本記事では、RAGの基本的な仕組みを理解するために、Pythonを使ってゼロからRAGを実装する手順をざっくり解説します。
株式会社ナレッジセンスは、「エンタープライズ企業の膨大なデータを掘り起こし、活用可能にする」プロダクトを開発しているスタートアップです。
この記事は何
この記事では、非エンジニアでも、手元のPCで「RAG」を動かせるというところまで解説したいと思います。
こんな感じでRAGを構築できます。入門から解説します
最近、非エンジニアでも、RAGに興味を持つ方が増えました。
ただ、一方で、RAGの「基本」についての記事は、だいぶ減っています。このままだと、「RAGに詳しい人だけが、さらに詳しくなっていく」という状態になってしまいます。
そこで今回は、入門者向けに、「やってみた」形式で、RAG技術のざっくり解説をしていきます。なるべく簡単に行きます↓
そもそもRAGとは?
RAG(ラグ)は、Retrieval-Augmented Generation の略です。
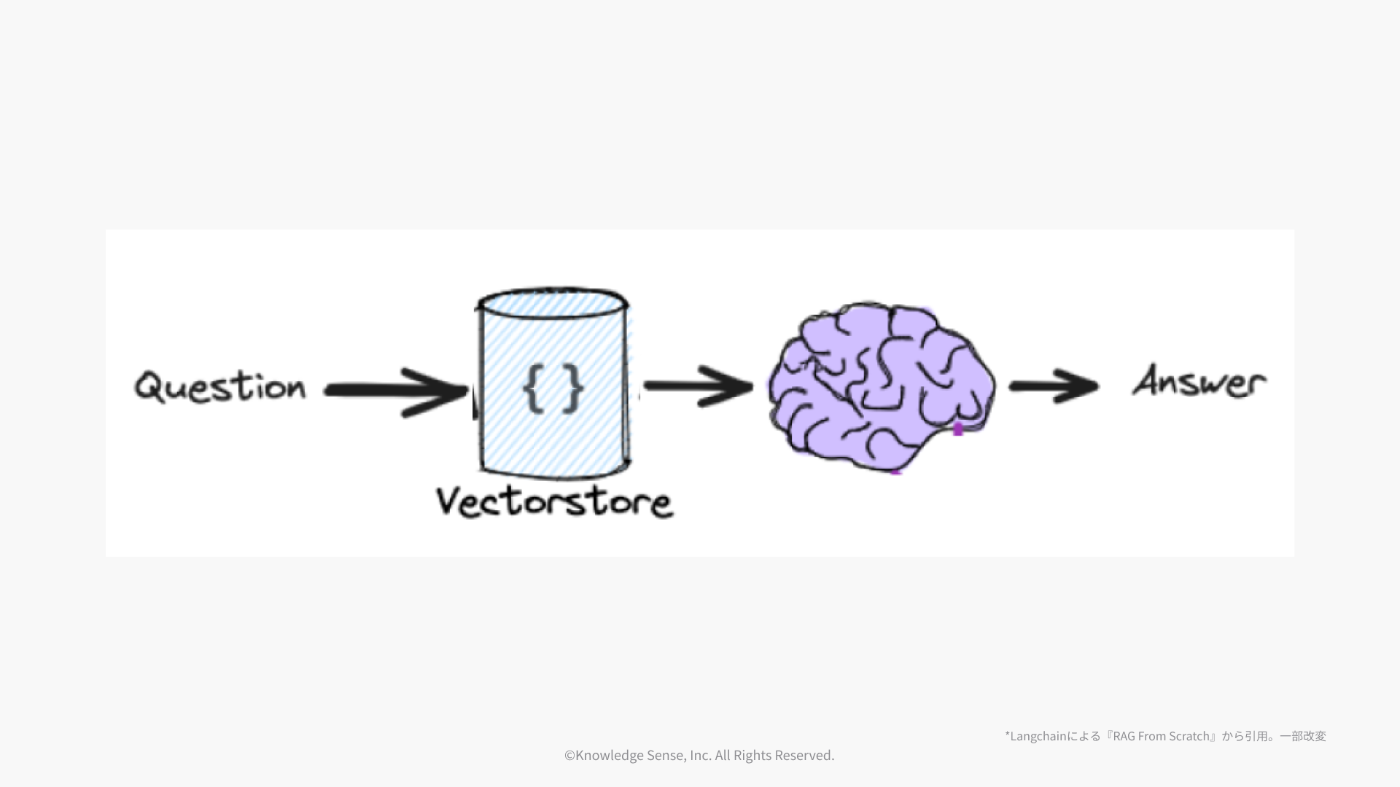
ざっくり言うと、RAGとは、LLM(GPT-5など)が外部の知識を参照して回答できるようにした仕組みです。
通常、LLMは、学習データに含まれていない最新の情報や、社内文書のようなクローズドな情報を知りません。そのため、そのまま質問しても「分かりません」と答えたり、それらしい嘘(ハルシネーション)をついたりしてしまいます。
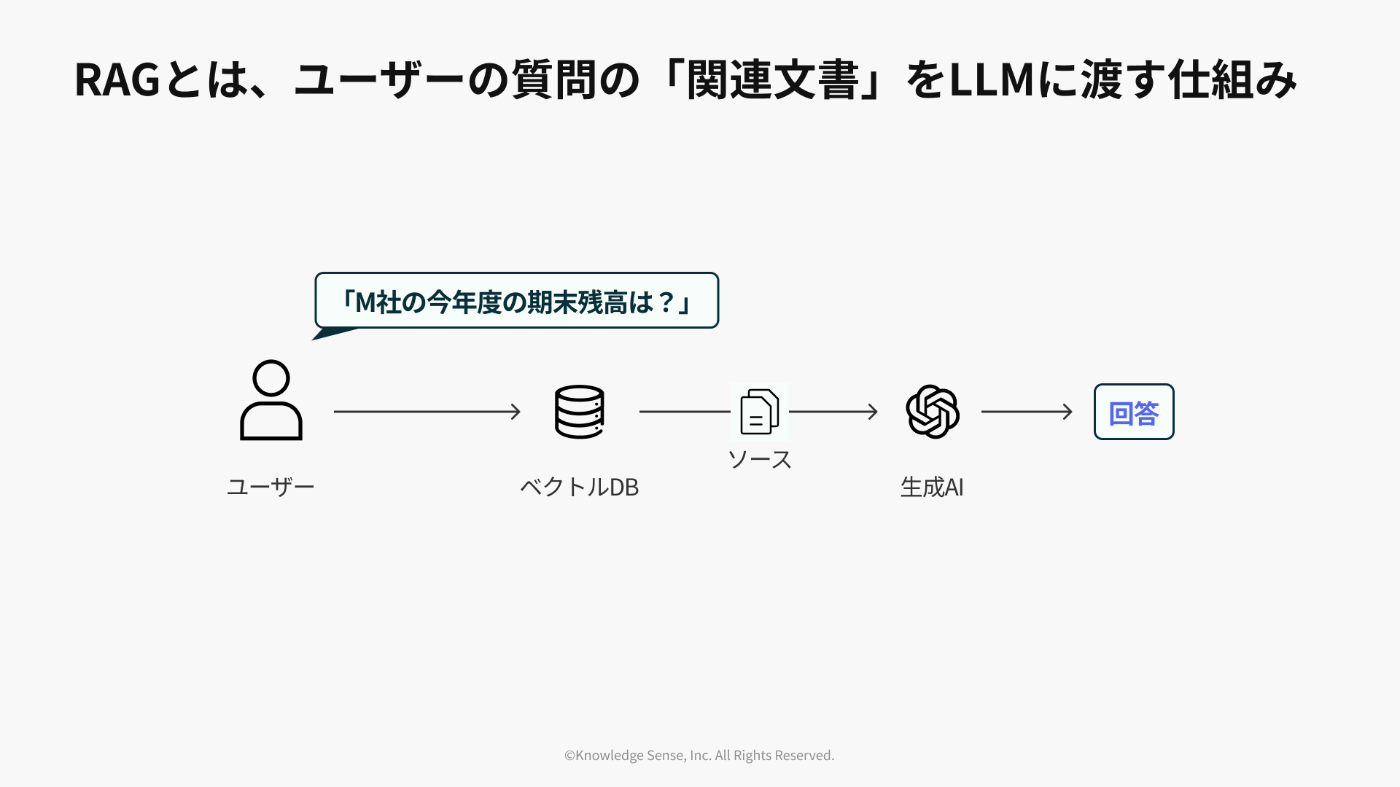
RAGは、この弱点を克服するための技術です。ユーザーから質問が来たら、まずその質問に関連する情報をデータベース(ベクトルデータベースなど)から探し出し、その「参考資料」と「質問」をセットでLLMに渡します。
ちなみに...
ちょっと余談ですが、「RAGは改善が大変」と聞いたことがあるなら、事実です。
ここまでの説明だけだと、かなりシンプルに聞こえますが、RAGという技術は「80点取るのは簡単、90点取るのは大変、100%はまず無理」。そんな技術です。(詳しくはこちら)
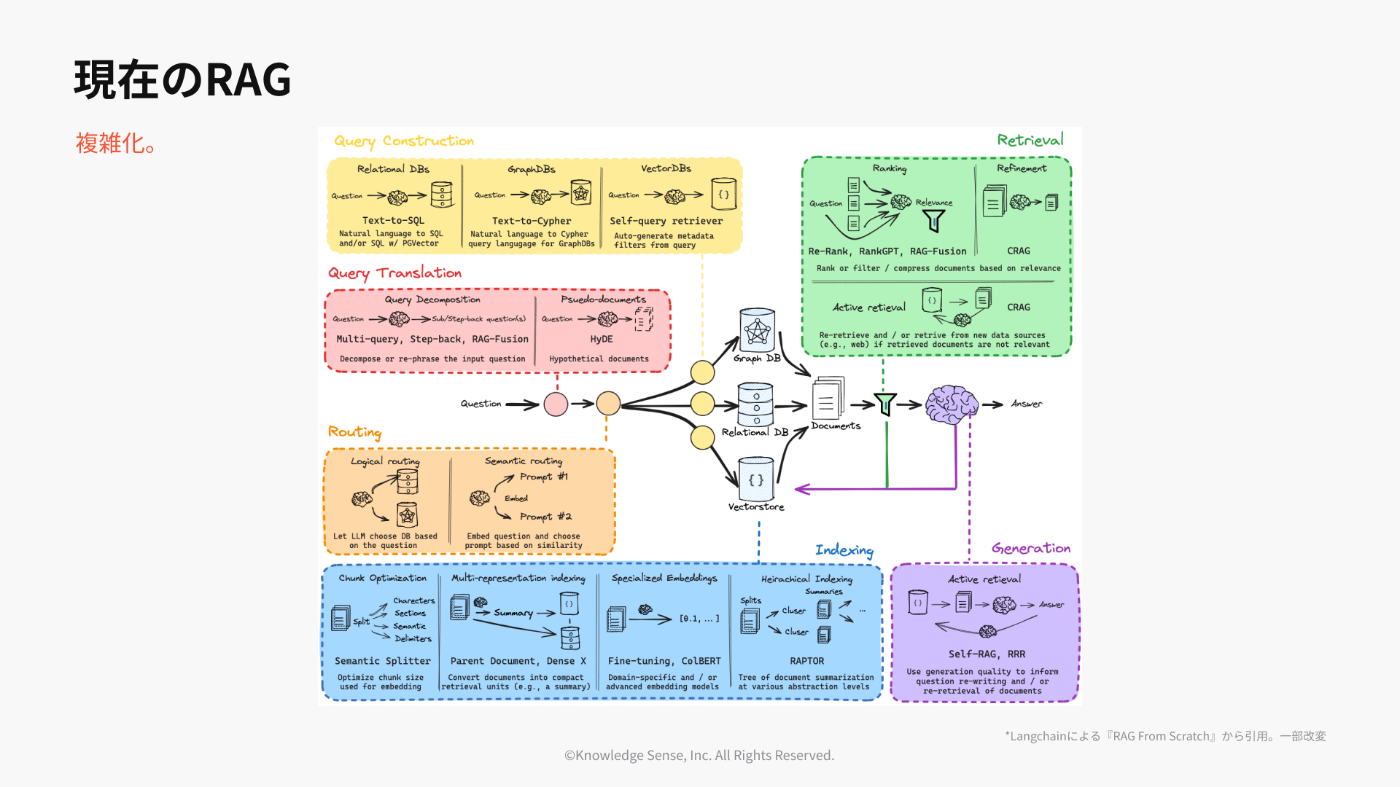
(↑上に書いてある手法の何百倍の論文が出ていて、それでも精度100%になることは無いです)
本題
RAGをゼロから実装してみる
では、このRAGの仕組みを、手元のPCで動かせる簡単なWebアプリとして実装していきます。
1. 準備 (環境構築)
1.1 uvのインストール
macOSの場合
curl -LsSf [https://astral.sh/uv/install.sh](https://astral.sh/uv/install.sh) | sh
Windowsの場合。PowerShell を「管理者として実行」し、以下を実行:
powershell -ExecutionPolicy ByPass -c "irm [https://astral.sh/uv/install.ps1](https://astral.sh/uv/install.ps1) | iex"
インストール後、新しくターミナルを開き直して、uv --version でエラーが出なければOK。
Windowsの場合は、例えば以下のように出ます
PS C:\Users\xxxxx> uv --version
uv 0.6.15
1.2 Pythonを入れる
uv python install
1.3 プロジェクト作成
作業ディレクトリを作って、uvプロジェクトを初期化
mkdir rag-from-zero-2025
cd rag-from-zero-2025
uv init
1.4 今回使うパッケージを uv で追加
uv add streamlit faiss-cpu python-dotenv openai numpy
1.5 OpenAI APIキーの設定
プロジェクト直下に .env という名前のファイルを作成して、中身に、ご自身のOpenAI APIキーを記述します。
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxx
1.6 data フォルダを作り knowledge.txt を格納
data フォルダを作成して、その中にknowledge.txt というファイルを作成してください。
knowledge.txtの中身は、RAGに読み込ませたい情報を自由に書きます。(例↓)。
RAG(Retrieval-Augmented Generation)は、2020年にLewisらによって提案された手法です。
RAGは、生成AIが外部のデータベースから関連情報を取得し、それを回答に活用する技術です。通常の大規模言語モデル(LLM)は、学習済みのデータに基づいて応答を生成します。(参考: OpenAI公式 https://help.openai.com/en/articles/8868588-retrieval-augmented-generation-rag-and-semantic-search-for-gpts )
2025年現在、RAGはGPT-5のような最新モデルと組み合わせて利用されることが一般的であり、多くのエンタープライズAIシステムの中核技術となっています。
ベクトルデータベースにはFaissやPinecone、Milvusなどがよく使われます。
株式会社ナレッジセンスは、エンタープライズ向けのRAGプロダクト「ChatSense」を開発しています。主な特徴は、高精度な検索とセキュリティです。
ちなみにここまでで、以下のようなフォルダ構成になっているはずです
1.7 app.py を作成し、以下を記述
app.py
import os
from pathlib import Path
import numpy as np
import faiss
import streamlit as st
from dotenv import load_dotenv
from openai import OpenAI
# === 設定 ===
EMBEDDING_MODEL = "text-embedding-3-small"
CHAT_MODEL = "gpt-5" # GPT-5系モデル
TOP_K = 3 # 何件のドキュメントを参照するか
# === OpenAIクライアントの初期化 ===
load_dotenv()
try:
# .env の OPENAI_API_KEY を読む
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
except Exception as e:
st.error(f"OpenAI APIキーの読み込みに失敗しました。.envファイルを確認してください。: {e}")
st.stop()
# === ドキュメント読み込み ===
def load_documents(data_dir: str = "data"):
"""
'data'ディレクトリから.txtファイルを読み込む
"""
docs = []
base = Path(data_dir)
if not base.exists():
st.error(f"'{data_dir}' ディレクトリが見つかりません。作成してください。")
return []
for p in base.glob("*.txt"):
try:
text = p.read_text(encoding="utf-8")
docs.append(
{
"id": p.name,
"path": str(p),
"text": text,
}
)
except Exception as e:
st.warning(f"ファイル {p.name} の読み込みに失敗しました: {e}")
return docs
# === 埋め込み生成 ===
def embed_texts(texts):
"""
OpenAIの埋め込みAPIを利用して、テキストリストをベクトル化
"""
try:
resp = client.embeddings.create(
model=EMBEDDING_MODEL,
input=texts,
)
embeddings = [d.embedding for d in resp.data]
return np.array(embeddings, dtype="float32")
except Exception as e:
st.error(f"Embeddingの生成に失敗しました: {e}")
return None
# === ベクトルインデックスの構築 ===
@st.cache_resource(show_spinner="ドキュメントをベクトル化しています...")
def build_index():
"""
ドキュメントを読み込み、ベクトル化し、Faissインデックスを構築する
"""
docs = load_documents()
if not docs:
st.error("data/ 配下に .txt ファイルがありません。RAGの検索対象となるファイルを追加してください。")
st.stop()
texts = [d["text"] for d in docs]
embeddings = embed_texts(texts)
if embeddings is None:
st.error("Embeddingの生成に失敗したため、インデックスを構築できません。")
st.stop()
dim = embeddings.shape[1]
index = faiss.IndexFlatL2(dim) # L2距離(ユークリッド距離)
index.add(embeddings)
return index, embeddings, docs
# === 検索(Retrieval) ===
def search_similar_docs(query: str, index, docs, k: int = TOP_K):
"""
質問文をベクトル化し、Faissで類似ドキュメントを検索する
"""
query_emb = embed_texts([query]) # shape: (1, dim)
if query_emb is None:
return []
distances, indices = index.search(query_emb, k)
results = []
for dist, idx in zip(distances[0], indices[0]):
doc = docs[int(idx)]
results.append(
{
"score": float(dist),
"doc_id": doc["id"],
"path": doc["path"],
"text": doc["text"],
}
)
return results
# === プロンプト組み立て ===
def build_rag_prompt(question: str, retrieved_docs):
"""
検索結果と質問文を組み合わせて、LLMへのプロンプトを作成する
"""
# コンテキストとして使うテキスト(長すぎるときは適当に切る)
max_chars = 1000
context_parts = []
for r in retrieved_docs:
t = r["text"]
if len(t) > max_chars:
t = t[:max_chars] + "\n...(以下略)"
context_parts.append(f"[{r['doc_id']}]\n{t}")
context = "\n\n---\n\n".join(context_parts)
system_prompt = (
"あなたは社内ドキュメントに基づいて回答するアシスタントです。"
"コンテキストに書かれていないことは推測せず、「分かりません」と答えてください。"
)
user_prompt = f"""以下は社内ドキュメントから抽出したコンテキストです。
# コンテキスト
{context}
---
# ユーザーからの質問
{question}
---
上記コンテキストの内容だけを根拠に、日本語で丁寧に回答してください。
コンテキストに十分な情報がない場合は、その旨を正直に伝えてください。
"""
return system_prompt, user_prompt
# === 回答生成(Generation) ===
def generate_answer(system_prompt: str, user_prompt: str):
"""
OpenAI Responses APIを叩いて回答を生成する
"""
try:
resp = client.responses.create(
model=CHAT_MODEL,
instructions=system_prompt,
input=user_prompt,
# GPT-5は temperature 固定なので指定しない
)
# すべてのテキスト出力が一つにまとまったプロパティ
return resp.output_text
except Exception as e:
st.error(f"OpenAI APIの呼び出しに失敗しました: {e}")
return None
# === Streamlit UI ===
def main():
st.set_page_config(page_title="RAGをゼロから実装する【2025年版】", layout="wide")
st.title("RAGをゼロから実装して仕組みを学ぶ【2025年版】")
st.caption(f"モデル: {CHAT_MODEL} | Embedding: {EMBEDDING_MODEL} | 検索: Faiss")
st.write(
f"このデモでは、ローカルの `{Path('data').resolve()}` フォルダ内にある `.txt` ドキュメントを検索対象にした、シンプルなRAGを実装しています。"
)
# インデックス構築
try:
index, embeddings, docs = build_index()
except Exception as e:
st.error(f"インデックスの構築に失敗しました。: {e}")
st.stop()
with st.sidebar:
st.header("設定")
top_k = st.slider("参照するドキュメント数", 1, 10, TOP_K)
st.markdown("### 読み込まれたドキュメント一覧")
if docs:
for d in docs:
st.markdown(f"- `{d['id']}`")
else:
st.warning("ドキュメントがありません。")
question = st.text_input("質問を入力してください(例:ナレッジセンスとは?)")
run = st.button("RAGに聞いてみる")
if run and question:
with st.spinner("検索 & 回答生成中..."):
# 1. 検索
retrieved = search_similar_docs(question, index, docs, k=top_k)
if not retrieved:
st.error("検索に失敗しました。")
st.stop()
# 2. プロンプト作成
system_prompt, user_prompt = build_rag_prompt(question, retrieved)
# 3. 回答生成
answer = generate_answer(system_prompt, user_prompt)
if answer:
col1, col2 = st.columns(2)
with col1:
st.subheader("🤖 回答")
st.write(answer)
with col2:
st.subheader("📚 検索されたコンテキスト")
for r in retrieved:
with st.expander(f"`{r['doc_id']}`(類似スコア: {r['score']:.4f})"):
st.text(r["text"][:1500]) # 表示しすぎると重いので適当に切る
else:
st.error("回答の生成に失敗しました。")
elif run and not question:
st.warning("質問を入力してください。")
if __name__ == "__main__":
main()
1.8 RAGを動かす
ターミナルにて、以下を実行
uv run streamlit run app.py
※ちなみに最初は、以下のような記述が出るかもですが、無視してエンターでOKです
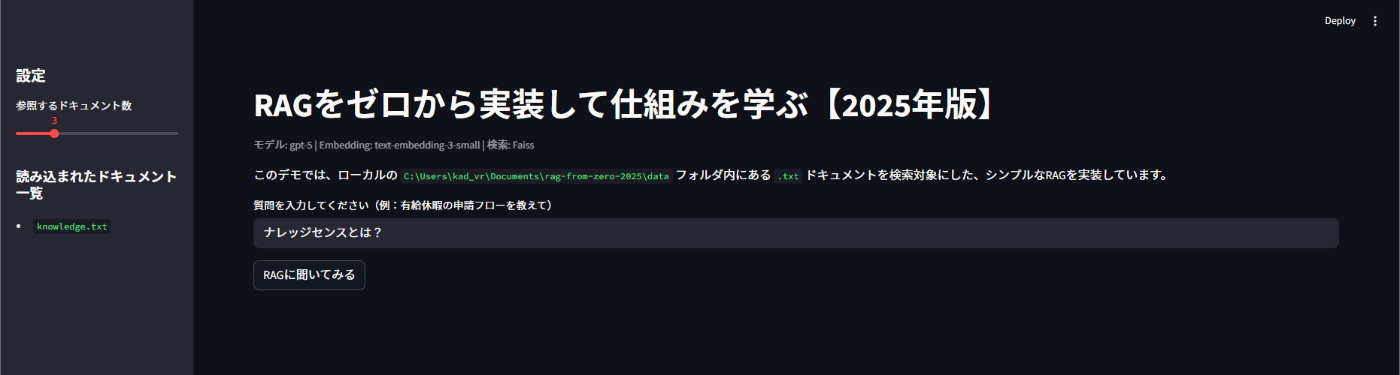
自動的に http://localhost:8501/ のリンクが開かれて、RAGが利用できるようになるかと思います。
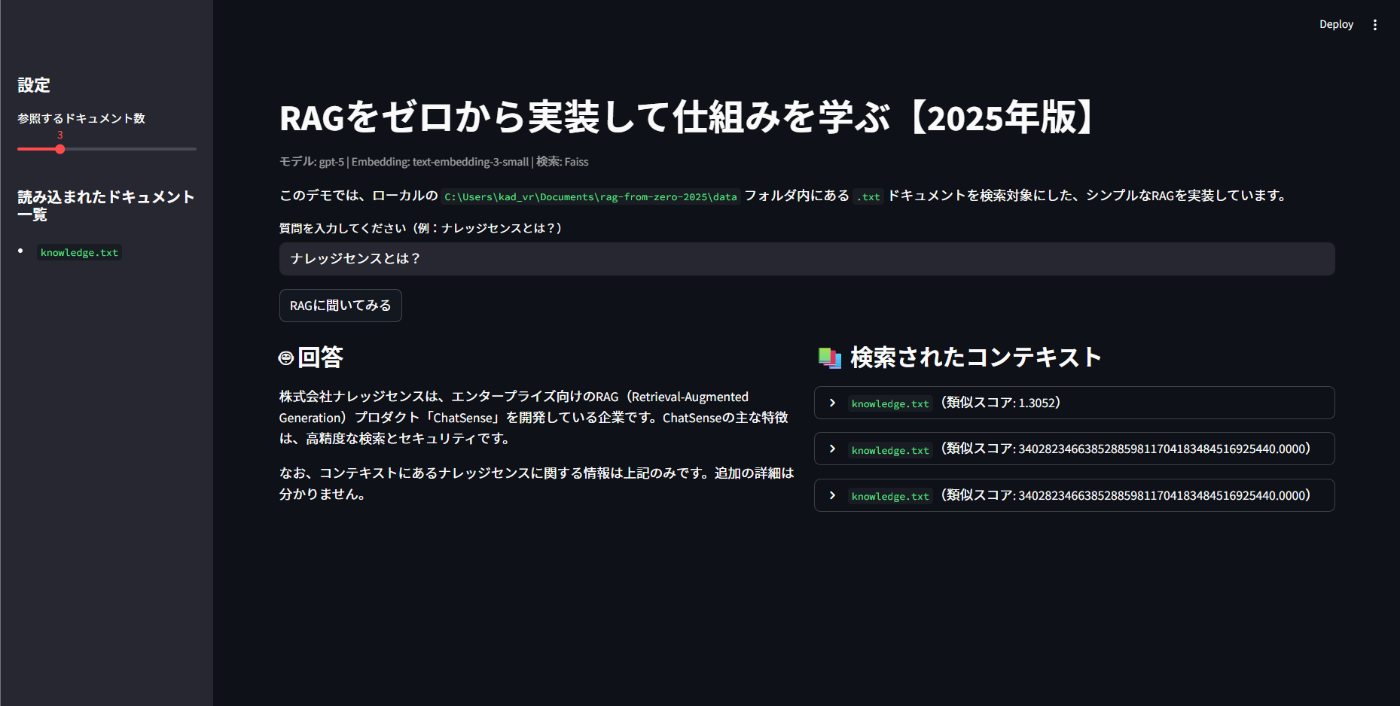
1.9 RAGに質問して試す
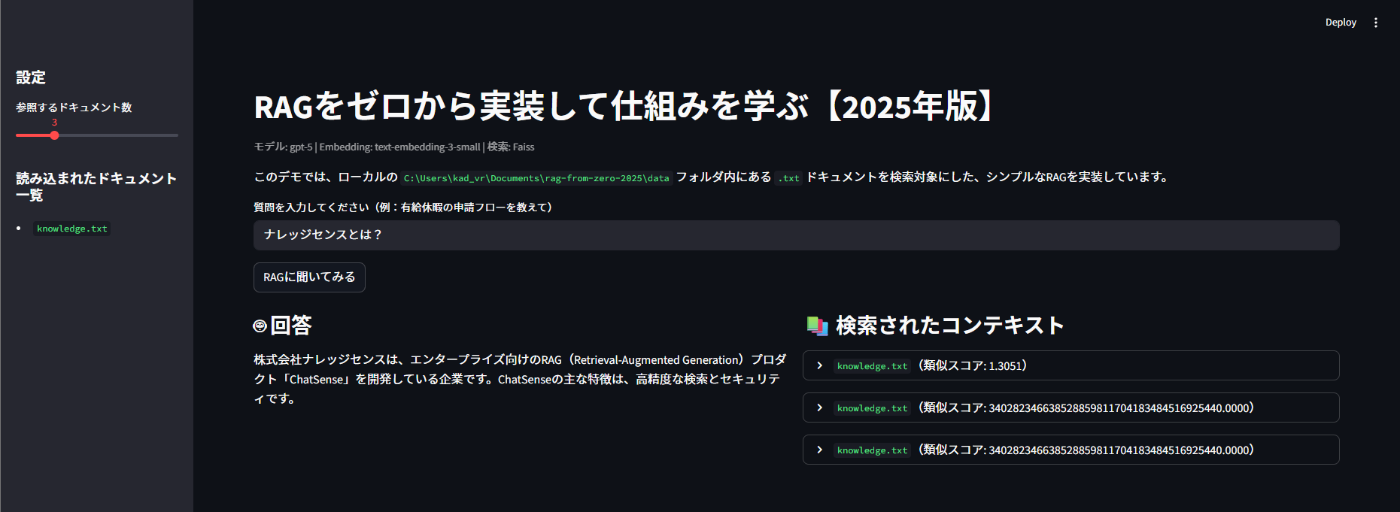
以下のように、回答が返ってきたら成功です👍️
1.10 ソースコードをいじって仕組みを理解
-
knowledge.txtがRAGのソースです。内容を好きに変えてみてください。きっと感動するはず -
app.pyがRAGの仕組みそのものなので、これを複雑化していけば、より精度の高い回答を作っていくことが可能になります。
まとめ
弊社では普段から、エンタープライズ向けに生成AIサービスを開発しています。
今回は非常に簡単なRAGでしたが、これを応用して、図表入りのPDFでもうまく回答できるようにしたり、何百万件のドキュメントで上手くいくようにするには、結構、骨の折れる作業が必要になります。
ぜひ、シンプルなRAGを構築してみて、「RAGは構築は簡単だけど精度向上は大変」という感想を、実体験として聞かせてください。
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion