【Juliaで因果推論】回帰分析 - OLS推定量の不偏性・効率性・一致性
- 3つの"良い"推定方法の基準: 不偏性・効率性・一致性 (一致性が一番大事)
- 仮定
E[U|X]=0 E[\hat{\beta}] = \beta - 真の値
\beta \hat{\beta}, \tilde{\beta} Var[\hat{\beta}] < Var[\tilde{\beta}] \hat{\beta} \tilde{\beta} - 仮定
Cov[X, U]=0 \hat{\beta} \xrightarrow{p} \beta
前回はOLS推定の結果が因果効果として信用に値するようなものとなるために必要な仮定
不偏性 (unbiasedness)
私たちが知りたいのは母集団で成り立つ関係式(population model)
不偏推定量の定義
母集団のパラメータ
であれば,
不偏性は推定量の期待値に関する特性です.つまり,「もし複数回サンプリングできたとして,それぞれ推定した場合,推定量は平均的に真の値を当てる」ということです.実際の分析ではサンプリングは1回の場合がほとんどなので推定は1回きりです.推定量に不偏性があれば,1回きりの分析も"平均的には"真の値を当てていることになります[4].
推定量が不偏性を持たないとき,推定量の期待値と真の値は異なります.その違いをバイアス(bias)といいます.
推定量のバイアスの定義
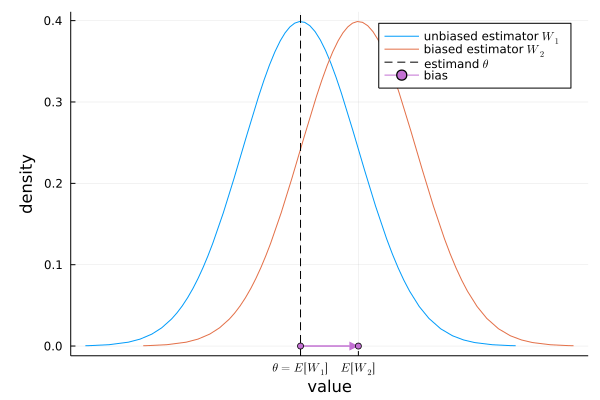
Figure.1 推定量の分布(不偏性,バイアス)のイメージ
Figure.1は真の値
ところで,真の値を推定するものであればどんなものでも推定量です.極論,でたらめな乱数randn()を推定量とすることもできますが,乱数は不偏性を持ちません.一方,OLS推定は「仮定
OLS推定の不偏性
仮定
Proof:
母集団における
母集団の関係式とランダムサンプリングより,
真の値
2行目は和のオペレーターの特性,3行目はpopulation modelを使って変形しています.分子に注目すると,
従って,OLS推定量
と表せます.これは
ここで,zero conditional mean assumption
さらに,zero conditional mean assumption
従って
最後に繰り返し期待値の法則より,見た目を不偏性の定義に寄せると,
となり,仮定
目で見るとわかりやすいので,シミュレーションしてみましょう[10].母集団から複数回,
シミュレーションでは
さて,まずは仮定
仮定
- サンプルサイズ:
N = 200 - 母集団モデル:
Y = 1 + 2 X + U -
X X \sim \mathcal{N}(3, 1) -
U U \sim \mathcal{U}[-1, 1] E[U]=0 -
X U E[U|X]=0 - サンプル数:
M = 1000
using Random, Plots, StatsPlots, Distributions, DataFrames, GLM, LaTeXStrings, Printf
# Generate simulated data (zero conditional mean)
β1 = 2 # true params
β0 = 1
N = 200 # sample size
function gen_data_zcm()
X = rand(Normal(3, 1), N) # X (no distribution ristrictions)
# X = rand(Uniform(1, 3), N) # you can change to any distribution
U = rand(Uniform(-1, 1), N) # U (the only ristriction is E[U]=0)
# U = rand(Chi(1)-1, N) # you can change to any distribution
# scatter(X, U) # E[U|X]=0, X and U are independent (no correlation)
Y = β0 .+ β1 * X + U # linear population model
df = DataFrame(Y = Y, X = X)
return df
end
# Estimate with different sample multiple times
Random.seed!(1234)
M = 1_000 # number of sample
β1_hats = []
# plot with cool GIF animation
anim = @animate for m in 1:5:M
df = gen_data_zcm()
ols = lm(@formula(Y ~ X), df)
push!(β1_hats, coef(ols)[2])
histogram(β1_hats, bins=10, xlims=[1.75, 2.25], title=L"M="*@sprintf("%d", m), xlabel=L"\hat{\beta}_1", ylabel="count", label=false)
density!(twinx(), β1_hats, xlims=[1.75, 2.25], xticks=false, yticks=false, label=false)
vline!([β1], linestyle=:dash, color=:gray, linewidth=2, label="true "*L"\beta_1")
title!(L"M = " * @sprintf("%d", m))
end
gif(anim, "sim_unbiasedness.gif", fps=60)
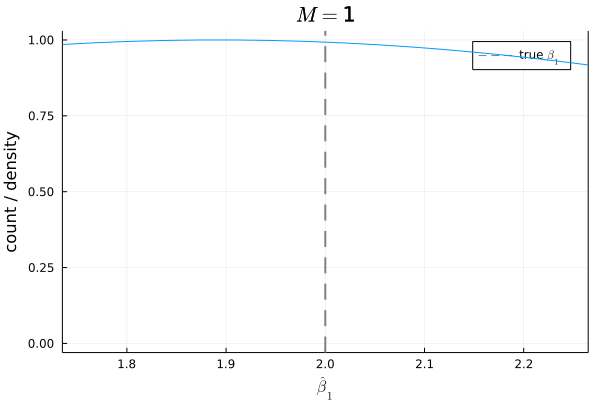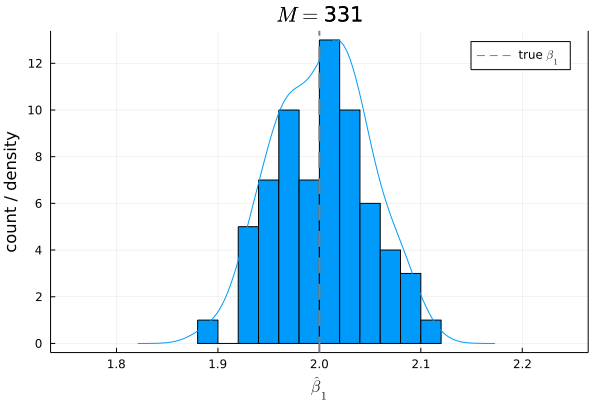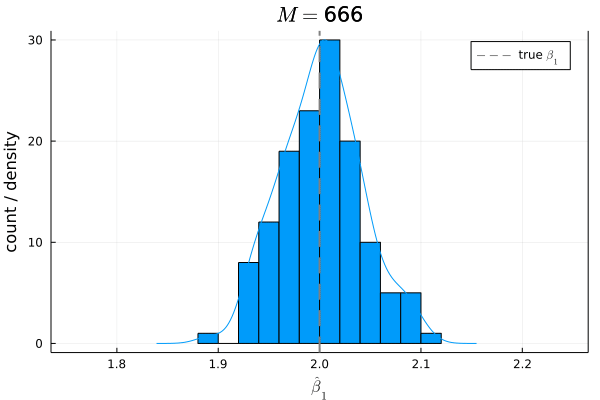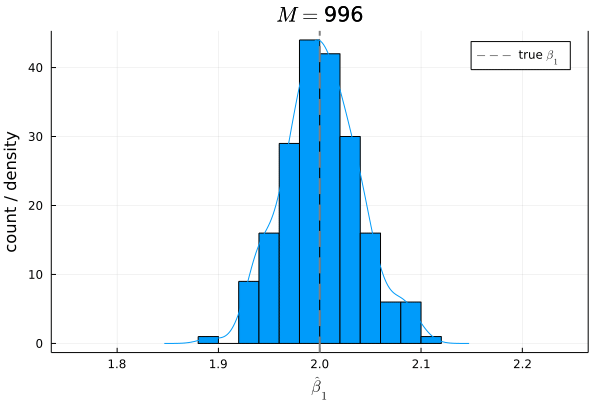
# Bias
mean(β1_hats) - β1
# 0.0072132362380079584
今度は,仮定
仮定
- サンプルサイズ:
N = 200 - 母集団モデル:
Y = 1 + 2 X + U -
X X \sim \mathcal{N}(3, 1) -
U U \sim \mathcal{N}(0, 1) E[U]=0 -
X U Cov[X, U]\neq0, E[U|X]\neq0 - サンプル数:
M = 1000
using Random, Plots, StatsPlots, Distributions, DataFrames, GLM, LaTeXStrings, Printf
# Generate simulated data (not zero conditional mean)
β1 = 2 # true params
β0 = 1
N = 200 # sample size
function gen_data_notzcm()
XU = rand(MvNormal([3, 0], [1 0.1; 0.1 1]), N) # Correlated Multivariate Normal Corr[X, U] = 0.1
X = XU[1, :]
U = XU[2, :]
# scatter(X, U) # E[U|X]!=0, X and U are orrelated
Y = β0 .+ β1 * X + U # linear population model
df = DataFrame(Y = Y, X = X)
return df
end
# Estimate with different sample multiple times
Random.seed!(1234)
M = 1_000 # number of sample
β1_hats = []
# plot with cool GIF animation
anim = @animate for m in 1:5:M
df = gen_data_notzcm()
ols = lm(@formula(Y ~ X), df)
push!(β1_hats, coef(ols)[2])
histogram(β1_hats, bins=10, xlims=[1.75, 2.25], title=L"M="*@sprintf("%d", m), xlabel=L"\hat{\beta}_1", ylabel="count", label=false)
density!(twinx(), β1_hats, xlims=[1.75, 2.25], xticks=false, yticks=false, label=false)
vline!([β1], linestyle=:dash, color=:gray, linewidth=2, label="true "*L"\beta")
title!(L"M = " * @sprintf("%d", m))
end
gif(anim, "sim_biased.gif", fps=60)
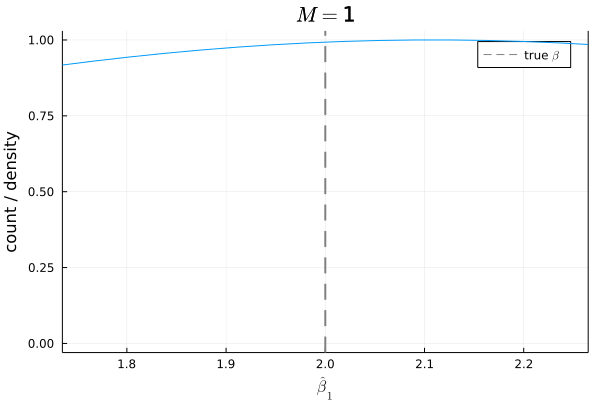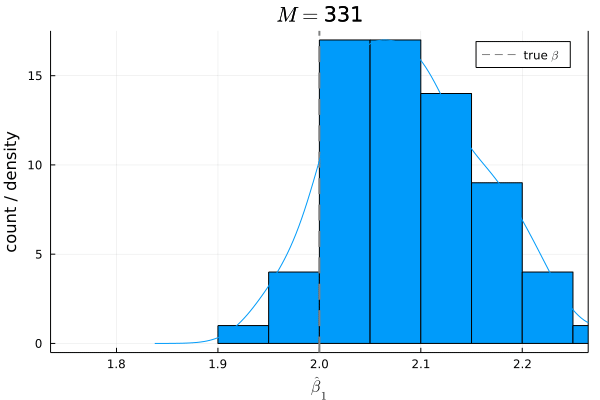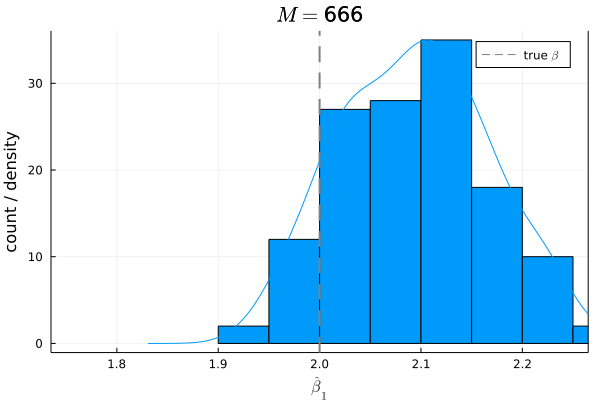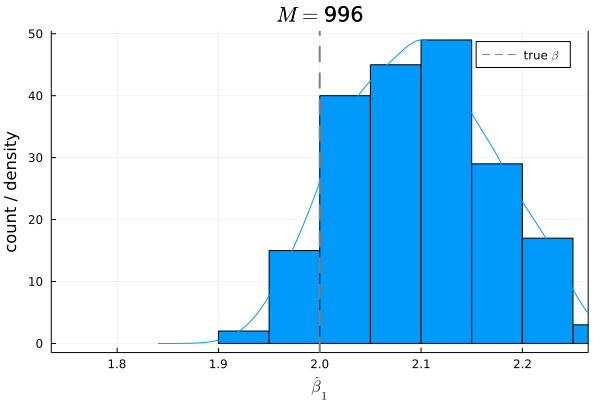
# Bias
mean(β1_hats) - β1
# 0.09866853535852238
バイアスは,
シミュレーションの結果からもわかる通り,もし仮定
効率性 (efficiency)
推定量が不偏性をもっていても,サンプルによって得られる推定値にばらつきが生じてしまいます.このばらつき具合は推定量の分布の分散(sampling variance)として考えられます.ばらつきが小さい推定量ほど良い推定量であり,効率的であるといいます.
相対的効率性の定義
母集団のパラメータ
のとき,
効率性は推定量の分散に関する特性です.また,効率性はあくまでも複数の不偏推定量の相対的な分散の大きさの違いによって議論されます.
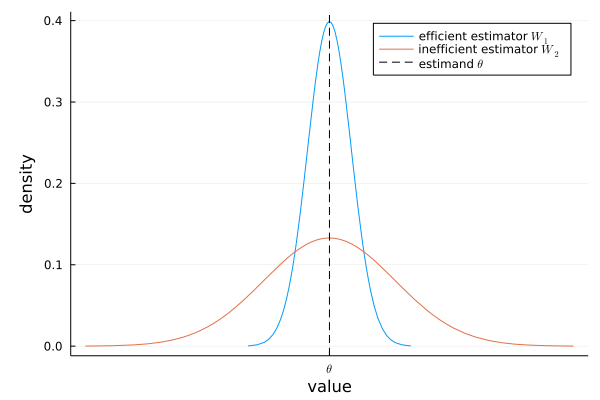
Figure.2 推定量の分散・効率性のイメージ
Figure.2より,推定量の分散が大きいと,推定によって結果のばらつきが大きくなります.すると同じ分析をしても大きく結果が異なる傾向が強くなってしまいます.よって当たり前ですが推定量の(
不偏性や後で紹介する一致性は推定の結果が真の値とどれだけ異なるのかについてですが,効率性は真の値とどれだけ離れるかではなくどれだけ推定にばらつきがあるかについてです.なので不偏性や一致性と比べると効率性はあまり重要視されないことが多いです.しかし,もし不偏性と一致性の両方を持つような推定方法が複数ある場合は,より(推定のばらつきが少ない)効率的な推定方法が良いでしょう.ちなみに,推定量の分散
一致性 (consistency)
推定量が不偏性を持っていたとしても推定量の分散によって,推定にばらつきが生じてしまいます.中にはそもそも不偏性を持たないような推定量もあります[15].これでは多くの推定が信用できないものとなってしまいます.そこで,新たに漸近的な(asymptotic, large sample properties)議論を導入します.ザックリ言うと「サンプルサイズが無限大であれば推定量は真の値と一致するかどうか」です.サンプルサイズが無限大のとき真の値と一致すれば,推定量は一致性を持つといいます.通常,計量経済学では一致性を推定量の最低条件としています.それくらい重要な特性です.
一致推定量の定義
母集団のパラメータ
と確率収束すれば,
一致性は推定量の確率極限に関する特性です.定義を直訳すれば,「サンプルサイズを無限大にすれば,推定量
推定量の漸近バイアスの定義
漸近バイアス(asymptotic bias)[18]とは,推定量が一致性を持たない(inconsistent)ときの,推定量の確率極限
推定量
OLS推定の一致性
OLS推定は,
Proof:
母集団における
OLS推定量の不偏性の証明で導出した,OLS推定量
両辺に
ここで大数の法則を使うと,
更に仮定より
よって,
もし,
-
Cov[X_i, U] > 0 \text{plim} \hat{\beta}_1 > \beta_1 -
Cov[X_i, U] < 0 \text{plim} \hat{\beta}_1 < \beta_1
この漸近バイアスの式は,めちゃくちゃ重要です[22].
さて,一致性についてもシミュレーションで理解を深めましょう.サンプルサイズ
仮定
- サンプルサイズ:
N = 1:10000 - 母集団モデル:
Y = 1 + 2 X + U -
X X \sim \mathcal{N}(5, 2) -
U U \sim \mathcal{U}[-1, 1] -
X U Cov[X, U] = 0
using Random, Plots, StatsPlots, Distributions, DataFrames, GLM, LaTeXStrings, Printf
# Generate simulated data (not correlated X and U)
β1 = 2 # true params
β0 = 1
function gen_data_notcorr(N)
X = rand(Normal(5, 2), N)
U = rand(Uniform(-1, 1), N)
Y = β0 .+ β1 * X + U # linear population model
df = DataFrame(Y = Y, X = X)
return df
end
# Estimate with increasing sample size
Random.seed!(1234)
N_inf = 300 # infinity sample size
β1_hats = []
# plot with cool GIF animation
anim = @animate for N in 1:N_inf
df = gen_data_notcorr(N)
ols = lm(@formula(Y ~ X), df)
push!(β1_hats, coef(ols)[2])
plot(β1_hats, marker=:circle, xlabel=L"N", ylabel=L"\hat{\beta}_1", label="OLS estimator "*L"\hat{\beta}_1"*"with sample size "*L"N")
hline!([β1], linestyle=:dash, color=:gray, linewidth=2, label="true "*L"\beta_1=2")
end
gif(anim, "sim_consistency.gif", fps=60)
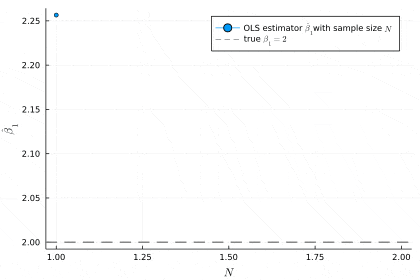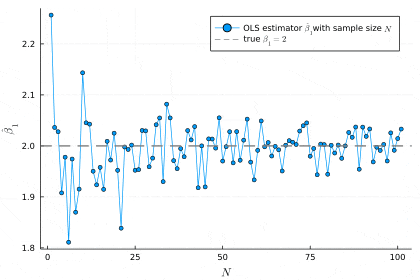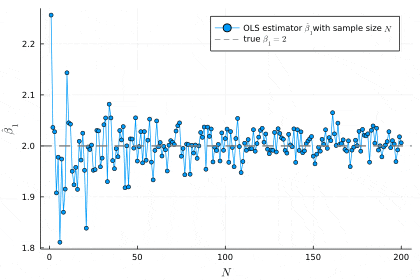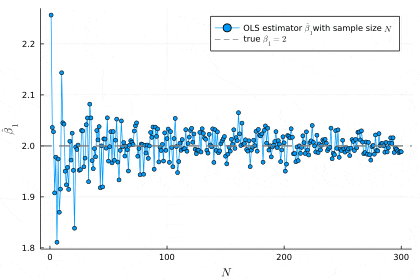
サンプルサイズが増えるにつれ,推定値が真の値の値に近づいていることが分かります.サンプルサイズ
Random.seed!(1234)
N_inf = 10_000 # infinity sample size
β1_hats = []
for N in 1:N_inf
df = gen_data_notcorr(N)
ols = lm(@formula(Y ~ X), df)
push!(β1_hats, coef(ols)[2])
end
scatter(β1_hats, markersize=2, alpha=0.1, xlabel=L"N", ylabel=L"\hat{\beta}_1", label="OLS estimator "*L"\hat{\beta}_1"*"with sample size "*L"N")
hline!([β1], linestyle=:dash, color=:gray, linewidth=2, label="true "*L"\beta_1=2")

# the value of OLS estimator at N = 10000
print(β1_hats[N_inf])
# 2.003832883131732
今度は
仮定
- サンプルサイズ:
N = 1:10000 - 母集団モデル:
Y = 1 + 2 X + U -
X X \sim \mathcal{N}(5, 2) -
U U \sim \mathcal{N}(0, 1) -
X U Cov[X, U] \neq 0
using Random, Plots, StatsPlots, LinearAlgebra, Statistics, DataFrames, GLM, LaTeXStrings, Printf
# Generate simulated data (not correlated X and U)
β1 = 2 # true params
β0 = 1
function gen_data_corr(N)
Σ = [2 0.9; 0.9 1]
L = cholesky(Σ).L
b = [5 0]
XU = randn(N, 2) * L .+ b # correlated X and U
X = XU[:, 1]
U = XU[:, 2]
Y = β0 .+ β1 * X + U # linear population model
df = DataFrame(Y = Y, X = X)
return df
end
# Estimate with increasing sample size
Random.seed!(1234)
N_inf = 300 # infinity sample size
β1_hats = []
# plot with cool GIF animation
anim = @animate for N in 1:N_inf
df = gen_data_corr(N)
ols = lm(@formula(Y ~ X), df)
push!(β1_hats, coef(ols)[2])
plot(β1_hats, marker=:circle, xlabel=L"N", ylabel=L"\hat{\beta}_1", label="OLS estimator "*L"\hat{\beta}_1"*"with sample size "*L"N")
hline!([β1], linestyle=:dash, color=:gray, linewidth=2, label="true "*L"\beta_1=2")
end
gif(anim, "sim_inconsistency.gif", fps=60)
Random.seed!(1234)
N_inf = 10_000 # infinity sample size
β1_hats = []
for N in 1:N_inf
df = gen_data_corr(N)
ols = lm(@formula(Y ~ X), df)
push!(β1_hats, coef(ols)[2])
end
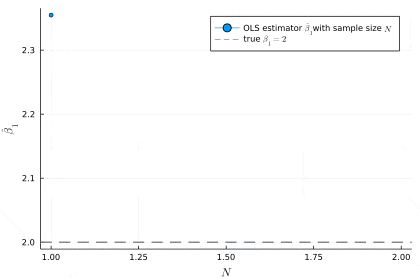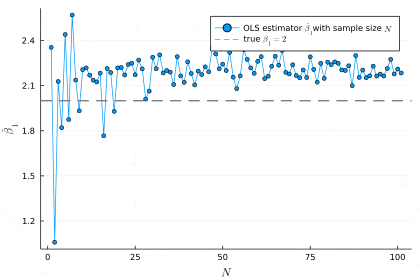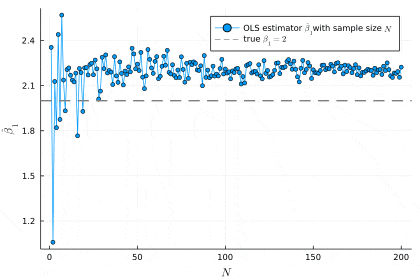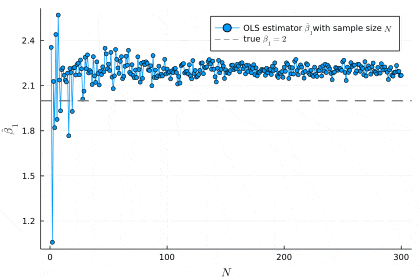
scatter(β1_hats, markersize=2, alpha=0.1, xlabel=L"N", ylabel=L"\hat{\beta}_1", label="OLS estimator "*L"\hat{\beta}_1"*"with sample size "*L"N")
hline!([β1], linestyle=:dash, color=:gray, linewidth=2, label="true "*L"\beta_1=2")

# the value of OLS estimator at N = 10000
print(β1_hats[N_inf])
# 2.1985094056667593
不偏性がなくても一致性があれば,サンプルサイズが十分大きいとき推定は外れません.一方一致性がないと,どんなにサンプルサイズを大きくしてもOLS推定量は外れます.よって,「一致性を持たないことによる漸近バイアス」は「不偏性を持たないことによるバイアス」よりも深刻な問題として捉えられることが多いです[25].
仮定
Refference
Cunningham, S., 2021. Causal inference: the mixtape. Yale University Press.
Wooldridge. 2019. Introductory Econometrics: A Modern Approach
Stock, J.H. and Watson, M.W., 2018. Introduction to econometrics 4th Edition. Boston: Addison Wesley.
-
必要条件という意味でザックリ表現してます.自分の分析を守るときに「
X U E[U|X]=0 X U -
推定量
\hat{\beta} \beta \hat{\beta} \beta -
一般的なパラメータと推定量の表記をしていますが,OLSであれば
E[\beta] = \hat{\beta} -
逆に言えば,不偏性があっても"平均的には当てる"だけなので,外すときは外します. ↩︎
-
特に議論してきませんでしたが,線形回帰の大前提の仮定として,線形のpopulation modelを想定することと母集団からランダムサンプリングすることがあります.詳しくは代表的な計量の教科書を参照してください(Wooldridge, 2019, p.40-41). ↩︎
-
この表現は推定量の特性を考えるうえでめちゃくちゃ使います.後ほどOLS推定量の一致性でも出てきます. ↩︎
-
推定量はサンプリングしたデータ
i = 1, \dots, N E[\hat{\beta}_1|X_1, \dots, X_N] -
誤差項
U E[U|X]=0 -
切片の不偏性
E[\hat{\beta}_0] = \beta_0 \hat{\beta}_0 = \bar{Y} - \hat{\beta}_1 \bar{X} -
式でごちゃごちゃやっても実感がわきにくい時に,シミュレーションをすると,ビジュアルで理解できて効果的です. ↩︎
-
当たり前すぎますが,説明変数
X -
少し仮定をviolateさせてみるのもシミュレーションの醍醐味です. ↩︎
-
データ生成プロセスの
MvNormal()の分散共分散行列をいじってみてください. ↩︎ -
そこそこ大変です. ↩︎
-
例えば,最尤推定は一致性を持ちますが,不偏性は必ずしも持ちません. ↩︎
-
推定量
W N -
サンプルサイズ無限大というのはあくまでも仮想的な話ですが,その仮想的な話ですら外すような推定量はポンコツです. ↩︎
-
実際は漸近バイアスでも単に"バイアス"と呼ぶことが多いです.何なら実証研究における"バイアス"のほとんどは漸近バイアスのことです. ↩︎
-
一致性を持たないポンコツ推定量は仮にサンプルサイズが無限大でもドンピシャ(確率1)で外します. ↩︎
-
「
X U E[U|X]=0 E[U|X]=0 -
ここでも,誤差項
U Cov[X,U]=0 -
欠落変数バイアスそのものです ↩︎
-
無限大としてはまだまだ不十分ですが,プロットもあるので勘弁してください. ↩︎
-
コードをいじってやってみてください ↩︎
-
サンプルサイズが小さければ,一致性が成り立っていると主張しにくいので,不偏性がないとダメです.一方, サンプルサイズが十分に大きいときは一致性さえあれば不偏性がなくてもエコノミスト的には大丈夫らしいです(Wooldridge, 2019, p.164). ↩︎
Discussion