本記事では、RAGのソースにするドキュメントに対して、「Q&Aデータ」を自動で生成できる手法「ExpertGenQA」について、ざっくり理解します。株式会社ナレッジセンスは、エンタープライズ企業向けにRAGサービスを提供しているスタートアップです。
この記事は何
この記事は、ドキュメントについての高品質なQ&Aを自動生成する手法「ExpertGenQA」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合はこちらの記事もご参考下さい。
本題
ざっくりサマリー
ExpertGenQAは、専門文書に基づいたにQ&Aを、高品質かつ自動で作成するための新しい手法です。カリフォルニア大学リバーサイド校の研究者らによって2025年3月に提案されました。
通常、RAGを評価するためのデータセットの作成は大変です。特に、ソースとして投入する文書の専門性が高い場合、開発者の負担は大きいです。というのも、「ユーザーはどんな質問をしてくるのか」について、その分野/文書を勉強しながら、開発する必要があるためです。
「ExpertGenQA」という手法では、人間が作成した数件の例だけで、そのパターンを踏襲した、Q&Aデータを自動生成することができます。
問題意識
大前提として、RAGの精度を上げるコツは、「ユーザーがする想定質問と、理想回答」の解像度を高めることです。
しかし、「大企業のユーザーがRAGに使いたい文書、専門的すぎる」という問題が存在します。
そうすると通常、開発者である我々は、「想定質問」を上手く考えられません。回答精度を上げる難易度が一気に上がります。
もちろん、ユーザーへのヒアリングはしますが、ユーザーの負担を考えると、良くて2~3個の想定質問をもらえる程度です。
手法
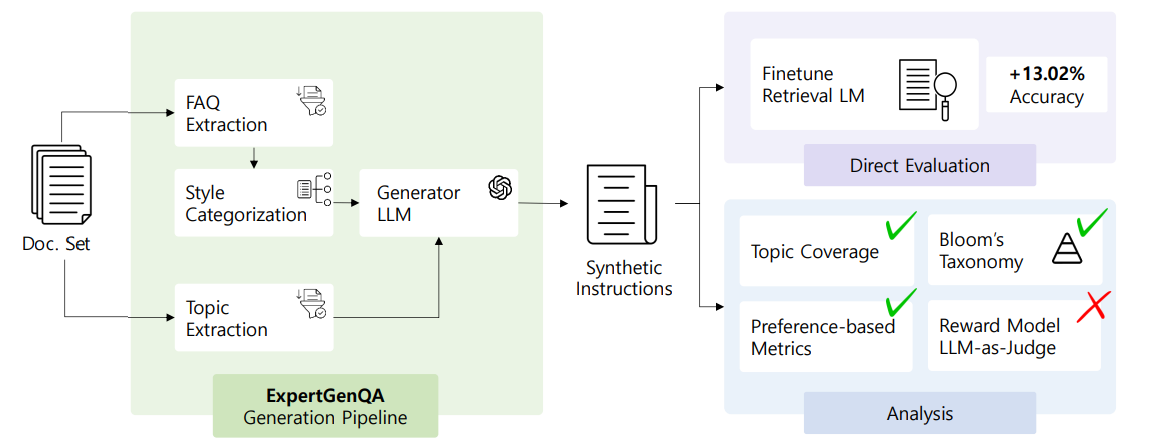
ExpertGenQA は、以下のようなルールで文書からQ&Aを作成していきます。

-
質問のスタイルを予め分類
- この文書について、ざっくりどんなタイプの質問が来るかカテゴリを考える
- 例えば論文では、以下のような分類をしています
- ①文書に登場する「ルール」についての質問(文書中に答えがある)
- ②もっと具体的な状況についての質問(ルールに当てはめたときどうなるか?)
- ③用語についての質問
- (→この3つをそのまま使うのもいいですし、別の分類を定義してもいいです!)
-
専門家(人間)が、数件の想定質問を作る
- 1で定義したスタイルそれぞれについて、少なくとも数件はQ&Aの例を作成
- LLMを使って、文書から主要なトピックを抽出
-
Q&A生成
- LLMを使って、3の各トピックについて、1の各スタイルで質問を自動生成
- ポイントとして、各スタイルごとに、2の想定質問(人間が作成)を例としてLLMに渡す
- 重複したQ&Aを削除
ExpertGenQA のキモは、ユーザーからの想定質問を、予め分類した上で、LLMにQ&Aを作成させている点です。しかも、この分類それぞれについて、お手本となる質問(=いわゆる「few-shot」のサンプル)をLLMに与えています。これにより、LLMは、方向性を間違えることなく、爆速でサンプルQ&Aを作成できるようになります。
成果
- 従来のFew-shot生成やテンプレートベースの手法に比べて、質問生成の効率が2倍に。
- 専門的な内容を網羅するトピックカバー率は94.4%を達成。
- 生成された質問で検索モデル訓練。Top-1精度が13.02%改善。(下図)

生成したQ&Aデータは、検索モデルをファインチューニングするためにも使うことができます。私が焦点を当てたメインテーマではありませんが、ExpertGenQAは、この方面で使ったとしても、かなり強力な手法になることが示されています。
まとめ
弊社では普段、大企業向けにRAGサービスを提供しています。大企業のドキュメントは、業界独自のルールが織り込まれた、専門性が高い内容ばかりです。
こうした難解な文書を「シンプルなRAG」に入れると、まず、上手くいきません。そのため、専門的な内容に対して精度を上げるための工夫[2]が実装されたRAGが必要になります。
そして、そういった「工夫」で本当に精度が上がっているのか?開発者が最終チェックする際、ExpertGenQAは、かなり便利な手法です。
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion