導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
この記事では、曖昧な質問に対する回答の精度を高め、さらに処理速度を大幅に改善した手法「DIVA」について紹介します。

サマリー
DIVAは、従来のRAGでは対応が難しかった曖昧な質問に対する精度を向上させつつ、他の同様の手法と比べて精度が高く、回答速度も速い点が特徴です。
DIVAの特徴は主に2つあります。1つ目は質問を複数の形に拡張して、検索の多様性を高める「Retrieval Diversification」。2つ目は、得られた情報の有用性を評価する「Adaptive Generation」というフレームワークを採用している点です。これにより、高速かつ高精度な検索結果を得ることが可能です。
問題意識
Embeddingは曖昧な質問が苦手
質問に関連する情報を検索して、その情報を回答に用いるRAGですが質問の内容によっては関連する情報の取得に問題が発生する事があります。
論文中ではその例として「ハリー・ポッターに登場するウィーズリー兄弟を演じたのは誰?」というものがあげられています。この質問の難しいポイントは大きく分けて2つ存在しています。1つ目はウィーズリー兄弟は人数が多いため、例えば「フレッド・ウィーズリー」や「ジョージ・ウィーズリー」などの情報を直接取ってこれない可能性があります。(例えば「ロン・ウィーズリー」の情報ばかり取って来られてしまうなど)さらにハリー・ポッターという言葉に関連して質問とは関係のない「ハリー・ポッター」自身の情報を取ってきてしまうこともあります。
これに対してDIVAは、「ウィーズリー兄弟」というEmbeddingでは認識しづらい意味を、一度LLMに解釈させて「フレッド・ウィーズリー」や「ジョージ・ウィーズリー」として関連情報を取得できるようにする工夫を行っています。
さらに、取得した回答もLLMに渡す前にEmbeddingのスコアでフィルタリングすることで、「ハリー・ポッター」自身などの関係ない情報も除外しています。
手法
DIVAは、データを保管する段階では一般的なRAGの手法と差異がありません。なので、ここではDIVAのドキュメントを取得するまでの手順について解説します。

- ユーザーの質問を受け取り、予測されるより丁寧な質問を複数作成
- 質問ごとにEmbeddingを用いて関連文書を検索し、その中で類似度の低い文書を除外
- 作成された質問と提供された文書を比較して、それぞれの質問に回答できているかを判定
- 一つでも回答できていると判断された場合はドキュメントをLLMに渡して回答。一つも回答できていると判断されなかった場合はLLMに直接回答してもらう
成果
DIVAの成果を確認する前にまず予備実験の結果から見ていこうと思います。
論文内の予備実験ではまず、あるデータセットに対して一般的なRAGを用いてドキュメントを検索してLLM回答させるという実験を行いました。
すると以下のような結果になりました。
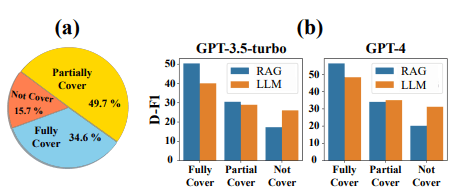
ここでD-F1は評価スコアを表し、Fully Coverは取得したドキュメント内にすべての関連情報が含まれている状態。Partially Coverが部分的に情報を含んでいる状態。そしてNot Coverは関連情報が含まれていないことを表しています。
(b)の結果を見てみるとドキュメント内にすべての回答がある場合は当然RAGの精度が高いですが、正しくない情報を含む場合、そのままLLMだけを使用したほうが結果が良いことが示されています。
次は精度と検索にかかる時間、そして費用をまとめた図になります。

DIVAはそのままのRAGと比べると検索に時間や費用がかかるものの、精度面では最高の値となっており、Iterative RAG(既存の手法)と比較すると時間、費用、精度すべての面で結果を上回っています。
最後に他の手法との比較結果です。

比較対象はVanilla RAG(基本的な機能だけを備えたRAG)、Iterative RAG(ToC)、Self RAGと各種LLMにQuery Refinement(クエリをLLMに調整させること)を使用したものとで比較されています。
速度面はIterative RAGの次に遅くなってしまっていますが、精度の面では他のすべての手法と比べて高い性能を実現しています。
まとめ
質問を多様化してそこから更に取得したドキュメントが必要なデータかを判断することで精度を上げる手法「DIVA」について紹介しました。サービスを提供するうえでこの手法が良いと感じるポイントは、ドキュメントのアップロードが基本的なRAGと差異がないという点です。このため、比較的簡単に実験できるのはかなり推せるポイントかと思います。またこれまでRAGの性能を評価する際に時間まで含めてほしいと言及してきましたが、その点も含めて評価に加えている点も良いポイントです。
そして、予備実験で得られた結果も非常に興味深いものとなっています。この結果から、RAGにおいて中途半端な情報、もしくは関係のない情報を含めてしまうと精度が下がってしまうことを示しています。この結果は別の手法を採用するうえでも重要な観点で、可能であれば関係のある情報だけを厳選してLLMに渡すことが重要であることを示しています。
以上がDIVAの紹介となりましたが、比較的簡単に実装できる手法ですので、ユーザーの曖昧な質問に低コストで対応したいというニーズがある場合には、是非一度お試しください。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion