本記事では、RAGの性能を高めるための「DyPRAG」という手法について、ざっくり理解します。株式会社ナレッジセンスは、エンタープライズ企業向けにRAGを提供しているスタートアップです。
この記事は何
この記事は、RAGの新手法である「DyPRAG」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
(すみません、ちょっと今回、玄人向けの記事です...🙏)
本題
ざっくりサマリー
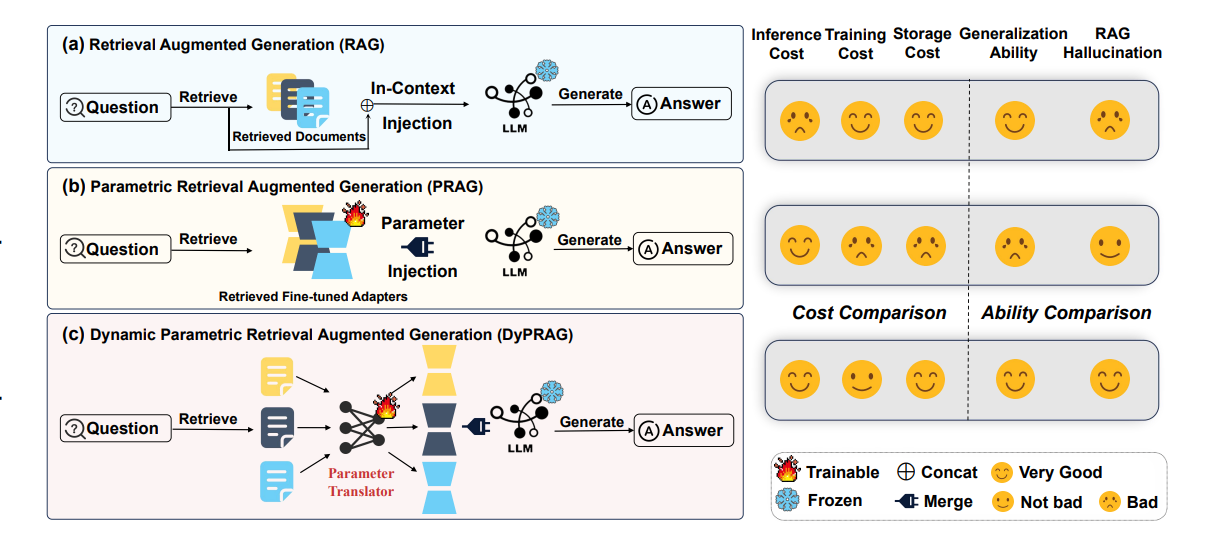
DyPRAGは、中国科学院自動化研究所の研究者らによって2025年3月に提案されました。
通常のRAGでは、ユーザーの質問に関連する文書を「会話のコンテキスト」としてLLMに渡します(=「In-context learning」)。ただ、このとき文字数が多すぎると、LLMがハルシネーションを起こしたり、入力内容をLLMが「忘れて」しまったりなど、問題が起きます。[2]
DyPRAGでは、関連文書をLLMのパラメータに変換して、LLMに直接注入します。こうすることで、LLMは、文書の内容を、より忠実に理解して回答できるようになります。
(※ちなみに当然ですが、LLMにパラメータレベルで干渉できなければいけないので、GPT-4oのような重み非公開のモデルでは、この手法は使えません...)
問題意識
従来のRAGでは、入力内容が長かったり複雑だったりすると、一定の確率でLLMがハルシネーションを起こすという課題がありました。
実際、僕の感覚でも、「GPT-4o」のような強いモデルを使ったRAGでも、そこそこの確率でハルシネーションを起こします。(入力文書が専門的だと、特に起きやすい。)
そこでまず、2025年1月に、「PRAG」という手法が提案されました[3]。

この手法は「DyPRAG」の前身です。「検索された文書をパラメータ化して、LLMに直接渡す」という手法ですが、事前に全ての文書についてLoRA学習が必要になるなど、「運用コストが高すぎる」という課題がありました。
このような流れで、「DyPRAG」が発表されました。DyPRAGでは、毎回の学習は必要としない形で、「検索された文書をパラメータ化してLLMに直接渡す」を実現し、RAGの精度を向上させます。
手法

【事前にやっておくこと】
-
あらかじめ文書をパラメータ化しておく
- 上記画像の「Stage 1」部分
- 回答ソースにしたい文書を、質問応答(QA)ペアの形式に変換する
- QAペアに変換された文書をもとに、小さなLoRAのパラメータを生成する
- このような「文書→パラメータ」ペアを大量に保管しておく(480件くらい)
-
パラメータ変換器を訓練する
- 上記画像の「Stage 2」部分
- 1のペアを学習データとして、文書をパラメータ化するための小さなMLP(ニューラルネットワーク)を事前訓練
- (これにより、新しい文書を瞬時にパラメータへ変換できる)
【ユーザーが質問を入力して来たとき】
- 関連する文書を検索(通常通り)
-
文書をパラメータに変換
- 検索した文書を、上記の「パラメータ変換器」に入力し、パラメータを得る
- それをLoRAパラメータとしてLLM内部に注入
- 最終的な回答を生成
DyPRAGという手法のキモは、「文書をパラメータに変換する変換器」の部分です。外部情報を直接パラメータに変換してモデルの内部表現に統合することによって、LLMの内部知識(事前に学習している知識)と外部のソースを、自然な形で融合させて回答することができます。これは、論文では 知識融合 (=「knowledge fusion」) と表現されています。
成果

- DyPRAG-Combine(※パラメータとしても、コンテキストとしてもダブルでLLMに渡す手法)が最も高性能
- PRAG(従来手法)より圧倒的に軽量(PRAG比でストレージは0.04%)
- わずか480件のDoc-Paramペアだけで、汎化性能が得られる(1件あたり数秒で生成可能)

- OOD(未知の質問)にも強く、従来のRAGより20%以上スコア改善
まとめ
弊社では普段から、エンタープライズ向けにRAGサービスを開発しています。その中で、大企業の文書、専門性高すぎるという問題があります。文書の専門性が高いと、RAGは回答精度が落ちやすいです。
RAGのハルシネーションを防ぐ手法は、他にも色々あります[4]が、上記で触れた「知識融合」を発生させることで回答精度を上げるというのは、ユニークな手法だなと思いました。
この手法を使うことで最も恩恵を受けるのは、小さいモデルを使ったRAGです。もちろん、大きいモデル(GPT-4oなど)を使ったRAGでも性能は上がります。しかし、「DyPRAG」の性質は「内部知識を外付けで注入できる」ということなので、そもそもの「内部知識」が乏しい(小さい)モデルに対してこの手法を使った方が、インパクトが大きいです。
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
-
"Better wit than wealth: Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhancement", Tan et al. ↩︎
-
例えば「Lost in the Middle」問題は有名です。入力される文字数が多すぎると、LLMは、真ん中の方に書かれていることを無視してしまうというLLMの問題です。 ↩︎
-
例えば『RAGのハルシネーションを尤度で防ぐ』や『Astute RAG』など。 ↩︎
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion