導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
今回は、文章の尤度とドキュメントの配置位置、そして回答の精度の関係性を調査した論文について紹介します。
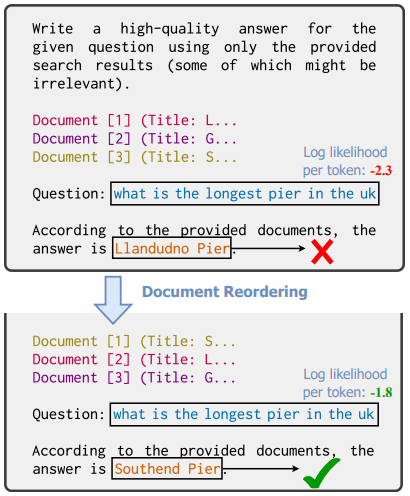
サマリー
RAGにおいて、正解ドキュメントの文章の配置と、回答精度の関連性は以前から注目されていました。この関係性の原因が文章の尤度(文字同士のつながりをLLMがどの程度自然と捉えているかの指標)にあるとしたのが、この論文の大まかな趣旨です。
質問ないしは回答の尤度を用いることで以下のような機能が実現できます。1つ目は、回答の精度をLLMによる出力の前に事前に推測すること。2つ目は、生成された回答がどの程度正しいか推測すること。これらを検証した実験結果について紹介していきます。
問題意識
RAGの精度は正解ドキュメントの位置に依存する
RAGは関連するドキュメントを検索して、検索したドキュメントと質問文を合わせることでLLMの知り得ない情報を回答させる手法です。多くの研究では、このドキュメントをいかに正確に検索するかという点に焦点が当てられています。しかし、実は同じドキュメントであっても、LLMに文章を渡す順序に影響を受けて回答の精度に差が生まれることがわかっています。具体的には関連性の高いドキュメントを、文章の冒頭、ないしは最後の方に置くことで精度が向上するとされています。
しかし、それはあくまで経験則的な事実であり、なぜこうした現象が発生するかについて体系的に調査したものはほとんど存在していませんでした。
用語の説明
実験結果の解説の前に、重要な用語「尤度」について説明します。
本記事でいうところの「尤度」とは、ある文章をLLMが読み込んだときに、それぞれの文字同士のつながりがLLMにとって自然かどうかを表した値となっています。
そもそもLLMは、単語(トークン)の次につながる単語を確率的に推測して、確率の高いものを選択していくことで文章を生成しています。なので、文章を渡すことで、単語同士のつながる可能性を数値化して出力が可能になっています。
実験
今回紹介する論文は、実験がメインとなっていますので、一つ一つの実験結果についてまとめていきます。前提として、LLMに対して渡す文章は前半にドキュメント、そして後半に質問を渡し回答を生成しています。
正解ドキュメントと尤度の関係性
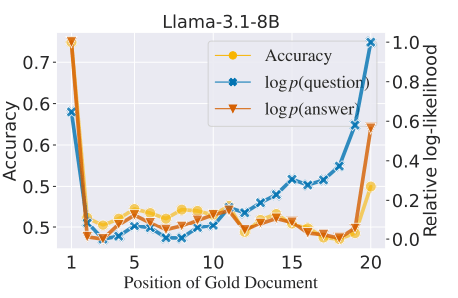
こちらは、横軸に正解ドキュメントの配置、そして縦軸には最終的に生成された回答の精度と、質問文の尤度と回答の尤度が示されています。視覚的な判断にはなってしまいますが、これら3つの数値はかなり連動しており、特に精度と回答の尤度はかなり強い関係性がありそうです。
精度と質問文の尤度の関係性

こちらは、横軸に相対的な質問の尤度を、縦軸に精度を設定したグラフとなっています。様々な条件において相関関係があることが認められそうです。
正解ドキュメント以外の配置の影響

ここまでの実験は、正解ドキュメントの位置と尤度の関係性を示していました。この実験では、正解ドキュメントでないドキュメントの位置を動かした際に精度と尤度に影響を与えるかについて調べています。結論としては、正解でないドキュメントの位置を変更しても、正解のドキュメントを動かし際の精度や尤度ほどの変化は見受けられませんでした。
まとめ
今回の論文は、正解ドキュメントの位置、回答の精度、そして質問、回答の尤度の関係性を調査する内容となっていました。これは非常に興味深い成果で、LLMがその回答をどのくらい信頼して出力しているかが事前にわかることを意味しています。これを応用することで正解ドキュメントの有無を推測したり、出力後にその回答が誤った事実を含む可能性を数値的に判断できるようになりました。
ただし、実際に利用する際には以下の点に注意する必要がありそうです。
- LLMがその回答を事前にある程度知っていた可能性がある
- 意外性のある(だが正しい)回答では相関が下がる可能性がある
- より専門的な分野になると、相関が薄れる可能性がある
- 文章の尤度を出力する必要がある関係上、現状オープンソースのLLMを使用する必要がある
なので、いつものことではありますが、実際に利用するケースでは事前にどの程度関係性があるか、うまくいかないパターンが存在しないか、などの調査は非常に重要になってきます。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion