「LightRAG: Simple and Fast Retrieval-Augmented Generation」を試す
論文
概要(NotebookLM)
本論文は、外部の知識ソースを統合することで、大規模言語モデル(LLM)を強化する、Retrieval-Augmented Generation(RAG)システムについて、LightRAGという革新的なフレームワークを提案しています。 LightRAGは、グラフ構造をテキストインデックスと検索プロセスに組み込むことで、従来のRAGシステムの限界を克服し、より正確で文脈的に適切な応答を生成することを目指しています。このフレームワークは、低レベルと高レベルの両方の検索戦略を組み合わせることで、詳細な情報と概念的な情報を効率的に取得し、多様なクエリに対応できるようになっています。また、グラフ構造とベクトル表現を統合することで、関連するエンティティや関係を効率的に検索し、結果の包括性を向上させることができるようになっています。
落合プロンプト(Claude-3.5-Sonnet)
1. どんなもの?
LightRAGは、大規模言語モデル(LLM)の性能を向上させるための新しい検索拡張生成(RAG)システムです。従来のRAGシステムの限界を克服するため、グラフ構造をテキストのインデックス作成と検索プロセスに組み込んでいます。LightRAGの主な特徴は、包括的な情報検索を可能にする二段階検索システム、グラフ構造とベクトル表現を統合した効率的な検索メカニズム、そして新しいデータを迅速に統合できる増分更新アルゴリズムです。これらの機能により、LightRAGは複雑な相互依存関係を捉え、文脈に即した関連性の高い応答を生成することができます。
2. 先行研究と比べてどこがすごい?
LightRAGは、従来のRAGシステムと比較して以下の点で優れています:
- グラフ構造の活用:複雑な関係性を捉え、より包括的な情報検索を実現
- 二段階検索システム:低レベルと高レベルの情報を効果的に組み合わせ、多様な質問に対応
- 効率的な検索メカニズム:グラフ構造とベクトル表現の統合により、関連エンティティと関係の高速検索を実現
- 動的更新能力:増分更新アルゴリズムにより、新しい情報を迅速に統合し、システムの適応性を向上
- コスト効率:従来のGraphRAGと比較して、トークン消費量とAPI呼び出し回数を大幅に削減
これらの特徴により、LightRAGは特に大規模なデータセットや複雑な質問に対して、より優れた性能を発揮します。
3. 技術や手法の肝はどこ?
LightRAGの核となる技術は以下の3点です:
- グラフベースのテキストインデックス作成:LLMを使用してエンティティと関係を抽出し、知識グラフを構築します。これにより、複雑な相互依存関係を効果的に表現します。
- 二段階検索パラダイム:低レベル検索(特定のエンティティや関係に焦点)と高レベル検索(より広範なトピックやテーマを対象)を組み合わせ、包括的な情報検索を実現します。
- 増分更新アルゴリズム:新しいデータを既存のグラフ構造に効率的に統合し、システムの適応性と最新性を維持します。
これらの技術により、LightRAGは効率的で適応性の高いRAGシステムを実現し、多様な質問に対して文脈に即した関連性の高い応答を生成することができます。
4. どうやって有効だと検証した?
LightRAGの有効性は、UltraDomainベンチマークデータセットを用いた実験的評価によって検証されました。具体的には、以下の方法で評価が行われました:
- 複数のデータセット(農業、CS、法律、混合)を使用し、多様な分野での性能を検証
- 既存のRAGベースライン(NaiveRAG、RQ-RAG、HyDE、GraphRAG)との比較
- GPT-4を使用した多次元評価:包括性、多様性、エンパワーメント、全体的な品質を評価
- アブレーション研究:二段階検索パラダイムとグラフベースのテキストインデックス作成の有効性を個別に検証
- ケーススタディ:具体的な質問に対する応答の質的分析
- コストと適応性の分析:トークン消費量、API呼び出し回数、データ更新の効率性を評価
これらの評価により、LightRAGが特に大規模データセットや複雑な質問に対して、既存のRAGシステムを上回る性能を示すことが実証されました。
5. 議論はある?
論文では、LightRAGの性能と特徴に関して以下の点が議論されています:
- グラフ強化RAGシステムの優位性:大規模コーパスでの複雑なクエリ処理において、LightRAGを含むグラフベースのシステムが純粋なチャンクベースの検索方法よりも優れていることが示されました。
- 応答の多様性:LightRAGの二段階検索パラダイムが、より多様な応答を生成する能力を向上させることが確認されました。
- GraphRAGとの比較:LightRAGがGraphRAGを一貫して上回る性能を示し、特に大規模データセットでの優位性が顕著でした。
- 元のテキストの重要性:グラフベースのインデックス作成が元のテキストを効果的に要約し、場合によってはノイズを減らす可能性があることが示唆されました。
- コストと効率性:LightRAGが既存のシステムと比較して、トークン消費量とAPI呼び出し回数を大幅に削減できることが示されました。
これらの議論は、LightRAGの強みと潜在的な応用分野を浮き彫りにしています。
6. 次に読むべき論文は?
本論文の内容を深く理解し、関連分野の最新動向を把握するために、以下の論文を読むことをお勧めします:
- Ram et al. (2023) "In-context retrieval-augmented language models" - RAGシステムの基本概念と最新のアプローチについて
- Fan et al. (2024) "A survey on RAG meeting LLMs: Towards retrieval-augmented large language models" - RAGシステムの包括的なサーベイ
- Edge et al. (2024) "From local to global: A graph RAG approach to query-focused summarization" - グラフベースのRAGアプローチに関する詳細な研究
- Gao et al. (2023) "Retrieval-augmented generation for large language models: A survey" - RAGシステムの最新の進展と課題に関するサーベイ
- Chen et al. (2024) "LLAGA: Large language and graph assistant" - LLMとグラフデータの統合に関する研究
これらの論文は、RAGシステム、グラフベースのアプローチ、LLMとグラフの統合など、LightRAGに関連する重要なトピックをカバーしています。
インデックス作成・検索について(Claude-3.5-Sonnet)
インデックス作成プロセス
LightRAGのグラフベースのテキストインデックス作成は、以下の3つのステップで行われます:
エンティティと関係の抽出(R(・)関数):
例:「心臓病専門医は症状を評価して潜在的な心臓の問題を特定する」というテキストから、
- エンティティ:「心臓病専門医」「心臓病」
- 関係:「心臓病専門医が心臓病を診断する」
を抽出します。LLMプロファイリング(P(・)関数):
各エンティティとリレーションに対して、キーバリューペアを生成します。
例:
- キー:「心臓病専門医」
- バリュー:「心臓病専門医は、心臓と循環器系の疾患を専門とする医師です。彼らは...」
重複排除(D(・)関数):
異なるテキストセグメントから抽出された同一のエンティティや関係を統合します。
例:複数の文書で「心臓病」について言及されている場合、それらを1つのノードに統合します。検索プロセス
LightRAGの二段階検索パラダイムは以下のように機能します:
クエリキーワード抽出:
例えば、「電気自動車の普及が都市の大気質と公共交通インフラにどのような影響を与えるか?」というクエリに対して:
- 低レベルキーワード:「電気自動車」「大気質」「公共交通」
- 高レベルキーワード:「環境影響」「都市計画」「交通政策」
キーワードマッチング:
- 低レベル検索:「電気自動車」「大気質」「公共交通」に関連するエンティティを検索
- 高レベル検索:「環境影響」「都市計画」「交通政策」に関連する広範な情報を検索
高次の関連性の組み込み:
検索されたエンティティの近傍ノードも含めて情報を収集します。
例:「電気自動車」ノードから「充電インフラ」「バッテリー技術」などの関連ノードも取得このプロセスにより、LightRAGは特定のエンティティに関する詳細情報と、より広範なコンテキスト情報の両方を効率的に取得し、包括的で文脈に即した応答を生成することができます。
具体的には、上記のクエリに対して、電気自動車の排出ガス削減効果、充電インフラの都市計画への影響、公共交通システムの電化の可能性など、多角的な情報を組み合わせた応答を生成することが可能になります。
GitHubレポジトリ
良さそう
検索はもちろんなんだけど、
増分更新アルゴリズム:新しいデータを既存のグラフ構造に効率的に統合し、システムの適応性と最新性を維持します。
重複排除(D(・)関数):
異なるテキストセグメントから抽出された同一のエンティティや関係を統合します。
例:複数の文書で「心臓病」について言及されている場合、それらを1つのノードに統合します。
この辺も良さそう。
Quick Startに従って進めてみる。Colaboratoryで。
パッケージインストール。今回はレポジトリからインストールすることにした。
!git clone https://github.com/HKUDS/LightRAG
%cd LightRAG
!pip install -e .
RAGに読み込ませるドキュメントはいつもどおり以下を使用する。
from pathlib import Path
import requests
import re
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
# Wikipediaからのデータ読み込み
wiki_titles = ["オグリキャップ"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = f"# {title}\n\n## 概要\n\n"
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
# markdown(.md)ファイルとして出力
with open(f"{title}.md", "w") as fp:
fp.write(wiki_text)
LightRAGで使用する作業ディレクトリを作成
!mkdir oguricap
notebookなのでイベントループのネストを有効化しておく。
import nest_asyncio
nest_asyncio.apply()
OpenAI APIキーをセット
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
ドキュメントからインデックスを作成
from lightrag import LightRAG, QueryParam
rag = LightRAG(working_dir="./oguricap",)
with open("./オグリキャップ.md") as f:
rag.insert(f.read())
ちなみにLightRAGの作業ディレクトリには以下のようなファイルが作成される
$ tree oguricap
oguricap
├── graph_chunk_entity_relation.graphml
├── kv_store_full_docs.json
├── kv_store_llm_response_cache.json
├── kv_store_text_chunks.json
├── lightrag.log
├── vdb_chunks.json
├── vdb_entities.json
└── vdb_relationships.json
それぞれのファイルはざっくりこんな感じかな?詳細まではわからないけど。
-
graph_chunk_entity_relation.graphml: GraphMLのXMLデータ -
kv_store_full_docs.json: インデックスの元となるチャンク分割前テキストっぽい -
kv_store_llm_response_cache.json: 恐らく検索時のグラフ検索結果のキャッシュ? -
kv_store_text_chunks.json: 各テキストチャンクの実体 -
lightrag.log: ログ -
vdb_chunks.json: テキストチャンクのベクトルデータ -
vdb_entities.json: エンティティのベクトルデータ -
vdb_relationships.json: リレーションシップのベクトルデータ
では検索を行ってみる。検索は4つの選択肢がある。naiveはチャンクのベクトル検索、localとglobalは恐らくGraphRAGを踏襲していて、hybridはglobalとlocalの組み合わせなのだろう。
naivelocalglobalhybrid
それぞれで検索してみる。
naive
print(rag.query("オグリキャップの戦績をまとめると?", param=QueryParam(mode="naive")))
INFO:lightrag:Truncate 27 to 3 chunks
オグリキャップは、日本の競走馬であり、特に1980年代に活躍した名馬です。彼の戦績は非常に優れたもので、数々の重賞レースでの勝利が記録されています。オグリキャップはそのキャリアの中で多くの競走馬の中でも際立つ存在となり、ファンからの絶大な支持を受けました。彼の主な戦績としては、1988年の有馬記念での勝利が挙げられます。このレースでの優勝はオグリキャップにとっても象徴的なもので、彼の名声を不動のものにしました。また、オグリキャップはその他にも、1989年の毎日王冠や1990年の天皇賞(秋)など多くの重要なレースで優勝しており、特に中央移籍後の活躍が目立ちます。
競走成績を細かく見ると、オグリキャップは重賞レースでの勝利が数多く、時には圧倒的な差をつけて勝利することもありました。その走りは競馬ファンの心をつかみ、彼の存在は「競馬の神話」を形成する一因となりました。
オグリキャップの戦績は決して単なる数字の集合ではなく、日本競馬の歴史における感動とドラマを含んでいます。競走馬としての素晴らしい才能はもちろん、彼が競走中に魅せた勇気や苦悩、そして勝利の瞬間は、ファンにとって忘れがたい思い出となっています。
local
print(rag.query("オグリキャップの戦績をまとめると?", param=QueryParam(mode="local")))
INFO:lightrag:Local query uses 60 entites, 43 relations, 3 text units
オグリキャップの戦績まとめ
概要
オグリキャップは日本の競走馬で、特に1980年代後半から1990年代初頭にかけて活躍しました。その魅力とパフォーマンスは多くの競馬ファンを魅了し、数々の名勝負を繰り広げました。彼の戦績は、重賞レースへの多くの出場と、そこから得られた優勝によって特徴づけられています。
主なレースと成果
- 第35回有馬記念
- オグリキャップはこのレースで優勝し、広く注目を集めました。1988年のこのレースにおいて、彼は多くのファンにその名を知らしめることとなりました。
- 天皇賞(秋)
- オグリキャップは天皇賞(秋)に出走し、結果的に2着となりました。このレースは彼の競走馬としての評価に影響を与える重要なイベントとなりました。
- 高松宮杯
- このレースでオグリキャップは優勝し、その勝利により競走馬としての地位をさらに確立しました。この勝利は彼にとって重要な一歩であり、競馬界での認知度を高めました。
- 毎日王冠
- オグリキャップはこのレースでの勝利を通じて重賞連勝記録を達成しました。特に1989年の開催では、彼のパフォーマンスが高く評価されました。
- 毎日杯
- このレースにはオグリキャップが出走し、その結果は彼の競走能力を示すものでした。優れた成績を残し、さらなる名声を築きました。
結論
オグリキャップの戦績は、数々の重賞レースでの成功によって形作られており、その多くが競馬ファンの記憶に残る名勝負となっています。特に有馬記念や天皇賞(秋)などの重要なレースでのパフォーマンスによって、彼は競走馬界において不動の地位を築くことができました。彼の存在は日本競馬史において特筆されるべきものであり、多くの人々に愛され続けています。
global
print(rag.query("オグリキャップの戦績をまとめると?", param=QueryParam(mode="global")))
INFO:lightrag:Global query uses 44 entites, 60 relations, 3 text units
オグリキャップの戦績概要
オグリキャップは、1980年代から1990年代にかけて活躍した日本の競走馬であり、その戦績は非常に輝かしいものです。彼は多くの著名なレースに出走し、数々の勝利を収め、競馬史上の名馬として名を馳せています。
主な競走成績
オグリキャップは特に以下のレースでの成績が際立っています:
- 有馬記念
- オグリキャップは1988年に初勝利を収め、その後も1991年に再び勝利しました。このレースは彼のキャリアにおいて特に重要で、ファンからの支持も厚く、「オグリコール」が起こるなど、その人気を証明しました。
- ジャパンカップ
- ジャパンカップでは、1990年に出走し、特に1991年に世界レコードタイムで走ったとされています。オグリキャップはこのレースで2着に終わったことがあり、競走馬としての能力を証明しましたが、結果として彼の晩年に影響を与えるレースでもありました。
- 毎日王冠
- 1989年、オグリキャップはこのレースで史上初の連覇を達成し、その実力を強く印象づけました。
- 天皇賞(秋)
- 1990年には、天皇賞(秋)に出走し、結果は2着でした。このレースでは彼のパフォーマンスが評価されていましたが、その後の不振につながる要因があったとも言われています。
その他のレース
オグリキャップは他にも、マイルチャンピオンシップや宝塚記念、安田記念など数多くの重賞に出走し、多くの勝利を収めています。これにより、彼は数々の重賞タイトルを獲得し、その地位を不動にしました。
引退後
引退後、オグリキャップは優駿スタリオンステーションにて種牡馬生活を送り、その血統は今でも競馬界に影響を与え続けています。彼の息子や兄弟馬も競走馬として成功を収めており、オグリキャップの名前は競馬ファンの心に永遠に残ることでしょう。
総括
オグリキャップの戦績は、ただの数字の羅列ではなく、彼がもたらした興奮と感動、そして日本競馬界における影響を体現しています。彼の活躍は、競馬ファンにとっての特別な記憶として今なお鮮明に思い起こされ、多くの人々に愛され続けています。
hybrid
print(rag.query("オグリキャップの戦績をまとめると?", param=QueryParam(mode="hybird")))
INFO:lightrag:Local query uses 60 entites, 43 relations, 3 text units
INFO:lightrag:Global query uses 44 entites, 60 relations, 3 text unitsオグリキャップの戦績の概要
オグリキャップは、1988年から1990年にかけて活躍した日本の競走馬で、その名前は広く知られています。彼の戦績は、数々の名馬との対戦や特筆すべきイベントに彩られています。以下に、オグリキャップの主要な戦績をご紹介します。
主なレース
- 有馬記念:
- オグリキャップはこのレースでの活躍によって名声を高め、特に1989年に勝利を収めたことは、そのキャリアにおいて重要な出来事となりました。この勝利によって彼は日本競馬界での歴史的な地位を確立しました。
- 毎日王冠:
- 1989年、オグリキャップはこのレースで史上初の連覇を達成しました。レースでの力強いパフォーマンスにより、彼の名声はさらに高まりました。
- 高松宮杯:
- 有名なこの競走でもオグリキャップが優勝し、彼の能力を改めて証明しました。このレースは特に多くのファンから注目を集めました。
- ジャパンカップ:
- オグリキャップはこの国際的なレースにも参加しましたが、最終的には2着に終わる結果となりました。このレースの後、高評価を受ける一方で、その後のパフォーマンスに関する分析が行われました。
競走馬としての影響
オグリキャップの競走成績は、彼自身の神秘的な存在感や人気に大きく寄与しました。特に彼のレースにおける強さと独特の騎手との相性は、多くのファンを魅了し、競馬熱を高める要因となりました。岡部幸雄や武豊といった名騎手との関係も、彼の成功に一役買いました。
後の功績
オグリキャップは、引退後も種牡馬としての活動を通じて、競馬界に多大な影響を与え続けました。優駿スタリオンステーションでの生活は、競走馬としての功績を受け継ぐ形でファンからも支持されています。オグリキャップの名前は、現在も競馬の記憶として多くの人々に語り継がれています。
結論
オグリキャップは、その力強い走りと栄光の数々によって日本競馬のアイコンとなりました。彼の戦績は決して短いものではなく、競馬界における名勝負や記録に満ちているため、今後も語り継がれることでしょう。
とてもシンプルに書けて回答もいい感じに思えるのだけど、レポジトリにはドキュメントがあまりなくて、ちょっと論文なりコードを読まないとよくわからない感がある。
で、色々みていると、どうやらLightRAGは以下をベースにしているみたい。
nano-graphrag
シンプルで簡単にハックできるGraphRAGの実装
😭 GraphRAGは強力で良いものですが、公式実装は読みづらく、ハックするのが難しいです。
😊 このプロジェクトは、より小さく、高速で、クリーンなGraphRAGを提供する一方で、コア機能はそのまま残っています(ベンチマークとイシューを参照)。
🎁
テストとプロンプトを除いて、nano-graphragは約1100行のコードです。
コンポーネント
以下は利用可能なコンポーネントです。
タイプ 何? どこ? LLM OpenAI ビルトイン DeepSeek サンプル ollama サンプル Embedding OpenAI ビルトイン Sentence-transformers サンプル ベクトルデータベース nano-vectordb ビルトイン hnswlib ビルトイン、サンプル milvus-lite サンプル faiss サンプル グラフストレージ networkx ビルトイン neo4j ビルトイン(ドキュメント) 可視化 graphml サンプル チャンキング トークンサイズによる ビルトイン テキストスプリッターによる ビルトイン
ビルトインとは、nano-graphrag内にその実装があることを意味します。サンプルとは、examplesフォルダ内のチュートリアル内にその実装があることを意味します。- examples/benchmarksをチェックして、コンポーネント間の比較をいくつかご覧ください。
- より多くのコンポーネントの提供はいつでも歓迎します。
色々サンプルが豊富に用意されている。ある程度はLightRAGにも流用できそうな気がするので、こちらも確認してみる。
確認してみたけど、LightRAGはいろいろnano-graphragから不要なものとかは削ってる感があるっぽいなぁ・・・nano-graphragだとneo4jとかに対応してるんだけど、LightRAGにはない。ちょっともったいないな。
逆に言うと今あるものがすべてって感じかも。コードベースも大きくないしちょっとCursorで色々追加するのがよいかもね。
それぞれのファイルはざっくりこんな感じかな?詳細まではわからないけど。
- graph_chunk_entity_relation.graphml: GraphMLのXMLデータ
このGraphMLのXMLデータがあれば可視化が可能。nano-graphragのexamplesからコードを引っ張ってきて、ちょっと修正した。
import networkx as nx
import json
import os
import webbrowser
import http.server
import socketserver
import threading
def graphml_to_json(graphml_file):
G = nx.read_graphml(graphml_file)
data = nx.node_link_data(G)
return json.dumps(data)
def create_html(html_path):
html_content = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Graph Visualization</title>
<script src="https://d3js.org/d3.v7.min.js"></script>
<style>
body, html {
margin: 0;
padding: 0;
width: 100%;
height: 100%;
overflow: hidden;
}
svg {
width: 100%;
height: 100%;
}
.links line {
stroke: #999;
stroke-opacity: 0.6;
}
.nodes circle {
stroke: #fff;
stroke-width: 1.5px;
}
.node-label {
font-size: 12px;
pointer-events: none;
}
.link-label {
font-size: 10px;
fill: #666;
pointer-events: none;
opacity: 0;
transition: opacity 0.3s;
}
.link:hover .link-label {
opacity: 1;
}
.tooltip {
position: absolute;
text-align: left;
padding: 10px;
font: 12px sans-serif;
background: lightsteelblue;
border: 0px;
border-radius: 8px;
pointer-events: none;
opacity: 0;
transition: opacity 0.3s;
max-width: 300px;
}
.legend {
position: absolute;
top: 10px;
right: 10px;
background-color: rgba(255, 255, 255, 0.8);
padding: 10px;
border-radius: 5px;
}
.legend-item {
margin: 5px 0;
}
.legend-color {
display: inline-block;
width: 20px;
height: 20px;
margin-right: 5px;
vertical-align: middle;
}
</style>
</head>
<body>
<svg></svg>
<div class="tooltip"></div>
<div class="legend"></div>
<script type="text/javascript" src="./graph_json.js"></script>
<script>
const graphData = graphJson;
const svg = d3.select("svg"),
width = window.innerWidth,
height = window.innerHeight;
svg.attr("viewBox", [0, 0, width, height]);
const g = svg.append("g");
const entityTypes = [...new Set(graphData.nodes.map(d => d.entity_type))];
const color = d3.scaleOrdinal(d3.schemeCategory10).domain(entityTypes);
const simulation = d3.forceSimulation(graphData.nodes)
.force("link", d3.forceLink(graphData.links).id(d => d.id).distance(150))
.force("charge", d3.forceManyBody().strength(-300))
.force("center", d3.forceCenter(width / 2, height / 2))
.force("collide", d3.forceCollide().radius(30));
const linkGroup = g.append("g")
.attr("class", "links")
.selectAll("g")
.data(graphData.links)
.enter().append("g")
.attr("class", "link");
const link = linkGroup.append("line")
.attr("stroke-width", d => Math.sqrt(d.value));
const linkLabel = linkGroup.append("text")
.attr("class", "link-label")
.text(d => d.description || "");
const node = g.append("g")
.attr("class", "nodes")
.selectAll("circle")
.data(graphData.nodes)
.enter().append("circle")
.attr("r", 5)
.attr("fill", d => color(d.entity_type))
.call(d3.drag()
.on("start", dragstarted)
.on("drag", dragged)
.on("end", dragended));
const nodeLabel = g.append("g")
.attr("class", "node-labels")
.selectAll("text")
.data(graphData.nodes)
.enter().append("text")
.attr("class", "node-label")
.text(d => d.id);
const tooltip = d3.select(".tooltip");
node.on("mouseover", function(event, d) {
tooltip.transition()
.duration(200)
.style("opacity", .9);
tooltip.html(`<strong>${d.id}</strong><br>Entity Type: ${d.entity_type}<br>Description: ${d.description || "N/A"}`)
.style("left", (event.pageX + 10) + "px")
.style("top", (event.pageY - 28) + "px");
})
.on("mouseout", function(d) {
tooltip.transition()
.duration(500)
.style("opacity", 0);
});
const legend = d3.select(".legend");
entityTypes.forEach(type => {
legend.append("div")
.attr("class", "legend-item")
.html(`<span class="legend-color" style="background-color: ${color(type)}"></span>${type}`);
});
simulation
.nodes(graphData.nodes)
.on("tick", ticked);
simulation.force("link")
.links(graphData.links);
function ticked() {
link
.attr("x1", d => d.source.x)
.attr("y1", d => d.source.y)
.attr("x2", d => d.target.x)
.attr("y2", d => d.target.y);
linkLabel
.attr("x", d => (d.source.x + d.target.x) / 2)
.attr("y", d => (d.source.y + d.target.y) / 2)
.attr("text-anchor", "middle")
.attr("dominant-baseline", "middle");
node
.attr("cx", d => d.x)
.attr("cy", d => d.y);
nodeLabel
.attr("x", d => d.x + 8)
.attr("y", d => d.y + 3);
}
function dragstarted(event) {
if (!event.active) simulation.alphaTarget(0.3).restart();
event.subject.fx = event.subject.x;
event.subject.fy = event.subject.y;
}
function dragged(event) {
event.subject.fx = event.x;
event.subject.fy = event.y;
}
function dragended(event) {
if (!event.active) simulation.alphaTarget(0);
event.subject.fx = null;
event.subject.fy = null;
}
const zoom = d3.zoom()
.scaleExtent([0.1, 10])
.on("zoom", zoomed);
svg.call(zoom);
function zoomed(event) {
g.attr("transform", event.transform);
}
</script>
</body>
</html>
'''
with open(html_path, 'w', encoding='utf-8') as f:
f.write(html_content)
def create_json(json_data, json_path):
json_data = "var graphJson = " + json_data.replace('\\"', '').replace("'", "\\'").replace("\n", "")
with open(json_path, 'w', encoding='utf-8') as f:
f.write(json_data)
def visualize_graphml(graphml_file, html_path):
json_data = graphml_to_json(graphml_file)
html_dir = os.path.dirname(html_path)
if not os.path.exists(html_dir):
os.makedirs(html_dir)
json_path = os.path.join(html_dir, 'graph_json.js')
create_json(json_data, json_path)
create_html(html_path)
visualize_graphml(
"oguricap/graph_chunk_entity_relation.graphml",
"html/graph_visualization.html"
)
これでhtmlディレクトリ配下に、graph_visualization.htmlとgraph_json.jsが生成されるので、両方ダウンロードしてブラウザでHTMLファイルを開けば良い。こんな感じで表示される。
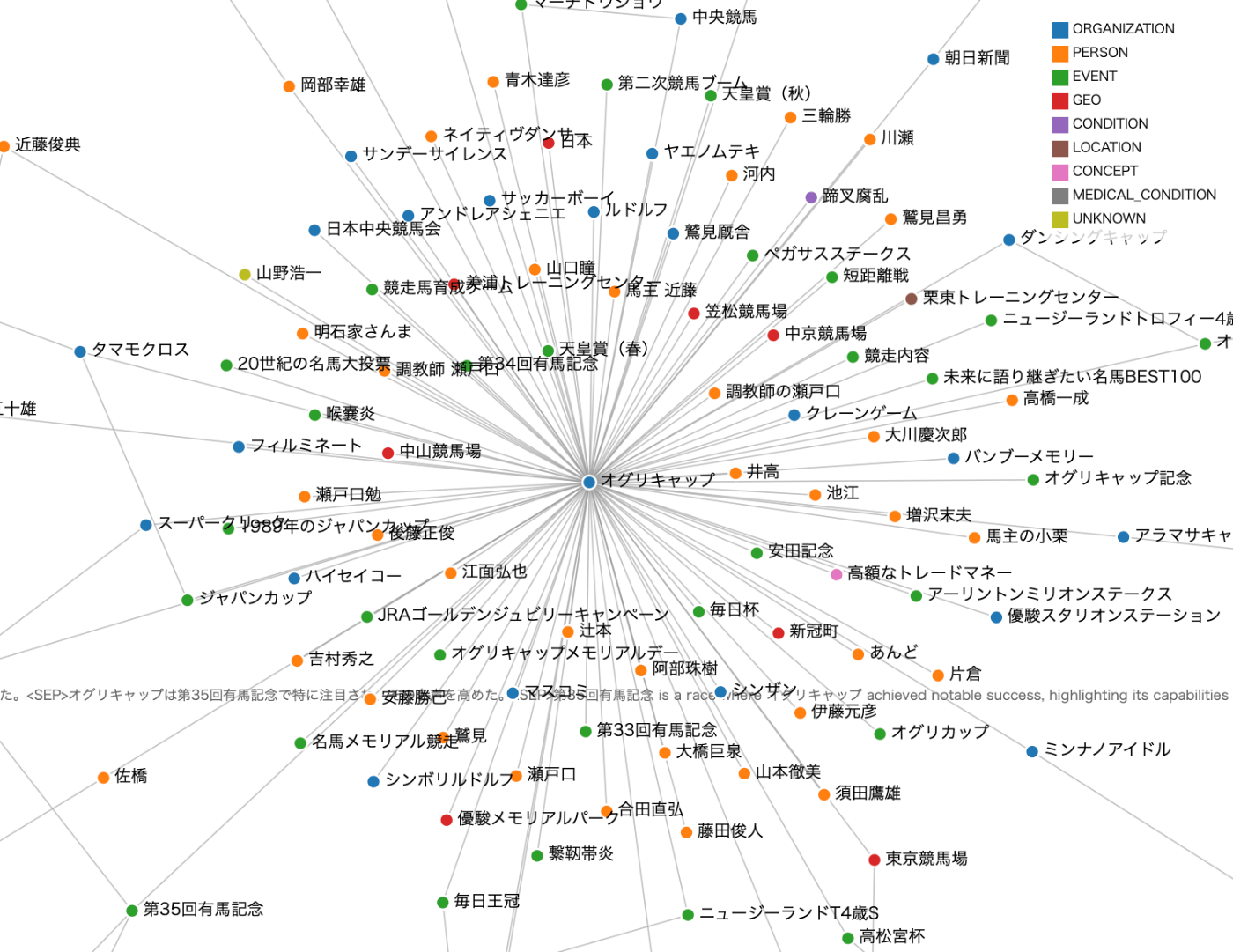
検索結果をグラフにできるといいんだけどねぇ・・・
まとめ
MS公式のGraphRAGに比べると、かなりシンプルに書けて、公式よりも精度が高いGraphRAGが実現できるのは良い。このシンプルさはLightRAGのベースになってるnano-graphragの恩恵もあると思う。
nano-graphragも一応試してみたのだけど、ざっくり定性的にはLightRAGの回答のほうが精度がよかったように思えた。ただその反面、nano-graphragにあるいろいろなインテグレーションはLightRAGでは削られていたりもするので、そこはちょっともったいないところ。LightRAGからnano-graphragにバックポートしてくれないかなと思ったりもする。
まあ、どちらを触るにせよコードベースは小さめなので、コードの中身を追っかけたり、カスタマイズしたりってのもやりやすそう。とりあえずフォークしていろいろ触ってみたいと思う。
いろいろ更新されていた
- グラフのストレージにNeo4Jが追加
-
textractに対応、PDF、DOC、PPT、CSVなど、読み込めるドキュメントが増加 - グラフの可視化が可能に
nano-graphragとはもう別の道になりそうだけど、徐々に使い勝手は上がっていってるかも。