答を生成する。
-
complex(Complex QA)- 多段階の推論を使用して、複雑な質問を複数のサブ質問に分解する。
- キーワード検索と類似検索の両方を実行して文脈を取得し、その文脈を含めて回答を生成する。
-
ReAct(ReAct Agent)- 計画を立て、それを実行するというプロセスを繰り返すことで、ユーザーの要求に応える。
- 複数のツールを使用して情報を収集し、最終的な回答を生成することができる。
- 参考: https://arxiv.org/abs/2210.03629
-
ReWOO(ReWOO Agent)- まず第1段階で段階的な計画を立て、次に第2段階で各ステップを解く。
- 推論プロセスを支援する外部ツールを使用することができる。
- すべての段階が完了すると、エージェントは回答を要約する。
- 参考: https://arxiv.org/abs/2305.18323
simple
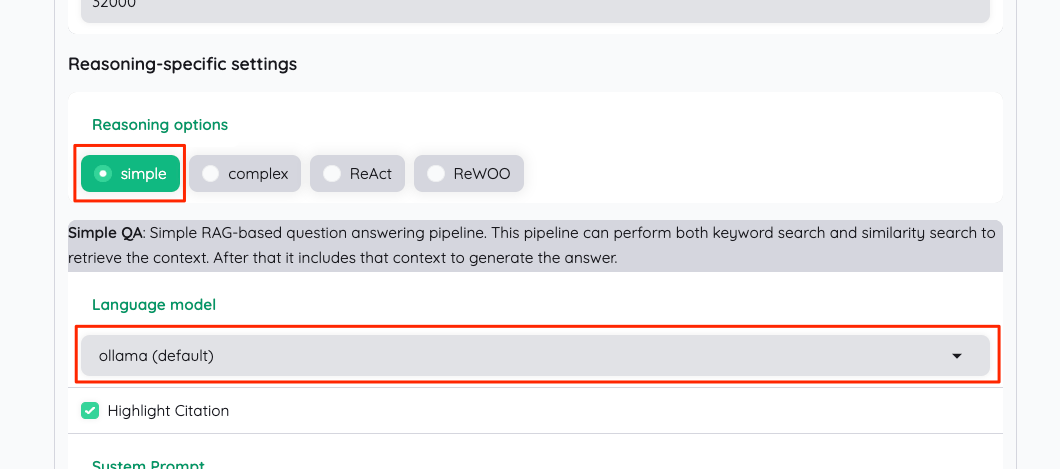
complex
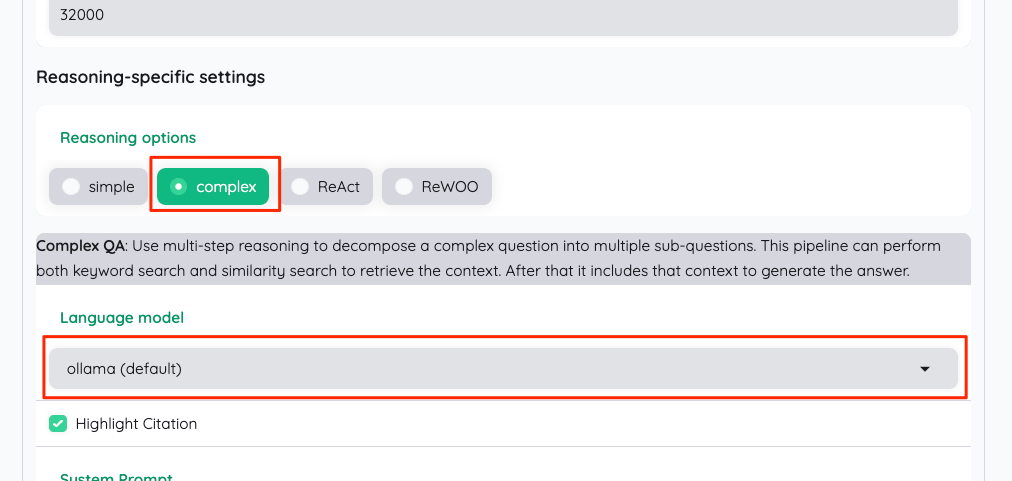
ReAct

ReWOO
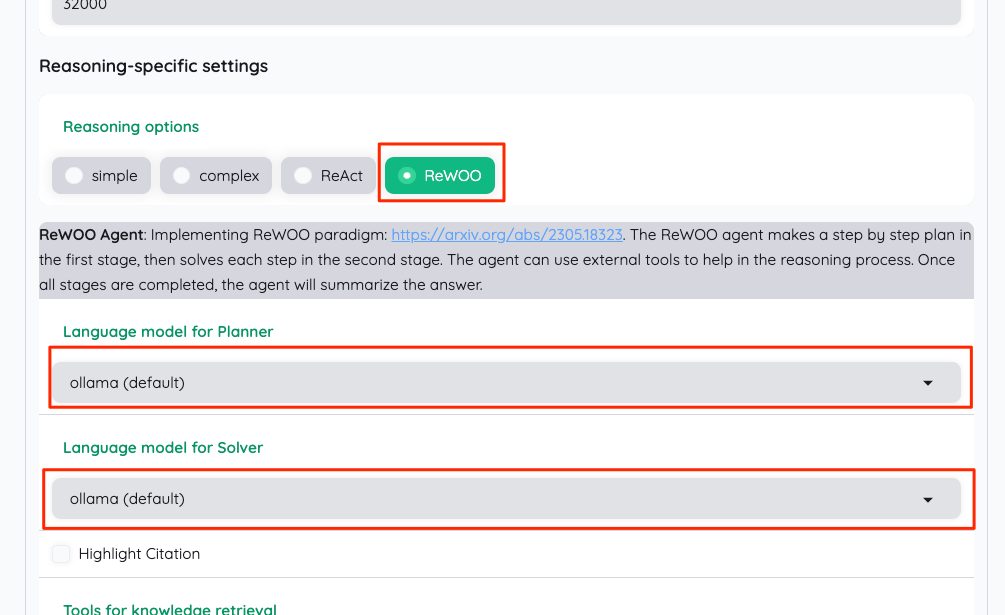
全部設定変更したら"simple"を選択しなおして保存しておく。多分ここで選択してあるものが推論オプションのデフォルトになると思う。
これですべての設定がOllamaを使用するように書き換わったはず。
なお、余談だがReAct/ReWOO Agentの場合は一部のツールも使える様子。

ファイルアップロード
RAGのコンテキストで使用するファイルをアップロードする。今回は、神戸市が公開している観光に関する統計・調査資料のうち、「令和4年度 神戸市観光動向調査結果について」のPDFを使う。
PDF直
Filesタブ→File Collectionタブでファイルをアップロードする。GraphRAGは気になるが、一旦後回し。
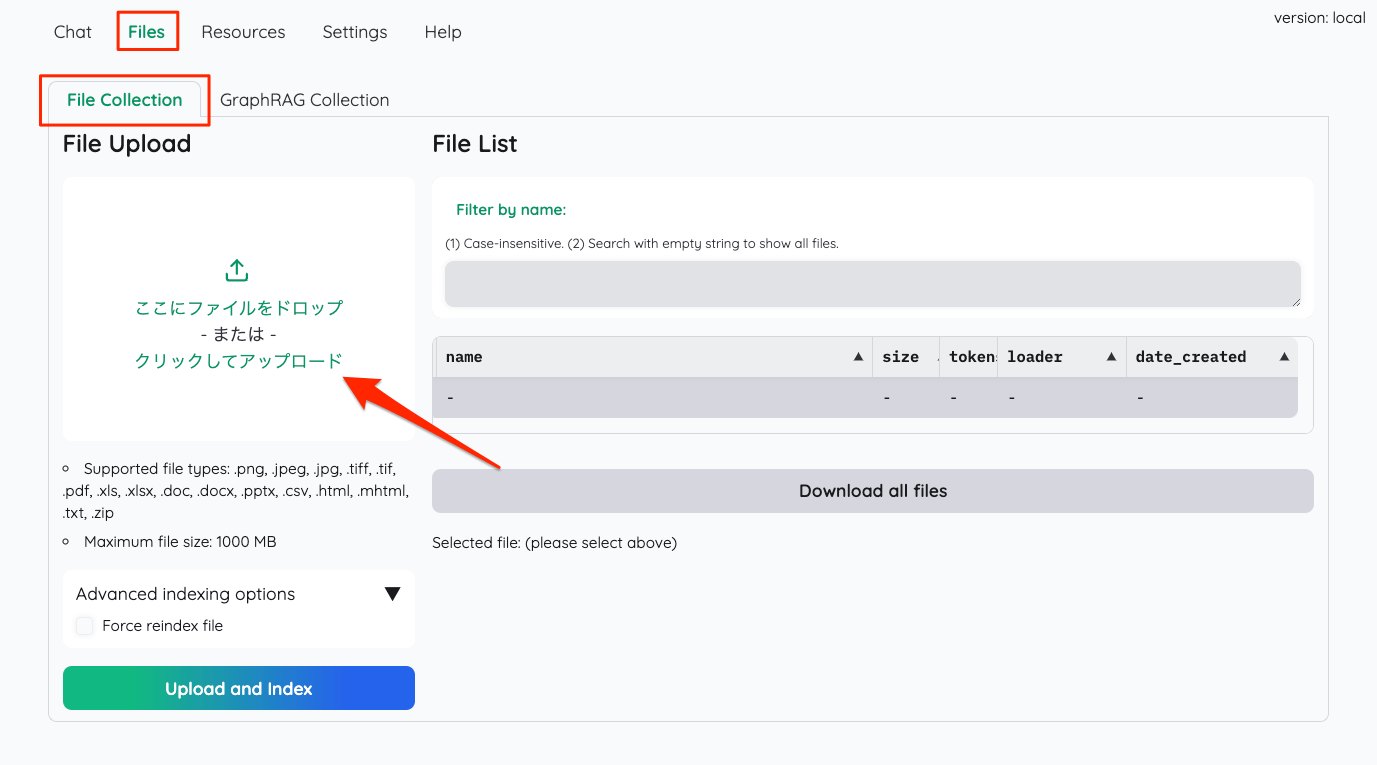
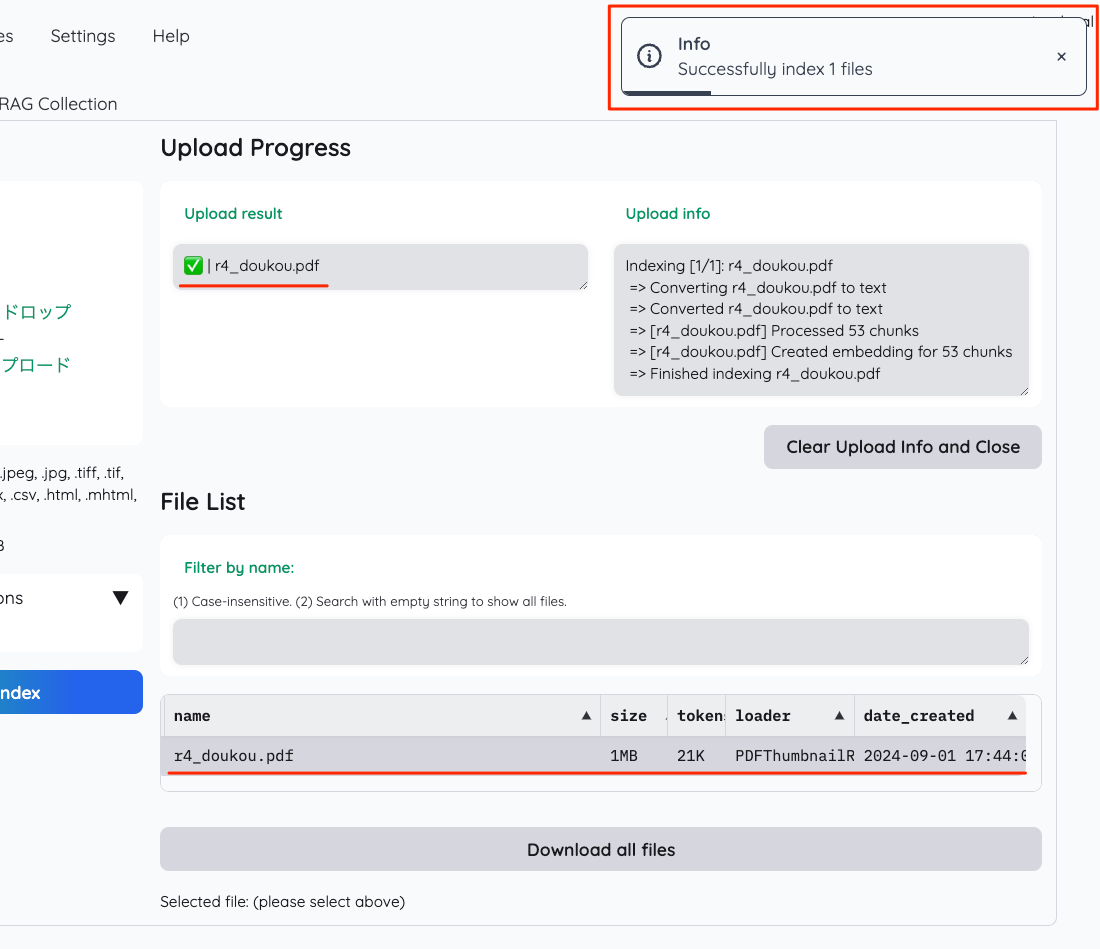
ファイルがアップロードされたらインデックス化
インデックス化が行わるので、しばらく待って以下のように表示されればOK。
ファイルを使ったチャット
ファイルをインデックス化したので、それを使ってチャットしてみる。Chatタブをクリックしてチャット画面に移動。
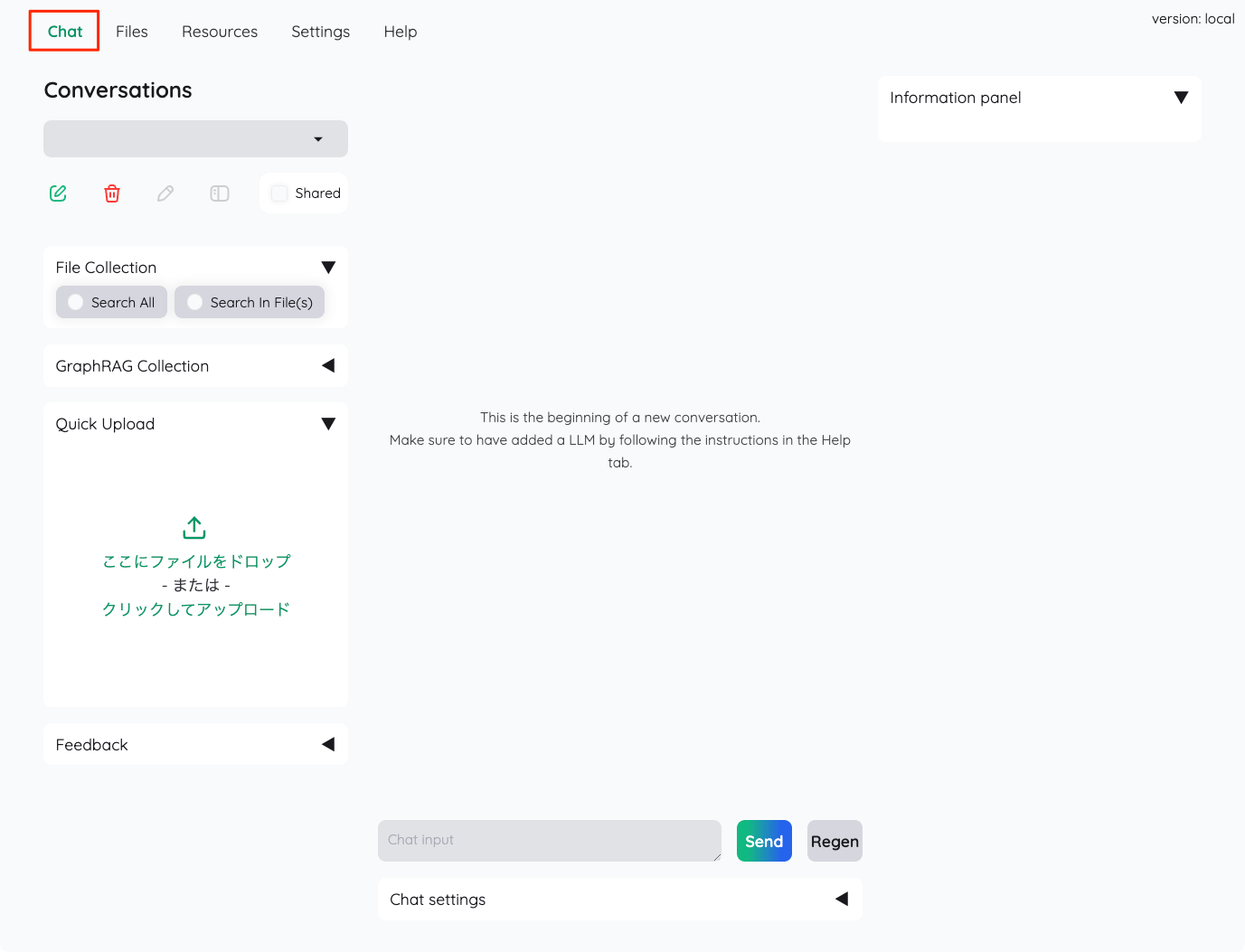
左メニューのFile Collectionから、今回は先ほど登録したファイル「だけ」を使って、チャットする。"Search In File(s)"を選択して、先程のファイルを選択。なお、"Search All"だと登録したファイル全部を使って検索を行う様子。あと、ファイルアップロードは"Quick Upload"からも行える様子。

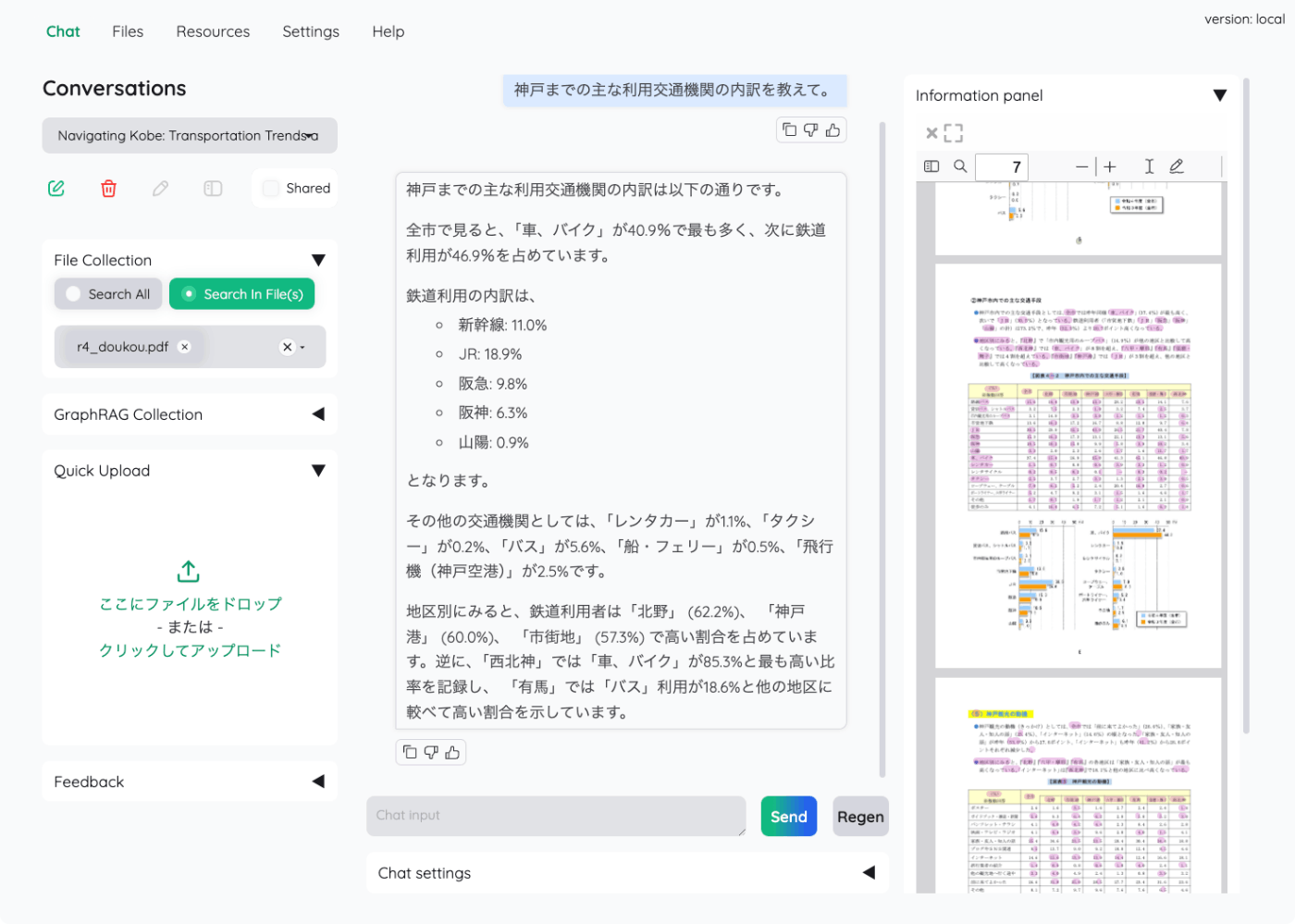
ではチャット。
回答はストリーミングで行われ、根拠となるドキュメントの引用が右に表示される。

引用の"Preview"をクリックすると、実際のPDFの内容も表示される。
少し試してみた限りだと、テキストファイルのインデックス登録については、
- Filesメニューからは登録できるけど、どうもうまくインデックスされていないように思える
-
unstructuredパッケージが存在しないとかログには出てた。
-
- Quick Uploadではテキストファイルは対象外
のようなので、現時点ではテキストファイルは使えないのかなー?と思っている。
2024/09/02追記
Issueがあった。Dockerイメージにはいろいろ足りないパッケージがあるらしい。
2024/09/05追記
v0.4.5で.txtと.mdに対応した模様。Unstructuredとか使ってなくてネイティブのクラスでやってる。
GraphRAGも試してみたのだが、どうもインデックスで失敗している
- 元のFile Collectionで登録したドキュメントを一旦削除
- GraphRAG Collectionで再度登録
- インデックス作成でエラー
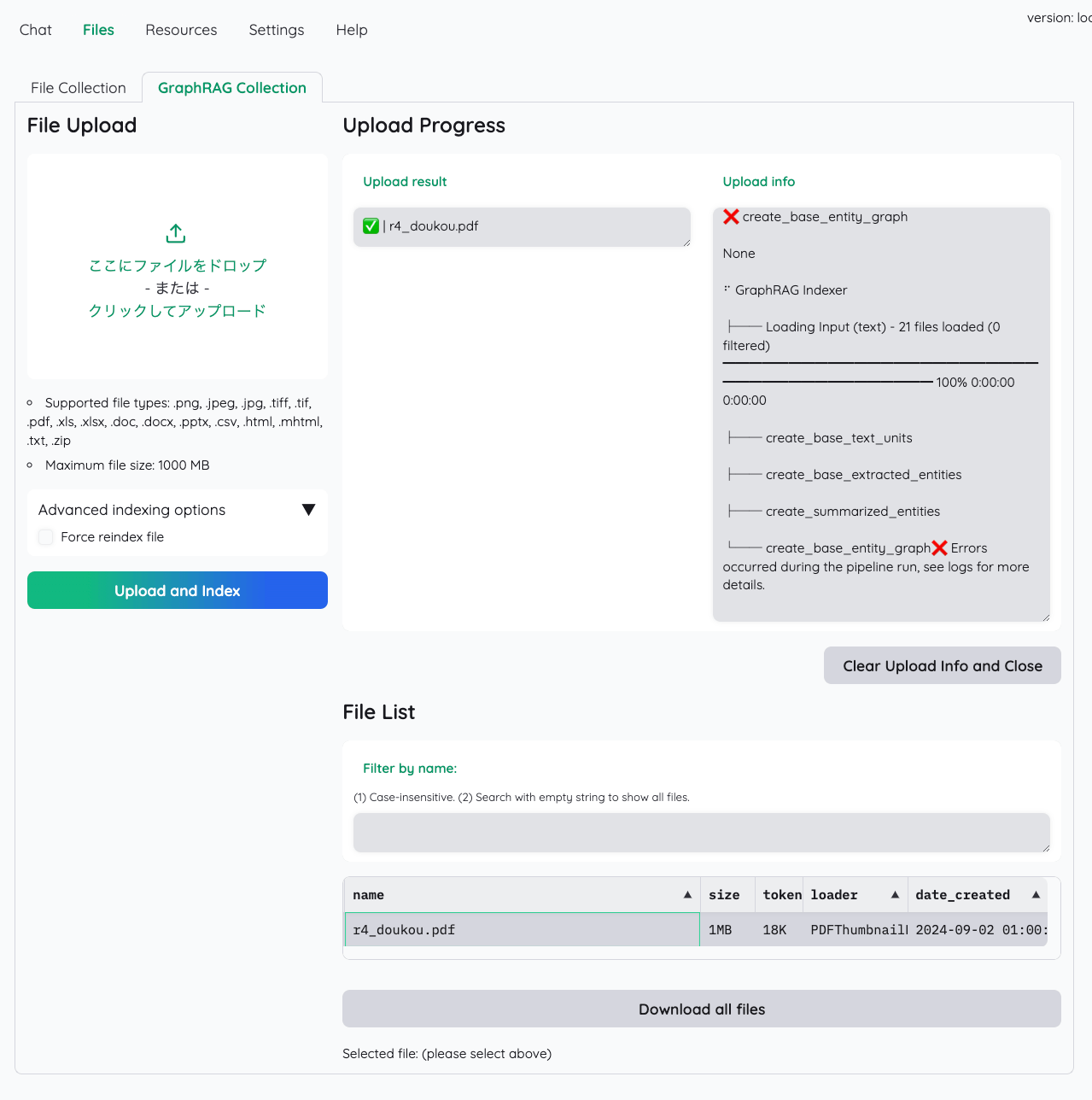
この状態でも一応チャットできるかを確認してみたが、やはりダメ
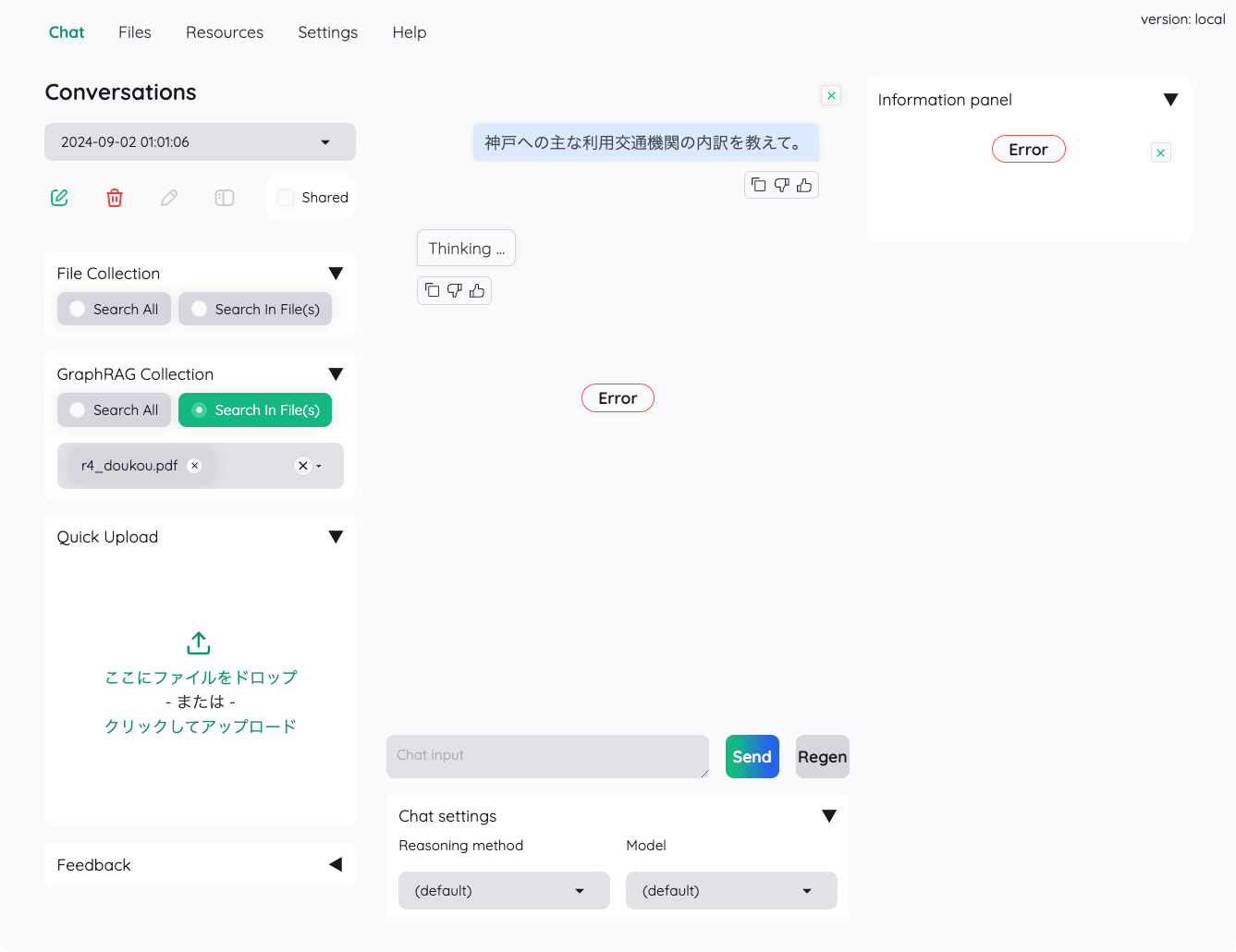
Issueにも上がっている様子
公式がHuggingFaceで提供しているデモのサンプルデータがどうやら公開されているらしい。GraphRAGを手っ取り早く試すならこれを使うのが早いかも。
とりあえずまとめ
kotaemonがよいのは、UIがとてもコンパクトに整理されていて、かつ、必要な機能をビジュアル的にも提供しているというところかな。Gradioでここまでできるのがすごいな。
とりあえず普通にドキュメント読み込んでRAGってのはできたので、次はGraphRAGを動かすところまで試すべく、ソースからセットアップしてみる予定
ソースからのインストール
以下を参考にollamaを使ったGraphRAGの構築をゴールに進めたのだが、
結論から言うと、
- ollamaではGraphRAGの構築は今のところ成功できていない。
- OpenAIを使えばGraphRAGの構築が成功した
ということで、記録として手順を書いておく。
python仮想環境は適宜用意しておくこと。
レポジトリクローン
$ git clone https://github.com/Cinnamon/kotaemon && cd kotaemon
レポジトリからライブラリインストール
$ pip install -e "libs/kotaemon[all]"
$ pip install -e "libs/ktem"
Dockerfileを見てみるとこれだけだと色々足りない、というかGraphRAGのパッケージが含まれていない。
ということで、合わせてインストール。色々怒られるが一旦無視。
$ pip install graphrag future
$ pip install "pdfservices-sdk@git+https://github.com/niallcm/pdfservices-python-sdk.git@bump-and-unfreeze-requirements"
2024/09/05追記
v0.4.5でMarkdownとテキストファイルのサポートが行われたようなので、それらについてはUnstruturedは不要。
あと、前回試したときに、テキストファイルをインデックスさせようとしたらunstructuredパッケージがないと言われていたのでunstruturedも追加する
shell~~ ~~$ pip install unstructured~~ ~~
ブラウザ内でPDFを表示するためのJSのパッケージを取得して展開しておく。
$ mkdir libs/ktem/ktem/assets/prebuilt
$ wget https://github.com/mozilla/pdf.js/releases/download/v4.0.379/pdfjs-4.0.379-dist.zip
$ unzip pdfjs-4.0.379-dist.zip -d libs/ktem/ktem/assets/prebuilt/pdfjs-4.0.379-dist
.envの設定。
# OpenAIの設定: APIキーやモデルをセット
OPENAI_API_BASE=https://api.openai.com/v1
OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXX
OPENAI_CHAT_MODEL=gpt-4o-mini
OPENAI_EMBEDDINGS_MODEL=text-embedding-3-small
# Azure OpenAIの設定: APIキーやデプロイメントをセット ※今回は未使用
AZURE_OPENAI_ENDPOINT=
AZURE_OPENAI_API_KEY=
OPENAI_API_VERSION=2024-02-15-preview
AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo
AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002
# Cohereの設定(リランキングで使用) ※今回は未使用
COHERE_API_KEY=
# ローカルモデル(ollama)の設定: 使用するモデルをセット ※ただしGraphRAGでの使用は未成功
LOCAL_MODEL=ezo-humanities-9b-gemma-2-it-imatrix:q8_0
LOCAL_MODEL_EMBEDDINGS=bge-m3:latest
# GraphRAGの設定
# ※GRAPHRAG_EMBEDDING_MODELはOPENAI_EMBEDDINGS_MODELと同じにしておいたほうが良さそう
GRAPHRAG_API_KEY=sk-XXXXXXXXXXXXXXXX
GRAPHRAG_LLM_MODEL=gpt-4o-mini
GRAPHRAG_EMBEDDING_MODEL=text-embedding-3-small
# Azure DIの設定 ※今回は未使用
AZURE_DI_ENDPOINT=
AZURE_DI_CREDENTIAL=
# Adobe APIの設定 ※今回は未使用
# 以下で無料のクレデンシャルが入手可能
# https://acrobatservices.adobe.com/dc-integration-creation-app-cdn/main.html?api=pdf-extract-api
# 合わせて以下ライブラリのインストールが必要
# pip install "pdfservices-sdk@git+https://github.com/niallcm/pdfservices-python-sdk.git@bump-and-unfreeze-requirements"
PDF_SERVICES_CLIENT_ID=
PDF_SERVICES_CLIENT_SECRET=
# PDF.jsの設定(上の手順でJSパッケージを展開しておくこと)
PDFJS_VERSION_DIST="pdfjs-4.0.379-dist"
# GradioのLISTENポートの設定
GRADIO_SERVER_NAME=0.0.0.0
GRADIO_SERVER_PORT=7860
ではkotaemonを起動。dotenv runとか初めて知ったわ。
$ dotenv run -- python app.py
ブラウザからアクセスして確認すると、必要な設定がほぼ全て行われていることがわかる。
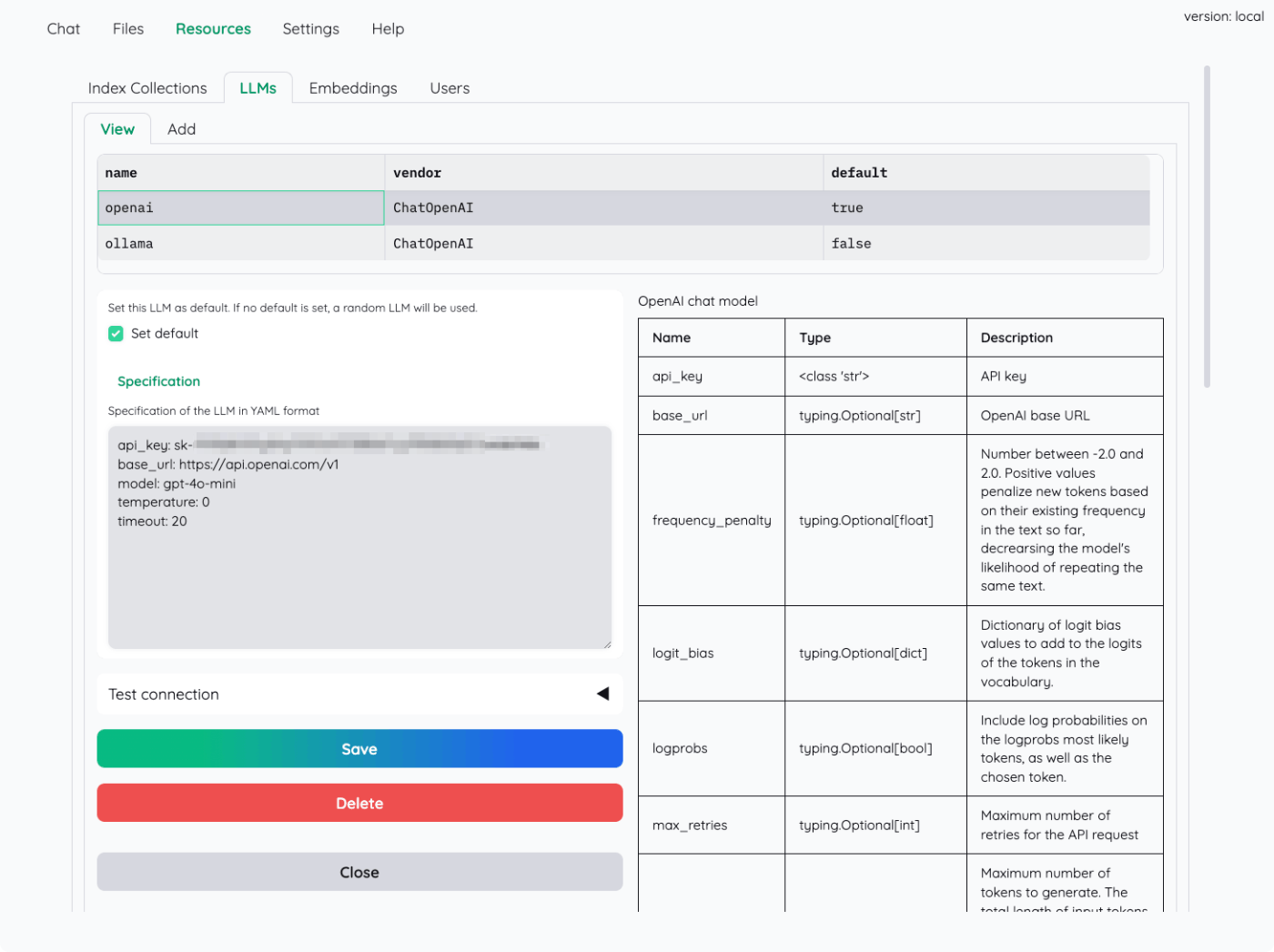
ざっと見た感じ、自分で設定変更が必要だったのは言語だけ。あとは特に変更していない。

ではGraphRAGでインデックスを作成する。今回は以下のwikipediaのページをテキスト抽出したものを使用する。
抽出したスクリプトは本題からはそれるので詳細は割愛。
wikipediaのページからテキストを抽出するpythonスクリプト
from pathlib import Path
import requests
import re
import argparse
import sys
# データ保存先のパスを定義
DATA_PATH = Path("./wiki_data")
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
def scrape_wikipedia(titles):
# データ保存先ディレクトリの作成(存在しない場合)
DATA_PATH.mkdir(exist_ok=True)
for title in titles:
try:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
},
timeout=10 # タイムアウトを10秒に設定
)
response.raise_for_status() # HTTPエラーがあれば例外を発生させる
data = response.json()
page = next(iter(data["query"]["pages"].values()))
if "extract" not in page:
print(f"警告: '{title}' の記事が見つかりませんでした。", file=sys.stderr)
continue
wiki_text = f"# {title}\n\n## 概要\n\n"
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
# markdown(.md)ファイルとして出力
output_file = DATA_PATH / f"{title}.txt"
with open(output_file, "w", encoding="utf-8") as fp:
fp.write(wiki_text)
print(f"'{title}' の記事を正常に保存しました: {output_file}")
except requests.RequestException as e:
print(f"エラー: '{title}' の取得中にネットワークエラーが発生しました: {e}", file=sys.stderr)
except KeyError as e:
print(f"エラー: '{title}' の解析中に問題が発生しました: {e}", file=sys.stderr)
except IOError as e:
print(f"エラー: '{title}' のファイル書き込み中に問題が発生しました: {e}", file=sys.stderr)
except Exception as e:
print(f"予期せぬエラー: '{title}' の処理中に問題が発生しました: {e}", file=sys.stderr)
def main():
parser = argparse.ArgumentParser(description="Scrape Wikipedia articles and save as markdown files.")
parser.add_argument("titles", nargs="+", help="Wikipedia article titles to scrape")
args = parser.parse_args()
scrape_wikipedia(args.titles)
if __name__ == "__main__":
main()
実行
$ python get_wiki_text.py "オグリキャップ"
'オグリキャップ' の記事を正常に保存しました: wiki_data/オグリキャップ.txt
wikidataディレクトリ以下にテキストファイルが作成される。中身はMarkdownになっている。
アップロードしてインデックス作成。
GraphRAGのインデックス作成はちょっと時間がかかる。進捗がわかりにくいのだけども、以下のように出力されるまで待てばよい。
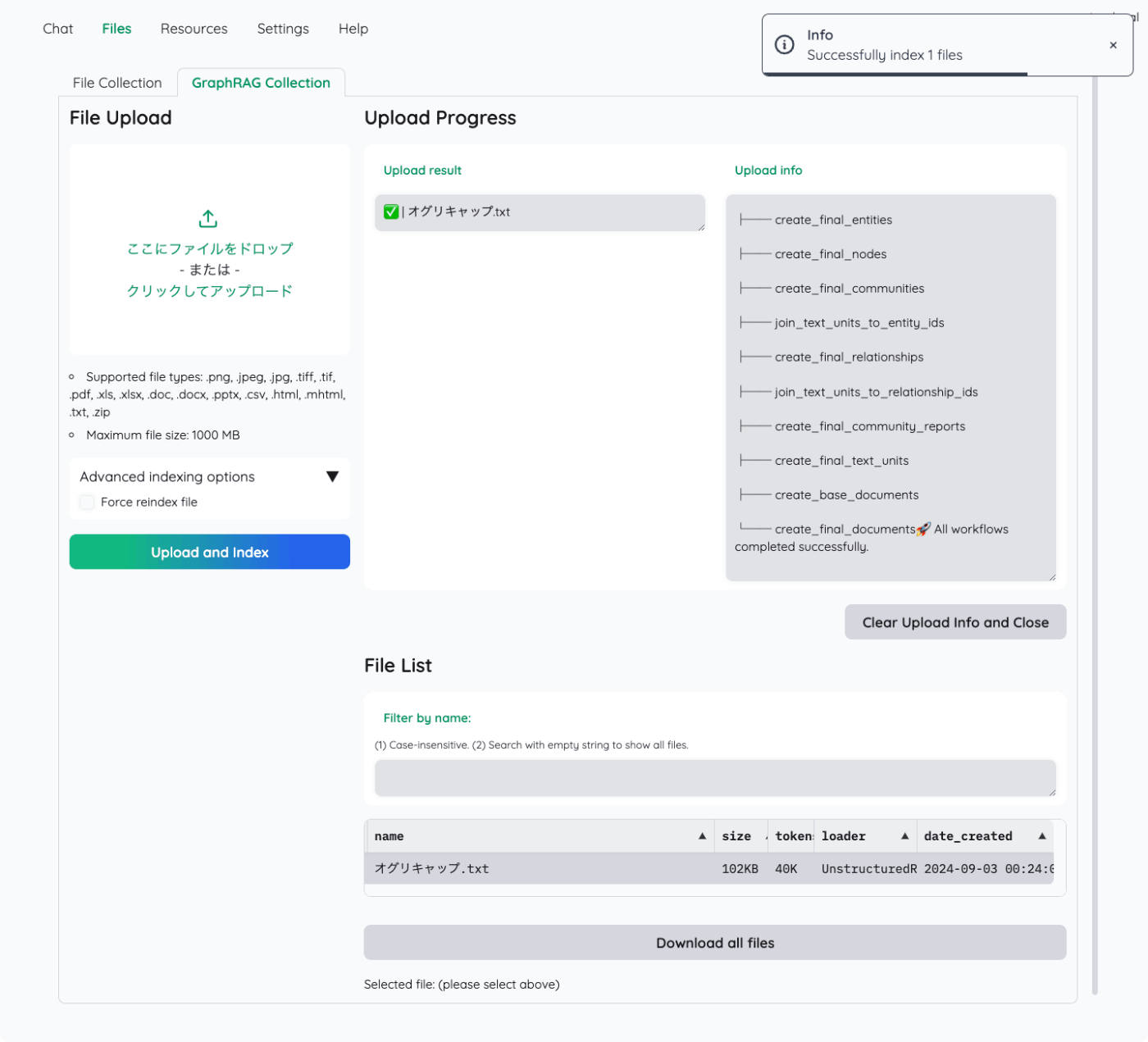
ではチャットしてみる。Chatタブで左メニューのGraphRAG Collectionから先ほどのファイルを選択。
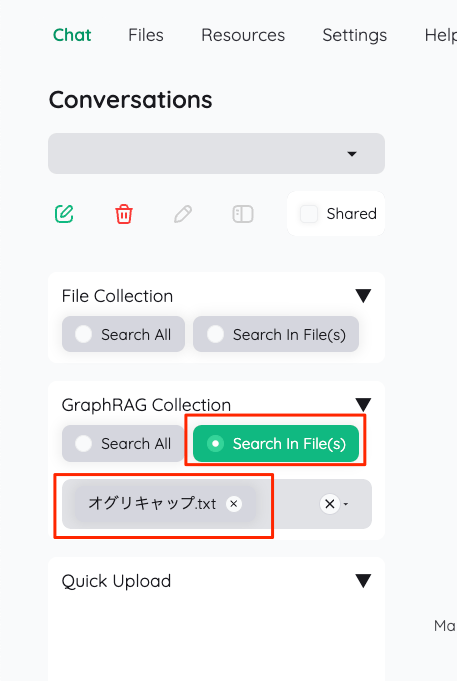
適当にチャットしてみるとこんな感じで、グラフが生成されているのがわかる。
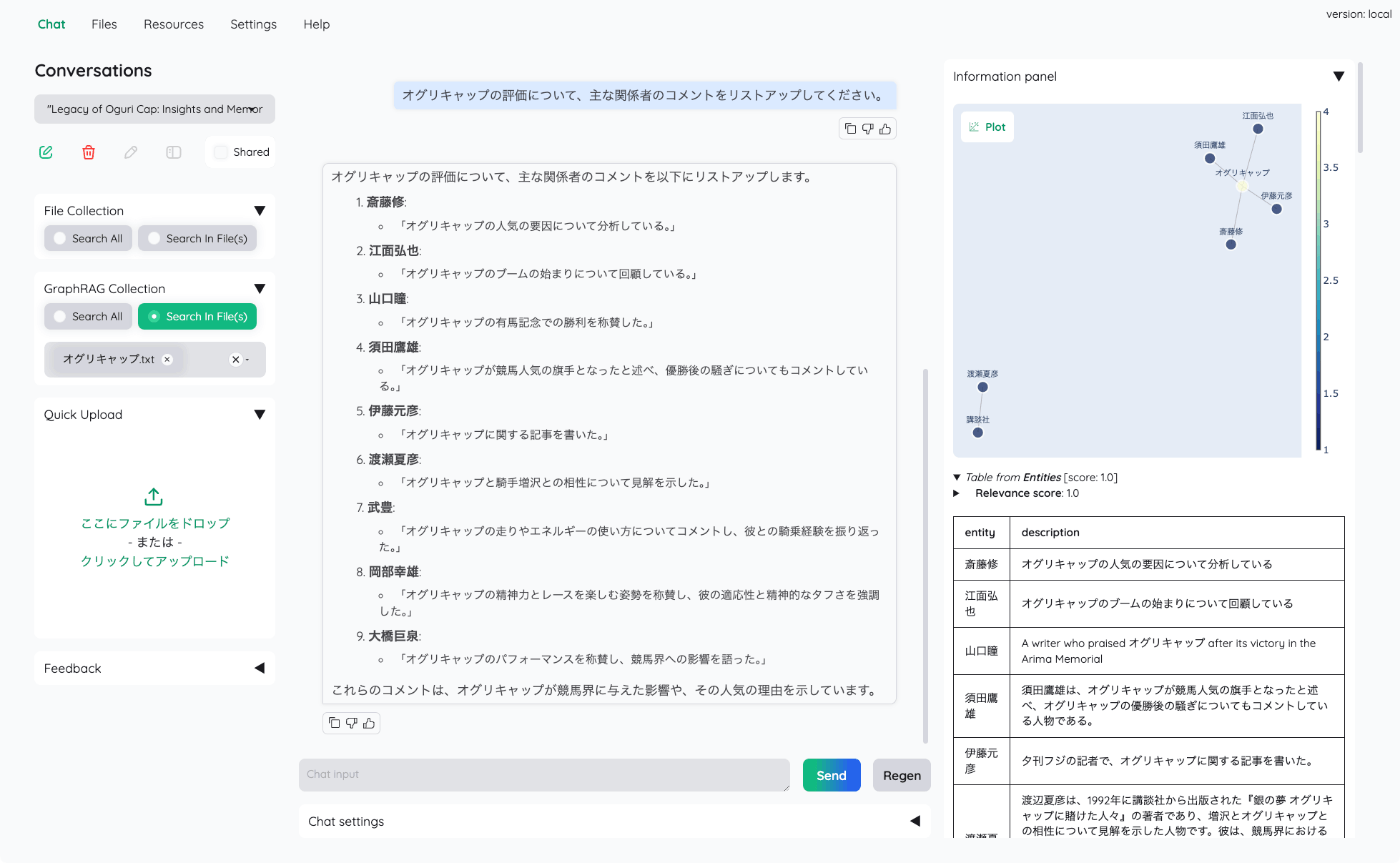
右のinformation panelに検索結果に関する出力がいろいろあって内容を見てみると面白い。
まずグラフが表示されている。ノードとリレーションの関係性が視覚的にわかる。
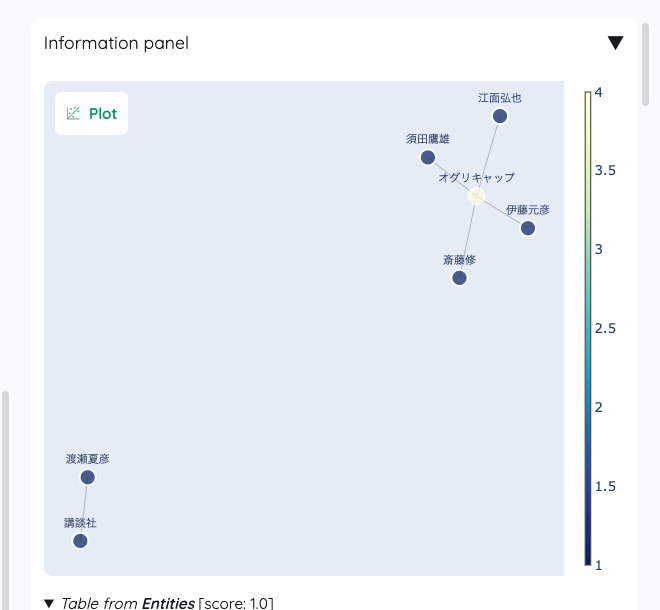
次に、エンティティ、つまりノードごとの説明が出力されている。

次に、テキストデータのチャンクが出力されている。ここは関連部分がハイライトされているっぽい。

次に、レポートとあるが、おそらくこれはGraphRAGにおけるコミュニティの要約だと思う。

最後にリレーションごとの出力。

これらがコンテキストとして入力され最終的な回答が生成されているのだと思う。
ただ、少し動かしてみた感じだと、ちょっと安定していないと言うか、クエリによってはエラーになったりすることもそれなりにある。
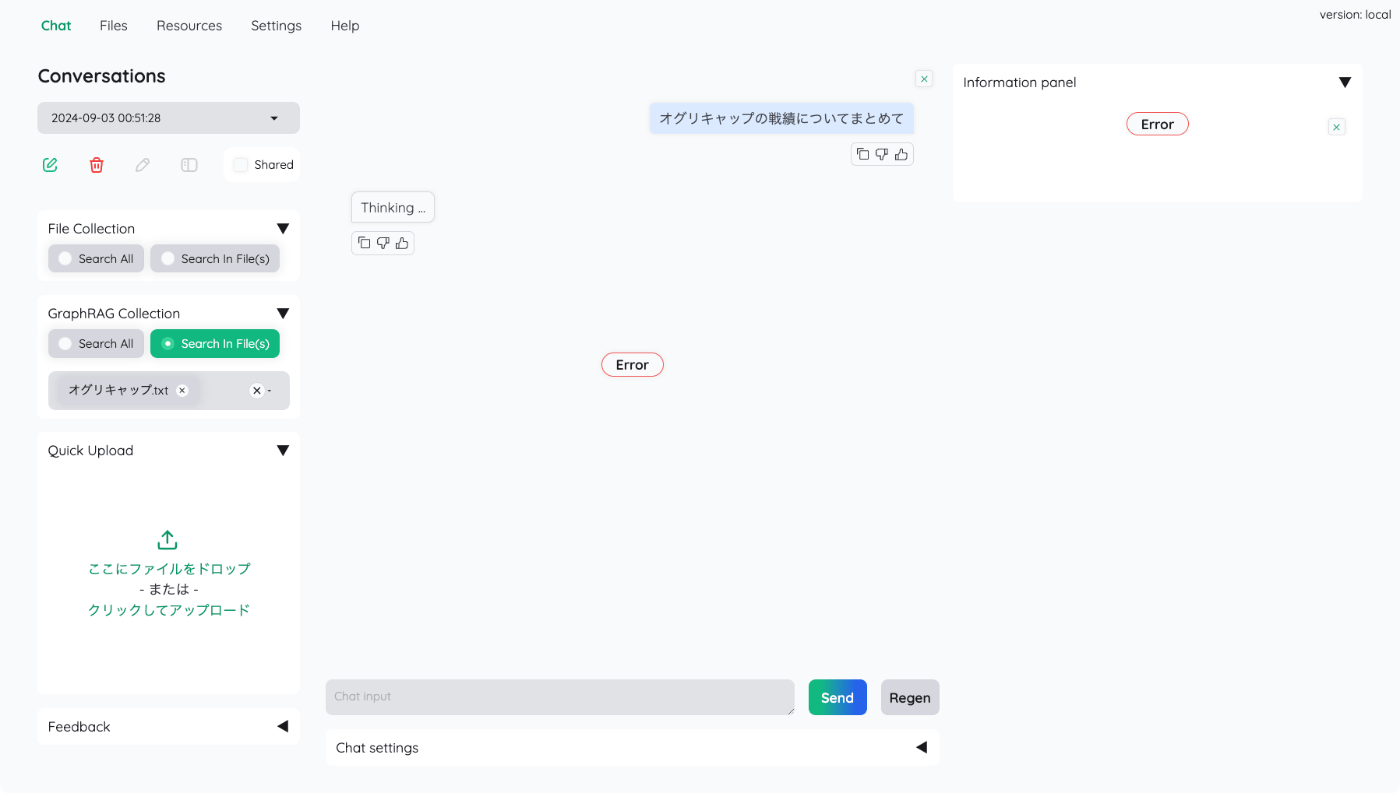
エラーが起きた時のログをざっと見た感じだとどうもパースエラー?ぽく見えるので、性能が高いモデルを使ったほうがいいのかな?という雑感。gpt-4o-miniだと足りないのかもしれない。
2024/09/03追記
上の方で書いた通り、どうもGRAPHRAG_LLM_MODELが適切にGraphRAGライブラリにわたっていない可能性があるように思える。
ちょっと.envの設定に関してはトリッキーなところがあるので、その点については後述。
.envで設定したパラメータの扱いはこんな感じ
- .envで設定した環境変数は以下の2パターンで扱われる
- 初回起動時にのみ読み込まれるもの
- kotaemonは内部に管理用データベース(sqlite)を持っていて、UIからの設定変更などはここで管理される
- 一部の設定は、初回起動時に環境変数(.env)から読み出されて、初期値としてデータベースに登録される
- 初回起動以降はデータベースを参照し、.envを設定変更しても反映されない(と思う)
- LLM/Embeddingのモデルの設定などはこれ
- ただし環境変数で指定できるのは一部のパラメータのみで、GUI上で変更する必要があるものもある
- ずっと環境変数として読み込まれるもの
- 内部のデータベースで管理されずに、常に環境変数として定義される
- 現状の実装がおいついておらず、環境変数でしか定義できない模様
- GraphRAGの設定はこれにあたる
- 初回起動時にのみ読み込まれるもの
という感じでちょっと現状はパラメータの管理がややこしくなっている。まあ致し方ないところかな。
上の方で書いた通り、どうもGRAPHRAG_LLM_MODELが適切にGraphRAGライブラリにわたっていない可能性があるように思える。
この箇所なのだけども、コードだとこのあたり
ここでGraphRAGのインデックス作成に必要な設定ファイルを初期化、そのあとインデックスを作成するコマンドをsubprocess.runで実行している。で環境変数はコマンド側にも渡されているはずなのだけども。
GraphRAGの環境変数は以下にある。たしかにGRAPHRAG_LLM_MODELは存在している。
シンプルに環境変数がsubprocess.runで実行されるコマンドに受け渡されているかを試してみた。Colaboratoryなのでアレかもだけども。
こういうスクリプトを用意。
import os
print(os.environ.get('GRAPHRAG_LLM_MODEL', 'Not found'))
セルから実行
import os
import subprocess
os.environ["GRAPHRAG_LLM_MODEL"] = "gpt-4o"
result = subprocess.run(['python','read_env.py'], capture_output=True, text=True)
print(result)
CompletedProcess(args=['python', 'read_env.py'], returncode=0, stdout='gpt-4o\n', stderr='')
環境変数はきちんと受け渡されているように思える。
ではGraphRAG単体で確認してみる。コマンドを実行。
from google.colab import userdata
os.environ["GRAPHRAG_API_KEY"] = userdata.get('OPENAI_API_KEY')
!python -m graphrag.index --init --root ./ragtest
settings.yamlが作成されるが、モデルがgpt-4-turbo-previewになっている。
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat # or azure_openai_chat
model: gpt-4-turbo-preview
(snip)
一応これでインデックス作成してみる
!python -m graphrag.index ---root ./ragtest
OpenAIのダッシュボードでUsage確認するも、やっぱりgpt-4-turboが使用されているように思える。
一応Issue上げておいたら返事が来ていた。
GRAPHRAG env varsは公式実装に従って設定されています。
https://microsoft.github.io/graphrag/posts/config/env_vars/GRAPHRAG_LLM_MODELは初期化コマンド(kotaemonで使用)の際に尊重されず、正しくsettings.yamlに保存されないようです。
https://microsoft.github.io/graphrag/posts/config/init/次回のリリースで正しく行う方法を検討します。 この問題についてもPRを作成していただけると助かります。 ご報告ありがとうございました。
これを見る限りはGraphRAG側の問題かなという気がする。
2024/09/03追記
GraphRAGのドキュメント見てても、インデックス作成フェーズでの環境変数の使い方がよくわからないんだよなあ・・・ドキュメント見ながらこの内容だと普通使えると思うよねぇと思いつつ・・・
バグなのか、使い方が間違っているのかよくわからないので、一旦discussionにとどめた。
あと、めちゃめちゃアドホックではあるが、一応修正案だけ出してみた。手元では動作しているように思うが、あまりにアレなのでPRは躊躇・・・
とりあえずkotaemonでollama+GraphRAGをやる道のりはまだ遠そうということかな・・・残念
GraphRAGの見え方やUIはとても良いと思うので、今後のリリースに期待