導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。
今回は、RAGの要であるEmbeddingの性能を大きく低下させてしまう、文章の特性について解説します。
このブログで紹介している内容は以下の論文を元に作成しておりますので、詳細はそちらをご確認ください。RAGを構成してみたが、どうしても正解の文章を取ってこれない!そんなときはもしかするとこの論文で紹介されているような文章になってしまっているかもしれません。
サマリー
Embeddingは、RAGの検索能力の根幹に関わる機能ですが、そのの性能や特性についてはあまり知られてはいません。実は、保管するテキストの文体や分割方法次第で最大90%程度、検索性能が下がってしまいます。
今回紹介する論文では、Embeddingの性能を著しく下げるテキストの特徴を調べ、その性質についてまとめています。特に「文章の位置」、「使用する単語」、「文章量」による影響が大きいとされています。残念ながら具体的な対策は提示されていませんので、対応策の例として、これまでに紹介した記事をあわせて明記しておきました。そちらもぜひ、ご確認ください。
問題意識
Embeddingの特徴と数値的な意味
Embeddingがどういったものかおさらいします。Embeddingは、主に数百文字程度の文章を数百次元以上のベクトルデータに置き換える機能を有しています。そして、このベクトルデータには以下のような特徴があります。
- ベクトルデータは、文章の意味を表している
- ベクトルデータの内積が1に近いほど2つの文章の意味は類似している
厳密には異なる特性を持つものもありますが、RAGについて考えるうえではこの理解で十分です。特に内積を取るだけで文章の類似度がわかるという性質のお陰で、EmbeddingはRAGの主要な検索機能としての役割を果たしています。
Embeddingの限界
しかし、Embeddingにも限界があり一般的には「固有名詞に弱い」と言われています。これは、Embeddingの学習内で利用されてこなかった単語の意味をEmbeddingが理解できないためです。これは一つの例ですが、論文内では更に以下の要素によってEmbeddingの性能が下がると言及されています。
- 位置バイアス: 重要な情報が文章内のどの位置にあるか
- 単語バイアス: 意味と関係なく同じ単語が含まれているか
- 文章量バイアス: 文章量が多いか少ないか
Embeddingの性能を引き下げる文章の特徴
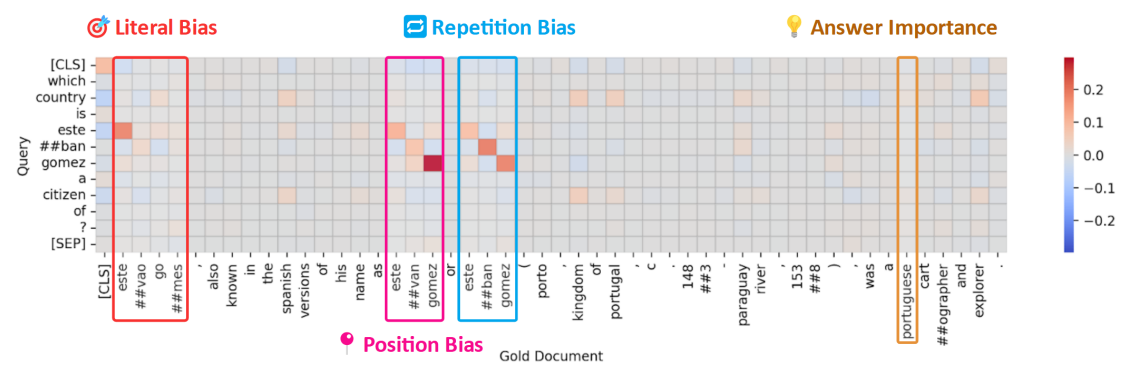
ここでは、各種の文章の傾向によって生じる文章間の類似度の低下についてまとめています。比較に使用されている数値は、割合を表すものではなくt検定と呼ばれる比較手法で得られる値(t値)で、値が大きいほどずれが大きいことを示しています。
位置バイアス
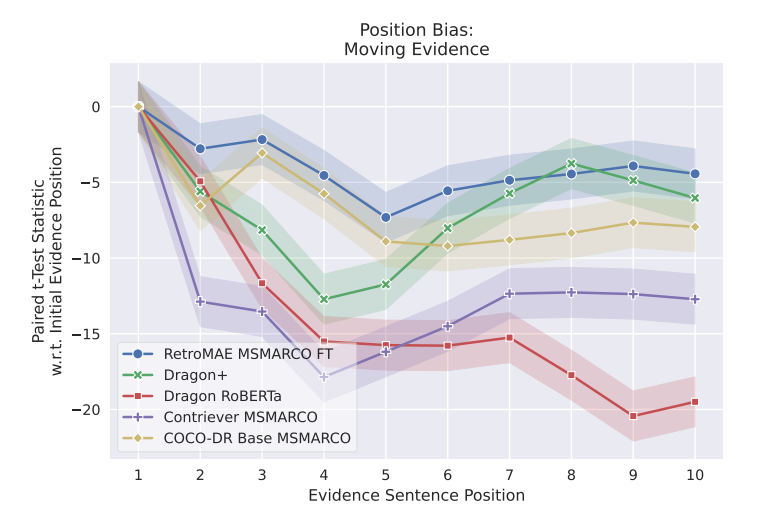
入力したクエリに対する回答が、どの位置にあるかによって類似度がどのように変化するかを示したグラフです。文章の先頭にある状態が最も類似度の高い状態で、そこから減少していきモデルごとに最も性能が下がるポイントは異なりますが、誤差の範囲の7~20倍ものズレが発生していまうことを示しています。
【対抗策】
単語バイアス

意味は同じだが、表記が異なる(例えば"US"と"United States")とドキュメントの類似度に誤差の範囲の20倍以上の差が生まれます。たとえば、「United States」を含むクエリで検索した場合、対象のドキュメントが「United States」なのか「US」なのかで、大きな差が生まれることになります。
【対抗策】
文章量バイアス
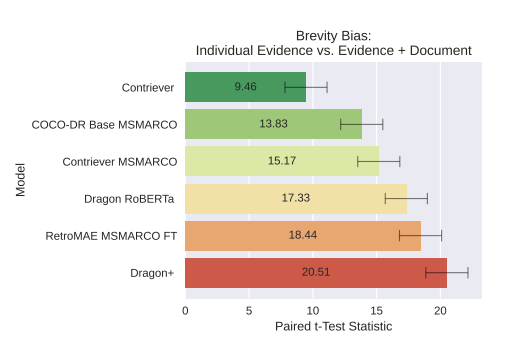
保管されている文章の長さによる類似度の比較結果です。この結果は正解となる文章だけの場合と、正解とは無関係な文章を含んだ場合で、類似度にどの程度差が生まれるかを示しています。
【対抗策】
精度への影響
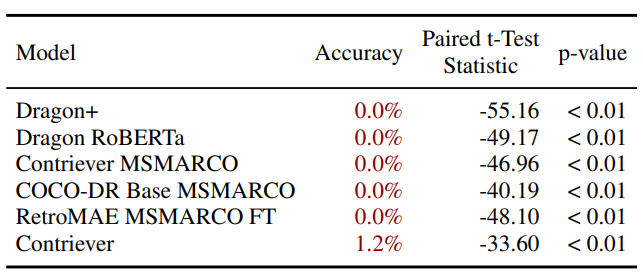
正解を含むが関係のない文章も含む正解ドキュメントと、正解を含まないがEmbeddingが一致していると導きたくなる特徴を持つ不正解ドキュメントを比較して、正解ドキュメントを類似していると判断できるかを実験しています。結果として、圧倒的に不正解ドキュメントを取得する傾向にあり、正解ドキュメントを選べる確率はほぼ0%となっています。
まとめ
ドキュメントの特徴による、Embedding性能への影響についてまとめた論文を紹介しました。最後の「精度の影響」に記載されるような極端な例はそう多くは無いですが、これらのバイアスが反映されることで知らず知らずのうちにRAGの性能を引き下げることがあります。実際にRAGを運用していると、他にも、「意味的な区切りを無視して文章を分割してしまうことで意味が損なわれるケース」や、「パソコンの再起動」と「アプリの再起動」のように言葉としては似ているが、使われ方が全く違うような言葉が類似していると判定されてしまうといったケースがあげられます。汎用的に問題に対処するのは難しいので、自身のユースケースを見極めて、それにあった対処法を見つけることが重要です。対抗策に示された手法も、一つの対策になるのでぜひご活用ください。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion