【Juliaで因果推論】回帰分析 - OLS推定とその仮定
- 2つの仮定
E[U]=0, E[U|X]=E[U] Y=\beta_0 + \beta_1 X + U β_1 - 2つの仮定から,Zero conditional mean
E[U|X]=0 E[Y|X] = \beta_0 + \beta_1 X - 仮定に基づき線形回帰モデルをモーメント法による推定をすると,結果として最小二乗誤差を最小化するような(OLS)係数パラメータの推定値が得られる.
回帰分析は,他の変数を一定に(コントロール)して推定し,2つの変数間の因果関係を見出す最も代表的な方法の1つです.しかし,推定した結果が因果効果であると信用に値するものとなるためには,ある条件(仮定)が満たされていることが必要となります.仮に仮定が満たされていなければ,いくら"回帰分析"をしたとしてもその結果は因果効果として解釈できません.よって因果推論を目的とする回帰分析では,この仮定を理解することが重要となります.
母集団(population)と標本(sample)
私たちが分析で知りたいことは,興味の対象となる集合全体の中で ,
Population model
2つの変数,
-
X Y -
X Y - どのように相関関係と因果関係を区別し,他の条件を一定にしたときの
X Y
回帰分析をする際はまず頭の中で,以下のモデルが母集団で成り立っている,またはデータ生成プロセスである(と少なくとも近似できる)と考えます(population model).
このモデルを線形回帰モデルといいます.因果関係を想定するとモデルに意味が見出されます.因果が目的であれば(モデルが正しいかどうかはさておき)このモデルの見方は,右辺が原因で左辺が結果を表わします.
-
Y -
X -
U -
\beta_0 \beta_1
このモデルが3つの問題にどう対応しているか見てみましょう.まず問題1「
しかし現実の世界は複雑であるため
問題2「
となり,「
ちなみに,なぜ線形な関係を仮定するのでしょうか?1つの理由として,計算が楽だからです.しかし現実の世界は複雑で,単純な線形関係では
一番難しい問題3「どのように相関関係と因果関係を区別し,他の条件を一定にしたときの
- データを使って線形回帰モデルを推定したときに、因果効果として信用に値するような
\beta_1
ここでは,線形回帰モデルを推定する最も基本的で代表的な方法,最小二乗法(Ordinary Least Squares: OLS)[5]について考えます.すると問題3はさらに具体的になります.
- 線形回帰モデルをOLS推定したとき,信用に値するような
\beta_1
だいぶ具体的になりました.この問題に対してならはっきり答えられます.答えは2つの仮定,
-
E[U]=0 U -
E[U|X]=E[U] U X
が成り立っていればOLS推定で得られる
仮定1: E[U]=0
1つ目の仮定は,誤差項
定数項のある線形回帰モデルを見てみましょう.ただし誤差項の期待値はゼロではない何らかの値(
このままだと一見,仮定
新しいモデルは定数項が
ちなみに定数項は
仮定2: E[U|X]=E[U]
2つ目の仮定はとても重要です.仮定1と違い,仮定2は
そもそも,条件付期待値
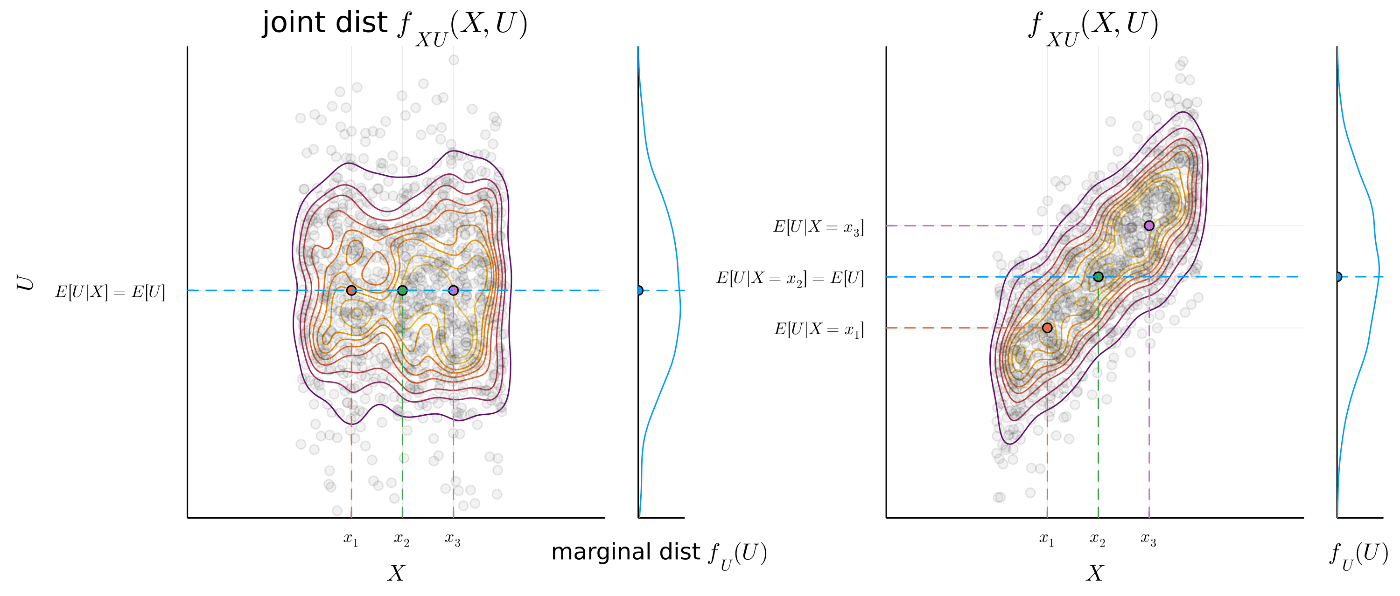
Figure.1 Mean independence のイメージ.
左:
左は
一方,右は
よって仮定2
E[U|X]=0
2つの仮定が成り立っていると
となり,
Proof:
モデルを議論する際,条件付期待値は直接イメージしにくいため[6],代わりに必要条件である
が成り立っているかどうか考えるとスムーズです[7].
実際に
using CSV, DataFrames, Plots, StatsPlots, Statistics
df = CSV.read("Earnings_and_Height.csv", DataFrame)
scatter(df.height, df.earnings, alpha=0.05, legend=false, xlabel="height (inches)", ylabel="annual labor earnings (dollars)")

次のような線形回帰モデルを考えます.
このモデルによる
欠落変数の見つけ方は2ステップです.
- 説明変数
X Y Z - その要因
Z U
- その要因
- モデルに入っていない要因
Z X - もし相関があれば,
Z U X U E[U|X]=0
- もし相関があれば,
例えばモデルに含まれていない要因
-
Sex \rightarrow Earnings Sex Earings -
Cov[Height, Sex] \neq 0 Height Sex
本当に相関があるかないか分からなくても,モデルの議論においては相関がありそうという時点で,
ちなみにデータを見ると,女性か男性か(
gdf = groupby(df, :sex)
scatter(gdf[2].height, gdf[2].earnings, alpha=0.05, label="male", xlabel="height (inches)", ylabel="annual labor earnings (dollars)")
scatter!(gdf[1].height, gdf[1].earnings, alpha=0.05, label="female")
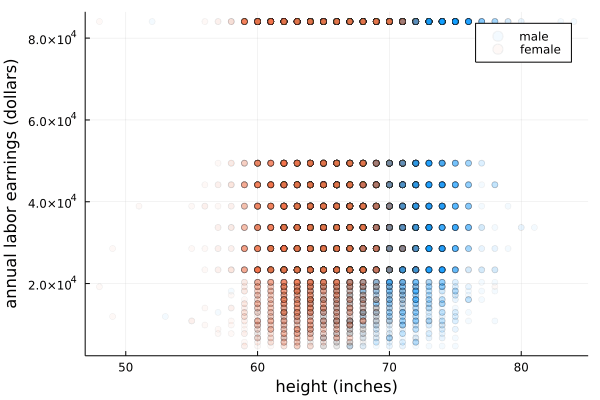
scatter(df.sex, df.height, alpha=0.05, legend=false, xlabel="sex (1=Male, 0=Female)", ylabel="height (inches)")
violin!(df.sex, df.height, side=:right, fillalpha=0, linewidth=1, label=false)
cor(df.height, df.sex)
# 0.6998784100114194
Conditional Expectation Function: CEF
もし
となります.
私たちが知りたいのは,標本の
このCEFは,高校のTOEICの点数
もちろん中には

Figure.2 母集団の回帰直線(CEF)
現実の世界で起きている事象の多くはランダムですが,ランダムの中でも手元のデータから解釈できるメカニズムの部分と,データではわからない部分が存在します.
もし
仮定に基づくモデルの推定
線形回帰モデルを推定するときに必要な2つの仮定を確認したうえで,いよいよモデルの推定方法(係数パラメータの求め方)に移ります.実際の推定も仮定ベースで進むので,繰り返しますが2つの仮定は重要です.
まず,推定するためには標本が必要です.母集団から
母集団で平均的に成り立つ(と思う)回帰モデルは
でした.母集団で平均的に成り立つモデル(関係性)はサンプルでも平均的に成り立つ という自然なアイディアから,サンプルの回帰モデル
を用意しておきます.このモデルは後で使います.
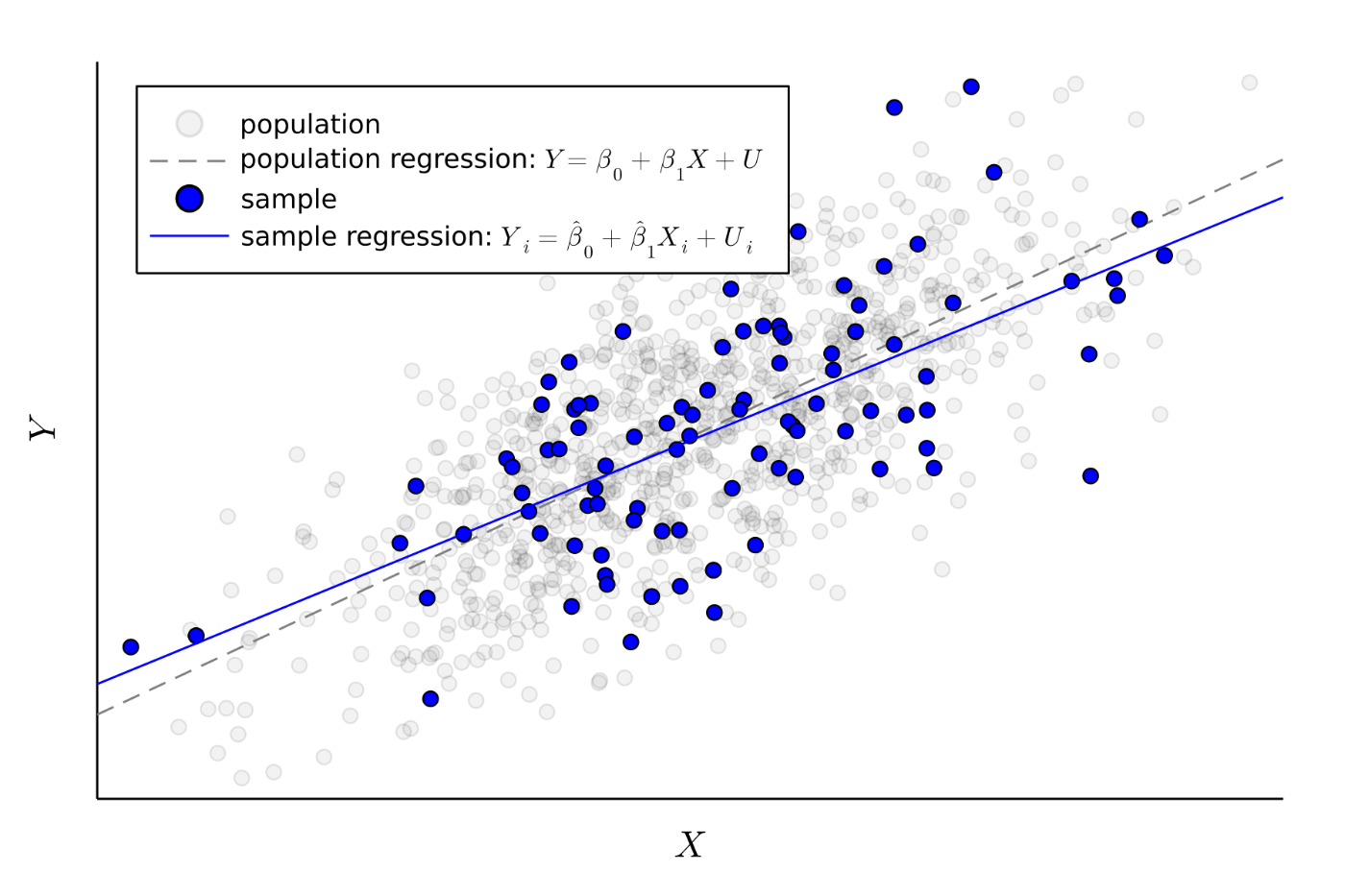
Figure.3 母集団回帰と標本回帰のイメージ
まずは母集団で2つの仮定から示される
が成り立ちます.ここで,母集団の回帰モデルより,
が得られます.これは,母集団で回帰モデルと仮定1と仮定2が成り立つために必要な,母集団における
しかし私たちは母集団を扱うことはできないため,母集団から直接パラメータ見つけることはできません.そこで母集団で成り立つ仮定はサンプルでも成り立つという自然なアイディアから,母集団における条件式をサンプルに置き換えて,私たちがデータを用いて対処できるようにします.2つの仮定がサンプルでも成り立つのであれば,母集団の時と同様に今度はサンプルの回帰から,
母集団の条件式と見比べると,期待値のオペレーター
Solve
まず,1つ目の条件
ここで,和のオペレーターの特性より,
を用いると,
よって,仮定に基づく条件式を満たすようなパラメータ
と推定されます.このような母集団のパラメータ(e.g.
ちなみにこの,「母集団で成り立つ関係はサンプルでも成り立つはず」というアイディアから,母集団のモーメント条件(population moment condition)をもとにサンプルのモーメント条件(sample moment condition)を立ててパラメータを推定する方法をモーメント法(Method of Moments: MM)といい,得られるパラメータの推定量
ところで,MM推定量に基づきデータから計算された推定値(推定量の実現値)によって,あらゆる
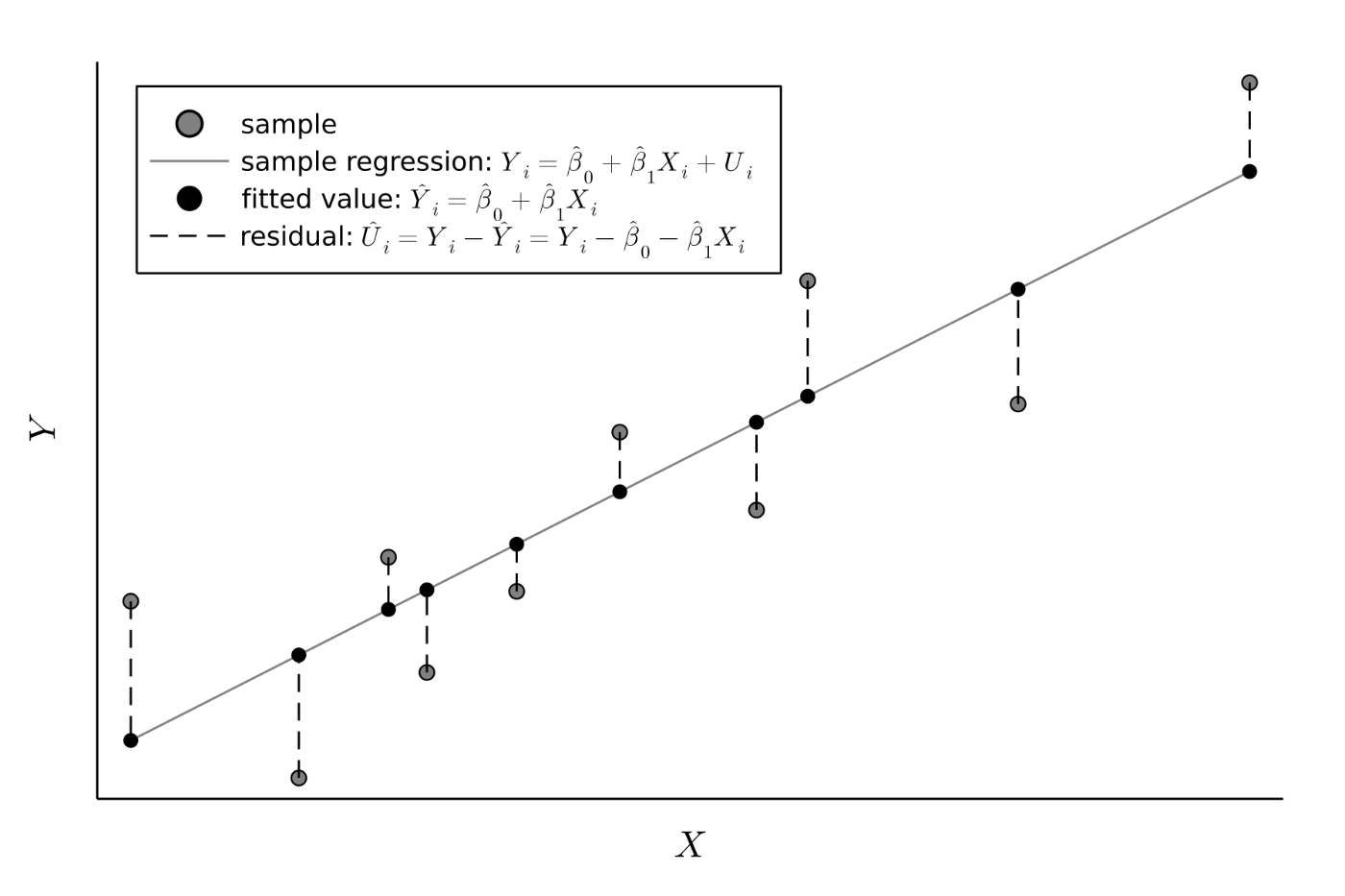
Figure.4 推計値と残差のイメージ
全てのサンプルに対して平均的にどれだけうまく予測できたかは,残差の二乗和(sum of squared residuals)[21]を指標として見ます.
"良い"モデルとして,残差の二乗和を最小にするような(予測精度が最も高い)モデルが考えられます.つまり,残差の二乗和を最小にするようなパラメータ
ですが,実はこの"良い"モデルのパラメータはMM推定で得られるパラメータ
Solve
これはサンプルのモーメント条件と一致します.
よって結果的に「残差の二乗和を最小にするような
データを使ったOLS推定のシミュレーション
式で線形回帰モデルの推定の仕方がわかったので,データを使ってプログラムで推定してみましょう.まずは,自分で真の値を設定して仮想データを自作し,シミュレーションでモデルのOLS(MM)推定値と真の値を比べてみましょう.
シミュレーションでは私たちが神様なので母集団のパラメータを好きな値に設定できます.ここでは定数項の真の値を
仮想的な母集団の
using Random, Statistics, Plots, LaTeXStrings, Printf
# 真の値を設定: Y = β0 + β1 X + U
β0, β1 = 3.0, 5.5
# 仮想データの生成.
Random.seed!(1)
N = 200
X = rand(Uniform(0, 1), N) # Xは一様分布 U ~ Uniform[0, 1] (どんな分布でもいい)
σ_U = 1
U = rand(Normal(0, σ_U), N) # Uは正規分布 U ~ Normal(0, 1) (どんな分布でもいい)
Y = β0 .+ β1 * X + U
# 線形回帰モデルを想定
# モデルのパラメータの推定,
β1_hat = cov(X, Y) / var(X)
β0_hat = mean(Y) - β1_hat * mean(X)
print("true params: ", (β0, β1), "\n")
print("estimated params: ", (β0_hat, β1_hat), "\n")
# true params: (3.0, 5.5)
# estimated params: (3.1341948310553907, 5.255470309812545)
# プロット
scatter(X, Y, color=:blue, xlabel=L"X", ylabel=L"Y", label="mock data", legend=:topleft, dpi=300)
Plots.abline!(β1_hat, β0_hat, color=:blue, label=latexstring("OLS: ", L"\hat{Y}_i = ", @sprintf("%.1f", β0_hat), L" + ", @sprintf("%.1f", β1_hat), L"X_i"))
Plots.abline!(β1, β0, color=:black, linestyle=:dash, label=latexstring("True Model: ", L"E[Y|X] = ", @sprintf("%.1f", β0), L" + ", @sprintf("%.1f", β1), L"X"))

真の値とOLS推定値を比べると,真の値
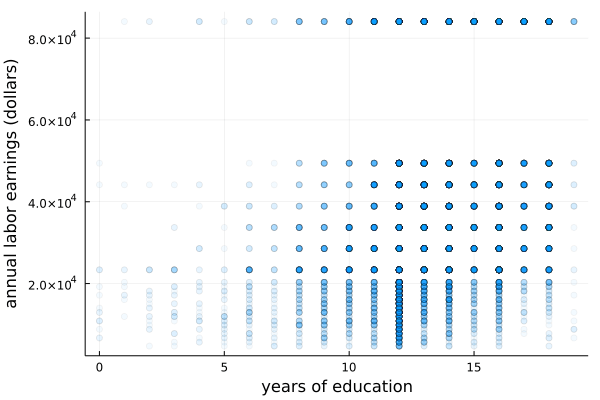
次に,実際のデータを使って教育
using CSV, DataFrames, Plots, Statistics
df = CSV.read("Earnings_and_Height.csv", DataFrame)
scatter(df.educ, df.earnings, alpha=0.05, legend=false, xlabel="years of education", ylabel="annual labor earnings (dollars)")
毎回OLS推定値をフルスクラッチ(共分散/分散)で求めるのは面倒です.大体のプログラミング言語や数理統計ソフトには回帰分析のパッケージが備わっているので,使ってみましょう.JuliaであればGLM.jlがいいと思います.
using GLM
linearRegressor = lm(@formula(earnings ~ educ), df)
# earnings ~ 1 + educ
# Coefficients:
# ────────────────────────────────────────────────────────────────────────
# Coef. Std. Error t Pr(>|t|) Lower 95% Upper 95%
# ────────────────────────────────────────────────────────────────────────
# (Intercept) -6648.03 969.179 -6.86 <1e-11 -8547.72 -4748.35
# educ 3953.76 70.2676 56.27 <1e-99 3816.03 4091.49
# ────────────────────────────────────────────────────────────────────────
出力される表の1列目Coef.にパラメータの推定値が表示されています.定数項((Intercept))はeduc)はCoef.以外の数字が意味していることは次回以降説明します.ちなみに,推定量の式を律儀に実装した結果も同じ推定値を与えます[27].
# estimate from scratch
β1_hat = cov(df.educ, df.earnings) / var(df.educ)
β0_hat = mean(df.earnings) - β1_hat * mean(df.educ)
print("estimated params: ", (β0_hat, β1_hat), "\n")
# estimated params: (-6648.030688955005, 3953.7613449465175)
結果の解釈ですが,もし
そもそもなぜ「
Refference
Cunningham, S., 2021. Causal inference: the mixtape. Yale University Press.
Huntington-Klein, N., 2021. The effect: An introduction to research design and causality. Chapman and Hall/CRC.
Wooldridge 2012 Introductory Econometrics: A Modern Approach
Stock, J.H. and Watson, M.W., 2018. Introduction to econometrics 4th Edition. Boston: Addison Wesley.
Angrist, J.D. and Pischke, J.S., 2008. Mostly harmless econometrics. In Mostly Harmless Econometrics. Princeton university press.
-
標本のみの関係性に基づいた意思決定をして母集団に処置を行っても,思った通りの変化は得られない可能性があるからです. ↩︎
-
この時点ではまだ因果関係までは想定していません.ただザックリとXの変化によってYがどう変化するかというメカニズムについてを考えます. ↩︎
-
原則,確率変数は大文字で表します.値や確率変数の実現値は小文字で表します(文献によってまちまちです).ちなみに,データや変数はアルファベットで表し,統計的に推測される母集団のパラメータ(e.g.
\beta_1 -
モデルがどれだけ現実を近似できているかはまた別の話です.モデルが妥当かどうかを吟味する必要があります. ↩︎
-
結果的にはOLSと一致しますが導出はMM法でやります.MM法だと高度な回帰分析へと繋げやすいからです. ↩︎
-
直接zero conditional mean assumptionをイメージしたいときは,Figure.1のように
E[U|X=x_1]=E[U|X=x_1]= \dots -
必要条件なので,
Cov[U, X]=0 E[U|X]=0 Cov[U, X]=0 E[U|X]=0 Cov[U, X]=0 -
データはhttps://media.pearsoncmg.com/intl/ge/2019/cws/ge_stock_econometrics_4/content/datapages/stock04_data04.htmlからダウンロードできます. ↩︎
-
厳密には,「身長の値によっては男女の(分布の)平均は異なりそう」
E[Sex|Height=h_1] \neq E[Sex|Height=h_2] \neq E[Sex] -
なぜ期待値なのかについてですが,1つの理由として,期待値は確率変数の分布を理解するうえで有用な代表値だからです.もう1つの理由としては,期待値は予測誤差(MSE)を最小化できるからです(Angrist and Pischke, 2008, p.25).通常,期待値が興味の対象ですが,中央値やパーセンタイルが興味の対象となる回帰分析もあります(quantile regression). ↩︎
-
当たり前ですが,
E[U|X]=0 E[Y|X] = \beta_0 + \beta_1 X + E[U | X] X X Y \frac{dY}{dX}=\beta_1 + \frac{dE[U|X]}{dX} E[Y|X]=\beta_0 + \beta_1 X X Y \beta_1 -
サンプルの大きさは「サンプルサイズ」です.「サンプル数」という言葉はデータセットの数を意味し,複数回分析するとき以外は基本的に使いません. ↩︎
-
注意するべきこととして,モデルの推定方法を考える段階ではサンプルの分析単位は仮想的にに
i (X_i, Y_i) i=1 i=2 x_{\text{Aさん}}=3個 y_{\text{B社}}=1,000,000円 -
誤差項
U -
population moment conditions ↩︎
-
sample moment conditions ↩︎
-
母集団の真のパラメータ
\beta_0, \beta_1 -
\hat{\beta_1} (\hat{\beta_1}=確率変数の式) (\hat{\beta_1}=数字) -
分母が
X X 0 -
残差の表記は
U_i \hat{} U_i U_i -
全サンプルに対するモデルの予測パフォーマンスは,「二乗」の和でなくても測れます.例えば残差の「絶対値」の和でも予測精度は測れます.しかし,一般的には絶対値よりも二乗の方が後の計算が楽なので残差の二乗和が人気です.二乗和は予測が大きく外れたサンプルに対して大きいペナルティを課すことに留意しましょう. ↩︎
-
最小化問題なので
\sum_{i=1}^N (Y_i - \hat{\beta}_0 - \hat{\beta}_1 X_i)^2 \hat{\beta}_0 -
OLSは仮定
E[U|X]=0 E[U|X]=0 E[U|X]=0 -
誤差項
U E[U|X]=0 -
ここでは,奇跡的に母集団での
X Y -
サンプルサイズ
Nを小さくしたらどうなるでしょうか?誤差項の分散σ_Uを大きくしたらどうなるでしょうか?シミュレーションではいろいろいじりながら勉強できるので楽しいですね. ↩︎ -
パッケージは通常行列でプログラムされているはずです. ↩︎
-
目に見えない能力は賃金に(正の)影響を与えそう,そして能力は教育とも(正に)相関しそう.妄想だけでも仮定が満たされない可能性があるので,今の分析の結果は信用できませんね. ↩︎
Discussion