導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
本記事では、RAGの文書検索をより正確に行えるようにするための技術、RAPTORについて紹介いたします。
RAPTORは、よりユーザーの質問に沿った文書を取得できるようになるため、LLMを使用する際の費用や時間を抑えることが可能になります。
サマリー
RAPTORは、効率的な文書の階層構造を構築することで、効率的な文書の検索を実現しています。
論文内ではRAPTORの特徴を以下のように提言しています。
- 文書を複数のレベルで要約することで、長文を含む文書を効率的に保管できるようになった
- GPT-4やUnifiedQAと組み合わせることで、3つのQAタスクで非常に高い成果をあげられた
この記事について
この記事では、RAPTORの仕組みの解説とその成果について解説します。
概要の把握を目指していますので、細かな計算式等は省いています。
より詳細な情報は元の論文を参照してください。
この仕組みは長い文書を効率的に検索できる手法を提案するものとなっているので、基本的にはRAGでの使用を想定した技術となっています。
RAGそのものの解説や、性能向上のためのその他の手法については以下の記事も参考にしてみてください。
解説
RAPTORの誕生の経緯と動作手順について解説します。
問題意識
なぜRetrievalなのか?
LLMの性能の向上により、入力できる文書は大幅に増加しています。このため、選択的に文書を選ばなくともすべての文書をLLMにわたすことで、必要な情報を適切に抜き出すことが可能になりつつあります。そのため、わざわざRetrievalなどの仕組みを用いて文書を選択する必要性は一見薄れているように思えます。
しかし、入力する文章が長大になれば、時間、金額、正確性のすべての要素でマイナスに働きます。当然これらの問題も時間とともに解決されていくことが想定されますが、多くの場合でRetrievalの改善のほうが成果が上がりやすく、Retrievalの必要性は結果としてさらに増しています。
なぜ要約が必要なのか?
文書の保管方法の研究が進められていますが、その多くは標準的なアプローチ、つまり連続的な文字列を任意の長さで分解しそれを保管、そしてベクトルデータを元に検索するという手法が取られています。
しかし、こうした連続的な文書の分割だけでは、文書全体の意味を捉えきることができないという問題をはらんでいるとされています。
この問題に対して、再帰的な文書の要約を導入することで、情報がより集約的になり広範な情報を取り扱えるようになり、こうした手法はいくつか提唱されています。
なぜRAPTORなのか?
文書の要約を検索対象とする方法により、文書全体の把握が得意になる一方で、その手法だけでは文書内での距離が遠い場合、つまり別々の場所に記載された内容を集約することができません。これに対してRAPTORは、チャンクの意味的な近さを元にグループ化しその内容を要約する手法を採用するしています。これにより、長い文章で発生しやすい意味的には近いが文章の位置としては遠いものを集約することができるようになっており、より効率的な情報の集約を実現しています。
手法
RAPTORのより詳細な動作手法を紹介します。
保存手順
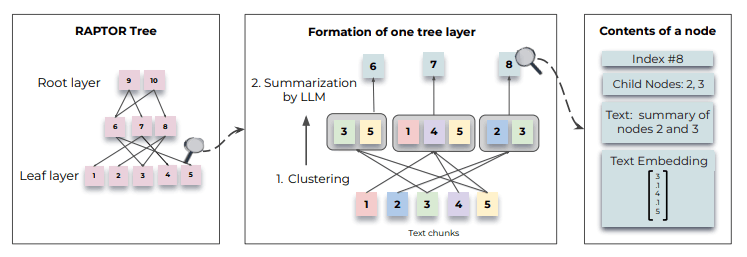
RAPTORは、文書を保管する際にチャンクのベクトル化とグループ化そしてLLMによる要約を繰り返し文書を保管します。この仕組みをより詳細に説明します。
1. 文書のチャンク化
一番最初の手順としては、文書を100トークン以下ごとに分割し、それをチャンクとして扱います。このとき、100トークン目が文章の途中であった場合、文章を丸ごと次のチャンクに保管するようにします。これにより文章の途中でテキストが分割されてしまう問題を防いでいます。
2. チャンクのグループ化
ここからの処理は再帰的な処理の一部となります。一つ前の段階で得られたチャンクを元に処理を行います。
チャンクのグループ化を行なう際に特徴的な点として、チャンクが複数のグループに所属できるようにしている点です。この柔軟性により、そのチャンクが複数のトピックを内包している場合であっても、各トピックで必要な情報を欠落させずに済むようになります。
RAPTORで採用されている集約アルゴリズムはGaussian Mixture Models (GMMs)をベースに作成されています。この手法は柔軟性と正確性をバランスよく考慮した枠組みとなっています。
GMMsでは、データは複数のガウス分布を重ね合わせたものとして捉えており、これをチャンクごとのベクトルデータに応用します。その際に課題になるのが、類似性の判断方法です。チャンクのEmbeddingによって得られたベクトルデータの類似性を測定する際に、距離を使用すると適切に動作しない可能性があります。これはベクトル間の距離をベースにクラスタリングを行なうGMMsのフレームワークから考えると問題となります。そこでRAPTORでは、ベクトルデータに対して、Uniform Manifold Approximation and Projection(UMAP)を採用することで、次元削減を行いそのデータを使用しています。
GMMsを利用するうえで次に考えないといけないのは、最適な分割数の決定です。これには、Bayesian Information Criterion (BIC)を採用します。この手法によって決定された数字を元にGMMのパラメータを Expectation-Maximization algorithmを用いて推定します。
ベクトルデータをクラスタリングしていくなかで、特定のクラスタにデータが集中することがあります。要約を実行する都合上、一つのデータにチャンクが集中するのを避けたいため、データが集中したグループの中でさらに再帰的にクラスタの作成を行い、すべてのクラスタ内のチャンクのトークン合計が一定以下になるまで繰り返していきます。すべてのクラスタのトークン合計が一定量を下回った段階で、その時点でのクラスタが一つ一つのグループとしてあつかわれることになります。
3. グループに含まれるチャンクの要約
意味的に近いチャンク同士をグループ化したあとは、その内容をLLMを使用して要約します。要約に使用するグループのトークン数は、グループ化の際にすでに制限をかけながら実行されていたため、特に問題にならないです。
論文内では、gpt-3.5-turboを使用して要約しています。この要約を分析したところ、4%程度の要約に小さなHallucinationが含まれていました。しかし、親ノードへの集約やLLMにわたすデータに含まれた際の影響は殆ど見受けられなかったと記述されています。
余談ではありますが、この要約タスクはもしかすると以前紹介したLLMLingua-2を応用することができるかもしれません。
4. 手順2, 手順3の繰り返し
手順3で生成されたチャンクを手順2で再びグループ化します。
この作業を最終的に一つにグループがまとまるまで繰り返していきます。
生成されたチャンクはベクトルDB等に保管することになりますが、その際には階層構造を把握できるようにするために親のID等を保持して検索できるようにする必要があります。
検索手順
RAPTORは、要約などを含むチャンクデータに対して二種類の検索手順を提案しています。
ただし実験の結果collapsed treeの2000トークンが一番精度が出たようなので、今後示す結果は主にその方法、値を採用しているみたいです。

1. tree traversal
tree traversalという手法では以下のような手順で関連文書を取得します。
- Rootの階層でコサイン類似度の近い任意の個数のチャンクを検索
- 取得したチャンクの子要素の中で再度コサイン類似度の近いチャンクを取り出す
- 2の手順を末端のチャンクに至るまで繰り返す。
- 取得したチャンクのうち、コサイン類似度の近い任意の個数のチャンクを取得する
2. collapsed tree
collapsed treeという手法では以下のような手順で関連文書を取得します。
- 階層に関係なくコサイン類似度を計算し、任意の個数のチャンクを取得する
- あらかじめ設定した上限トークン数に至るまで繰り返しチャンクを取得していく
成果
RAPTORは以下の3つのデータセットで成果を検証しています。
- 物語文書検索タスク(NarrativeQA): 本や映画の内容を表す文章を元にしている。質問に対して答えるタスクを実行しており、いくつかの評価基準で評価している。
- NLP論文の全文(QASPER):NLP論文の全文と5000個ほどの質問に対して、選択式の質問となっている
- 文章に基づく多選択肢問題(QuALITY):5000トークンほどの文章の中から複数選択肢の中の正解を見つけるタスクとなっている。

RAPTORを使用、もしくは不使用な場合の物語文書検索タスクの精度に関する結果では、すべての評価方法、手法で精度が向上していることが確認できる。

この他にも、NLP論文の全文や文章に基づく多選択肢問題における精度も軒並み向上しています。
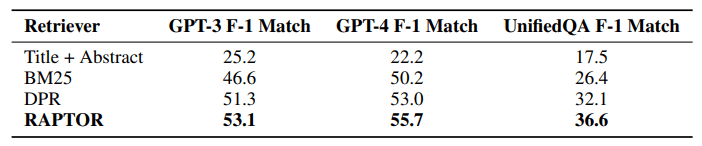
また、調査対象となっているGPT-3, GPT-4, UnifiedQAをLLMとして利用した場合であっても、BM25、DPRを使用した場合よりも高い精度が実現できているようです。
少なくとも既存のチャンク化のみの手法と比べるとRAPTORを導入することはプラスに働いていると言えそうです。

再び物語文書検索タスクについて複数のモデルで結果を比較したところ、一部では一番良い成果を上げたものの他の評価方法では、Retriever + Readerの次点の成果となったようです。

NLP論文の全文に対する選択タスクは、長文をそのまま扱えるモデルを使用した場合と比較して高い成果を上げているようです。個人的には、他の検索手法との比較があるとより成果がわかりやすかったなという印象です。

文章に基づく多選択肢問題のタスクについては、専用に作られたAIモデルと比較してもGPT-4と組み合わせることでこれまでの成果を大きく超えることに成功したようです。
まとめ
汎用的な手法でRAGの精度を改善できる手法ということで、このRAPTORという手法は面白そうです。特に、日本語だと精度が下がりそうな要素が見受けられなかったのも個人的にはポイントが高いです。記事の途中にも記載しましたが、要約タスクにおけるLLMLingua-2との親和性も気になります。
一方で、成果の提示の中での比較対象として、同じRetrievalで別の手法を試したものが含まれていなかった点は気になりました。実際にシステムに組み込んで成果が見込まれるかどうかの検証はこれからの課題になると思います。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion