導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、サービスのシステム開発を行なっています。サービスではLLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
本記事では、入力するプロンプトの圧縮を効率的に行うための技術、LLMLingua-2について解説します。

LLMLingua-2は、いくつかの手法を組み合わせることによって、品質を下げないままプロンプトを圧縮してくれます。
サマリー
LLMLingua-2は以下の方法で、情報の欠落を抑えた上でプロンプトのトークン数を大幅に減らすことに成功しています。
- ターゲットとなるLLM(GPT-4など)にプロンプトの圧縮タスクを行なってもらう
- そのデータを基に入力したプロンプトを構成するトークンの不要、必要を判断する機械学習モデルを作成する
- 入力に対して上記機械学習モデルを適用し、優先度の高いトークンから順にデータを選択し圧縮プロンプトを作成する
以上のステップで汎用的にプロンプトを圧縮することに成功しています。
この記事について
この記事では、LLMLingua-2の仕組みの解説とその成果について解説します。細かな計算式等は省いて、概要を理解できるように解説しています。細かい部分については、元の論文を参照してください。
この仕組みの応用範囲はプロンプト全般に対して有効なため、特に事前知識は必要ありませんが、仕組みの中ではRAGなどを意識した部分が一部存在しています。
RAGそのものの解説や、性能向上のためのその他の手法については以下の記事も参考にしてみてください。
解説
LLMLingua-2の誕生の経緯とその動作手法について解説します。
問題意識
LLMを使用しているとより正確な回答を得るために、より多くのプロンプトの入力が必要になってきます。しかし、入力するプロンプトを増やすと以下のような問題発生します。
- レスポンスが遅くなる
- LLMの制限により必要なプロンプトを入力できない
- それまでの会話を忘れてしまう
- コストが増える
- パフォーマンスが低下する
(https://github.com/microsoft/LLMLingua より)
個人的には2番目、3番目のプロンプトの長さ制限に起因する問題はLLMの性能の向上により緩和されつつあると思います。
その一方でレスポンスの速度低下、コストの増加、パフォーマンスの低下は課題として残り続けるています。
この問題を解決するために登場したのがLLMLingua-2です。
LLMLingua-2とは
LLMLingua-2は、GPT4が行う圧縮タスクを学習データとして、入力されたデータのトークン単位での必要度合いを計算、高い順に取得という非常にシンプルな仕組みになっています。
また、LLMLingua-2には、前身となるLLMLingua, LongLLMLinguaというものが存在しています。
が、その内容は全く異なるものとなっており共通点といえば、入力するプロンプトの性質ごとに別々の圧縮率をかける(BudgetControl)くらいです。
なので、内容を理解する上でLLMLingua, LongLLMLinguaについて特に知る必要はありません。
少し余談にはなりますが、LLMLinguaは日本語のタスクにおいては、性能が非常に低くなってしまうとされています。以下の記事でとてもわかりやすくまとめられているので参考にしてみてください。
原因として考えられるのは、入力された文章のトークン分割や文章の区切れ目の判断、SegmentのPerplexity計算に用いる小さなモデル(GPT-2など)が日本語に弱いことが想定されます。
これに対して、LLMLingua-2は日本語になることで、パフォーマンスが落ちそうな要素が仕組上見受けられないので、日本語にも応用できることが期待できそうです。(学習が必要な点が難点ではありますが)
手法
ここからは、LLMLingua-2を動作させるために必要な手順を紹介します。
動作手順
LLMLingua-2は、機械学習モデルを使用する関係上、利用の前に別途学習が必要になります。仕組みの概要を理解するために、はじめに利用時の動作の仕組みについて解説します。
1. Budget Control
LLMLingua-2では、入力するプロンプトを instruction, demonstration, questionという種類に分けています。
instructionは、プロンプト内で質問とは別に前提となる動作の要求など行う部分です。例としては「以下の情報をもとにユーザーの質問に回答して下さい」などです。
demonstrationは、回答に必要な情報や例示などLLMの回答の内容をコントロールするために使用されるデータのことを指しています。例としてはRAGシステム内の検索によって得られたデータなどです。
questionは、ユーザーの質問そのものを指しています。例としては、「日本語の文章を要約するのに適したLLMは何ですか?」などです。
以上三つの情報をそれぞれ別々に認識できる状態でデータを渡します。一般的にdemonstrationは、情報が複数存在する場合に冗長な情報を含んでいる可能性が高く、対照的にinstructionとquestionは欠落するとそもそも目的すら伝わらない可能性があるため、相対的にdemonstrationの圧縮率を高めに設定します。
2. Compression Strategy
ここから入力を圧縮していきます。
圧縮したい対象のプロンプトをxとして、トークン化した際の数をNとします。そして、圧縮したい倍率をrとします。
- 最終的に取得するトークン数を決定します。rNです。
- 機械学習モデルを使用して各トークンのprobability(pi)を計算します。
- pi値の高いトークンを上から順にrN個取得し、元の文章と同じ順番に並び替えます。
以上です。
動作時の挙動は非常にシンプルです。
LLMLinguaと比較しても内容は非常にシンプルなだけに理解しやすいです。
学習手順
Compression Strategyの手順の2番目に各トークンのProbabilityを計算すると書きましたが、この計算には機械学習モデルが使用されます。ここからは、その機械学習モデルの学習過程を紹介します。
- ターゲットとなるLLMを対象に、プロンプトの圧縮を依頼する。
- 変換前後のデータを基にDataAnnotationを実施する。
- 圧縮したデータをVariation RateとAlignment Gapの二つの観点から、質の悪いデータを排除する
- 元のプロンプトをBERTでトークン化したものを入力として、各トークンのProbabilityを算出。DataAnnotationの結果との差分を基に損失関数を作成しその値が小さくなるように学習を進めていく
といった手順を踏んでいます。特に教師データを人の手でラベリング等をせずに実施できるのは学習する上で非常に大きなアドバンテージかと思います。
成果
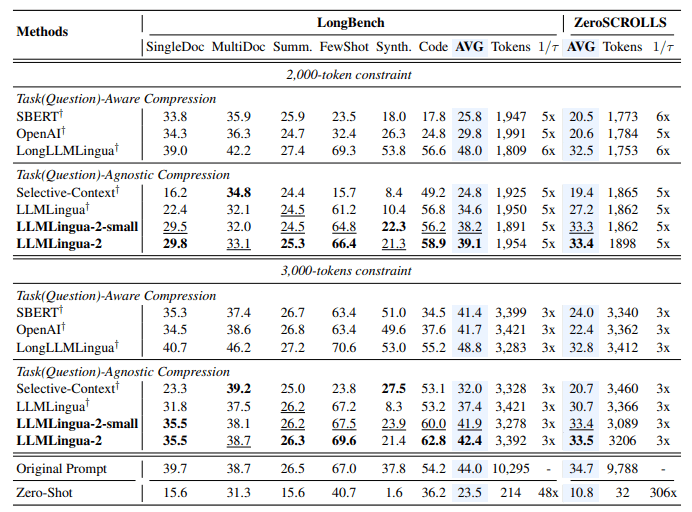
論文では、プロンプト圧縮の先駆けであるSelective-Contextと、LLMLingua, LongLLMLinguaとの比較が行われています。特定のタスクを除いて平均的にあLLMLingua-2の性能が高いことが示唆されています。
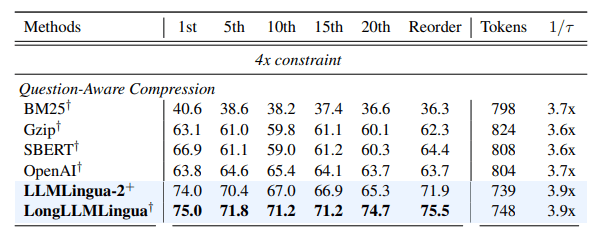
一部のタスク、取り分け質問を意識した圧縮については、LongLLMLinguaの方が精度が高いことが示されています。RAGなどを使用する場合では、LongLLMLinguaの方が相性がいいのかもしれません。

タスクの種類に依存するとは思いますが、プロンプトの長さを20%まで圧縮して更に回答精度も上がるといった結果も見られます。
まとめ
内容は非常にシンプルながら、高い性能を実現できている点はとても良さそうです。学習データの集め方もわかりやすくとても理解しやすいものでした。
特に日本語を対象とすることを想定しても、応用が効きそうな点も良さそうです。
ただ、どんなデータを学習させるとどういった成果が出るのかや、実際に日本語を使用しての成果等はわからないままとなってしまいました。
また、RAGへの応用を考えると、QuestionとDemonstrationの関係性をベースに抽出箇所をコントロールするLongLLMLinguaの考え方の方が相性も良さそうなので、これらの検証はこれからの課題としたいと思います。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion