本記事では、RAGの性能を高めるための「SINR」という手法について、ざっくり理解します。
株式会社ナレッジセンスは、生成AIやRAGを使ったプロダクトを、エンタープライズ企業向けに開発しているスタートアップです。
この記事は何
この記事は、RAGにおける「検索」と「生成のための読み込み」を分離する新手法「SINR」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は、こちらの記事もご参考下さい。
本題
ざっくりサマリー
「SINR」は、RAGの回答精度を高めるための手法です。Dell Technologiesの研究チームによって2025年11月に発表されました。
ちなみに「SINR」は「Search is not Retrieval」の略です。「検索とリトリーバルは違うよ」という主張です。
通常のRAGでは、ドキュメントを細切れ(チャンク)にして、データベースに保管します。そして、ユーザーから質問が来たら、チャンクを 「検索」して、それをそのまま「LLMへの入力」に使います。
しかし、そういう普通のRAGでは「重要な情報が前後のチャンクに分断されてしまう」という課題があります。(参考)。
※チャンクを細切れにするほど、検索の精度は上がりますが、そうすると逆に、LLMに渡す際、文脈が消えてしまいます。
そこで、SINRという手法では、「ベクトル検索に使うチャンク」と「LLMに渡すコンテキストのチャンク」を別々に使うことで、この課題を解決します。
問題意識
適当に実装したRAGでは、「チャンキングで文脈が消える」という課題があります。
実際、RAGで「検索精度が出ない」というお悩みの中でも、この問題が原因であることは、かなり多いです。
そして、検索精度が出ないと「最適なチャンクサイズは何文字だ?」という話になりがちです。
ただ、残念ながら、
そもそもそれは、問いの立て方が間違っています。チャンクのサイズ(文字数)を多くすると、文脈は確保されますが、検索の精度は落ちてしまうためです。基本的にはトレードオフの関係です。
手法
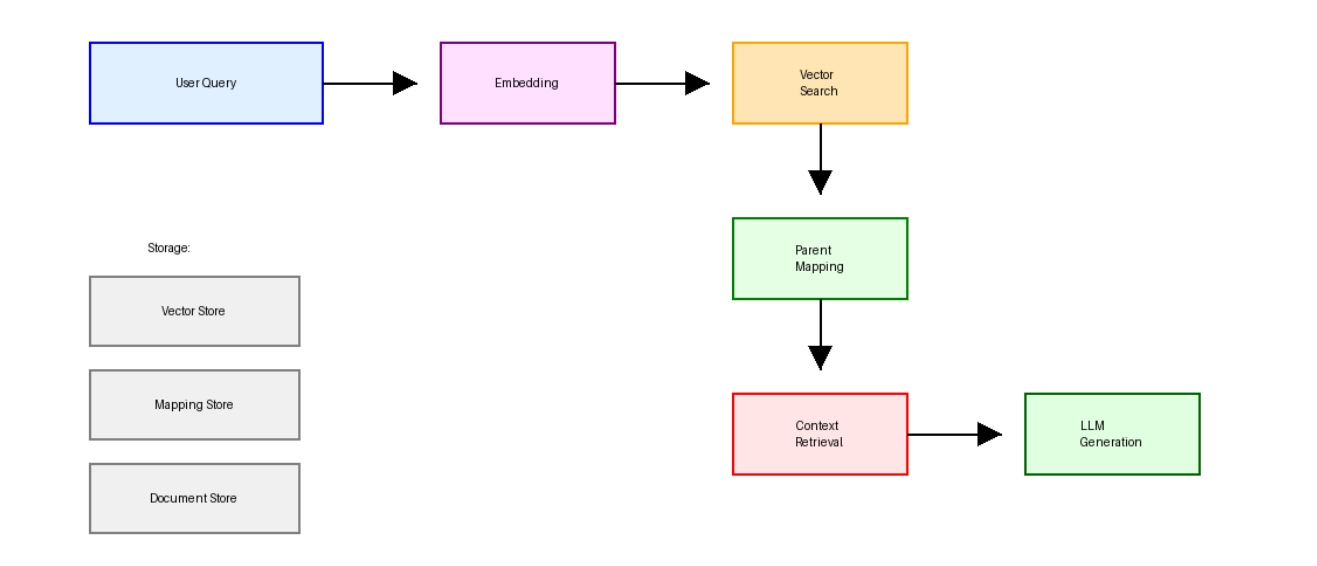
SINRという手法は、ざっくりいうと、データを「親子」の階層構造で管理します。

親子構造の手法で、名前が「SNIR」(読み方はシニアー)なのはシャレでしょうか
【事前にやっておくこと】
-
LLMに渡す用のチャンク作成(親)
- 文書を「意味のまとまり」ごとに大きく区切る(約600〜1000トークン)
-
検索用のチャンク作成(子)
- 1の親チャンクを、さらに細かく区切る(約100〜200トークン)
-
マッピング
- どの「子」がどの「親」に属するか、を紐付けておく
【ユーザーが質問を入力して来たとき】
-
意味検索
- ユーザーの質問に対して、細かい方のチャンクを使ってベクトル検索 -
親チャンクをLLMに渡す
- ヒットした「子」が所属する「親」チャンクを、LLMに渡す
-
参考情報を元に、回答生成
- ここは普通のRAGと同じ
この手法のキモは、検索用のチャンクと活用のチャンクを分けていることです。チャンクの「文字数」自体は、そこまで大きな問題ではありません。
成果

- 検索精度の向上(Recall@20で15〜25%改善)
- 文脈の一貫性の向上(30%向上)
- 検索インデックスサイズの削減(40〜60%削減)
- →小さいチャンクだけを保管するため。(無駄なSliding Windowが不要になる)
- クエリレイテンシの短縮(20〜30%短縮)
まとめ
この手法の手法は、RAGの精度を上げるための非常に基本的な手法です。
今回取り上げたのは2025年の論文ではあるものの、実務としてはかなり前から、精度向上の手法として知られています。(例えば、LangchainのSmall to Big[2]手法など。)
また、これを応用して、要約チャンクを作る手法「RAPTOR」も、定石になりつつあります。
ぜひ、みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion